【Explain】mysql之explain详解(分析索引的最佳使用)
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain 这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。所以我们 深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用。 (QEP:sql生成一个执行计划query Execution plan)

mysql> explain select * from servers;
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | servers | ALL | NULL | NULL | NULL | NULL | 1 | NULL |
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
1 row in set (0.03 sec)
expain出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra,下面对这些字段出现的可能进行解释:
一、 id
我的理解是SQL执行的顺序的标识,SQL从大到小的执行
1. id相同时,执行顺序由上至下
2. 如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
3.id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
二、select_type
示查询中每个select子句的类型
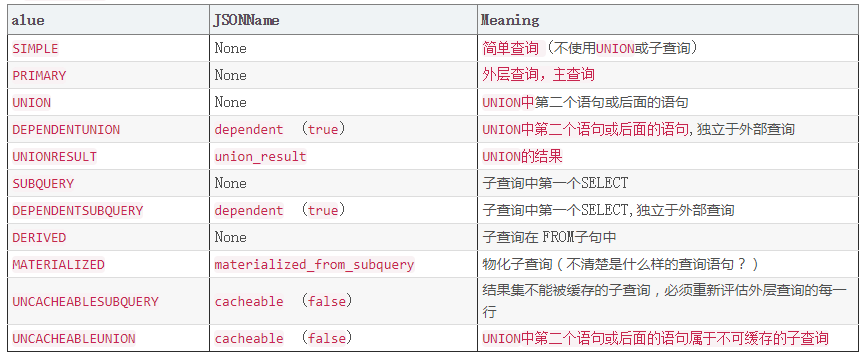
(1) SIMPLE(简单SELECT,不使用UNION或子查询等)
(2) PRIMARY(查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION(UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT(UNION的结果)
(6) SUBQUERY(子查询中的第一个SELECT)
(7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,取决于外面的查询)
(8) DERIVED(派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
如下:
三、table
有可能是
实际的表名 如select * from t1;
表的别名 如 select * from t2 as tmp;
derived 如from型子查询时(来自于子查询的派生表)
null 直接计算得结果,不用走表,例如select 1+2
显示这一行的数据是关于哪张表的,有时不是真实的表名字,看到的是derivedx(x是个数字,我的理解是第几步执行的结果)
mysql> explain select * from (select * from ( select * from t1 where id=2602) a) b;
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | <derived3> | system | NULL | NULL | NULL | NULL | 1 | |
| 3 | DERIVED | t1 | const | PRIMARY,idx_t1_id | PRIMARY | 4 | | 1 | |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
四、type(重要)
表示MySQL在表中找到所需行的方式,又称“访问类型”。是分析”查数据过程”的重要依据
常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行 ,逐行做全表扫描.,运气不好扫描到最后一行. (说明语句写的很失败)
index: Full Index Scan,index与ALL区别为index类型只遍历索引树,相当于data_all index 扫描所有的索引节点,相当于index_all
range:只检索给定范围的行,使用一个索引来选择行,能根据索引做范围的扫描
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值,通过索引列,可以直接引用到某些数据行
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
const、system、NULL指查询优化到常量级别, 甚至不需要查找时间.
五、possible_keys
注意: 系统估计可能用的几个索引,但最终,只能用1个.
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询
六、Key
key列显示MySQL实际决定使用的键(索引)
如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
七、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
不损失精确性的情况下,长度越短越好
八、ref
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
九、rows
表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
有时候结果集中多一列filtered
为什么Mysql explain extended中的filtered列值总是100%
执行Mysql的explain extended的输出会比单纯的explain多一列filtered(MySQL .7缺省就会输出filtered),它指返回结果的行占需要读到的行(rows列的值)的百分比。按说filtered是个非常有用的值,因为对于join操作,前一个表的结果集大小直接影响了循环的次数。但是我的环境下测试的结果却是,filtered的值一直是100%,也就是说失去了意义。 参考下面mysql .6的代码,filtered值只对index和all的扫描有效(这可以理解,其它场合,通常rows值就等于估算的结果集大小。)。
十、Extra
性能从好到坏:useing index>usinh where > using temporary | using filesort
该列包含MySQL解决查询的详细信息,有以下几种情况:
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询
Using filesort:MySQL中无法利用索引完成的排序操作称为“文件排序”
Using where:列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
useing index代表索引覆盖,就是查询的列正好在索引中,不用回物理行查询数据。参考http://www.cnblogs.com/qlqwjy/p/8593076.html
执行Mysql的explain extended的输出会比单纯的explain多一列filtered(MySQL .7缺省就会输出filtered),它指返回结果的行占需要读到的行(rows列的值)的百分比。按说filtered是个非常有用的值,因为对于join操作,前一个表的结果集大小直接影响了循环的次数。但是我的环境下测试的结果却是,filtered的值一直是100%,也就是说失去了意义。 filtered值只对index和all的扫描有效(这可以理解,其它场合,通常rows值就等于估算的结果集大小。)
总结:
• EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
• EXPLAIN不考虑各种Cache
• EXPLAIN不能显示MySQL在执行查询时所作的优化工作
• 部分统计信息是估算的,并非精确值
• EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划。
【Explain】mysql之explain详解(分析索引的最佳使用)的更多相关文章
- 【详细解析】MySQL索引详解( 索引概念、6大索引类型、key 和 index 的区别、其他索引方式)
[详细解析]MySQL索引详解( 索引概念.6大索引类型.key 和 index 的区别.其他索引方式) MySQL索引的概念: 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分 ...
- Mysql加锁过程详解(8)-理解innodb的锁(record,gap,Next-Key lock)
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- MySQL数据库优化详解(收藏)
MySQL数据库优化详解 mysql表复制 复制表结构+复制表数据mysql> create table t3 like t1;mysql> insert into t3 select * ...
- MySQL 执行计划详解
我们经常使用 MySQL 的执行计划来查看 SQL 语句的执行效率,接下来分析执行计划的各个显示内容. EXPLAIN SELECT * FROM users WHERE id IN (SELECT ...
- Mysql加锁过程详解(5)-innodb 多版本并发控制原理详解
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(1)-基本知识
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql 三大特性详解
Mysql 三大特性详解 Mysql Innodb后台线程 工作方式 首先Mysql进程模型是单进程多线程的.所以我们通过ps查找mysqld进程是只有一个. 体系架构 InnoDB存储引擎的架构如下 ...
- MySQL关闭过程详解和安全关闭MySQL的方法
MySQL关闭过程详解和安全关闭MySQL的方法 www.hongkevip.com 时间: -- : 阅读: 整理: 红客VIP 分享到: 红客VIP(http://www.hongkevip.co ...
- HttpRuntime详解分析
HttpRuntime详解分析(上) 文章内容 从上章文章都知道,asp.net是运行在HttpRuntime里的,但是从CLR如何进入HttpRuntime的,可能大家都不太清晰.本章节就是通过深入 ...
- Mysql加锁过程详解(9)-innodb下的记录锁,间隙锁,next-key锁
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
随机推荐
- 【Java】自动获取某表某列的最大ID数
使用场景: 当需要往数据库插入数据时,表的主键需要接着已经有的数据后面进行自增.比如已经wq_customer表里,主键为TBL_ID,如果是空表,那么插入的数据TBL_ID设置为1,如果已经有n条数 ...
- QoS专题-第3期-QoS实现之报文简单分类与标记
QoS实现之报文简单分类与标记 上一期专题我们讲到,MQC中的流分类可以实现报文的分类,流行为可以对报文进行重标记,从而实现对流量的精细化差分服务.而优先级映射则可以根据802.1p优先级.DSCP优 ...
- 洛谷 P2951 [USACO09OPEN]捉迷藏Hide and Seek
题目戳 题目描述 Bessie is playing hide and seek (a game in which a number of players hide and a single play ...
- [CF1103B]Game with modulo
题目大意:交互题,有一个数$a(a\leqslant10^9)$,需要猜出它的值,一次询问为你两个数字$x,y(x,y\in[0,2\times10^9])$: 若$x\bmod a\geqslant ...
- 关于kali linux系统的简单工具
Linux系统中关于几个重要目录的原英文解释: /etc/: Contains configuration files of the installed tools /opt/: Contains M ...
- [NOIP2016 D1T3]换教室 【floyd+概率dp】
题目描述 对于刚上大学的牛牛来说,他面临的第一个问题是如何根据实际情况申请合适的课程. 在可以选择的课程中,有 2n2n 节课程安排在 nn 个时间段上.在第 ii(1 \leq i \leq n1≤ ...
- 解题:POI 2016 Nim z utrudnieniem
题面 出现了,神仙题! 了解一点博弈论的话可以很容易转化题面:问$B$有多少种取(diu)石子的方式使得取后剩余石子异或值为零且取出的石子堆数是$d$的倍数 首先有个暴力做法:$dp[i][j][k] ...
- php 阿拉伯数字转中文
function numToWord($num){$chiNum = array('零', '一', '二', '三', '四', '五', '六', '七', '八', '九');$chiUni = ...
- 三年java面试题
前言: 楼主毕业三年,从大学时期就开始一直从事java web方面的开发.我在去年的今天有一篇帖子:两年java面试经验.经历了一年的上班,成长了很多.今年因为某些原因辞职了.从2月底辞职,到3月初, ...
- angular 的 @Input、@Output 的一个用法
angular 使用 @input.@Output 来进行父子组件之间数据的传递. 如下: 父元素: <child-root parent_value="this is parent ...