第八课:不一样的链表 linux链表设计哲学 5星级教程
这一课最后实现的链表,和普通链表不同,借鉴了linux内核链表的思想,这也是企业使用的链表。
基础介绍:
顺序表的思考
顺序表的最大问题是插入和删除需要移动大量的元素!
如何解决?
A:在线性表数据元素之间空出位置,为以后插入使用。
B:这样不行!中间无论空多少都有可能用完!
A:那不是无解了嘛!
B:我觉得让每个元素都知道他的下个元素就行了,哪有空插哪
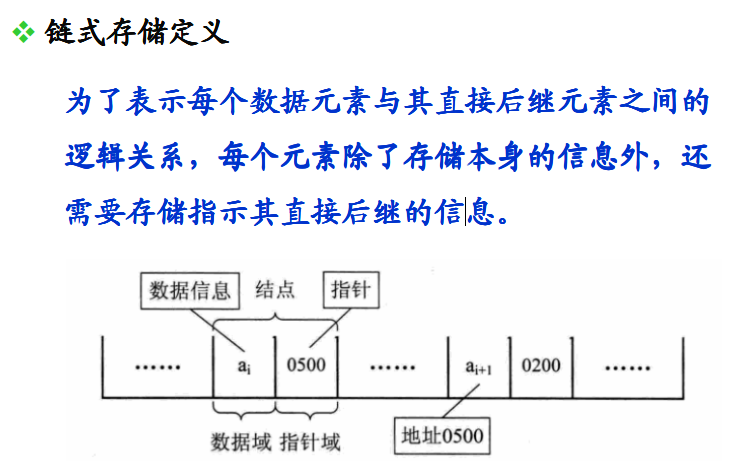
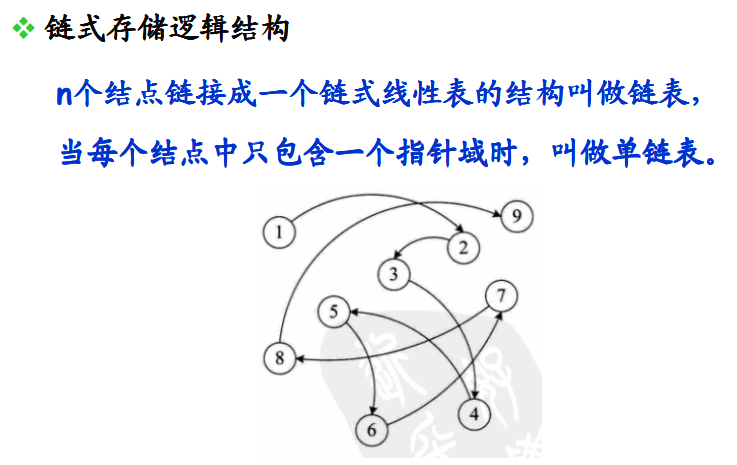
链表的基本概念
表头结点
链表中的第一个结点,包含指向第一个数据元素的指针以及链表自身的一些信息
数据结点
链表中代表数据元素的结点,包含指向下一个数据元素的指针和数据元素的信息
尾结点
链表中的最后一个数据结点,其下一元素指针为空,表示无后继 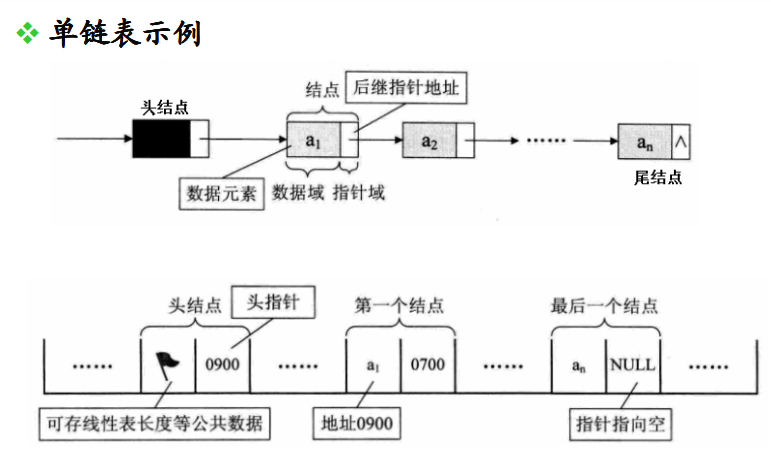
看看经典书籍《c和指针》上构建的链表方式:

这也是我们说的普通链表,但是,linux操作系统却不使用这种链表,为什么呢?因为普通链表的局限性,可操作性,维护性太差,所以,我们借鉴linux内核的思想,完成链表,这也是企业级别的做法。
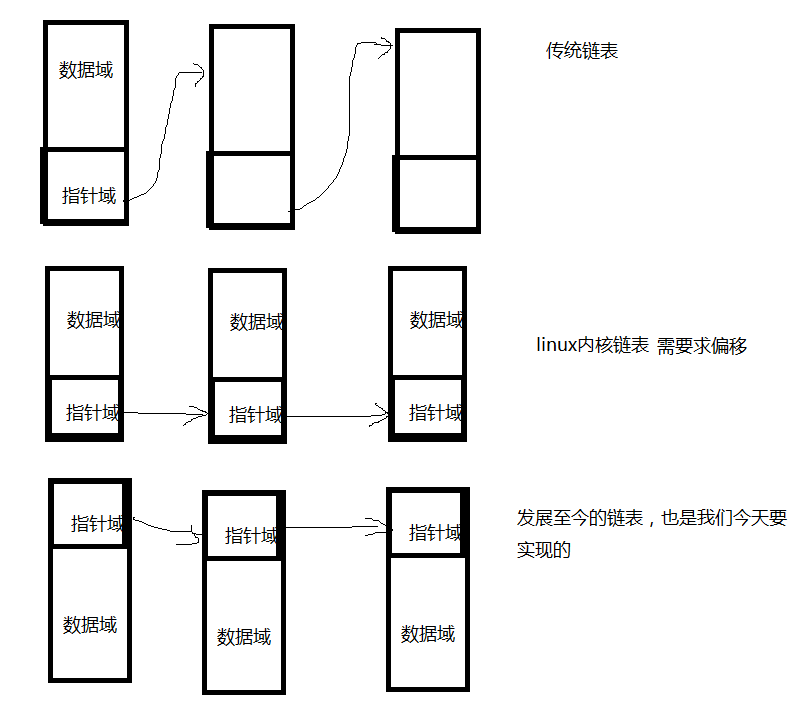
我们下面要实现的链表,没有数据域,只有指针域,数据域是外部给的,这里的链表,可以应对外界任何数据,而普通链表则不行。既然普通链表不能包含外事万物,我们就用万事万物来包含我们的链表,这就是linux内核链表思想。但是linux内核链表还需要求偏移,因为内核链表的指针域放在数据结构最下面,这样想知道指针域上面数据需要根据指针求偏移,于是有了那老生常谈的两个宏,后面随笔会分析。经过时代的进步,现在要实现的链表,是改进后的linux内核链表,把指针域放在结构最上方,这样就不用大费周章求偏移了,这也是今天我们要实现的链表。

上面的Value结构体,是用户,使用这个链表的人定义的,这个结构只有一个要求,就是定义一个header节点,后面的数据可以任意,上面是int v,我们可以随意增加属性double ,float,char数据,这是普通链表做不到的。
头文件必知声明:
typedef void LinkList;
typedef unsigned int Tleng;
typedef struct _tag_LinkListNode
{
struct _tag_LinkListNode* next;
}LinkListNode;
typedef struct _tag_LinkList
{
LinkListNode header;
Tleng length;
} TLinkList;
LinkListNode类型定义的对象,就是链表的指针域,这个指针指向一个自身类型的结构:

TLinkList类型定义的是我们的头结点,包含一个指针域和链表的长度:
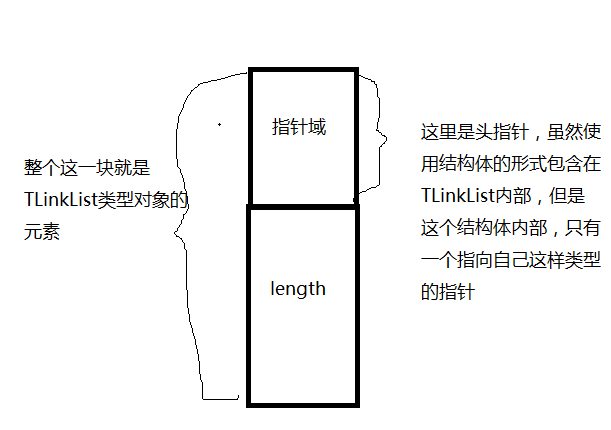
是的,就是这样奇怪,没有数据域。我们自己定义的数据结构,不能包含万事万物,那么我们就用万事万物来包含我们的结构。数据域是由使用这个链表的人来给出的,而不是设计这个链表的人,这样的链表,不管你想存放何种数据类型,我们都可以做到。
首先第一步,创建链表:
LinkList* LinkList_Create()
{
TLinkList* ret = (TLinkList*)malloc(sizeof(TLinkList)); if( ret != NULL )
{
ret->length = ;
ret->header.next = NULL;
}
return ret;
}
创建链表的函数,其实是创建链表头,里面包含一个链表长度信息和一个结构体(这个结构体只包含一个指向自身的指针)。所以,在实现部分,我们只是malloc TLinkList类型的大小,创建的链表需要被返回,返回什么类型合适呢?根据用户的需求不同,返回的类型就不同,所以我们返回一个void *类型的指针给使用链表的人,使用者知道自己定义的数据类型是什么,只用把该函数返回的void *强制转化成自己定义的类型就可以了。
销毁链表:
void LinkList_Destroy(LinkList* list)
{
if(list!=NULL)//如果非空
{
free(list);//释放内存
list=NULL;//指针同时置成NULL,能避免一些误操作
}
}
虽然我们为void定义了别名LinkList,但是这里却没有使用,这是因为这个返回值void,改为LinkList不能表现其意义,还会让人阅读更困难一点,所以直接用void。而之前的创建函数返回LinkList *是有意义的,这代表我们想返回一个指向某种链式结构的指针,虽然它本质也为void *。
清空链表:
void LinkList_Clear(LinkList* list)
{
TLinkList* sList = (TLinkList*)list; if( sList != NULL )
{
sList->length = ;
sList->header.next = NULL;
}
}
你可能会问,这算哪门子的清空,至少给我把数据域的数据置成0什么的吧。但是我们的链表,清空就是这样,让它回到最初的状态,也就是创建它的时候的状态。
得到链表的长度:
int LinkList_Length(LinkList* list)
{
TLinkList* sList = (TLinkList*)list;
int ret = -; if( sList != NULL )
{
ret = sList->length;
} return ret;
}
这里要注意,我们的length定义成的无符号类型,所以,当链表的长度超过了int所能表达的最大正数值,那么这个函数的返回将得到不正确的值。
链表的插入:
//向一个链表list,在pos位置插入新元素 node
//接受使用链表的人传入一个新元素,这个传入的新元素就是node的类型,由于我们要做到类型无关,需要取得用户自定义
//数据的地址,在实现该函数时,我们采用的是 LinkListNode *也就是我们的指针域,这个指针指向用户定义的数据类型,但必须是结构体类型的 int LinkList_Insert(LinkList* list, LinkListNode* node, int pos)
{
TLinkList* sList = (TLinkList*)list;//把链表从void *强制转化成TLinkList*,现在我们的角色变成了实现这个函数的人
//我们知道链表的类型是TLinkList*,使用链表的人不用知道
//首先确保链表sList不为空,并且插入的文职要大于等于0,而且插入元素node也不能为空
int ret = (sList != NULL) && (pos >= ) && (node != NULL);
int i = ; if( ret )
{
LinkListNode* current = (LinkListNode*)sList;//借助辅助指针变量current,要插入,必然要操作数据域相关的内存空间
//而数据域是通过node参数传入的,我们其实只用关心如何串联我们的指针域,所以这里使用node类型(LinkListNode*)的辅助变量
//然而我们的辅助指针变量不得不先指向头结点,代替头结点做移动操作,所以需要把头结点
//强制转换成LinkListNode*,以便我们辅助指针变量遍历链表,为什么有头结点了还要引入辅助
//指针变量,如果这样问,你的c基础还需要加强,在很多c库函数额实现中我们大都引入了辅助指针
//来代替原始指针操作,这样肯定是有原因的。这里如果直接用链表头去遍历,第一次遍历倒是可以
//但是第二次呢?你的头结点移动了,就回不到最初了,这才需要引入辅助变量,以保证头结点可完整遍历链表
for(i=; (i<pos) && (current->next != NULL); i++)//插入,先看下面的图。然后就明白这里了,记住,指针指向谁,就把谁的地址给这个指针
{
current = current->next;
}
node->next = current->next;
current->next = node; sList->length++;
} return ret;
}
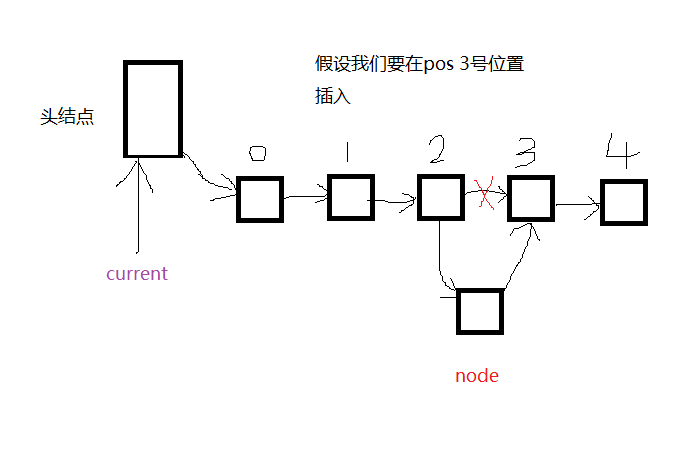
假设我们在pos=3处插入,此时我们首先应该使node指向3,再让2指向node,不能反过来先让2指向node,再让node指向3。原因很简单,单向链表,每个节点保存后继位置的地址,2的指针域保存了3的地址,如果我们先让2指向node,我们就会丢失3的地址。
下一步,辅助指针变量current需要指向2,为什么是2,因为我们要得到3的地址,必须通过2的指针域。
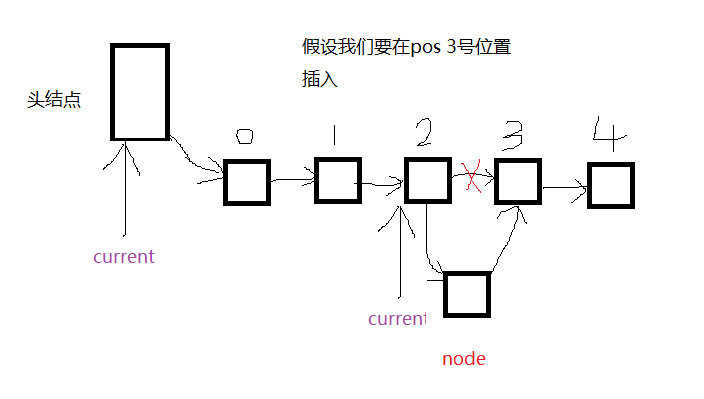
而current从头结点移动到2,刚好需要移动pos(3)次。所以,再看我们插入算法的for循环处。
for(i=; (i<pos) && (current->next != NULL); i++)//插入,先看上面的图。然后就明白这里了,记住,指针指向谁,就把谁的地址给这个指针
{
//辅助指针变量移动0——pos-1次,共计pos次,符合我们图像的分析
//并且保证current的指针域不是NULL,如果是NULL,证明不是合法的,因为我们是为了取得curren->next,并让node指向它
//最后就是移动辅助指针变量current,让current最后指向要插入地方的前一个节点,因为这个节点保存了pos位置的地址
current = current->next;
}
//用列举的pos=3做说明
//先让node指向3,再次重复,指针指向谁,就把谁的地址给它
//那么我们需要把3的地址给node,而3的地址存放在2中,而此时的2,正是current->next,current指向节点2,节点2的next域存放3的地址
node->next = current->next;
//然后让2指向node,所以我们需要把node地址给2
current->next = node;
//插入一个,长度加1
sList->length++;
}
获取链表pos位置的地址:
LinkListNode* LinkList_Get(LinkList* list, int pos)
{
TLinkList* sList = (TLinkList*)list;
LinkListNode* ret = NULL;
int i = ;
//保证链表不能为空,获取位置应该大于等于0并且小于链表的长度,为什么不能等于链表的长度?pos下标是
//从0 开始的,能得到pos下标为0,那么length已经是1了,链表长度总比最大pos位置大1
//故,pos严格小于length
if( (sList != NULL) && ( <= pos) && (pos < sList->length) )
{
LinkListNode* current = (LinkListNode*)sList;//这里和插入一样,引入辅助变量current
//移动pos次,此时current指向pos前一个位置,但是这个位置正好保存了pos位置的地址
for(i=; i<pos; i++)
{
current = current->next;
}
//把current的next指向位置返回出去,这个返回的位置正是pos位置
ret = current->next;
} return ret;
}
有了插入算法的分析,这个获取算法就不过多解释了。忍不住多说几句:函数返回类型LinkListNode*,为什么是这个类型?为了得到pos位置的数据域内容,我们必须要知道用户定义结构体的地址,而这个地址,也同样是用户定义结构体第一个元素的地址,也就是我们这里的指针域,即LinkListNode*类型,所以get函数返回LinkListNode*类型,然后让一个用户定义的结构体指针指向get的返回值,就可以得到用户数据域了。
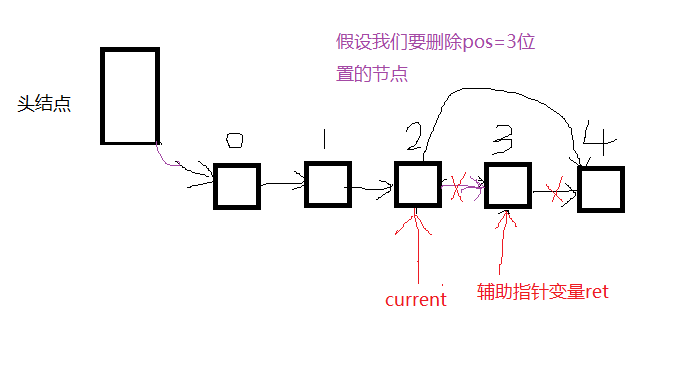
删除pos位置的节点:
LinkListNode* LinkList_Delete(LinkList* list, int pos)
{
TLinkList* sList = (TLinkList*)list;
LinkListNode* ret = NULL;
int i = ;
//链表非空,删除的位置大于等于0,并且小于length
if( (sList != NULL) && ( <= pos) && (pos < sList->length) )
{
LinkListNode* current = (LinkListNode*)sList;
//移动pos次
for(i=; i<pos; i++)
{
current = current->next;
}//执行完current指向pos前一个位置
//把pos位置的地址给辅助变量ret,要删除就要先保存现场,和插入一样的道理
ret = current->next;//ret现在是指向pos位置的
//断开pos位置和前后的联系
//让pos前一个位置(current->next )指向pos后一个位置(ret->next;)
//不要被next名字误导了,虽然名为next,但是实际还是存放在当前结构中的,只是当前结构中的next域保存了下一个位置的地址
//单链表,每个节点保存它的后继信息
current->next = ret->next;
//删除一个,长度减1
sList->length--;
} return ret;
}
main函数模型构建 1:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "LinkList.h" struct Value
{
LinkListNode header;
double v;
}; typedef struct _tag_Everythings
{
LinkListNode header;
int a;
double b;
char *p;
}Everythings; int main(int argc, char *argv[])
{
int i = ;
LinkList* list = LinkList_Create(); struct Value v1;
struct Value v2;
struct Value v3;
struct Value v4;
struct Value v5; v1.v = 1.1;
v2.v = 2.1;
v3.v = 3.1;
v4.v = 4.1;
v5.v = 5.1; LinkList_Insert(list, (LinkListNode*)&v1, LinkList_Length(list));
LinkList_Insert(list, (LinkListNode*)&v2, LinkList_Length(list));
LinkList_Insert(list, (LinkListNode*)&v3, LinkList_Length(list));
LinkList_Insert(list, (LinkListNode*)&v4, LinkList_Length(list));
LinkList_Insert(list, (LinkListNode*)&v5, LinkList_Length(list)); printf("插入的元素:\n");
for(i=; i<LinkList_Length(list); i++)
{ struct Value* pv = (struct Value*)LinkList_Get(list, i); printf("%f\n", pv->v);
} printf("删除的元素:\n");
while( LinkList_Length(list) > )
{ struct Value* pv = (struct Value*)LinkList_Delete(list, ); printf("%f\n", pv->v);
} LinkList_Destroy(list);
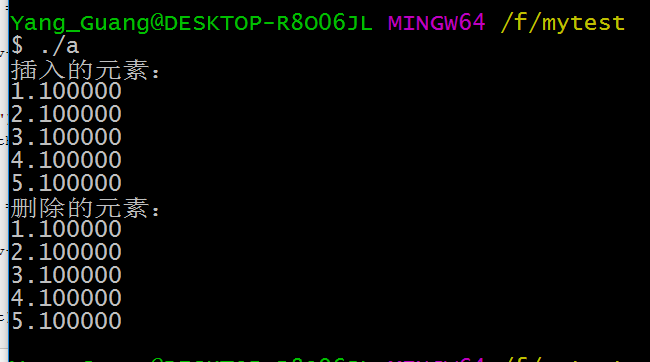
用户自己开辟的空间,我们链表负责链接指针域,此时我们插入的是基本元素double,下一个我们插入更多元素:
main函数模型构建 2:
Everythings e1,e2,e3;
LinkList* Elist=LinkList_Create();
e1.a=;e1.b=1.1;e1.p=(char *)malloc();strcpy(e1.p,"Hi ");
e2.a=;e2.b=2.1;e2.p="nice to meet you!";
e3.a=;e3.b=3.1;e3.p=(char *)malloc();strcpy(e3.p,"O(∩_∩)O哈哈~");
LinkList_Insert(Elist, (LinkListNode*)&e1, LinkList_Length(Elist));
LinkList_Insert(Elist, (LinkListNode*)&e2, LinkList_Length(Elist));
LinkList_Insert(Elist, (LinkListNode*)&e3, LinkList_Length(Elist)); printf("插入的元素:\n");
for(i=; i<LinkList_Length(Elist); i++)
{ Everythings* pe = ( Everythings*)LinkList_Get(Elist, i); printf("a=%d,b=%f,p=%s\n", pe->a,pe->b,pe->p);
} printf("删除的元素:\n");
while( LinkList_Length(Elist) > )
{ Everythings* pe= ( Everythings*)LinkList_Delete(Elist, ); printf("a=%d,b=%f,p=%s\n", pe->a,pe->b,pe->p);
}
LinkList_Destroy(Elist);
free(e1.p);//用户开辟的堆空间,需要用户自行释放
free(e3.p);
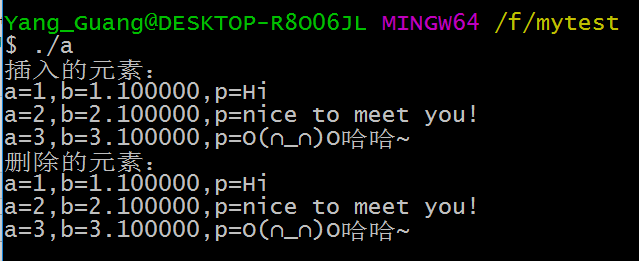
这里需要注意,用户malloc的空间,理应由用户自己释放,还有就是,在链表框架不做任何改动的情况下,我们就又实现了和第一种方式创建的对象所不同的链表。
main函数模型构建 3:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "LinkList.h" struct Value
{
LinkListNode header;
double v;
}; typedef struct _tag_Everythings
{
LinkListNode header;
int a;
double b;
char *p;
}Everythings; int main(int argc, char *argv[])
{
int i = ;
LinkList* Both=LinkList_Create(); struct Value v1; v1.v = 1.1;
struct Value v2; v2.v = 2.1;
struct Value v3; v3.v = 3.1;
struct Value v4; v4.v = 4.1;
struct Value v5; v5.v = 5.1; Everythings e1,e2,e3; e1.a=;e1.b=1.1;e1.p=(char *)malloc();strcpy(e1.p,"Hi ");
e2.a=;e2.b=2.1;e2.p="nice to meet you!";
e3.a=;e3.b=3.1;e3.p=(char *)malloc();strcpy(e3.p,"O(∩_∩)O哈哈~"); LinkList_Insert(Both, (LinkListNode*)&v1, LinkList_Length(Both));
LinkList_Insert(Both, (LinkListNode*)&v2, LinkList_Length(Both));
LinkList_Insert(Both, (LinkListNode*)&v3, LinkList_Length(Both));
LinkList_Insert(Both, (LinkListNode*)&v4, LinkList_Length(Both));
LinkList_Insert(Both, (LinkListNode*)&v5, LinkList_Length(Both));
LinkList_Insert(Both, (LinkListNode*)&e1, LinkList_Length(Both));
LinkList_Insert(Both, (LinkListNode*)&e2, LinkList_Length(Both));
LinkList_Insert(Both, (LinkListNode*)&e3, LinkList_Length(Both)); printf("插入的元素:\n");
for(i=; i<; i++)
{ struct Value* p1 = ( struct Value*)LinkList_Get(Both, i); printf("v=%f\n",p1->v);
}
for(i=; i<+; i++)
{ Everythings* p2 = ( Everythings*)LinkList_Get(Both, i); printf("a=%d,b=%f,p=%s\n", p2->a,p2->b,p2->p); } printf("删除的元素:\n"); for(i=;i>;i--)
{ struct Value* pv = (struct Value*)LinkList_Delete(Both, ); printf("%f\n", pv->v); } for(i=;i>;i--)
{ Everythings* pe= ( Everythings*)LinkList_Delete(Both, ); printf("a=%d,b=%f,p=%s\n", pe->a,pe->b,pe->p);
}
LinkList_Destroy(Both); free(e1.p);
free(e3.p); return ;
}
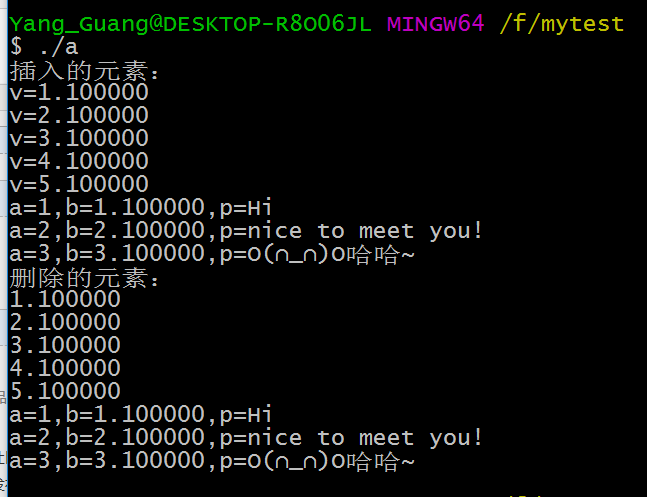
这里直接把两个结构同时连接进入了我们的链表,但是这样一来,遍历打印的时候是很不方便的,但仅仅是想利用循环打印而已,如同上面的例子一样,如果你真的是插入的对象全都是大小类型不同的,也不用循环遍历打印,而是直接通过LinkList_Get函数,指定要获取的位置,而在指定要获取的位置前,调用者必须知道你想要获取的结构体类型是什么。
Summary:
传统链表的局限性使得企业开发的维护变得困难,而今天我们实现的链表,普通链表是达不到这样的功能的,这也是现在企业中使用这样链表的原因,因为这样的链表,维护性可以得到保障。linux的设计哲学,既然传统链表包含不了万事万物,就让万事万物来包含我们的链表,故,在使用这样的链表的时候,一定也必须加上一个头,LinkListNode header;而且这个表头必须放在你数据对象所在结构的最上面,因为我们取用户数据对象的地址,这个地址就是我们表头的地址,这是利用了结构体首元素地址和结构体地址一样的特性。那么我们也就只用遵循这个协议,把用户的数据域用结构体表示,并把表头放在这个结构体的第一个位置,就可以使用可操作性如此强的链表,何乐而不为呢?
细枝末节:
还有一个需要注意的地方,虽然不是必须,但是应该这样去做。
typedef struct _tag_LinkList
{
LinkListNode header;
Tleng length;
} TLinkList;
这个类型声明,应该放在链表的源文件中,不应该放在链表的头文件中。因为源文件的实现,我们不应该让使用这个链表的知道,如同c标准库一样,给你个头文件和函数原型,你调用就行,这样我们可以把源文件做成一个动态库或者其他二进制文件进行封装,用户只用调用我们的接口,程序员不应该过多展示和接口无关的东西。
第八课:不一样的链表 linux链表设计哲学 5星级教程的更多相关文章
- 潭州课堂25班:Ph201805201 django 项目 第八课 注册功能分析,图片验证码视图设计 (课堂笔记)
1,用户名 是否已注册 2,手机号 是否被注册 3,图形验证码 4,短信验证码, 5,验证成功后,向后台提交数据:用户名,密码,手机号,短信验证 要写这五个视图, 获取图形验证码,请求方式:g ...
- Kali Linux Web 渗透测试视频教程— 第八课 nessus
Kali Linux Web 渗透测试视频教程— 第八课 nessus 文/玄魂 视频课程地址:http://edu.51cto.com/course/course_id-1887.html 目录 n ...
- 【C语言探索之旅】 第二部分第八课:动态分配
内容简介 1.课程大纲 2.第二部分第八课: 动态分配 3.第二部分第九课预告: 实战“悬挂小人”游戏 课程大纲 我们的课程分为四大部分,每一个部分结束后都会有练习题,并会公布答案.还会带大家用C语言 ...
- 【C语言探索之旅】 第一部分第八课:第一个C语言小游戏
内容简介 1.课程大纲 2.第一部分第八课:第一个C语言小游戏 3.第一部分第九课预告: 函数 课程大纲 我们的课程分为四大部分,每一个部分结束后都会有练习题,并会公布答案.还会带大家用C语言编写 ...
- Python第八课学习
Python第八课学习 www.cnblogs.com/resn/p/5800922.html 1 Ubuntu学习 根 / /: 所有目录都在 /boot : boot配置文件,内核和其他 linu ...
- 《Linux内核设计与实现》第八周读书笔记——第四章 进程调度
<Linux内核设计与实现>第八周读书笔记——第四章 进程调度 第4章 进程调度35 调度程序负责决定将哪个进程投入运行,何时运行以及运行多长时间,进程调度程序可看做在可运行态进程之间分配 ...
- BeagleBone Black第八课板:建立Eclipse编程环境
BBB第八课板:建立Eclipse编程环境 最近建立了一个新的编程环境.感觉很方便,给大家分享.除了先前BBB董事会远程桌面直接写shell脚本或C外部程序,经Debain 7.5根据该制度还试图用编 ...
- Linux内核设计第八周 ——进程的切换和系统的一般执行过程
Linux内核设计第八周 ——进程的切换和系统的一般执行过程 第一部分 知识点总结 第二部分 实验部分 1.配置实验环境,确保menu内核可以正常启动 2.进入gdb调试,在shedule和conte ...
- NeHe OpenGL教程 第四十八课:轨迹球
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
随机推荐
- go语言基础之函数有多个返回值
1.函数有多个返回值 示例1: package main //必须有一个main包 import "fmt" //go推荐用法 func myfunc01() (int, int, ...
- go语言基础之字符串类型 和 字符与字符串类型的区别
1.字符串类型 示例1: package main //必须有一个main包 import "fmt" func main() { var str1 string str1 = & ...
- css hack 和问题
浏览器特定的选择 当你想改变一个样式在一个浏览器而不是其他这些选择是非常有用的. IE 6及以下 * html {} IE 7及以下 *:first-child+html {} * htm ...
- MSSQL 触发器 暂停 和 启动
开启关闭触发器 禁用: ALTER TABLE member DISABLE TRIGGER trig1 GO 恢复: ALTER TABLE member ENABLE TRIGGER trig1 ...
- Nginx 内嵌lua脚本,结合Redis使用
0x00 Nginx 内嵌Lua脚本有下面特点: 20k个并发连接 Lua脚本能够在Nignx 11个层次的不同层次发挥作用,扩展Ngnix功能 Lua速度极快(寄存器指令) 0x01 应用场景 在w ...
- 开源工作流CCBPM中关于解决谷歌等浏览器silverlight的问题
CCBPM的流程设计器和表单设计器.是通过silverlight实现的. 有些用户和学习者在安装完CCFlow,执行流程设计器时,常常会出现提示安装silverlight.明明已经安装了,为什么还会出 ...
- Python网络爬虫 - 3. 异常处理
handle_excpetion.py from urllib.request import urlopen from urllib.error import HTTPError from bs4 i ...
- Failed to initialize storage module: user 的解决方式
网上提供了一种解决方法就是在session_start()前把session的存储方式改为files,即加入以下一句代码 if (ini_get('session.save_handler') !== ...
- java学习笔记2015-6-5
今天晚上不须要不论什么编译器 记事本编写代码 1.安装JDK配置 2.JDK JRE的关系 3.基本的语法 常量 变量 数据类型 逻辑运算符 流程控制语句 4.小的练习 问题 5.课后作业 ...
- java反射--获取成员变量信息
获取成员变量信息 代码及说明: public static void printFieldMessage(Object obj) { //要获取类的信息,首先要获取类的类类型 Class c=obj. ...