Python入门之三元表达式\列表推导式\生成器表达式\递归匿名函数\内置函数
本章目录:
一、三元表达式、列表推导式、生成器表达式
二、递归调用和二分法
三、匿名函数
四、内置函数
==================================================================
一、三元表达式、列表推导式、生成器表达式
1. 三元表达式
#三元表达式格式:
'''
判定条件? 为真时的结果 : 为假时的结果
'''
# 例
result = 5>3? 1 : 0
'''
定义函数比较两个值
'''
def max(x, y):
if x > y:
return x
else:
return y res = max(x, y)
oprint(res) '''
三元表达式仅应用于:
1. 条件成立返回前一个值
2. 条件不成立返回后面一个值
'''
res = x if x>y else y
print(res) # 三元表达式函数的写法
def max2(x,y):
return x if x > y else y print(max2)
2. 列表推导式
#1. 示例
egg_list = [] for i in range(10):
egg_list.append('Egg No.%s' %i) egg_list = ['Egg No.%s' %i for i in range(10)] #2. 语法
[expression for item1 in iterable1 if condition1
for item2 in iterable2 if condition2
....
for itemN in iterableN if conditionN
] # 例子如下
res = []
for item1 in iterable1:
if condition1:
for item2 in iterable2:
....
for itemN in iterableN:
if conditonN:
res.append(expression) #3 优点:方便,改变了变成习惯,可称之为声明式编程
3.生成器表达式
#1 把列表推导式的[]换成()就是生成器表达式
#2 示例:列表好比一筐鸡蛋,现在我们通过生成器把一筐鸡蛋变成一只可以随时下单的老母鸡,利用了生成器的特点
>>>chicken = ('Egg No.%s' %i for i in range(5))
>>>print(chicken)
# 得到的结果
>>> <generator object <genexpr> at 0x10143f200>
>>>next(chicken)
'Egg No.0'
>>>list(chicken) #chicken是生成器,具有可迭代属性,可以转换为列表
['Egg No.0', 'Egg No.1', 'Egg No.2', 'Egg No.3', 'Egg No.4']
#3 优点:一筐鸡蛋变成一只老母鸡,节省内存,一次只放一个鸡蛋到内存
二、递归调用和二分法
1. 递归调用的定义
# 递归调用是函数嵌套调用的一种特殊形式,函数在调用的时候,直接或者间接调用了自身,就是递归调用
# 示例 def foo():
print('from foo')
foo() foo() ----------------------------------------------------------------------------------
def bar:
print('I'm bar')
foo() def foo():
print('from foo')
bar() foo()
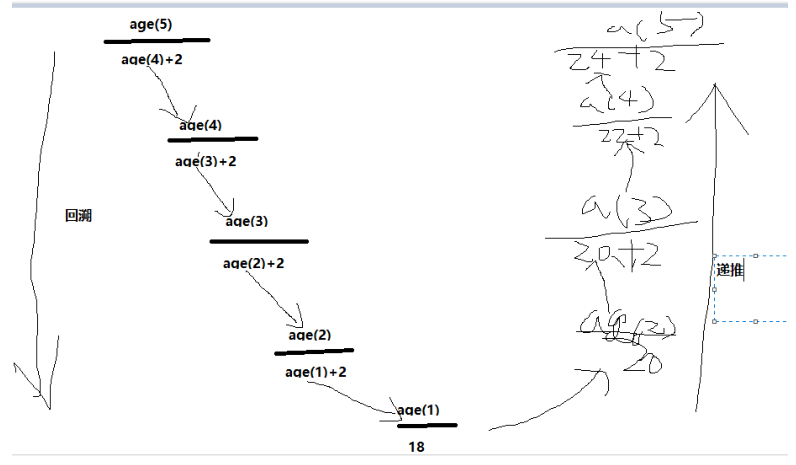
2. 递归分为两个阶段:递推,回溯
'''
salary(5) = salary(4)+300
salary(4) = salary(3)+300
salary(3) = salary(2)+300
salary(2) = salary(1)+300
salary(1) = 300 salary(n) = salary(n-1)+300
salary(1) = 100
''' def salary(n):
if n == 1:
return 100
return salary(n-1) + 100 print(salary(5))
'''
递归分为两个阶段:
1. 回溯
注意:一定要在某种条件下结束回溯,否则会无限循环下去
2. 递推
总结:
1. 递归一定要有一个明确的结束条件
2. 没进入下一次递归,问题的规模都应该减少
'''
'''
while和递推的区别:
while需要明确多少循环
递推只需要知道怎么去循环,至于循环多少次,没有说明
'''
items = [1,[2,[3,[4,[5,[6,[7,[8,[9,[10,11,]]]]]]]]] def tell(L1):
for item in L1:
if type(item) is not list:
print(item)
else:
tell(item) # tell再次调用自己,递归 tell(items)
3. Python中的递归效率低并且没有尾递归优化
#python中的递归 python中的递归效率低,需要在进入下一次递归时保留当前的状态,在其他语言中可以有解决方法:尾递归优化,即在函数的最后一步(而非最后一行)调用自己,
但是python又没有尾递归,且对递归层级做了限制 #总结递归的使用: 1. 必须有一个明确的结束条件 2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少 3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出
4. Python中可以修改递归最大深度
import sys sys.getrecursionlimit #Python中获取系统默认递归深度(1000)
sys.setrecursionlimit(2000) #修改系统默认递归深度为2000 n = 1
def test():
global n
print(n)
n += 1
test() test() #默认深度1000,打印到998停止;更改深度2000后,打印到1998
5. 二分法(即二分排序算法)
'''
从一个按照从小到大排列的数字列表中找到指定的数字,遍历的效率太低,用二分法可以提高查找效率
'''
L1 = [2,3,4,56,78,98,230,567,1222,1333,5620,10000]
def func_binary(num, L): #要找的值为num
print(L)
if len(L) > 0:
mid = len(1)//2 #列表已经从小大到排序,取列表的中间索引,获得中间值
if num > L[mid]:
L = L[mid+1 : ] #num比中间值大,只要取中间值右边部分,左侧舍弃
elif num < L[mid]:
L = L[ : mid] #num比中间值小,只要取中间值左边部分,右侧舍弃
else:
print('Find It!')
return
func_binary(num, L)
else:
print('Invalid Input List!')
return
search(1333, L1)
l=[1,2,10,30,33,99,101,200,301,402] def search(num,l,start=0,stop=len(l)-1):
if start <= stop:
mid=start+(stop-start)//2 #列表已经从小大到排序,取列表的中间索引,获得中间值
print('start:[%s] stop:[%s] mid:[%s] mid_val:[%s]' %(start,stop,mid,l[mid]))
if num > l[mid]: #num比中间值大,只要取中间值右边部分,左侧舍弃
start=mid+1
elif num < l[mid]: #num比中间值小,只要取中间值左边部分,右侧舍弃
stop=mid-1
else:
print('find it',mid)
return
search(num,l,start,stop)
else: #如果stop > start则意味着列表实际上已经全部切完,即切为空
print('not exists')
return search(301,l)
三、匿名函数
'''
有名函数与匿名函数的对比
有名函数:循环使用,保存了名字,通过名字就可以重复引用函数功能 匿名函数:一次性使用,随时随时定义 应用:max,min,sorted,map,reduce,filter
'''
# lambda自带return,所以不需要再加return


四、内置函数

字典的运算:最小值,最大值,排序
salaries={
'egon':3000,
'alex':100000000,
'wupeiqi':10000,
'yuanhao':2000
} 迭代字典,取得是key,因而比较的是key的最大和最小值
>>> max(salaries)
'yuanhao'
>>> min(salaries)
'alex' 可以取values,来比较
>>> max(salaries.values())
>>> min(salaries.values())
但通常我们都是想取出,工资最高的那个人名,即比较的是salaries的值,得到的是键
>>> max(salaries,key=lambda k:salary[k])
'alex'
>>> min(salaries,key=lambda k:salary[k])
'yuanhao' 也可以通过zip的方式实现
salaries_and_names=zip(salaries.values(),salaries.keys()) 先比较值,值相同则比较键
>>> max(salaries_and_names)
(100000000, 'alex') salaries_and_names是迭代器,因而只能访问一次
>>> min(salaries_and_names)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: min() arg is an empty sequence sorted(iterable,key=None,reverse=False)
#1、语法
# eval(str,[,globasl[,locals]])
# exec(str,[,globasl[,locals]]) #2、区别
#示例一:
s='1+2+3'
print(eval(s)) #eval用来执行表达式,并返回表达式执行的结果
print(exec(s)) #exec用来执行语句,不会返回任何值
'''
6
None
''' #示例二:
print(eval('1+2+x',{'x':3},{'x':30})) #返回33
print(exec('1+2+x',{'x':3},{'x':30})) #返回None # print(eval('for i in range(10):print(i)')) #语法错误,eval不能执行表达式
print(exec('for i in range(10):print(i)'))
compile(str,filename,kind)
filename:用于追踪str来自于哪个文件,如果不想追踪就可以不定义
kind可以是:single代表一条语句,exec代表一组语句,eval代表一个表达式
s='for i in range(10):print(i)'
code=compile(s,'','exec')
exec(code) s='1+2+3'
code=compile(s,'','eval')
eval(code)
Python入门之三元表达式\列表推导式\生成器表达式\递归匿名函数\内置函数的更多相关文章
- python基础-三元表达式/列表推导式/生成器表达式
1.三元表达式:如果成立返回if前的内容,如果不成立返回else的内容 name=input('姓名>>: ') res='SB' if name == 'alex' else 'NB' ...
- python 全栈开发,Day14(列表推导式,生成器表达式,内置函数)
一.列表生成式 生成1-100的列表 li = [] for i in range(1,101): li.append(i) print(li) 执行输出: [1,2,3...] 生成python1期 ...
- python之生成器(~函数,列表推导式,生成器表达式)
一.生成器 概念:生成器的是实质就是迭代器 1.生成器的贴点和迭代器一样,取值方式也和迭代器一样. 2.生成器一般由生成器函数或者声称其表达式来创建,生成器其实就是手写的迭代器. 3.在python中 ...
- Python的高级特性2:列表推导式,生成器与迭代器
一.列表推导式 1.列表推导式是颇具python风格的一种写法.这种写法除了高效,也更简短. In [23]: {i:el for i,el in enumerate(["one" ...
- 2018.11.06 生成器函数进阶&列表推导式&生成器表达式
1.生成器函数进阶 2.列表推导式 3.生成器表达式
- Python-02 生成器表达式,列表推导式
列表推导式和生成器表达式 列表推导式,生成器表达式1,列表推导式比较直观,占内存2,生成器表达式不容易看出内容,省内存. [ 变量(加工后的数据) for 变量i in 可迭代的数据类型 ] 列表 ...
- python 生成器函数.推导式.生成器表达式
一.生成器 什么是生成器,生成器的实质就是迭代器 在python中有三种方式来获取生成器: 1.通过生成器函数 2.通过各种推导式来实现生成器 3.通过数据的转换也可以获取生成器 1 def func ...
- day19-1 迭代器,三元表达式,列表推导式,字典生成式,
目录 迭代器 可迭代对象 迭代器对象 总结 三元表达式(三目表达式) 列表推导式 字典生成式 迭代器 可迭代对象 拥有iter方法的对象就是可迭代对象 # 以下都是可迭代的对象 st = '123'. ...
- python学习day11 函数Ⅲ (内置函数与lambda表达式)
函数Ⅲ(内置函数&lambda表达式) 1.函数小高级 函数可以当做变量来使用: def func(): print(123) func_list = [func, func, func] # ...
随机推荐
- Samba原理和配置
Samba原理和配置 个人原创,转载请注明,否则追究法律责任. 一,原理及安装 1,Samba是在Linux和UNIX系统上实现在局域网上共享文件一种通信协议,它为局域网内的不同计算机之间提供文件等资 ...
- Java 小记 — Spring Boot 注解
前言 本篇随笔将对 Spring Boot 中的常用注解做一个简单的整理归档,写作顺序将从启动类开始并逐步向内外扩展,目的即为了分享也为了方便自己日后的回顾与查阅. 1. Application 启动 ...
- 线程池ThreadPoolExecutor源码解读研究(JDK1.8)
一.什么是线程池 为什么要使用线程池?在多线程并发开发中,线程的数量较多,且每个线程执行一定的时间后就结束了,下一个线程任务到来还需要重新创建线程,这样线程数量特别庞大的时候,频繁的创建线程和销毁线程 ...
- Spring shiro 初次使用小结
首先引入一段关于shiro的介绍: 开发系统中,少不了权限,目前java里的权限框架有SpringSecurity和Shiro(以前叫做jsecurity),对于SpringSecurity:功能太过 ...
- MySQL解决方案
主从复制与主主复制怎么自动切换:使用Keepalived 日常如何导出数据:mysqldump.xtrabackup 主库宕机解决方案(一主多从) 登陆从库>show proce ...
- python趣味 ——奇葩的全局形参
在c++,c#,js等语言中: 函数定义(参数) 函数体:参数修改 这里的参数修改都是仅限于这个函数体内的 python不知道是不是bug,我们这样写: def test(a=[]): a.appen ...
- HTML定位简介
转载出处 定位一直是WEB标准应用中的难点,如果理不清楚定位那么可能应实现的效果实现不了,实现了的效果可能会走样.如果理清了定位的原理,那定位会让网页实现的更加完美. 定位的定义:在CSS中关于定位的 ...
- linux利用ssh远程执行多台机器执行同样的命令
这篇文章主要介绍了ssh远程执行命令方法和Shell脚本实例,本文讲解了ssh执行远程操作方法和远程执行命令shell脚本示例,需要的朋友可以参考下 ssh执行远程操作命令格式代码如下: ssh -t ...
- 10分钟快速入门Redis
Redis安装 来源:https://github.com/jaywcjlove/handbook 官方编译安装 $ wget http://download.redis.io/releases/re ...
- iOS 10.10 10.11 10.12 安装升级CocoPods
CocoPods简介 CocoaPods是一个用Ruby写的,负责管理iOS以及OSX系统下的一个第三方类库管理工具,通过CocoaPods,我们可以集中,统一的管理第三方开源库.当然这些库徐亚Coc ...