Memcached源码分析——内存管理
注:这篇内容极其混乱
推荐学习这篇博客。博客的地址:http://kenby.iteye.com/blog/1423989
基本元素item
item是Memcached中记录存储的基本单元,用户向memcached写入的key value键值对信息都以item的形式存入Memcached中。
item基本结构
首先用一张图来描述item的基本结构:
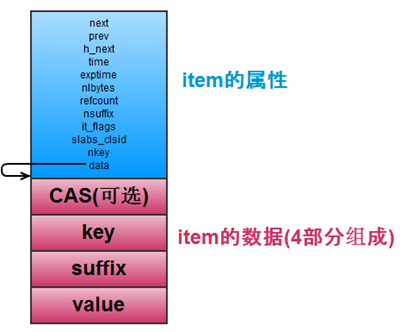
图 1-1 item的基本机构
图片来自博客,画的非常的清晰。从图片中可以看到,item主要有两个部分构成:item的元数据(属性)部分+item的数据本身部分构成。这个就是Memcached中记录的存储单元。以下是其定义的源代码:
typedef struct _stritem {
struct _stritem *next;
struct _stritem *prev;
struct _stritem *h_next; /* hash chain next*/
rel_time_t time; /* least recent access */
rel_time_t exptime; /* expire time */
int nbytes; /* size of data */
unsigned short refcount;
uint8_t nsuffix; /* length of flags-and-length string */
uint8_t it_flags; /* ITEM_* above */
uint8_t slabs_clsid;/* which slab class we're in */
uint8_t nkey; /* key length, w/terminating null and padding */
union {
uint64_t cas;
char end;
} data[];//data 不占用任何空间
} item;
使用typedef定义结构体_stritem为item。这个就是item的定义了。从item的定义中,可以看到,结构体本身并不包含任何关于数据key value的定义。那么是否和图中的红色部分有违背呢?
堆上操作的宏定义技巧
答案是在操作item的时候肯定会在堆上分配空间,开发人员使用了宏定义的技巧,使得对内存的管理更加的灵活方便:
unsigned int size = sizeof(item) + settings.chunk_size;
上面是一个完整的chunk的大小的求解方法,可以看到除了sizeof以外,还额外负担了用户手动配置的chunk_size。可以看到一个item所占的空间由两部分构成,符合2.1.1中对item的定义。而chunk_size所指向的内存空间又是如何划分的?
首先撇开内存空间的定义,结构体item中最关键的data[]空数组的定义:
typedef _stritem{
....
union{
uint64_t cas;
char end;
}data[];
}item;
在_stritem结构体中定义了一个空的数组data[],data[]不占用任何的空间。当item后续有数据时,data的地址就是紧接着item元数据部分的成员的首地址。有了这个就不难理解宏定义了。
cas是Memcached中为了支持多线程读写的一个标志,类似compare and swap(实际上是check and set),是可选的标志。当用户启动了cas特性后,则通过以下方式访问cas位:
item->data->cas;
而当用户没有启用cas的时候,则data就纯当指针基地址来使用了。有了以上的知识,我们来看几个宏定义的使用:
#define ITEM_key(item) (((char*)&((item)->data)) \
+ (((item)->it_flags & ITEM_CAS) ? sizeof(uint64_t) : )) #define ITEM_suffix(item) ((char*) &((item)->data) + (item)->nkey + 1 \
+ (((item)->it_flags & ITEM_CAS) ? sizeof(uint64_t) : )) #define ITEM_data(item) ((char*) &((item)->data) + (item)->nkey + 1 \
+ (item)->nsuffix \
+ (((item)->it_flags & ITEM_CAS) ? sizeof(uint64_t) : ))
使用四个宏定义来给予data指针计算不同成员的在堆空间上面的偏移量。来看第一个:ITEM_key(item),首先将data的地址强制转换成char*指针,从而以步进为字节方式获得地址。随后判断当前flag是否包含cas的部分,如果包含,则指针加上uint64_t的大小(8个字节)越过cas占用的地址;如果没有包含,则加0,表明data的地址就是key的地址。
剩下求解suffix、data的地址采用类似相同的方式来完成。可以看到这个技巧的牛逼的地方。求解suffix、data地址的时候,可以看到有个+1的操作,这个原因是key的末尾有一个null终结符,占用1个字节的空间。因此需要加一操作。
为了求解整个item占用空间大小(不是chunk的占用空间),同样定义了宏来求解:
#define ITEM_ntotal(item) (sizeof(struct _stritem) + (item)->nkey + 1 \
+ (item)->nsuffix + (item)->nbytes \
+ (((item)->it_flags & ITEM_CAS) ? sizeof(uint64_t) : ))
首先是_stritem本身的大小,随后是key的大小,空字节的大小,suffix的大小,value的大小,最后看当前是否使用了cas,如果使用了需要计算cas的大小。对每个分量求和便是整个item的大小。
从本小结的宏定义中我们看到了C语言项目对于内存的精细操作,纵观编程世界,可能也只有C能够做出这么精彩的内存操作。
item 元数据介绍
再来引入item的定义,这次直接截图了,写代码太占用空间了。
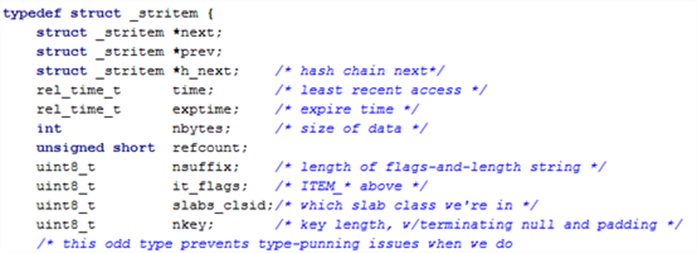
图 1-2 item的基本定义
这些数据代表了item的基本信息,在后续的很多数据结构中都会用到他们,以下列举主要的成员:
v LRU链表
next和prev指针用于构成链表,这个链表维护了当前已经分配的item空间。为了支持LRU特性,链表默认以访问频度排序,最新访问的item将位于链表的表头。
v hash表桶
h_next指针用于构成在hash链表中,桶内组成链表。hash表主要用于快速检索item。
v 相关时间
item的最近访问时间以及超时时间,在内存空间不足时,不得不将一些item换出内存,因此使用这个来完成。
v slabs_clsid
描述当前item位于哪个slabs类中。由于每个slab类的大小依次成指数递增,因此某个item需要位于一个slab类中,而slabs_clsid就是当前slab类的编号。
Hash表实现
为了实现快速的检索,Memcached内部实现了Hash表,就是为了纯检索。Memcached中的Hash表位于assoc.c以及assoc.h中实现的。我们来一睹hash表的定义:
static item** primary_hashtable = ;
用一个二级item指针就实现了hashtable,其实hashtable的实现都在业务逻辑中了。
Hash表的实际构成结构如下:
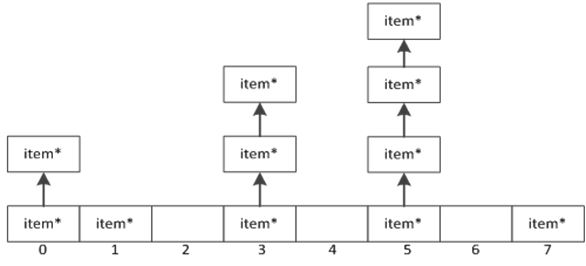
图 1-3 memcached hash表的实现
如上图,Memcached采用了开链方法,对Hash表进行了实现。本节将对Hash表进行介绍。
结构原理解释
从图 1-3可以看出hash表的基本实现。整体来讲就是一个指针数组,数组的每个元素存放着一个item。当对item进行存储检索时,将item的key求hash值,hash值的求法就是经典的取模法。存入之后就放入对应的编号位置。
如果遇上hash值相同冲突的情况,memcached则使用开链法,将相同hash值的item都链接在一起,使用item->h_next进行链接操作。
元素查找
为了求解hash值,memcached使用宏定义来求解给定的item应该存入哪个位置。
#define hashsize(n) ((ub4)1<<(n))
#define hashmask(n) (hashsize(n)-1)
hv = hash(key, nkey, );
it = primary_hashtable[hv & hashmask(hashpower)]
以上两个宏定义和两条语句求解hash表位置的item。其中hv的求解依赖自定义的hash函数,这个函数就不分析了。当求解出hv后,和宏2进行与操作就求出了hash表中桶的位置。而hashsize()就是将1左移n位,达到一个乘二的效果,而hashmask的目的是求出遮挡位:
以下为二进制:
原本:100000
遮挡:011111
可以看出遮挡位将首位变为0,剩余的都变为1。然后hv & hashmask的目的就是进行了一次求余数操作。这种求余操作避免了使用%这样消耗比较高的操作,缺点是只能应用于2的幂次的求余数操作。但一般为了快速,hash表的桶的个数也是2的幂次数。
求解出桶的位置之后,查找一个item就简单了。从桶的第0个元素的位置开始依次沿着h_next进行就可以了。
求余一般我都会直接使用%方法进行求解,开源项目能让人提炼自己的编程功力,提升基础。
hash表的扩张
hash表起始桶的个数为16,当存不下之后,hash表需要进行一次扩张操作。hash表的扩张需要一定时间,Memcached为了在表扩张时继续服务,使用了双hash表机制:
static item** primary_hashtable = ;
static item** old_hashtable = ;
平常主要使用primary_hashtable,当hash表扩张的时候,临时使用old_hashtable,当hash表扩张完毕之后再切换到primary_hashtable。
Memcached使用assoc_maintenance_thread()这个函数对hash表进行管理,实质上是通过一个守护线程死循环处理:
while (do_run_maintenance_thread){
......
}
通过一个while死循环,一直查看hash表的状态,当hash表满的时候对表进行扩容。
old_hashtable = primary_hashtable;
primary_hashtable = calloc(hashsize(hashpower + ), sizeof(void *));
if (primary_hashtable) {
if (settings.verbose > )
fprintf(stderr, "Hash table expansion starting\n");
hashpower++;
expanding = true;
expand_bucket = ;
STATS_LOCK();
stats.hash_power_level = hashpower;
stats.hash_bytes += hashsize(hashpower) * sizeof(void *);
stats.hash_is_expanding = ;
STATS_UNLOCK();
开始扩张前,将old_hashtable指向主表,随即主表重新开始分配空间,可以看到新空间的大小是老空间的2倍。随后再状态位里面设置一些标记,记录hash表新使用的空间。最后将hash_is_expanding置为1,通知线程开始对hash表进行扩张操作。
线程do_run_maintenance_thread负责将老表中的所有数据依次拷贝到新表中。每个循环拷贝一个桶中的所有item,用户可以设置每个循环拷贝多个桶,通过改变hash_bulk_move变量的值。但是这样可能会导致堆cache锁占用的时间过长,影响Memcached对外提供的服务。hash表扩张拷贝的代码如下:
item *it, *next;
int bucket; for (it = old_hashtable[expand_bucket]; NULL != it; it = next) {
next = it->h_next; bucket = hash(ITEM_key(it), it->nkey, ) & hashmask(hashpower);
it->h_next = primary_hashtable[bucket];
primary_hashtable[bucket] = it;
} old_hashtable[expand_bucket] = NULL
expand_bucket++;
expand_bucket从0开始。拷贝时,将老表第0个桶中的所有元素依次取出,并重新计算在新表中的桶的位置,拷贝到新表中。如果新表当前桶中已经有了item了,那么就放到桶中的第一个位置中。随后将老表当前桶的位置置为空。最后对桶计数自增,进入下一个循环,继续拷贝数据。
元素的删除
memcached删除元素并不是真的删除,因为内存都是预先分配好的,hash表中存的东西相当于引用。指针变量退出函数后内存自动就释放了。因此元素的删除只是修改hash表的指针结构:
item **before = _hashitem_before(key, nkey, hv);
if (*before) {
item *nxt;
hash_items--;
MEMCACHED_ASSOC_DELETE(key, nkey, hash_items);
nxt = (*before)->h_next;
(*before)->h_next = ; /* probably pointless, but whatever. */
*before = nxt; //*before代表item->next指针
return;
}
就是将before->h_next=item->h_next操作,经典的跨指针删除法。函数_hashitem_before查找当前key对应元素的前一个item,以方便删除操作。
slab结构
Memcached将所有slab类组织在一起,构成了slab存储结构。
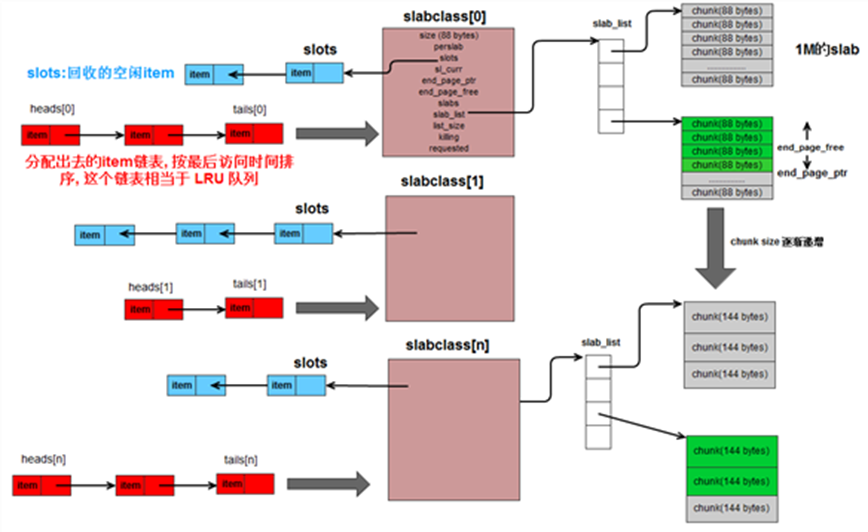
图 1-4 slab结构体系
图1-4是整个slab存储体系的结构图,以slab为核心,将空闲槽、LRU队列、slab列表、hash表完整的组合在一起。hash表已经在上一个小节中分析了,同时也不好在这张图中进行表述。本小结介绍slab结构体系。
slab类定义
直接上结构体的定义:

图1-5 slab类定义
定义一个结构体为slabclass_t类型。
size表明当前slab类中item的大小,slab id越高,则当前存储的item的chunk的大小越大,最大是1MB。perslab保存了当前slab类中拥有多少个item。计算方法很简单size/perslab就可以计算出来。
slots存储当前空闲的item。当item不用被回收时,会进入slot中去。slab在分配内存时优先从slots中进行分配。sl_curr看见变量定义的很牛逼,其实就是slots的数量。
slabs,一个slab类可能包含多个slab。系统分配内存时,当一个slab空间用完之后才会再分配下一个slab,这个slabs就是用于当前记录当前slab类已经分配了多少个slab了。
slab_list,就是多个slab形成的链表,用这个指针进行描述。而下面list_size记录前一个list的大小。记录的原因是在分配新的slab list的时,通常分配的数量都是前一个list大小的二倍。(很多空间自动增长的数据结构的内部的经典做法)
killing,在slab进行rebalance中使用的机制,暂时没有涉及这部分的代码,因此先跳过。
requested,已经请求的数据量大小,当前slab类已经分配出去的内存。
LRU队列
每个slab类都有若干item,构成一个LRU列表。当对这个slab进行内存分配时,如果内存不足,就必须将某个item换出内存,腾出空间给其他申请内存的item使用。某个slab类的item LRU队列并没有直接和slabclass_t直接挂钩,而是通过slab id进行关联:
static item *heads[LARGEST_ID];
static item *tails[LARGEST_ID];
在item.c文件中定义了两个全局的指针数组,这个就是当前系统中所有slabclass的LRU队列的头、尾指针。如果想要使用指定的LRU队列,使用head[id]以及tail[id]就可以对特定列表进行引用了。
v item插入
当系统新分配一个item时,需要将item放入LRU队列中进行保存。放入LRU队列的对首中:
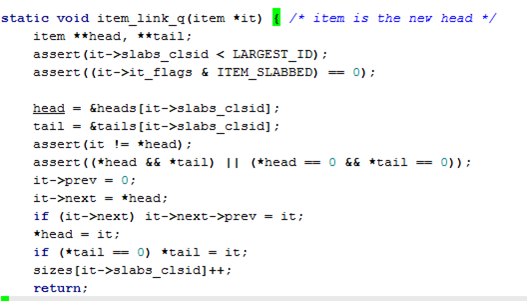
图 1-6 item插入
将item插入链表的头部,经典的头部操作。链表插入头部而不是尾部是有深刻原因的。当一个item插入链表时,表明这个item是最新,因此插入头部。后续进行淘汰item的时候就是从链表尾部进行淘汰。Memcached将LRU链表中,越靠近头部的节点,看成越新(更新、插入)的节点,LRU节点尾端的节点看成越老的节点。
v item删除
删除指定的item很容易,同样是经典的指针操作:

图 1-7 item unlink
可以看出将指针关系更新后,函数就退出了,并没有真正删除数据。没有free的原因就是memcached自己进行内存的管理。释放item留出的空间放入slab类的空闲槽slot中:

图 1-8 item unlink后的操作:挂入slot中
函数do_slabs_free负责将释放的item挂入slot中。同样是挂入slots队列的头部。
LRU队列更新
当对LRU队列中item访问时,需要更新item的状态,因为空间不够的时候换出的是一直没有使用的item。更新操作:
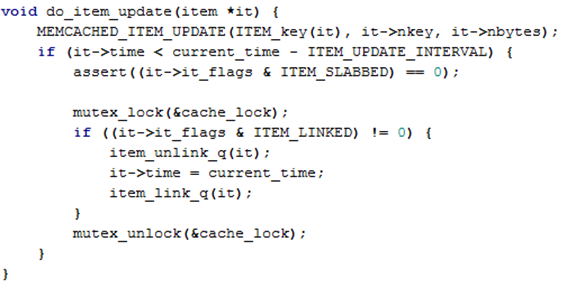
图 1-9 LRU队列更新
更新关键操作就是if语句块中的三行代码:1 把这个item拿出来,2 更新item的访问时间,3 把这个item再放进去。1和3两条语句将item从LRU队列中放入队列的首部,完成更新的目的。
在slab上分配item
之前的小结都是零碎的一些源码部分,这小节以slab的操作为轴,进行相关代码的分析工作。
主要调用函数do_item_alloc()完成。这个函数的代码量较多,业务逻辑较为复杂,这里进行简要的分析。
内存分配时优先从LRU队列中超时的item进行分配:

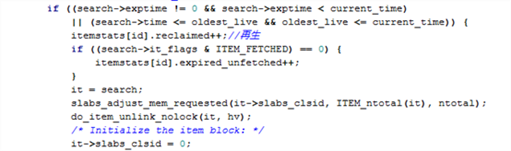
图 1-10 首先从LRU队列中寻找
search=tails[id],找到slab类id为id的LRU尾指针,并赋值给Search。从LRU队列末端开始选择的原因是LRU队列尾巴保存着最有可能超时的item,如果队列末端的都没超时,则跳过LRU item的换出操作。
从尾端开始查找,如果当前的hash桶被锁住了,就跳过,查找前一个item。如果没有跳过,并且item也超时了,则将调用do_item_unlink_nolock将item从hash表和LRU队列中移除。
如果LRU最后一个item没有超时,则表明所有LRU队列中的item均没有超时,因此暂时不能从LRU队列进行内存的分配,需要从slab系统进行内存的分配工作:
it = slabs_alloc(ntotal, id)
调用slabs_alloc()函数从slab系统中进行分配。slabs_alloc()函数操作同样较为负责,为了不打断do_item_alloc()的逻辑,先把这个函数放放,等do_item_alloc()函数分析完之后再讨论。
如果从slab系统中进行内存分配同样失败了,则只能还是从LRU队列中淘汰最旧未使用的item中了:

图 1-11 LRU队列换出item
如果slabs_alloc()失败,则只能无奈从LRU队列置换一个item出来。如果用户设置了不允许进行item置换,则最终只能报错:outofmemory了。否则更新evicted的item数量,并将这个item换出,更新当前slab类需要的内存信息,将换出的item从slab系统中移除。
当移除之后,返回选定的item,对item做基本的初始化,并将item返回给函数上层调用者。
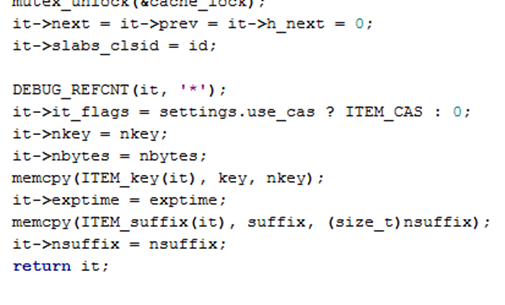
图 1-12 分配item的初始化
从slab系统中分配一个新的slab
上小节在item分配的时候,首先查看LRU队列中是否有合适的item。如果没有,则从slab类中进行内存的分配,调用函数:do_slabs_alloc()。
函数do_slabs_alloc()首先检查当前slab类中的空闲slot链表是否还有可用的slot,如果有则拿一个slot出来:
/* return off our freelist */
it = (item *)p->slots;
p->slots = it->next;
if (it->next) it->next->prev = ;
p->sl_curr--;
ret = (void *)it;
将slot链表中的第一个slot拿出来返回给调用者。如果当前slab类已经没有后空闲的slot链表,则需要重新分配内存,即调用函数:do_slabs_newslab()进行:
if ((mem_limit && mem_malloced + len > mem_limit && p->slabs > ) ||
(grow_slab_list(id) == ) ||//确保slab_list有足够容量
((ptr = memory_allocate((size_t)len)) == )) {// memory_allocate 分配 1M 的内存空间,
//memory_allocate 就是移动指针 MEMCACHED_SLABS_SLABCLASS_ALLOCATE_FAILED(id);
return ;
}
分配时,首先调用grow_slab_list()确保当前slab类有足够的空间。函数grow_slab_list()首先判断已经分配的slab个数是否已经赶上slab list的大小,如果赶上了说明slab list已经分配完了,调用realloc()将slab list的大小扩大一倍。
随后调用memory_allocate()分配1MB的空间出来,该函数将返回分配空间的指针mem_current,并将mem_current向前移动1MB大小,为下一次分配内存进行准备。又是一个手动管理内存的实例。
最后调用函数split_slab_page_into_freelist()将分配的内存初始化为slots,加入slot链表中。函数split_slab_page_into_freelist()将空间切分:
slabclass_t *p = &slabclass[id];
int x;
//将一大块儿内存分割成item,挂载到空闲slot中
for (x = ; x < p->perslab; x++) {
do_slabs_free(ptr, , id);
ptr += p->size;
}
依次将指针进行步进移动,划分为item,并将这个item进行fdo_slabs_free操作。而do_slabs_free():
it = (item *)ptr;
it->it_flags |= ITEM_SLABBED;
it->prev = ;
it->next = p->slots;
if (it->next) it->next->prev = it;
p->slots = it;
p->sl_curr++;
p->requested -= size;
修改当前item的前后指针,将item移入slots链表中去。
在slab上删除一个item
有了前面小节的基础,当需要手动删除item时则比较简单了,调用函数do_item_unlink()完成。
void do_item_unlink(item *it, const uint32_t hv) {
MEMCACHED_ITEM_UNLINK(ITEM_key(it), it->nkey, it->nbytes);
mutex_lock(&cache_lock);
if ((it->it_flags & ITEM_LINKED) != ) {
it->it_flags &= ~ITEM_LINKED;
STATS_LOCK();
stats.curr_bytes -= ITEM_ntotal(it);
stats.curr_items -= ;
STATS_UNLOCK();
assoc_delete(ITEM_key(it), it->nkey, hv);//hash表中删除
item_unlink_q(it);//LRU队列中删除
do_item_remove(it);//把item放入slot中
}
mutex_unlock(&cache_lock);
}
首先设置标志位,更新状态信息。随后调用assoc_delete()将item指针关系从hash表中删除。再调用item_unlink_q()将item指针关系从LRU队列中删除。最后调用do_item_remove()将item放入空闲slots队列中。
可以看出,删除item的时候并不真正的释放内存,而是巧妙的将空闲的item放入slots中,以备将来使用。优秀的内存管理操作使得Memcached的性能很高。
小结
本章对slab内存管理进行了介绍。可以看出,Memcached在对内存管理时,以slab类为核心,通过灵活改变操控hash表、LRU队列、slab空闲slots三类数据结构,改变item的具体行为以及位置,达成内存的分配与管理工作。设计非常合理与巧妙。
Memcached源码分析——内存管理的更多相关文章
- Memcached源码分析之内存管理
先再说明一下,我本次分析的memcached版本是1.4.20,有些旧的版本关于内存管理的机制和数据结构与1.4.20有一定的差异(本文中会提到). 一)模型分析在开始解剖memcached关于内存管 ...
- 鸿蒙内核源码分析(内存规则篇) | 内存管理到底在管什么 | 百篇博客分析OpenHarmony源码 | v16.02
百篇博客系列篇.本篇为: v16.xx 鸿蒙内核源码分析(内存规则篇) | 内存管理到底在管什么 | 51.c.h .o 内存管理相关篇为: v11.xx 鸿蒙内核源码分析(内存分配篇) | 内存有哪 ...
- Memcached源码分析之请求处理(状态机)
作者:Calix 一)上文 在上一篇线程模型的分析中,我们知道,worker线程和主线程都调用了同一个函数,conn_new进行事件监听,并返回conn结构体对象.最终有事件到达时,调用同一个函数ev ...
- Memcached源码分析之从SET命令开始说起
作者:Calix 如果直接把memcached的源码从main函数开始说,恐怕会有点头大,所以这里以一句经典的“SET”命令简单地开个头,算是回忆一下memcached的作用,后面的结构篇中关于命令解 ...
- Memcached源码分析
作者:Calix,转载请注明出处:http://calixwu.com 最近研究了一下memcached的源码,在这里系统总结了一下笔记和理解,写了几 篇源码分析和大家分享,整个系列分为“结构篇”和“ ...
- linux内存源码分析 - 内存回收(整体流程)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 当linux系统内存压力就大时,就会对系统的每个压力大的zone进程内存回收,内存回收主要是针对匿名页和文 ...
- TOMCAT8源码分析——SESSION管理分析(上)
前言 对于广大java开发者而已,对于J2EE规范中的Session应该并不陌生,我们可以使用Session管理用户的会话信息,最常见的就是拿Session用来存放用户登录.身份.权限及状态等信息.对 ...
- Tomcat源码分析——Session管理分析(上)
前言 对于广大java开发者而已,对于J2EE规范中的Session应该并不陌生,我们可以使用Session管理用户的会话信息,最常见的就是拿Session用来存放用户登录.身份.权限及状态等信息.对 ...
- (转)linux内存源码分析 - 内存回收(整体流程)
http://www.cnblogs.com/tolimit/p/5435068.html------------linux内存源码分析 - 内存回收(整体流程) 概述 当linux系统内存压力就大时 ...
随机推荐
- 日志生成控制文件syslog.conf
1: syslog.conf的介绍 对于不同类型的Unix,标准UnixLog系统的设置,实际上除了一些关键词的不同,系统的syslog.conf格式是相同的.syslog采用可配置的.统一的系统登记 ...
- Delphi 通过字符串实例化类
通过字符串创建窗体类对象 1.需要在程序初始化的时候将类注册,注册到对象 RegGroups:(TRegGroups)中,以便查找. 注册类使用的函数:RegisterClass ,窗体初始化操作放在 ...
- Oracle与MySQL连接配置
MySQL: Driver: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/GBDSPT(数据库名称) Oracle: Driver:o ...
- netty 基础知识
http://my.oschina.net/bieber/blog/406799 线程模型 http://hongweiyi.com/2014/01/netty-4-x-thread-model/ h ...
- 使用亚马逊云服务器EC2做深度学习(四)配置好的系统镜像
这是<使用亚马逊云服务器EC2做深度学习>系列的第四篇文章. (一)申请竞价实例 (二)配置Jupyter Notebook服务器 (三)配置TensorFlow (四)配置好的系统 ...
- java SE :文件基本处理 File、FileFilter、FileNameFilter
File 对目录及文件的创建.重命名.删除.文件列表.判断是否存在 构造函数 // 完整的目录或文件路径 public File(String pathname) //父级目录/文件路径+子级目 ...
- android开发笔记,杂
Mapping文件地址: mapping文件用于在代码被混淆后,还原BUG信息. release模式编译项目即可产生,相对位置:工程\build\outputs\mapping\release 需要c ...
- css 字符图标浏览器自带
项目中用到的一些特殊字符和图标 html代码 <div class="cross"></div> css代码 .cross{ width: 20px; he ...
- java项目建立流程
spring mvc 书籍Spring in Action, 4th Edition java项目建立流程 1 使用maven来管理项目中的库.先用marven建立一个框架mvn archetype: ...
- Vuex总结
Vuex官网链接:https://vuex.vuejs.org/zh-cn/strict.html Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式. 它采用集中式存储管理应用的所有组件 ...