linux内核中的链表
1.内核中的链表
linux内核链表与众不同,他不是把将数据结构塞入链表,而是将链表节点塞入数据,在2.1内核中引入了官方链表,从此内核中所有的链表使用都采用此链表,千万不要在重复造车轮子了!链表实现定义在<linux/list.h>,使用内核链表时,包含此文件。
1.1.传统的双向链表和内核中的双向链表的区别
- 有个单独的头结点(head)
- 每个节点(node)除了包含必要的数据之外,还有2个指针(pre,next)
- pre指针指向前一个节点(node),next指针指向后一个节点(node)
- 头结点(head)的pre指针指向链表的最后一个节点
- 最后一个节点的next指针指向头结点(head)
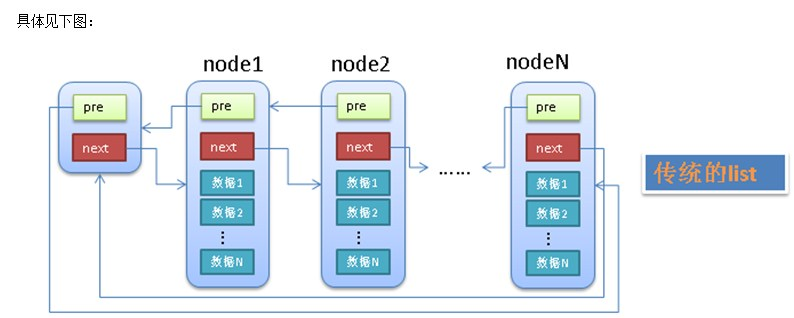
传统的链表有个最大的缺点就是不好共通化,因为每个node中的data1,data2等等都是不确定的(无论是个数还是类型)。linux中的链表巧妙的解决了这个问题,linux的链表不是将用户数据保存在链表节点中,而是将链表节点保存在用户数据中.linux的链表节点只有2个指针(pre和next),这样的话,链表的节点将独立于用户数据之外,便于实现链表的共同操作。
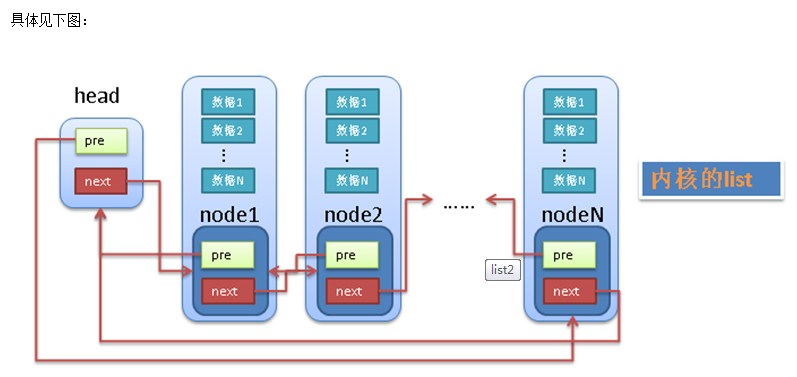
1.2.链表基础数据结构
内核链表节点原型
/* linux/types.h */
struct list_head {
struct list_head *next, *prev;
};
gcc特有的语法支持,根据结构体成员和结构体,算出此成员所在结构体内的偏移量
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
这个宏没什么特别的,主要是container_of这个宏
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
这里面的type一般是个结构体,也就是包含用户数据和链表节点的结构体。
ptr是指向type中链表节点的指针
member则是type中定义链表节点是用的名字
比如:
struct student
{
int id;
char* name;
struct list_head list;
};
- type是struct student
- ptr是指向stuct list的指针,也就是指向member类型的指针
- member就是 list
** 下面分析一下container_of宏: **
// 步骤1:将数字0强制转型为type*,然后取得其中的member元素
((type *)0)->member // 相当于((struct student *)0)->list
// 步骤2:定义一个临时变量__mptr,并将其也指向ptr所指向的链表节点const typeof(((type *)0)->member)*__mptr = (ptr);
// 步骤3:计算member字段距离type中第一个字段的距离,也就是type地址和member地址之间的差
// offset(type, member)也是一个宏,定义如下:#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
// 步骤4:将__mptr的地址 - type地址和member地址之间的差
// 其实也就是获取type的地址
步骤1,2,4比较容易理解,下面的图以sturct student为例进行说明步骤3:
首先需要知道 ((TYPE *)0) 表示将地址0转换为 TYPE 类型的地址
由于TYPE的地址是0,所以((TYPE *)0)->MEMBER 也就是 MEMBER的地址和TYPE地址的差,如下图所示:

2.链表操作的主要函数
2.1.声明和初始化
实际上Linux只定义了链表节点,并没有专门定义链表头,那么一个链表结构是如何建立起来的呢?让我们来看看LIST_HEAD()这个宏
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name)
当我们用LIST_HEAD(nf_sockopts)声明一个名为nf_sockopts的链表头时,它的next、prev指针都初始化为指向自己,这样,我们就有了一个空链表,因为Linux用头指针的next是否指向自己来判断链表是否为空:
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
除了用LIST_HEAD()宏在声明的时候初始化一个链表以外,Linux还提供了一个INIT_LIST_HEAD宏用于运行时初始化链表:
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
2.2.插入/删除/合并
插入
对链表的插入操作有两种:在表头插入和在表尾插入。Linux为此提供了两个接口:
static inline void list_add(struct list_head *new, struct list_head *head);
static inline void list_add_tail(struct list_head *new, struct list_head *head);
因为Linux链表是循环表,且表头的next、prev分别指向链表中的第一个和最末一个节点,所以,list_add和list_add_tail的区别并不大,实际上,Linux分别用
__list_add(new, head, head->next); /*头插*/
__list_add(new, head->prev, head); /*尾插*/
来实现两个接口,可见,在表头插入是插入在head之后,而在表尾插入是插入在head->prev之后。
假设有一个新nf_sockopt_ops结构变量new_sockopt需要添加到nf_sockopts链表头,我们应当这样操作:
list_add(&new_sockopt.list, &nf_sockopts);
从这里我们看出,nf_sockopts链表中记录的并不是new_sockopt的地址,而是其中的list元素的地址。如何通过链表访问到new_sockopt呢?下面会有详细介绍。
删除
static inline void list_del(struct list_head *entry);
当我们需要删除nf_sockopts链表中添加的new_sockopt项时,我们这么操作:
list_del(&new_sockopt.list);
被剔除下来的new_sockopt.list,prev、next指针分别被设为LIST_POSITION2和LIST_POSITION1两个特殊值,这样设置是为了保证不在链表中的节点项不可访问–对LIST_POSITION1和LIST_POSITION2的访问都将引起页故障。与之相对应,list_del_init()函数将节点从链表
中解下来之后,调用LIST_INIT_HEAD()将节点置为空链状态。
搬移
Linux提供了将原本属于一个链表的节点移动到另一个链表的操作,并根据插入到新链表的位置分为两类:
tatic inline void list_move(struct list_head *list, struct list_head *head);
tatic inline void list_move_tail(struct list_head *list, struct list_head *head);
例如list_move(&new_sockopt.list,&nf_sockopts)会把new_sockopt从它所在的链表上删除,并将其再链入nf_sockopts的表头。
合并
除了针对节点的插入、删除操作,Linux链表还提供了整个链表的插入功能:
static inline void list_splice(struct list_head *list, struct list_head *head);
假设当前有两个链表,表头分别是list1和list2(都是struct list_head变量),当调用list_splice(&list1,&list2)时,只要list1非空,list1链表的内容将被挂接在list2链表上,位于list2和list2.next(原list2表的第一个节点)之间。新list2链表将以原list1表的第一个节点为首节点,而尾节点不变.
当list1被挂接到list2之后,作为原表头指针的list1的next、prev仍然指向原来的节点,为了避免引起混乱,Linux提供了一个list_splice_init()函数:
static inline void list_splice_init(struct list_head *list, struct list_head *head);
该函数在将list合并到head链表的基础上,调用INIT_LIST_HEAD(list)将list设置为空链。
遍历
我们知道,Linux链表中仅保存了数据项结构中list_head成员变量的地址,那么我们如何通过这个list_head成员访问到作为它的所有者的节点数据呢?Linux为此提供了一个list_entry(ptr,type,member)宏,其中ptr是指向该数据中list_head成员的指针,也就是
存储在链表中的地址值,type是数据项的类型,member则是数据项类型定义中list_head成员的变量名,例如,我们要访问nf_sockopts链表中首个nf_sockopt_ops变量,则如此调用:
list_entry(nf_sockopts->next, struct nf_sockopt_ops, list);
这里”list”正是nf_sockopt_ops结构中定义的用于链表操作的节点成员变量名。list_entry的使用相当简单,相比之下,它的实现则有一些难懂:
#define list_entry(ptr, type, member) container_of(ptr, type, member)
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
在的nf_register_sockopt()函数中有这么一段话:
struct list_head *i;
list_for_each(i, &nf_sockopts) {
struct nf_sockopt_ops *ops = (struct nf_sockopt_ops *)i;
}
函数首先定义一个(struct list_head *)指针变量i,然后调用list_for_each(i,&nf_sockopts)进行遍历。在<include/linux/list.h>中,list_for_each()宏是这么定义的:
#define list_for_each(pos, head) \
for (pos = (head)->next, prefetch(pos->next); pos != (head); \
pos = pos->next, prefetch(pos->next))
它实际上是一个for循环,利用传入的pos作为循环变量,从表头head开始,逐项向后(next方向)移动pos,直至又回到head(prefetch()可以不考虑,用于预取以提高遍历速度)。
大多数情况下,遍历链表的时候都需要获得链表节点数据项,也就是说list_for_each()和list_entry()总是同时使用。对此Linux给出了一个list_for_each_entry()宏:
#define list_for_each_entry(pos, head, member)
某些应用需要反向遍历链表,Linux提供了list_for_each_prev()和list_for_each_entry_reverse()来完成这一操作,使用方法和上面介绍的list_for_each()、list_for_each_entry()完全相同。
安全性的考虑
在并发执行的环境下,链表操作通常都应该考虑同步安全性问题,为了方便,Linux将这一操作留给应用自己处理。Linux链表自己考虑的安全性主要有两个方面:
a list_empty()判断
基本的list_empty()仅以头指针的next是否指向自己来判断链表是否为空,Linux链表另行提了一个list_empty_careful()宏,它同时判断头指针的next和prev,仅当两者都指向自己时才返回真。这主要是为了应付另一个cpu正在处理同一个链表而造成next、prev不一致的情况。但代码注释也承认,这一安全保障能力有限:除非其他cpu的链表操作只有list_del_init(),否则仍然不能保证安全,也就是说,还是需要加锁保护。
b 遍历时节点删除
前面介绍了用于链表遍历的几个宏,它们都是通过移动pos指针来达到遍历的目的。但如果遍历的操作中包含删除pos指针所指向的节点,pos指针的移动就会被中断,因为list_del(pos)将把pos的next、prev置成LIST_POSITION2和LIST_POSITION1的特殊值。当然,调用者完全可以自己缓存next指针使遍历操作能够连贯起来,但为了编程的一致性,Linux链表仍然提供了两个对应于基本遍历操作的“_safe”接口:list_for_each_safe(pos,n, head)、list_for_each_entry_safe(pos, n, head, member),它们要求调用者另外提供一个与pos同类型的指针n,在for循环中暂存pos下一个节点的地址,避免因pos节点被释放而造成的断链。
3.例子
#include<linux/init.h>
#include<linux/slab.h>
#include<linux/module.h>
#include<linux/kernel.h>
#include<linux/list.h>
MODULE_LICENSE("GPL");
struct student
{
int id;
char *name;
struct list_head list;
};
void print_student(struct student *);
static int testlist_init(void)
{
struct student *stu1, *stu2, *stu3, *stu4;
struct student *stu;
// init a list head
LIST_HEAD(stu_head);
// init four list nodes
stu1 = kmalloc(sizeof(*stu1), GFP_KERNEL);
stu1->id = 1;
stu1->name = "wyb";
INIT_LIST_HEAD(&stu1->list);
stu2 = kmalloc(sizeof(*stu2), GFP_KERNEL);
stu2->id = 2;
stu2->name = "wyb2";
INIT_LIST_HEAD(&stu2->list);
stu3 = kmalloc(sizeof(*stu3), GFP_KERNEL);
stu3->id = 3;
stu3->name = "wyb3";
INIT_LIST_HEAD(&stu3->list);
stu4 = kmalloc(sizeof(*stu4), GFP_KERNEL);
stu4->id = 4;
stu4->name = "wyb4";
INIT_LIST_HEAD(&stu4->list);
list_add (&stu1->list, &stu_head);
list_add (&stu2->list, &stu_head);
list_add (&stu3->list, &stu_head);
list_add (&stu4->list, &stu_head);
list_for_each_entry(stu, &stu_head, list)
{
print_student(stu);
}
// print each student from 1 to 4
list_for_each_entry_reverse(stu, &stu_head, list)
{
print_student(stu);
}
// delete a entry stu2
list_del(&stu2->list);
list_for_each_entry(stu, &stu_head, list)
{
print_student(stu);
}
// replace stu3 with stu2
list_replace(&stu3->list, &stu2->list);
list_for_each_entry(stu, &stu_head, list)
{
print_student(stu);
}
return 0;
}
static void testlist_exit(void)
{
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "testlist is exited!\n");
printk(KERN_ALERT "*************************\n");
}
void print_student(struct student *stu)
{
printk (KERN_ALERT "======================\n");
printk (KERN_ALERT "id =%d\n", stu->id);
printk (KERN_ALERT "name=%s\n", stu->name);
printk (KERN_ALERT "======================\n");
}
module_init(testlist_init);
module_exit(testlist_exit);
linux内核中的链表的更多相关文章
- 拒绝造轮子!如何移植并使用Linux内核的通用链表(附完整代码实现)
在实际的工作中,我们可能会经常使用链表结构来存储数据,特别是嵌入式开发,经常会使用linux内核最经典的双向链表 list_head.本篇文章详细介绍了Linux内核的通用链表是如何实现的,对于经常使 ...
- Linux内核中链表实现
关于双链表实现,一般教科书上定义一个双向链表节点的方法如下: struct list_node{ stuct list_node *pre; stuct list_node *next; ElemTy ...
- linux内核中链表代码分析---list.h头文件分析(一)【转】
转自:http://blog.chinaunix.net/uid-30254565-id-5637596.html linux内核中链表代码分析---list.h头文件分析(一) 16年2月27日17 ...
- linux内核中链表代码分析---list.h头文件分析(二)【转】
转自:http://blog.chinaunix.net/uid-30254565-id-5637598.html linux内核中链表代码分析---list.h头文件分析(二) 16年2月28日16 ...
- Linux内核(10) - 内核中的链表
早上上班坐地铁要排队,到了公司楼下等电梯要排队,中午吃饭要排队,下班了追求一个女孩子也要排队,甚至在网上下载个什么门的短片也要排队,每次看见人群排成一条长龙时,才真正意识到自己是龙的传人.那么下面咱们 ...
- Linux内核中链表的实现与应用【转】
转自:http://blog.chinaunix.net/uid-27037833-id-3237153.html 链表(循环双向链表)是Linux内核中最简单.最常用的一种数据结构. ...
- Linux内核中双向链表的经典实现
概要 前面一章"介绍双向链表并给出了C/C++/Java三种实现",本章继续对双向链表进行探讨,介绍的内容是Linux内核中双向链表的经典实现和用法.其中,也会涉及到Linux内核 ...
- Linux内核中的GPIO系统之(3):pin controller driver代码分析
一.前言 对于一个嵌入式软件工程师,我们的软件模块经常和硬件打交道,pin control subsystem也不例外,被它驱动的硬件叫做pin controller(一般ARM soc的datash ...
- Linux内核中流量控制
linux内核中提供了流量控制的相关处理功能,相关代码在net/sched目录下:而应用层上的控制是通过iproute2软件包中的tc来实现, tc和sched的关系就好象iptables和netfi ...
随机推荐
- 结合Socket实现DDoS攻击
一.实验说明 1. 实验介绍 通过上一节实验的SYN泛洪攻击结合Socket实现DDoS攻击. 2. 开发环境 Ubuntu Linux Python 3.x版本 3. 知识点 本次实验将涉及以下知识 ...
- iOS开发所有KeyboardType与图片对应展示
1.UIKeyboardTypeAlphabet 2.UIKeyboardTypeASCIICapable 3.UIKeyboardTypeDecimalPad 4.UIKeyboardTypeDe ...
- python利用twilio模块给自己发短信
1.访问http://twilio.com/并填写注册表单.注册了新账户后,你需要验证一个手机号码,短信将发给该号码. 2.Twilio 提供的试用账户包括一个电话号码,它将作为短信的发送者.你将需要 ...
- java方法的定义格式
Java的方法类似于其他语言的函数,是一段用来完成特定功能的代码片段,声明格式为: [修饰符1 修饰符2 …..] 返回值类型 方法名( 形式参数列表 ){ Java 语句;… … … } 例如 ...
- display属性
display 属性规定元素应该生成的框的类型. 值 描述 none 此元素不会被显示. block 此元素将显示为块级元素,此元素前后会带有换行符. inline 默认.此元素会被显示为内联元素,元 ...
- php的格式化数字函数
php格式化数字:位数不足前面加0补足 php格式化数字:位数不足前面加0补足 感谢:http://www.cnblogs.com/xiaochaohuashengmi/archive/2011/12 ...
- $.ajax 中的contentType
$.ajax 中的contentType 在 cnodejs.org 论坛中有一个问题,让我也很奇怪,说是 $.ajax 设置数据类型 applicaiton/json之后,服务器端(express) ...
- loadrunner录制时web时,安全证书问题
测试环境:win7+LoadRunner11+ie9 遇到的问题:用LoadRunner录制时,打开百度,总是报安全证书问题,如图所示 解决方法:Tools——Recording Options——p ...
- PIL绘图
# coding:utf-8 # PIL的ImageDraw 提供了一系列绘图方法,让我们可以直接绘图.比如要生成字母验证码图片 from PIL import Image, ImageDraw, I ...
- typeof与instanceof的区别
一.instanceof运算符: 此运算符可以判断一个变量是否是某个对象(类)的实例,返回值是布尔类型的.想要理解它的作用,必须对面向对象有所理解: 代码实例如下: var str=new ...