大数据量情况下高效比较两个list
比如,对两个list<object>进行去重,合并操作时,一般的写法为两个for循环删掉一个list中重复的,然后再合并。
如果数据量在千条级别,这个速度还是比较快的。但如果数据量超过20W+(比如大批量的导入数据并对数据进行处理)时,则这块代码执行时间会比较长,非常影响用户体验和程序功能。这时我们可以用差集(Except)来处理重复数据。
下面MSDN上的代码示例演示了如何使用 Except<TSource>(IEnumerable<TSource>, IEnumerable<TSource>) 方法来比较两个数字序列,并返回仅在第一个序列中出现的元素。
double[] numbers1 = { 2.0, 2.1, 2.2, 2.3, 2.4, 2.5 };
double[] numbers2 = { 2.2 };
IEnumerable<double> onlyInFirstSet = numbers1.Except(numbers2);
foreach (double number in onlyInFirstSet)
outputBlock.Text += number + "\n";
/*
This code produces the following output:
2
2.1
2.3
2.4
2.5
*/
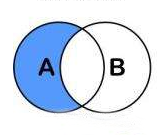
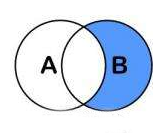
需要注意的是A.Except(B)与B.Except(A)结果是不一样的。
A.Except(B):
B.Except(A):
如果希望比较某种自定义数据类型对象的序列,则必须在您的类中实现 IEqualityComparer<T> 泛型接口。 下面的代码演示了如何在自定义数据类型中实现此接口并提供 GetHashCode 和 Equals 方法。
假设有需求是:在oldlist中过滤掉和list有相同ContractNo值的数据。
public class AssetPoolDataComparer : IEqualityComparer<AssetPoolData>
{
public bool Equals(AssetPoolData x, AssetPoolData y)
{
if (Object.ReferenceEquals(x, y)) return true;
//设置比较条件为两个ContractNo相同
return x != null && y != null && x.ContractNo.Equals(y.ContractNo);
} public int GetHashCode(AssetPoolData obj)
{
int hashContractNo = obj.ContractNo == null ? : obj.ContractNo.GetHashCode();
//主键ID
int hashProductID = obj.Id.GetHashCode(); return hashContractNo ^ hashProductID;
}
} var exceptList = oldlist.Except(list, new AssetPoolDataComparer()).ToList();
修改完代码,测试前后代码块运行时间,效果还是非常可观的。
ByQJL
大数据量情况下高效比较两个list的更多相关文章
- 大数据量情况下求top N的问题
上周五的时候去参加了一个面试,被问到了这个问题.问题描述如下: 假如存在一个很大的文件,文件中的每一行是一个字符串.请问在内存有限的情况下(内存无法加载这个文件中的所有内容),如何计算出出现频率最高的 ...
- phpExcel导入大数据量情况下内存溢出解决方案
PHPExcel版本:1.7.6+ 在不进行特殊设置的情况下,phpExcel将读取的单元格信息保存在内存中,我们可以通过 PHPExcel_Settings::setCacheStorageMeth ...
- phpExcel大数据量情况下内存溢出解决
版本:1.7.6+ 在不进行特殊设置的情况下,phpExcel将读取的单元格信息保存在内存中,我们可以通过 PHPExcel_Settings::setCacheStorageMethod() 来设置 ...
- C#拼接SQL语句,SQL Server 2005+,多行多列大数据量情况下,使用ROW_NUMBER实现的高效分页排序
/// <summary>/// 单表(视图)获取分页SQL语句/// </summary>/// <param name="tableName"&g ...
- MYSQL的大数据量情况下的分页查询优化
最近做的项目需要实现一个分页查询功能,自己先看了别人写的方法: <!-- 查询 --> <select id="queryMonitorFolder" param ...
- 大数据量冲击下Windows网卡异常分析定位
背景 mqtt的服务端ActiveMQ在windows上,多台PC机客户端不停地向MQ发送消息. 现象 观察MQ自己的日志data/activemq.log里显示,TCP链接皆异常断开.此时尝试从服务 ...
- 大数据量场景下storm自定义分组与Hbase预分区完美结合大幅度节省内存空间
前言:在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗.大量的预分 ...
- 由“大数据量Excel入库高效方式”瞥见“并联系统”之优势
使用场景: 当你有一个Excel文件,需要把其中的数据高速录入到数据库中,文件中包含10万条以上数据. 设计方案: 我们将整个过程分成三个阶段,A(装载Excel文件). ...
- java 导出Excel 大数据量,自己经验总结!
出处: http://lyjilu.iteye.com/ 分析导出实现代码,XLSX支持: /** * 生成<span style="white-space: normal; back ...
随机推荐
- php环境下所有的配置文件以及作用
以下主要是针对linux下的目录(windows也是一样,文件名都一样) Apache:etc/httpd.conf PHP:etc/php.ini (Apache 正在运行的 PHP 版本) M ...
- 【剑指offer28:字符串的排列】【java】
题目:输入一个字符串,按字典序打印出该字符串中字符的所有排列.例如输入字符串abc,则打印出由字符a,b,c所能排列出来的所有字符串abc,acb,bac,bca,cab和cba. import ja ...
- 机器学习之Adaboost (自适应增强)算法
注:本篇博文是根据其他优秀博文编写的,我只是对其改变了知识的排序,另外代码是<机器学习实战>中的.转载请标明出处及参考资料. 1 Adaboost 算法实现过程 1.1 什么是 Adabo ...
- ASP.NET与ASP.NET MVC 的差异、优点及缺点
众所周知,在微软的编程语言发展历史中,asp.net是不得不提的一个重要的发展阶段,它具有快速开发.层级明确的优点,但最大的缺点,同时也是它逐渐被废弃的原因就是,页面加载的viewstate过于庞大, ...
- CentOs下 SVN版本控制的安装(包括yum与非yum)
一.yum安装 rpm -qa subversion //检查是否安装了低版本的SVN yum remove subversion //如果存储旧版本,卸载旧版本SVN 开始安装 yum -y ins ...
- poj 2230详解
题目链接 : poj2230 大致题意: 有一个人每晚要检查牛场,牛场内有m条路,他担心会有遗漏,就每条路检查两次,且每次的方向不同,要求你打印他行走的路径(必须从1开始),打印一条即可. 思路分析 ...
- Zookeeper笔记3——原理及其安装使用
Zookeeper到底能干什么? 1.配置管理:这个好理解.分布式系统都有好多机器,Zookeeper提供了这样的一种服务:一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣 ...
- Android学习开发中如何保持API的兼容
Android学习开发中如何保持API的兼容: 1,采用良好的设计思路 在设计过程中,如果能按照下面的方式来进行设计,会让这个API生命更长久 面向用例的设计,收集用户建议,把自己模拟成用户,保证AP ...
- C#中windows服务安装方法
关于windows服务的编写方法,参考:http://www.cnblogs.com/sorex/archive/2012/05/16/2502001.html 我这里就补充一下安装方法. 1.首先打 ...
- android技术晋升之道
写一篇文章记录一下我看到的几个特别常见的误区,希望对团队晋升的同学能有帮助. 误区1:把特质当成案例 工作非常努力,连续一个月加班到12点,解决了问题 喜欢学习新技术和分享,团队同学都很喜欢 善于钻研 ...