sqoop一些语法的使用
参数详细资料 观看这个博客
http://shiyanjun.cn/archives/624.html
Sqoop可以在HDFS/Hive和关系型数据库之间进行数据的导入导出,其中主要使用了import和export这两个工具。这两个工具非常强大,提供了很多选项帮助我们完成数据的迁移和同步。比如,下面两个潜在的需求:
- 业务数据存放在关系数据库中,如果数据量达到一定规模后需要对其进行分析或同统计,单纯使用关系数据库可能会成为瓶颈,这时可以将数据从业务数据库数据导入(import)到Hadoop平台进行离线分析。
- 对大规模的数据在Hadoop平台上进行分析以后,可能需要将结果同步到关系数据库中作为业务的辅助数据,这时候需要将Hadoop平台分析后的数据导出(export)到关系数据库。
这里,我们介绍Sqoop完成上述基本应用场景所使用的import和export工具,通过一些简单的例子来说明这两个工具是如何做到的。
import和export工具有些通用的选项,如下表所示:
| 选项 | 含义说明 |
--connect <jdbc-uri> |
指定JDBC连接字符串 |
--connection-manager <class-name> |
指定要使用的连接管理器类 |
--driver <class-name> |
指定要使用的JDBC驱动类 |
--hadoop-mapred-home <dir> |
指定$HADOOP_MAPRED_HOME路径 |
--help |
打印用法帮助信息 |
--password-file |
设置用于存放认证的密码信息文件的路径 |
-P |
从控制台读取输入的密码 |
--password <password> |
设置认证密码 |
--username <username> |
设置认证用户名 |
--verbose |
打印详细的运行信息 |
--connection-param-file <filename> |
可选,指定存储数据库连接参数的属性文件 |
数据导入工具import
import工具,是将HDFS平台外部的结构化存储系统中的数据导入到Hadoop平台,便于后续分析。我们先看一下import工具的基本选项及其含义,如下表所示:
| 选项 | 含义说明 |
--append |
将数据追加到HDFS上一个已存在的数据集上 |
--as-avrodatafile |
将数据导入到Avro数据文件 |
--as-sequencefile |
将数据导入到SequenceFile |
--as-textfile |
将数据导入到普通文本文件(默认) |
--boundary-query <statement> |
边界查询,用于创建分片(InputSplit) |
--columns <col,col,col…> |
从表中导出指定的一组列的数据 |
--delete-target-dir |
如果指定目录存在,则先删除掉 |
--direct |
使用直接导入模式(优化导入速度) |
--direct-split-size <n> |
分割输入stream的字节大小(在直接导入模式下) |
--fetch-size <n> |
从数据库中批量读取记录数 |
--inline-lob-limit <n> |
设置内联的LOB对象的大小 |
-m,--num-mappers <n> |
使用n个map任务并行导入数据 |
-e,--query <statement> |
导入的查询语句 |
--split-by <column-name> |
指定按照哪个列去分割数据 |
--table <table-name> |
导入的源表表名 |
--target-dir <dir> |
导入HDFS的目标路径 |
--warehouse-dir <dir> |
HDFS存放表的根路径 |
--where <where clause> |
指定导出时所使用的查询条件 |
-z,--compress |
启用压缩 |
--compression-codec <c> |
指定Hadoop的codec方式(默认gzip) |
--null-string <null-string> |
果指定列为字符串类型,使用指定字符串替换值为null的该类列的值 |
--null-non-string <null-string> |
如果指定列为非字符串类型,使用指定字符串替换值为null的该类列的值 |
bin/sqoop help 可以查看出帮助文档 英文的 看不懂
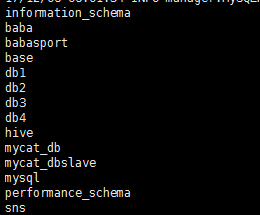
1:sqoop查看mysql有多少个数据库
bin/sqoop list-databases \
--connect jdbc:mysql://172.16.71.27:3306 \
--username root \
--password root

2:将mysql表中数据导入到hdfs中 imports
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--table test_tb
ps:如果没有指定hdfs的目录 默认会将数据存到系统当前登录用户下 以表名称命名的文件夹下

ps : 复制的时候一定要注意下 \ 的位置 少个空格都会报错。。。 默认会有4个MapReduce在执行 这里测试数据只有2条 so。。。

数据默认以逗号隔开 可以根据需求进行指定

导入数据至指定hdfs目录
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/beifeng/sqoop/imp_my_user \
--num-mappers 1
ps: num-mappers 1 指定执行MapReduce的个数为1
target-dir 指定hdfs的目录
sqoop 底层的实现就是MapReduce,import来说,仅仅运行Map Task
数据存储文件
* textfile
* orcfile
* parquet
将数据按照parquet文件格式导出到hdfs指定目录
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--table test_tb \
--target-dir /user/xuyou/sqoop/imp_my_user_parquet \
--fields-terminated-by '@' \
--num-mappers 1 \
--as-parquetfile
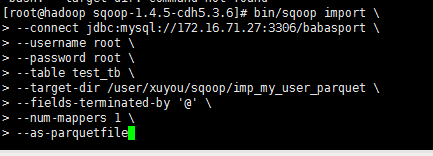
ps fields-terminated-by '@' 数据已@隔开
as-parquetfile 数据按照parquet文件格式存储
columns id,name 这个属性 可以只导入id已经name 这两个列的值

* 在实际的项目中,要处理的数据,需要进行初步清洗和过滤
* 某些字段过滤
* 条件
* join
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--query 'select id, account from my_user where $CONDITIONS' \
--target-dir /user/beifeng/sqoop/imp_my_user_query \
--num-mappers 1
ps: query 这个属性代替了 table 可以通过用sql 语句来导出数据
(where $CONDITIONS' 是固定写法 如果需要条件查询可以 select id, account from my_user where $CONDITIONS' and id > 1)
压缩导入至hdfs的数据 可以指定格式
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/beifeng/sqoop/imp_my_sannpy \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'
ps:compress 这个属性 是 开启压缩功能
compression-codec 这个属性是 指定压缩的压缩码 本次是SnappyCodec
sqoop一些语法的使用的更多相关文章
- hadoop问题集(1)
参考: http://dataunion.org/22887.html 1.mapreduce_shuffle does not exist 执行任何时报错: Container launch ...
- sqoop的基本语法详解及可能遇到的错误
1 sqoop介绍 Apache Sqoop是专为Apache Hadoop和结构化数据存储如关系数据库之间的数据转换工具的有效工具.你可以使用Sqoop从外部结构化数据存储的数据导入到Hadoop分 ...
- Oozie分布式任务的工作流——Sqoop篇
Sqoop的使用应该是Oozie里面最常用的了,因为很多BI数据分析都是基于业务数据库来做的,因此需要把mysql或者oracle的数据导入到hdfs中再利用mapreduce或者spark进行ETL ...
- Sqoop 结合多种系统的具体应用
Sqoop与HDFS结合 下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出. Sqoop import 它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示. 我们来 ...
- Hive学习之七《 Sqoop import 从关系数据库抽取到HDFS》
一.什么是sqoop Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL ...
- sqoop关系型数据迁移原理以及map端内存为何不会爆掉窥探
序:map客户端使用jdbc向数据库发送查询语句,将会拿到所有数据到map的客户端,安装jdbc的原理,数据全部缓存在内存中,但是内存没有出现爆掉情况,这是因为1.3以后,对jdbc进行了优化,改进j ...
- sqoop数据迁移(基于Hadoop和关系数据库服务器之间传送数据)
1:sqoop的概述: (1):sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具.(2):导入数据:MySQL,Oracle导入数据到Hadoop的HDFS.HIV ...
- Flume+Sqoop+Azkaban笔记
大纲(辅助系统) 离线辅助系统 数据接入 Flume介绍 Flume组件 Flume实战案例 任务调度 调度器基础 市面上调度工具 Oozie的使用 Oozie的流程定义详解 数据导出 sqoop基础 ...
- Sqoop 使用详解(内含对官方文档的解析)
Sqoop 是 Cloudera 公司创造的一个数据同步工具,现在已经完全开源了. 目前已经是 hadoop 生态环境中数据迁移的首选,另外还有 ali 开发的 DataX 属于同类型工具,由于社区的 ...
随机推荐
- .NET Core使用EF分页查询数据报错:OFFSET语法错误问题
在Asp.Net Core MVC项目中使用EF分页查询数据时遇到一个比较麻烦的问题,系统会报如下错误: 分页查询代码: ) * condition.PageSize).Take(condition. ...
- 如何在Eclipse配置PyDev插件
如何在Eclipse配置PyDev插件 | 浏览:1733 | 更新:2014-04-21 11:36 1 2 3 4 5 分步阅读 Eclipse配置PyDev插件 方法/步骤 从 Eclips ...
- Spring学习 6- Spring MVC (Spring MVC原理及配置详解)
百度的面试官问:Web容器,Servlet容器,SpringMVC容器的区别: 我还写了个文章,说明web容器与servlet容器的联系,参考:servlet单实例多线程模式 这个文章有web容器与s ...
- Sql Server统计报表案例
场景:查询人员指定年月工作量信息 USE [Test] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO ALTER procedure [dbo ...
- SQL的拼接语句在DELPHI中怎么写
SQL 语句的拼接,关键点在于对引号的处理上. 在 delphi 的语法中,使用单引号做字符串的标志符.因此,当遇到 SQL 语句中字符串标识量编写的时候,需要用两个单引号来代替实际的引号. 举例: ...
- 【前端学习笔记05】JavaScript数据存储Cookie相关方法封装
//Cookie设置 //设置新cookie function setCookie(name,value,duration){ var date = new Date(); date.setTime( ...
- 【数据库】MySQL 复制表结构
介绍 有时候我们需要原封不动的复制一张表的表结构来生成一张新表,MYSQL提供了两种便捷的方法. 例: CREATE TABLE tb_base( id INT NOT NULL PRIMARY KE ...
- Redis学习笔记一:Redis安装
Redis安装 1.下载进入redis官网下载redis-xxx.tar.gz包 2.将redis-xxx.tar.gz拷贝到Linux某一目录下并对其进行解压 tar -zxvf Redis-xxx ...
- 常用Transformation算子
map 产生的键值对是tupple, split分隔出来的是数组 一.常用Transformation算子 (map .flatMap .filter .groupByKey .reduc ...
- CF1100E
i207M给的题 省选前-小题解合集 给定一张有向图,每条边有边权.你可以花费边权的代价反转一条边,使得原图中没有环.最小化反转的边权的最大值. 首先二分,然后考虑判定. 转化为有些边可以翻转,有些边 ...