day3 集合set()实例分析
集合,我们在高中的时候专门学习过集合,并集,交集,差集等,下面来看一下集合的定义,如下:
集合(简称集)是数学中一个基本概念,它是集合论的研究对象,集合论的基本理论直到19世纪才被创立。最简单的说法,即是在最原始的集合论
——朴素集合论中的定义,集合就是“确定的一堆东西”。集合里的“东西”,叫作元素。
由一个或多个确定的元素所构成的整体叫做集合。若x是集合A的元素,则记作x∈A。集合中的元素有三个特征:1.确定性(集合中的元素必须是
确定的) 2.互异性(集合中的元素互不相同。例如:集合A={1,a},则a不能等于1) 3.无序性(集合中的元素没有先后之分),如集合{3,4,5}和
{3,5,4}算作同一个集合。
我们知道,集合具有互异性,集合中的每个元素都是不同的。而且集合是无序的。与字典一样,没有顺序可言,并且集合中的元素都是确定的。我们来验证一下集合的形式。
集合:(1)访问速度快;(2)天生解决了重复性的问题。
首先,互异性:
>>> s1 = set([11,22,33])
>>> s1
{33, 11, 22}
>>> s1.add(11)
>>> s1
{33, 11, 22}
>>> s1.add(33)
>>> s1
{33, 11, 22}
>>> s1.add(44)
>>> s1
{33, 11, 44, 22}
从上面我们可以看出,集合中的元素都是互异的,当我们向集合中添加相同的元素的时候,是程序虽然不会报错,但是集合里面不会出现两个相同元素的元素。如果集合中的元素是数字,那么只需键值。生成键--值列表。
确定性:
>>> s1.__contains__(11)
True
>>> s1.__contains__(12)
False
一个元素在集合中要么存在,要么不存在,因此,如果我们判断的时候,就只有真和假两种情况。
互异性:
我们知道,如果集合是互异性的,那么顺序不同元素相同的集合应该是相等的。那么就来验证一下:
>>> s1 = set([11,33,44,88])
>>> s2 = set([88,44,11,33])
>>> s1 == s2
True
从上面代码可以看出,集合s1和集合s2的元素相同,但是位置是不同的,但是判断是否相等的时候返回的是True,说明顺序不同元素相同的集合是同一个集合。
>>> dic = {"k1":"v1","k2":"v2","k1":"v1"}
>>> s3 = set(dic)
>>> s3
{'k1', 'k2'}
从上面代码可以看出,当set()集合里面的元素是集合是,生成的是键的集合。
下面来看看集合常用的方法:
1.add(self,*args,**kwargs)
def add(self, *args, **kwargs): # real signature unknown
"""
Add an element to a set.
This has no effect if the element is already present.
"""
pass
从上面源码中我们可以看出add(self,*args,**kwargs)是向集合中添加元素,Add an element to a set.作用是向集合中添加元素。
add(self,*args,**kwargs)是向集合中添加元素,我们学过了很多添加元素的方法。集合中添加元素的方法是add()。加入元素。
>>> s1 = {88, 33, 66, 11, 44}
>>> s1.add(77)
>>> s1
{33, 66, 11, 44, 77, 88}
>>> s1.add(66)
>>> s1
{33, 66, 11, 44, 77, 88}
从上面代码可以看出,add()是向结合中添加不同的元素。
2.clear(self,*args,**kwargs)
def clear(self, *args, **kwargs): # real signature unknown
""" Remove all elements from this set. """
pass
clear()是清楚集合中的元素,把集合中的所有元素都清楚,这种情况进场用来遍历结合之后重新生成集合元素。
>>> s2 = {88, 33, 11, 44}
>>> s2.clear() (1)清除集合中所有的元素。
>>> s2
set()
从上面,代码可以看出,clear()是清楚集合中的元素。如果集合中没有元素,那么表示形式为:set()空的集合。但是前面标识了这是一个什么样的空集合。set()避免与空字典,空列表,空元素表示形式一样而进行的区分。
clear(self)是用来清楚集合中的元素。字典中添加和清楚的方法,add(),clear().源代码写的是Remove all elements from this set.
3.copy(self,*args,**kwargs)
def copy(self, *args, **kwargs): # real signature unknown
""" Return a shallow copy of a set. """
pass
copy(self,*args,**kwargs)复制集合中的元素,产生新的一个内存地址,否则清除集合的时候,关联的其他变量也会被清除掉
set()
>>> s2.add(11)
>>> s2.add(22)
>>> s2.add(66)
>>> s2.add(44)
>>> s2
{66, 11, 44, 22}
>>> s3 = s2
>>> s3
{66, 11, 44, 22}
>>> s3.clear()
>>> s2
set()
我们知道,等号(=)只是进行关联,把一个变量关联到同一个元素的内存地址,两个变量公用一个地址。因此我们删除一个集合的元素的时候,另外一个集合也会收到影响,而使用copy()就不会发生这样的事情。
4.difference(self,*args,**kwargs)
def difference(self, *args, **kwargs): # real signature unknown
"""
Return the difference of two or more sets as a new set.
(i.e. all elements that are in this set but not the others.)
"""
pass
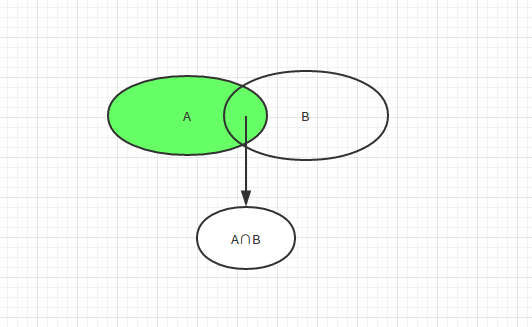
上面集合中,两个集合中间的部分为交集,两个集合减去各自部分的为不同的集合;如果是使用difference()那么,生成的集合是A - A∩B的集合。下面实例:
>>> s1 = {33, 66, 11, 44, 77, 88}
>>> s2
{99, 11, 44, 22}
>>> s1.difference(s2) = {88, 33, 66, 77}
>>> s2.difference(s1)
{99, 22}
>>> s3 = {33, 99, 22, 55}
>>> s1.difference(s2,s3)
{88, 66, 77}
从上面程序可以看出,集合s1.difference(s2)的集合表示方式为A - A∩B。我们可以使用difference比较多个集合不同,然后去差集的情况,不仅仅只是单纯的两个元素。A.difference(B,C,...N)等价于A - A∩B∩C∩...∩N。
5.difference_update(self,*args,**kwargs)
def difference_update(self, *args, **kwargs): # real signature unknown
""" Remove all elements of another set from this set. """
pass
difference_update(self,*args,**kwargs)s1.difference_update(s3)从集合s1中删除与s3集合中相同的元素。改变了集合s1,而difference()是生成一个新的集合,两者的结果是一样的,difference_update()是更新了集合s1,而difference()是新生成了一个集合,不改变原来的集合。
difference_update(self,*args,**kwargs)与difference()方法是一样的,不同的是,difference_update()更新集合之后把新生成的集合赋给原来的集合,而difference(self,*args,**kwargs)是生成一个新的集合,并不修改原来的集合。看下面的实例:
>>> s2 = {99, 11, 44, 22}
>>> s3 = {33, 99, 22, 55}
>>> s4 = {33, 66, 88, 11, 44, 77}
>>> s4.difference_update(s2,s3)
>>> s4
{66, 88, 77}
可以看出,上面方法difference_update()产生的集合与difference()产生的集合结果是一样的,只是difference_update()把新产生的结果更新给了原来的集合。
6.discard(self,*args,**kwargs)
def discard(self, *args, **kwargs): # real signature unknown
"""
Remove an element from a set if it is a member.(移除元素)
If the element is not a member, do nothing.
"""
pass
discard(self,*args,**kwargs)移除集合中的元素,如果这个元素不存在集合中,那么什么都不做。实例如下:discard的单词含义是丢弃,抛弃,丢弃集合中的元素。Remove an element from a set if it is a menber.If the element is not a member,do nothing.
>>> s1 = set([11,22,33,88,88,77,99,123,55,55])
>>> s1
{33, 99, 11, 77, 22, 55, 88, 123}
>>> s1.discard(55)
>>> s1
{33, 99, 11, 77, 22, 88, 123}
>>> s1.discard(666)
>>> s1
{33, 99, 11, 77, 22, 88, 123}
从上面程序可以看出,集合中的元素是不重复的,也没有顺序,无序性,因为我们输入的顺序改变了。当我们使用discard()删除元素时,如果这个成员在集合中,则删除;否则就什么也不做。do nothing.
7.pop(self,*args,**kwargs)
def pop(self, *args, **kwargs): # real signature unknown
"""
Remove and return an arbitrary set element.(移除)
Raises KeyError if the set is empty.
"""
pass
pop(self)从集合中弹出一个元素,并赋值给另外一个变量,实例如下:
>>> s1 = {'going', 'tom', 'alex', 'is', 'sb'}
>>> s1.pop()
'alex'
>>> s1
{'going', 'tom', 'is', 'sb'}
pop(self)不需要参数,表示的是从集合中移除一个元素,并赋值给一个新的变量,移除元素赋值,弹出,不想remove()是从集合中删除元素没有返回值。pop()源码是Remove and return an arbitrary set element.(移除)Raises KeyError if the set is empty.从集合中删除一个随意值,并且返回这个移除的随意值。如果集合是空的,则报错,显示KeyError类错误。由于集合的无序性,随机删除元素。不需要参数。TypeError: pop() takes no arguments (1 given)(pop()不需要参数)
>>> s1 = {33, 99, 11, 77, 22, 88, 123}
>>> s1.pop()
33
>>> s1.pop()
99
>>> s1.pop()
11
>>> s1.pop()
77
>>> s2 = set()
>>> s2.pop()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'pop from an empty set'
从上面可以看出,pop()是删除集合中的元素,当集合是空的时候,会报错,提示KeyError:'pop from an empty set'从一个空的列表删除元素。
8.remove(self,*args,**kwargs)
def remove(self, *args, **kwargs): # real signature unknown
"""
Remove an element from a set; it must be a member.
If the element is not a member, raise a KeyError.
"""
pass
remove(self,member)从集合中移除元素,没有返回值,删除集合中的值,remove(menber),实例如下:
>>> s1 = {'going', 'tom', 'is', 'sb'}
>>> s1.remove("is")
>>> s1
{'going', 'tom', 'sb'}
remove(menber)是从集合中移除元素,而pop()是从集合中弹出一个元素并赋值给新的变量。两者的区别在于,一个有返回值可以利用,而另外一个是没有返回值的。remove()的解释是Remove an element from a set;it must be a member.If the element is not a member,raise a KeyError.
从上面可以看出,remove()移除集合的成员的时候,如果这个成员不在集合中,则会报错,如果在则删除,与discard一样。
>>> s1 = {22, 88, 123}
>>> s1.remove(22)
>>> s1.remove(33)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 33
从上面可以看出,remove()是从集合中删除元素,如果在则删除,否则就会报错。
pop(self),remove(element),discard(element)都是删除集合中元素的方法,pop()是随机删除集合中的元素,不需要参数,并且有一个返回值;remove()是删除集合中指定的值,与discard()一样,不同的是,discard()删除指定的值的时候,如果这个值不存在,不会报错,什么都不做,而remove()则会报错。三种删除集合元素的方法。
9.intersection(self,*args,**kwargs)
def intersection(self, *args, **kwargs): # real signature unknown
"""
Return the intersection of two sets as a new set.(取交集,创建一个新的集合存放交集)
(i.e. all elements that are in both sets.)
"""
pass
intersection(s1,s2,s3,....,sn)取集合的交集,等价于s1∩s2∩s3∩...∩sn。
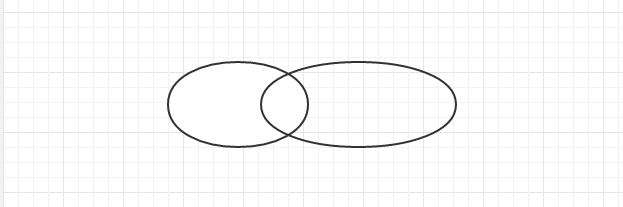
上面图中两个集合中间的部分就是两个集合的交集,intersection()下面来看两个实例,由于intersection()放回两个集合的交集并且生成一个新的集合(Return the intersection of two sets as a new set),我们去交集,并且定义一个参数接收这个新的集合。
>>> s1 = set([11,22,33,44,55,66])
>>> s2 = set([22,55,33])
>>> s3 = set([22,55,77,88])
>>> s4 = set([99,666])
>>> s1.intersection(s2,s3)
{22, 55}
>>> s1.intersection(s2,s3,s4)
set()
从上面可以看出,集合的参数是可以有多个的,并且,如果集合有交集,则返回交集;如果集合没有交集,则返回一个空的集合set().
10.intersection_update(self,*args,**kwargs)
def intersection_update(self, *args, **kwargs): # real signature unknown
""" Update a set with the intersection of itself and another.(取交集,修改原来set) """
pass
>>> s1 = {'zeng', 'geng', 'alex', 'sb'}
>>> s3 = {'marry', 'aoi', 'sb'}
>>> s1.intersection_update(s3)
>>> s1
{'sb'}
>>> s3
{'marry', 'aoi', 'sb'}
s1.intersection_update(s3)取集合s1和集合s3的交集,并把生成的交集元素放到集合s1中,删除两者不是集合的元素。如果两者没有交集则生成一个空的集合。intersection_update()与intersection()是一样的,只是intersection()生成了一个新的集合,而intersection_update()把新生成的集合赋给了原来的集合。(Update a set with the intersection of itself and another.)更新一个集合,是两个集合的交集。
11.isdisjoint(self,*args,**kwargs)
def isdisjoint(self, *args, **kwargs): # real signature unknown
""" Return True if two sets have a null intersection. """
"""判断是否有交集,如果没有交集,返回True.
pass
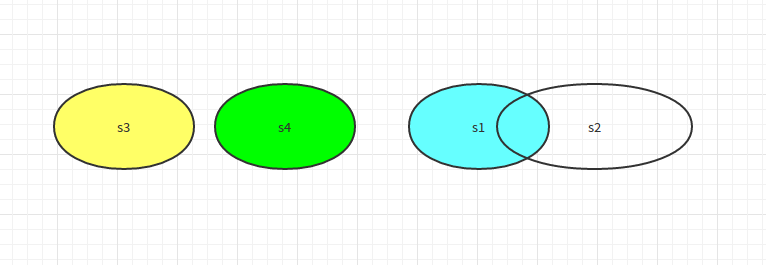
上图中,集合s3和s4没有交集,s1和s2有交集,isdisjoint()是判断集合是不是没有交集,如果没有交集,则返回True;否则如果有交集,则返回False。实例如下:
>>> s1 = {33, 66, 11, 44, 22, 55}
>>> s2 = {33, 22, 55}
>>> s1.isdisjoint(s2)
False
>>> s3 = {88, 77, 22, 55}
>>> s4 = {666, 99}
>>> s3.isdisjoint(s4)
True
上面判断是,s1和s2有交集但是返回错误,s3和s4没有交集返回True。isdisjoint()是判断集合是不是没有交集,没有就True。
>>> s1.isjoint(s2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'set' object has no attribute 'isjoint'
没有isjoint()方法,只能直接判断是不是没有交集,不能判断有交集,逗逼。
12.issubset(self,*args,**kwargs)
def issubset(self, *args, **kwargs): # real signature unknown
""" Report whether another set contains this set. """
"""判断集合是否是指定集合的子集"""
pass
issubset()判断一个集合是否是另一个集合的子集。(Report whether another set contains this set.)判断一个集合是否包含另外一个集合。s2.issubset(s1)等价于判断s1.__contains__(s2)。判断s2是否被包含在s1集合中。判断另外一个集合是否包含当前集合。
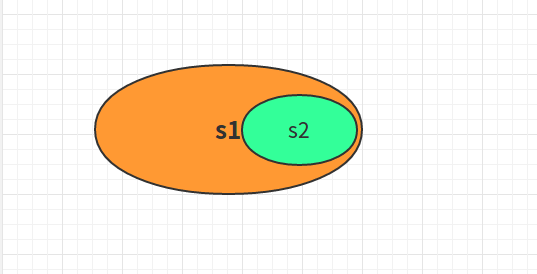
上面实例中,s2是s1的子集。s2完全包含在s1中。如果s2中有任何一个member成员不在s1中,那么就不包含在s1中。实例如下;
>>> s1 = {33, 66, 11, 44, 22, 55}
>>> s2 = {33, 22, 55}
>>> s2.issubset(s1)
True
>>> s3 = {88, 77, 22, 55}
>>> s3.issubset(s1)
False
上面示例中,是判断是否包含,由于s2中的每一个元素都在集合s1中,因此s2是集合s1的子集。s3中只有部分元素包含在集合s1中,因此不是s1的子集。返回False。
13.issuperset(self,*args,**kwargs)
def issuperset(self, *args, **kwargs): # real signature unknown
""" Report whether this set contains another set. """
"""判断是否是父集"""
pass
issuperset()(Report whether this set contains another set.)判断当前集合是否包含另一个集合。即判断当前集合是否是另外一个集合的父集。
issuperset()与issubset()是一样的,只是判断的顺序不一样而已。实例如下;
>>> s1 = {33, 66, 11, 44, 22, 55}
>>> s2 = {33, 22, 55}
>>> s3 = {88, 77, 22, 55}
>>> s1.issuperset(s2)
True
>>> s1.issuperset(s3)
False
上面实例中,由于s2是s1的子集,也即s1是s2的父集。所以返回True。
14.symmertric_difference(self,*args,**kwargs)
def symmetric_difference(self, *args, **kwargs): # real signature unknown
"""
Return the symmetric difference of two sets as a new set.
(i.e. all elements that are in exactly one of the sets.)
"""
pass
symmetric_difference()是取两个集合的对称差,A.symmetric_difference(B)等价于集合A∪B - A∩B。因而A.symmetric_difference(B)与B.symmetric_difference(A)结果是一样的。实例如下:
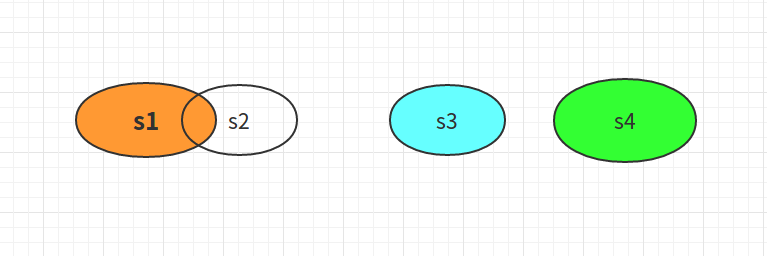
上面图中,s1和s2有交集,s3和s4没有交集,如果s1和s2使用symmetric_difference()则返回两个集合除了交集的部分。s3和s4使用交集等价于s3∪s4。
>>> s1 = set(["alex","tom","aoi","marry","geng"])
>>> s2 = set(["alex","geng","cang","kong"])
>>> s3 = set(["alex","tom","zeng"])
>>> s4 = set(["qian","zhang","wang"])
>>> s1.symmetric_difference(s2) (1)
{'cang', 'kong', 'aoi', 'tom', 'marry'}
>>> s2.symmetric_difference(s1) (2)
{'cang', 'tom', 'kong', 'marry', 'aoi'}
>>> s3.symmetric_difference(s4) (3)
{'alex', 'wang', 'zeng', 'qian', 'zhang', 'tom'}
>>> s4.symmetric_difference(s3) (s4)
{'alex', 'wang', 'zeng', 'qian', 'zhang', 'tom'}
>>> s1.symmetric_difference(s2,s3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: symmetric_difference() takes exactly one argument (2 given)
从上面代码可以看出,symmetric_difference()是对称性的,对称差;(1)和(2)的结果是一致的;(3)和(4)的结果是一致的。symmetric_difference()是两个集合先做并集,然后减去交集。symmetric_difference()是有一个参数,只能是两个集合的对称差。不像交集并集那样有很多参数。Return the symmetric difference of two sets as a new set.
15.symmertic_difference_update(self,*args,**kwargs)
def symmetric_difference_update(self, *args, **kwargs): # real signature unknown
""" Update a set with the symmetric difference of itself and another. """
pass
symmetric_difference_update()与symmetric_difference()是一样的。只是symmetric_difference_update()更新原来的集合。A.symmetric_difference_update(B)等价于A = A∪B - A∩B.
16.union(self,*args,**kwargs)
def union(self, *args, **kwargs): # real signature unknown
"""
Return the union of sets as a new set.(并集)
(i.e. all elements that are in either set.)
"""
pass
union()并集,求集合的并集,A.union(B)等价于A∪B.Return the union of sets as a new set.生成两个集合的并集。
>>> s1 = {'alex', 'tom', 'geng', 'marry', 'aoi'}
>>> s2 = {'alex', 'cang', 'geng', 'kong'}
>>> s3 = {'alex', 'tom', 'zeng'}
>>> s1.union(s2,s3)
{'geng', 'alex', 'cang', 'kong', 'aoi', 'zeng', 'tom', 'marry'}
union()是生成集合的并集。图如下:
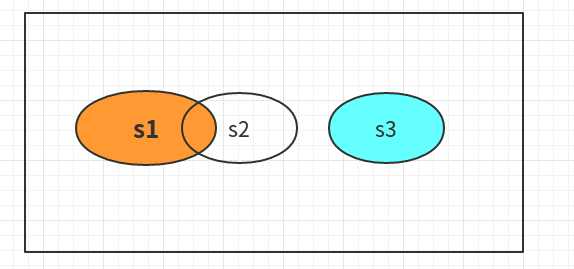
union()就是把集合中不同的元素合并成一个新的集合。
17.update(self,*args,**kwargs)
def update(self, *args, **kwargs): # real signature unknown
""" Update a set with the union of itself and others. """
pass
update()更新集合,是把集合合并之后返回给原来的集合。即A.update(B)等价于A = A∪B。实例如下:
>>> s1 = {'alex', 'tom', 'geng', 'marry', 'aoi'}
>>> s2 = {'alex', 'cang', 'geng', 'kong'}
>>> s3 = {'alex', 'tom', 'zeng'}
>>> s1.update(s3,s2)
>>> s1
{'geng', 'alex', 'cang', 'kong', 'aoi', 'zeng', 'tom', 'marry'}
从上面代码可以看出update()是把集合的元素并集之后赋给原来的值。我还以为存在一个union_update()原来直接是update().Update a set with the union of itself and others.
示例:下面有两个集合,是两个cmdb文件,原来的字典和新获取的字典,要求更新原来的字典,实例如下:
# 数据库中原有
old_dict = {
"#1": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 80},
"#2": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 80},
"#3": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 80}
}
# cmdb 新汇报的数据
new_dict = {
"#1": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 800},
"#3": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 80},
"#4": {'hostname': "c2", 'cpu_count': 2, 'mem_capicity': 80}
}
思路:
(1)原来有的,新的cmd也有,要么更新,要么不变。
(2)原来有,新的cmd没有,要删除的;
(3)原来没有,新的cmd有,要添加的。
# 数据库中原有
old_dict = {
"#1": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#2": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#3": {'hostname': "c1", 'cpu_count': , 'mem_capicity': }
} # cmdb 新汇报的数据
new_dict = {
"#1": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#3": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#4": {'hostname': "c2", 'cpu_count': , 'mem_capicity': }
} old = set(old_dict.keys())
new = set(new_dict.keys()) #原来有,现在没有,要删除的数据。
del_datas = old.difference(new)
for del_data in del_datas:
del old_dict[del_data]
#原来没有,现在有,新添加
add_datas = new.difference(old)
for add_data in add_datas:
old_dict[add_data] = new_dict[add_data]
#原来有,现在也有,更新
update_datas = old.intersection(new)
for update_data in update_datas:
old_dict[update_data] = new_dict[update_data] print(old_dict)
事实上,difference()才是求集合的差集,求出一个集合与另一个集合完全不同的元素,symmetric_difference()是求对称差集,上面方法使用的是difference()方法,也可以使用symmetric_difference(),只不过symmetric_difference()需要先求出两个集合的交集。
方法二:使用symmetric_difference():
# 数据库中原有
old_dict = {
"#1": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#2": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#3": {'hostname': "c1", 'cpu_count': , 'mem_capicity': }
} # cmdb 新汇报的数据
new_dict = {
"#1": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#3": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#4": {'hostname': "c2", 'cpu_count': , 'mem_capicity': }
} old = set(old_dict.keys())
new = set(new_dict.keys()) #原来有,现在也有,更新
update_datas = old.intersection(new)
#取交集
for update_data in update_datas:
old_dict[update_data] = new_dict[update_data] #原来有,现在没有,要删除的数据。
del_datas = old.symmetric_difference(update_datas)
for del_data in del_datas:
del old_dict[del_data] #原来没有,现在有,新添加
add_datas = new.symmetric_difference(update_datas)
for add_data in add_datas:
old_dict[add_data] = new_dict[add_data] print(old_dict)
上面使用了两种方法,一种是直接只用difference()求差集,另一种是先求交集,然后在求出差集,symmetric_difference().
# 数据库中原有
old_dict = {
"#1": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#2": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#3": {'hostname': "c1", 'cpu_count': , 'mem_capicity': }
} # cmdb 新汇报的数据
new_dict = {
"#1": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#3": {'hostname': "c1", 'cpu_count': , 'mem_capicity': },
"#4": {'hostname': "c2", 'cpu_count': , 'mem_capicity': }
} old = set(old_dict.keys())
new = set(new_dict.keys()) #原来有,现在没有,要删除的数据。
del_datas = old.difference(new)
for del_data in del_datas:
del old_dict[del_data]
#原来没有,现在有,新添加
add_datas = new.difference(old)
for add_data in add_datas:
old_dict[add_data] = new_dict[add_data]
#原来有,现在也有,更新
update_datas = old.intersection(new)
for update_data in update_datas:
old_dict[update_data] = new_dict[update_data] print(old_dict)
day3 集合set()实例分析的更多相关文章
- sql注入实例分析
什么是SQL注入攻击?引用百度百科的解释: sql注入_百度百科: 所谓SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令.具 ...
- Mahout机器学习平台之聚类算法具体剖析(含实例分析)
第一部分: 学习Mahout必需要知道的资料查找技能: 学会查官方帮助文档: 解压用于安装文件(mahout-distribution-0.6.tar.gz),找到例如以下位置.我将该文件解压到win ...
- Hive(六)hive执行过程实例分析与hive优化策略
一.Hive 执行过程实例分析 1.join 对于 join 操作:SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.useri ...
- 《深入理解mybatis原理1》 MyBatis的架构设计以及实例分析
<深入理解mybatis原理> MyBatis的架构设计以及实例分析 MyBatis是目前非常流行的ORM框架,它的功能很强大,然而其实现却比较简单.优雅.本文主要讲述MyBatis的架构 ...
- C#保留2位小数几种场景总结 游标遍历所有数据库循环执行修改数据库的sql命令 原生js轮盘抽奖实例分析(幸运大转盘抽奖) javascript中的typeof和类型判断
C#保留2位小数几种场景总结 场景1: C#保留2位小数,.ToString("f2")确实可以,但是如果这个数字本来就小数点后面三位比如1.253,那么转化之后就会变成1.2 ...
- java集合源码分析(三):ArrayList
概述 在前文:java集合源码分析(二):List与AbstractList 和 java集合源码分析(一):Collection 与 AbstractCollection 中,我们大致了解了从 Co ...
- java集合源码分析(六):HashMap
概述 HashMap 是 Map 接口下一个线程不安全的,基于哈希表的实现类.由于他解决哈希冲突的方式是分离链表法,也就是拉链法,因此他的数据结构是数组+链表,在 JDK8 以后,当哈希冲突严重时,H ...
- 用C++实现的数独解题程序 SudokuSolver 2.3 及实例分析
SudokuSolver 2.3 程序实现 用C++实现的数独解题程序 SudokuSolver 2.2 及实例分析 里新发现了一处可以改进 grp 算法的地方,本次版本实现了对应的改进 grp 算法 ...
- 用C++实现的数独解题程序 SudokuSolver 2.1 及实例分析
SudokuSolver 2.1 程序实现 在 2.0 版的基础上,2.1 版在输出信息上做了一些改进,并增加了 runtil <steps> 命令,方便做实例分析. CQuizDeale ...
随机推荐
- python函数的输入参数
http://note.youdao.com/noteshare?id=c2a0a39ee3cae09a62dcbc9f96d04b56
- 前端PHP入门-033-连接数据库-天龙八步
php检查MySQL的支持是否开启? 若没有看到mysqli扩展在windows服务器下,打开php.ini文件,将php_mysqli.dll打开即可! 注意: 从PHP7开始默认不再支持mysql ...
- 关闭eclipse自动弹出console功能
使用eclipse时经常会用到最大化窗口,而如果此时是开着tomcat等服务的话,一段后台有打印什么东西出来都会自己弹出 console挺烦人的.可以使用以下操作关闭这个功能. Preferences ...
- json属性名为什么要双引号?
原因一: 更加规范,利于解析 原因二: 避免class等关键字引起的不兼容问题 原因三: 可能也是最隐晦的: var a = 00; var b = {00: 12}; a in b; --> ...
- 【费用流】【CODEVS】1227 方格取数2
[算法]最小费用最大流(费用流) [题解] 费用流:http://www.cnblogs.com/onioncyc/p/6496532.html 本题构图: 在有限的k次行走中尽可能多的拿到数字,明显 ...
- 【CodeForces】947 C. Perfect Security 异或Trie
[题目]C. Perfect Security [题意]给定长度为n的非负整数数组A和数组B,要求将数组B重排列使得A[i]^B[i]的字典序最小.n<=3*10^5,time=3.5s. [算 ...
- 持续集成工具Jenkins安装、部署、使用
本文介绍jenkins,利用其做项目发布与持续集成交付工具. 一.Jenkins是什么? Jenkins是基于Java开发的一种持续集成工具,用于监控持续重复的工作,功能包括: 1.持续的软件版本发布 ...
- git创建新分支推送到远程
1.创建本地分支 git branch 分支名,例如:git branch 2.0.1.20120806 注:2.0.1.20120806是分支名称,可以随便定义. 2.切换本地分支 git ch ...
- html中插入其他html,并实现动态效果!
<html> <body> 倒计时开始...... <span id="s1">888</span> <!--在html中先做 ...
- 简单响应式Bootstrap框架中文官网页面模板
链接:http://pan.baidu.com/s/1o7MQ6RC 密码:kee5