【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装、Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置。具体请参看:
【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-上
6. Linux节点配置
设置主机名:根据规划修改主机名,执行hostnamectl set-hostname hdoop1,修改主机名并写入配置文件,使用hostname查看当前生效的主机名。

关闭防火墙:使用systemctl命令关闭防火墙,stop是本次关闭,disable是下次开机也不会启动(永久关闭)。这里我们需要使用disable彻底关闭。

停止selinux:使用getenforce命令可以查询selinux状态,使用setenforce命令设置状态 0表示允许通过(即本次关闭selinux,下次启动还会还原,要想永久关闭,则需要使用vim编辑配置文件,下图为getenforce和setenforce的使用)

vim编辑器的简要使用说明:
vim编辑器有三种状态:普通模式,编辑模式,命令模式
普通模式按i键进入编辑模式,按esc键回普通模式
普通模式进入命令模式,直接在普通模式下输入(冒号加命令)
:q!(不保存退出) :q(直接退出)
:w(保存不退出) :wq(保存退出)
selinux的配置文件目录:etc/selinux/config
输入命令:vim etc/selinux/config 即可打开配置文件编辑,按i键进入编辑模式,修改为如下结果。cat为查看文件命令。

利用VMware克隆另外两个节点:利用节点1的虚拟机克隆出另外两台节点虚拟机,克隆完成后按规划修改主机名和IP地址。分别为hadoop2节点IP为192.168.1.20,hadoop3节点IP为192.168.1.30,修改方法与前面一致。
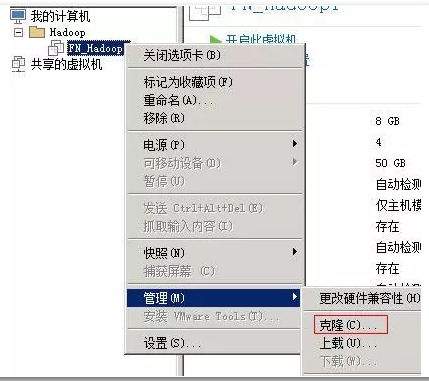
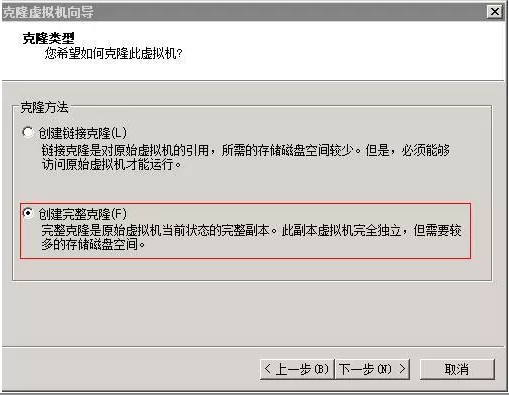
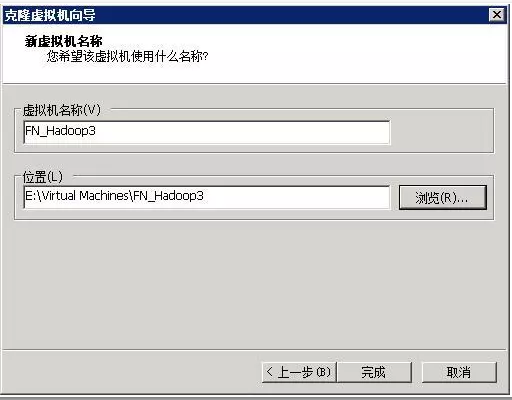
设置主机名和IP对应:每个节点都要设置,写法是一样的,完成之后可以直接ping主机名来测试是否设置成功。输入vim /etc/hosts打开配置文件编辑,修改为如下结果。(三个节点都是一样的方式)。

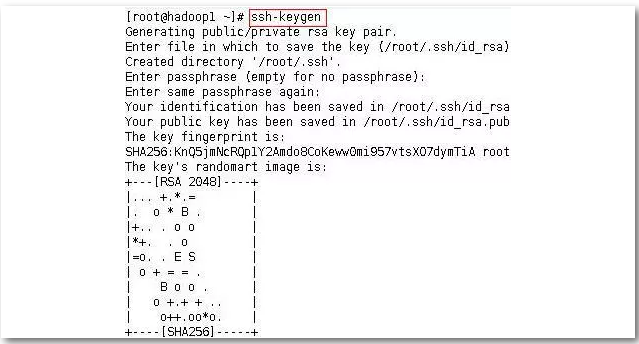
设置ssh互信:ssh免密码登录如果不配置,在启动集群时候需要输入每个节点的密码方可启动,为避免多次输入密码,可配置ssh免密码登录。下面以hadoop1为例,首先生成密钥,然后将密钥传给其它节点,也要传给自己。(另外两个节点也要做,做法是一样的,如下所示)。
首先,生成密钥:ssh-keygen (敲三次回车)
然后将密钥传给其它节点(包括自己),每个节点都要做,命令格式如下:
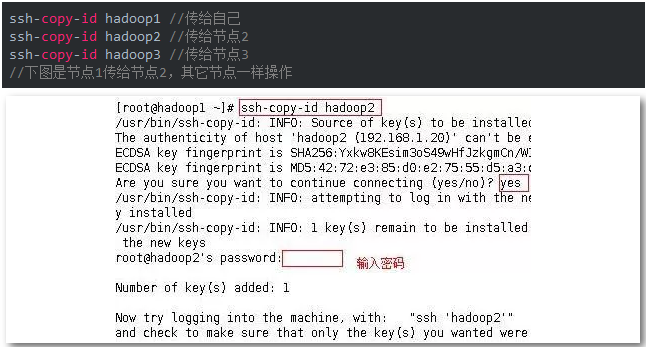
用ssh测试一下能否直接登陆(下图是从节点1登陆至节点2和节点3)
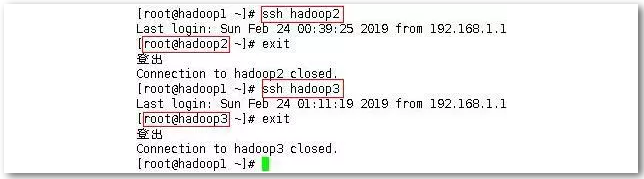
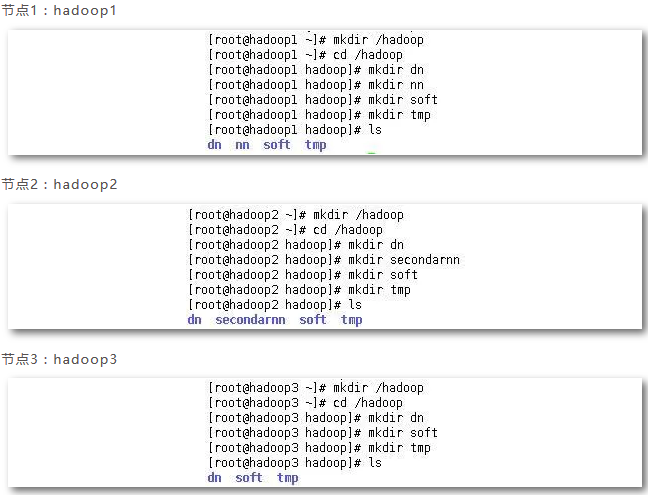
目录建立:根据规划为每个节点创建目录文件夹。
7. JDK安装配置
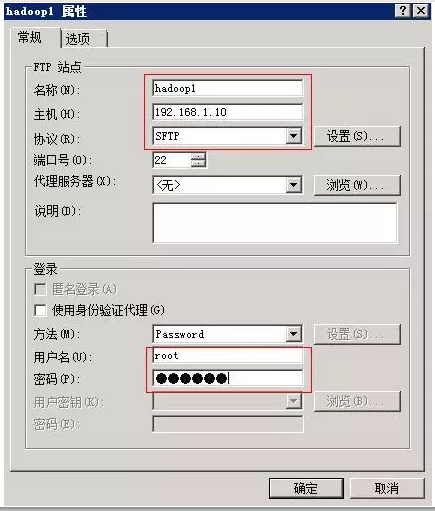
拷贝JDK包至节点机:首先使用Xftp将JDK安装文件传输至Linux节点机,打开Xftp工具,配置会话,在Xftp工作区左侧打开物理机需要上传软件所在的目录,再在右侧打开节点机hadoop1的目的目录(/hadoop/soft),将文件由左侧拖至右侧即可。
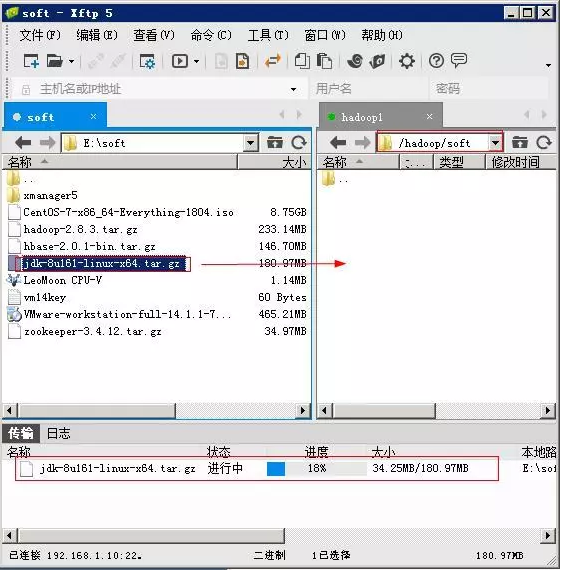
解压JDK: tar -zxvf jdk-8u161-linux-x64.tar.gz,解压完成后即可看到蓝色的JDK文件夹

编辑环境变量:配置root用户的环境变量,切换至家目录,使用vim .bash_profile编辑环境变量。添加如下内容。
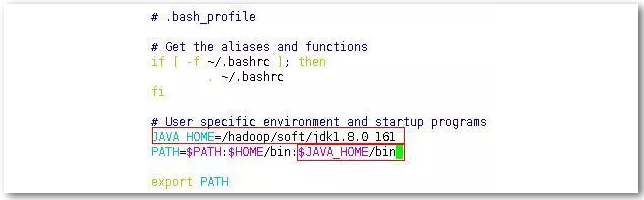
验证:使用source .bash_profile重新加载环境变量,使用命令java –version查看现在java的版本,看能否成功执行,结果如下。

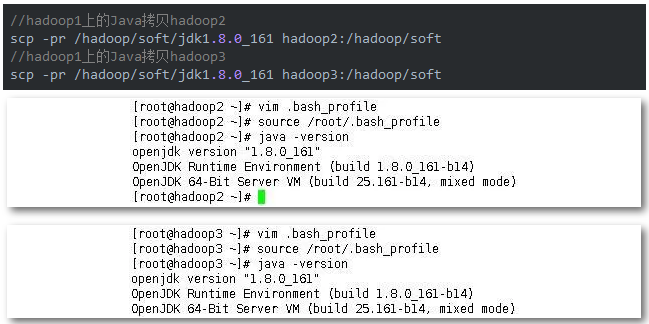
其它节点安装:将节点hadoop1上的Java拷贝到另外两个节点上,然后分别登陆至两个节点,按上面的方法设置另外两个节点的环境变量。完成后重新加载环境变量,查看版本验证一下。
8. Hadoop安装配置
将Hadoop软件包上传至节点1:利用Xftp将物理机上的hadoop-2.8.3.tar.gz传输至节点1上(/hadoop/soft)目录下。
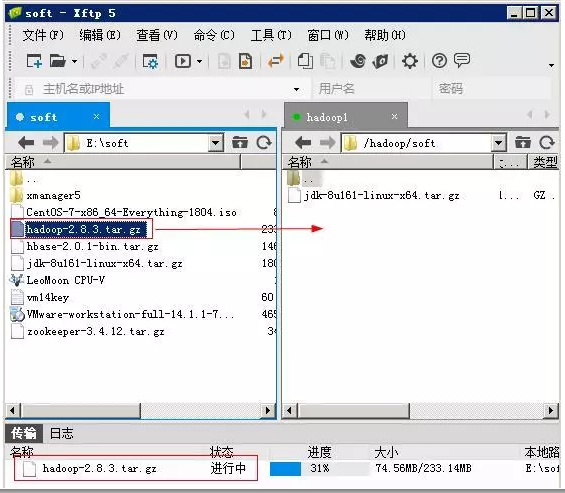
解压Hadoop: tar -zxvf hadoop-2.8.3.tar.gz

进入Hadoop配置文件目录:如下图所示
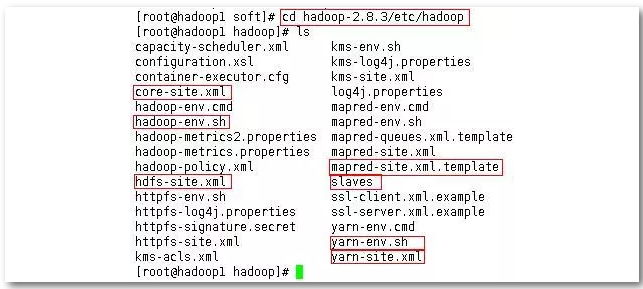
编辑Hadoop配置文件:需要编辑hadoop-env.sh、yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves。(小建议:可以用Xftp将这些文件复制到windows系统上,用Notepad++修改保存,然后在复制到每个节点相应的文件夹里覆盖原来的)。当然,也可在linux下用vim编辑这些文件,只是较为不便。
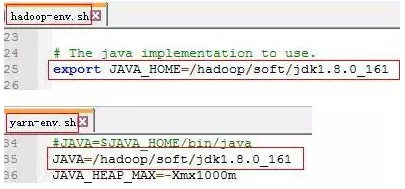
a. 设置hadoop-env.sh和yarn-env.sh中的java环境变量
b.配置core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.10:9000</value>
</property>
<property>
<name>hadoop,tmp.dir</name>
<value>/hadoop/tmp/</value>
</property>
</configuration>
c.配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.1.10:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.20:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///hadoop/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///hadoop/dn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///hadoop/secondarynn</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
d.配置mapred-site.xml文件(由于默认没有mapred-site.xml文件,只有一个mapred-site.xml.template文件,可以将这个template文件重命名为mapred-site.xml)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.10:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.10:19888</value>
</property>
</configuration>
e.配置yarn-site.xml文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.10:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.10:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.10:8031</value>
</property>
<property>
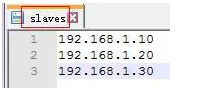
f.配置slaves文件
编辑环境变量:配置root用户的环境变量,切换至家目录,使用vim .bash_profile编辑环境变量。添加如下内容。

验证:使用source .bash_profile重新加载环境变量,使用命令hadoop version查看现在hadoop的版本,结果如下。

其它节点安装:将节点hadoop1上已经配置好的hadoop拷贝到另外两个节点上,然后按上面的方法设置另外两个节点的环境变量。(使用vim .bash_profile编辑环境变量),完成后用上面查看版本的方式验证一下。

9. Hadoop启动
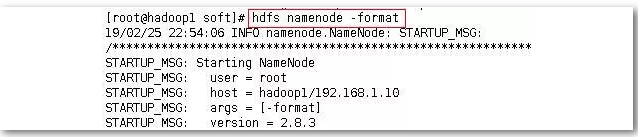
使用hdfs namenode –format格式化hdfs文件系统,如下图。(仅在第一次启动之前需要格式化,后面启动不需要格式化,只需在节点1上执行)
使用start-all.sh启动所有服务(只需在节点1上执行)
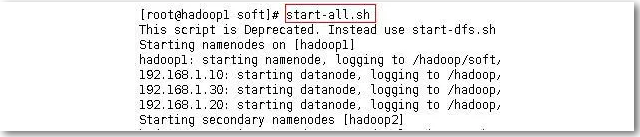
启动成功可分别登陆至每个节点运行jps查看每各个节点上运行的进程,正常情况如下。

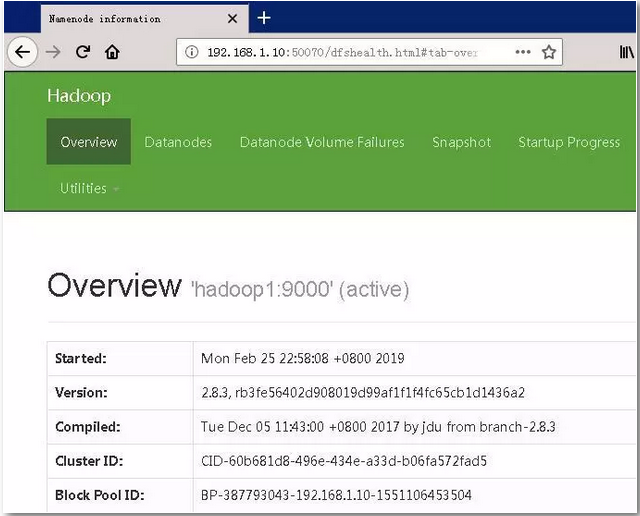
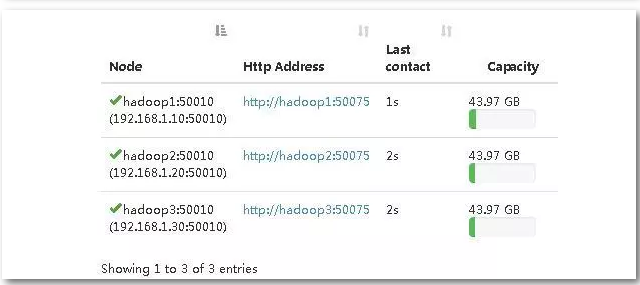
在物理机上访问hdfs的web界面,打开物理机浏览器,输入网址:http://192.168.1.10:50070,结果如下图能看到datanode的数据和启动datanode相同,表示启动成功。
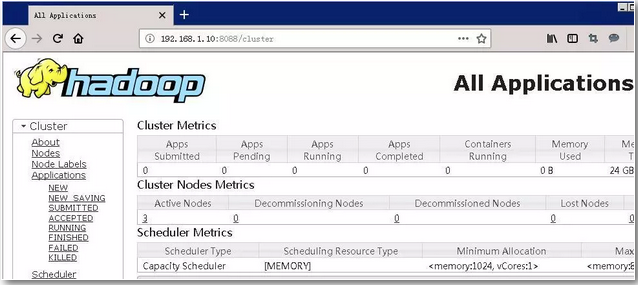
同上,使用浏览器打开http://192.168.1.10:8088,结果如下图,表示yarn正常正常启动。
【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下的更多相关文章
- HDP 企业级大数据平台
一 前言 阅读本文前需要掌握的知识: Linux基本原理和命令 Hadoop生态系统(包括HDFS,Spark的原理和安装命令) 由于Hadoop生态系统组件众多,导致大数据平台多节点的部署,监控极其 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 单机,伪分布式,完全分布式-----搭建Hadoop大数据平台
Hadoop大数据——随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快.信息更是爆炸性增长,收集,检索,统计这些信息越发困难,必须使用新的技术来解决这 ...
- Ambari——大数据平台的搭建利器之进阶篇
前言 本文适合已经初步了解 Ambari 的读者.对 Ambari 的基础知识,以及 Ambari 的安装步骤还不清楚的读者,可以先阅读基础篇文章<Ambari——大数据平台的搭建利器>. ...
- 【定义及安装】Ambari——大数据平台的搭建利器
Ambari 是什么 Ambari 跟 Hadoop 等开源软件一样,也是 Apache Software Foundation 中的一个项目,并且是顶级项目.目前最新的发布版本是 2.0.1,未来不 ...
- 量化派基于Hadoop、Spark、Storm的大数据风控架构--转
原文地址:http://www.csdn.net/article/2015-10-06/2825849 量化派是一家金融大数据公司,为金融机构提供数据服务和技术支持,也通过旗下产品“信用钱包”帮助个人 ...
- Ambari——大数据平台的搭建利器(一)
Ambari 跟 Hadoop 等开源软件一样,也是 Apache Software Foundation 中的一个项目,并且是**项目.目前最新的发布版本是 2.0.1,未来不久将发布 2.1 版本 ...
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
- 互联网大规模数据分析技术(自主模式)第五章 大数据平台与技术 第10讲 大数据处理平台Hadoop
大规模的数据计算对于数据挖掘领域当中的作用.两大主要挑战:第一.如何实现分布式的计算 第二.分布式并行编程.Hadoop平台以及Map-reduce的编程方式解决了上面的几个问题.这是谷歌的一个最基本 ...
随机推荐
- 基于puppeteer模拟登录抓取页面
关于热图 在网站分析行业中,网站热图能够很好的反应用户在网站的操作行为,具体分析用户的喜好,对网站进行针对性的优化,一个热图的例子(来源于ptengine) 上图中能很清晰的看到用户关注点在那,我们不 ...
- 循环神经网络(RNN)--学习笔记
一.基本概念 RNN针对的数据是时序数据.RNN它解决了前馈神经网络,无法体现数据时序关系的缺点.在RNN网络中,不仅同一个隐含层的节点可以相互连接,同时隐含层的输入不仅来源于输入层的输入还包括了上一 ...
- Java c# 跨语言Json反序列化首字母大小写问题
C#标准是首字母大写,Java规范是首字母小写,在序列化成Json之后,反序列化会出现反序列化失败的问题.. 从C#反序列化成JavaBean的时候通过如下注解可以直接解决该问题 @JsonNamin ...
- js中几种实用的跨域方法原理详解【转】
源地址:http://www.cnblogs.com/2050/p/3191744.html 这里说的js跨域是指通过js在不同的域之间进行数据传输或通信,比如用ajax向一个不同的域请求数据,或者通 ...
- URL 规范 整理
URL 规范 不用大写:(强制) 用中杠-不用下杠_:(强制) 参数列表要encode,编码使用utf-8:(强制) URI中的名词表示资源集合,使用复数形式.(建议) 增加版本号(建议) URI中统 ...
- VS2010+OpenCV3.4.1+zbar 64位
1. OpenCV3.4.1和zbar文件夹放到指定的路径下,我把它们放在了"D:\二维码\环境"中. zbar:链接:https://pan.baidu.com/s/11eCDV ...
- Cookie SQL注入
转自http://blog.sina.com.cn/s/blog_6b347b2a0101379o.html cookie注入其原理也和平时的注入一样,只不过说我们是将提交的参数已cookie方式提交 ...
- PHP之cookies小练习
//5-1.php 1 <? error_reporting(E_ALL ^ E_NOTICE); if ($_COOKIE['username']!="") { echo ...
- Android/Linux Thermal Governor之IPA分析与使用
IPA(Intelligent Power Allocator)模型的核心是利用PID控制器,Thermal Zone的温度作为输入,可分配功耗值作为输出,调节Allocator的频率和电压值. 由P ...
- React Native在特赞的应用与实践
基于React技术栈构建开发前端项目,并使用React Native开发特赞移动APP 目前正在使用Node.js开发和维护特赞服务网关,希望Node.js能够在更轻量级的微服务架构中发挥重要作用 课 ...