spark 机器学习基础 数据类型
spark的机器学习库,包含常见的学习算法和工具如分类、回归、聚类、协同过滤、降维等
使用算法时都需要指定相应的数据集,下面为大家介绍常用的spark ml 数据类型。
1.本地向量(Local Vector)
存储在单台机器上,索引采用0开始的整型表示,值采用Double类型的值表示。Spark MLlib中支持两种类型的矩阵,分别是密度向量(Dense Vector)和稀疏向量(Spasre Vector),密度向量会存储所有的值包括零值,而稀疏向量存储的是索引位置及值,不存储零值,在数据量比较大时,稀疏向量才能体现它的优势和价值
scala> import org.apache.spark.mllib.linalg.{Vector, Vectors}
注意:scala默认会导入scala.collection.immutable.Vector,所以必须显式导入org.apache.spark.mllib.linalg.Vector
1.1密度向量,零值也存储
scala> val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
1.2.1创建稀疏向量,指定元素的个数、索引及非零值,数组方式
基于索引(0,2)和值(1,3)创建稀疏向量
scala> val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
1.2.2 创建稀疏向量,指定元素的个数、索引及非零值,采用序列方式
scala> val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))
2.带类标签的特征向量(Labeled point)
Labeled point是Spark MLlib中最重要的数据结构之一,它在无监督学习算法中使用十分广泛,它也是一种本地向量,只不过它提供了类的标签,对于二元分类,它的标签数据为0和1,而对于多类分类,它的标签数据为0,1,2,…。它同本地向量一样,同时具有Sparse和Dense两种实现方式
scala> import org.apache.spark.mllib.regression.LabeledPoint
2.1LabeledPoint第一个参数是类标签数据,第二参数是对应的特征数据
//密度
scala> val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
scala> println(pos.features)
scala> println(pos.label)
//稀疏
scala> val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
注意:第2个特征值为0,从编程的角度来说,这样做可以减少内存的使用,并提高做矩阵内积时的运算速度
3.本地矩阵(Local matrix)
本地向量是由从0开始的整数下标和Double类型的数值组成。它有稠密向量(dense vector)和稀疏向量(sparse vertor)两种。在列的主要顺序中,它的非零输入值存储在压缩的稀疏列(CSC)格式中
在一维数组[1.0、3.0、5.0、2.0、4.0、6.0]中,对应的矩阵大小(3、2):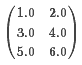
本地矩阵的基类是Matrix,提供了两种实现 DenseMatrix和SparseMatrix. 推荐使用工厂方法实现的Matrices来创建本地矩阵.
scala> import org.apache.spark.mllib.linalg.{Matrix, Matrices}
3.1 创建稠密矩阵
scala> val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
3.2 创建稀疏矩阵
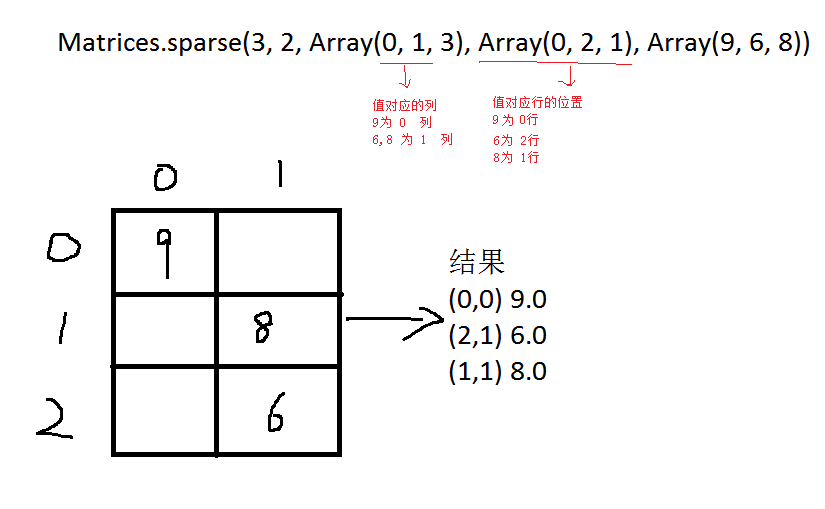
scala> val sm: Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8))
4.分布式矩阵(Distributed matrix)
分布式矩阵有Long类型的行列数据和Double类型值,存储在一个或多个RDDs中
4.1. 行矩阵(RowMatrix)
行矩阵是一个没有行索引的,以行为导向(row-oriented )的分布式矩阵,它的行只支持RDD格式,每一行都是一个本地向量。由于每一行都由一个局部向量表示,所以列的数量是由整数范围所限制的,但是在实际操作中应该要小得多
scala> import org.apache.spark.mllib.linalg.Vector
scala> import org.apache.spark.mllib.linalg.distributed.RowMatrix
scala> import org.apache.spark.mllib.linalg.{Vector, Vectors}
4.1.1 生成DataFrame
scala> val df1 = Seq(
(1.0, 2.0, 3.0),
(1.1, 2.1, 3.1),
(1.2, 2.2, 3.2)).toDF("c1", "c2", "c3")
scala> df1.show
c1 c2 c3
1.0 2.0 3.0
1.1 2.1 3.1
1.2 2.2 3.2
4.1.2 DataFrame转换成RDD[Vector]
scala> val rv1= df1.rdd.map {
x =>Vectors.dense(
x(0).toString().toDouble,
x(1).toString().toDouble,
x(2).toString().toDouble)
}
scala> rv1.collect()
4.1.3 创建行矩阵
scala> val mt1: RowMatrix = new RowMatrix(rv1)
scala> val m = mt1.numRows()
scala> val n = mt1.numCols()
查看:
scala> mt1.rows.collect()
或
scala>mt1.rows.map { x =>
(x(0).toDouble,
x(1).toDouble,
x(2).toDouble)
}.collect()
4.2 CoordinateMatrix坐标矩阵
CoordinateMatrix是一个分布式矩阵,每行数据格式为三元组(i: Long, j: Long, value: Double), i表示行索引,j表示列索引,value表示数值。只有当矩阵的两个维度都很大且矩阵非常稀疏时,才应该使用坐标矩阵。可以通过RDD[MatrixEntry]实例来创建一个CoordinateMatrix。MatrixEntry包装类型(Long, Long, Double)
scala> import org.apache.spark.mllib.linalg.distributed.CoordinateMatrix
scala> import org.apache.spark.mllib.linalg.distributed.MatrixEntry
4.2.1 生成df(行坐标,列坐标,值)
scala> val df = Seq(
(0, 0, 1.1), (0, 1, 1.2), (0, 2, 1.3),
(1, 0, 2.1), (1, 1, 2.2), (1, 2, 2.3),
(2, 0, 3.1), (2, 1, 3.2), (2, 2, 3.3)).toDF("row", "col", "value")
4.2.2 生成入口矩阵
scala> val m1 = df.rdd.map { x =>
val a = x(0).toString().toLong
val b = x(1).toString().toLong
val c = x(2).toString().toDouble
MatrixEntry(a, b, c)
}
scala> m1.collect()
4.2.3 生成坐标矩阵
scala> val m2 = new CoordinateMatrix(m1)
scala> m2.numRows()
scala> m2.numCols()
查看
scala> m2.entries.collect().take(10)
spark 机器学习基础 数据类型的更多相关文章
- Spark机器学习基础三
监督学习 0.线性回归(加L1.L2正则化) from __future__ import print_function from pyspark.ml.regression import Linea ...
- Spark机器学习基础二
无监督学习 0.K-means from __future__ import print_function from pyspark.ml.clustering import KMeans #from ...
- Spark机器学习基础一
特征工程 对连续值处理 0.binarizer/二值化 from __future__ import print_function from pyspark.sql import SparkSessi ...
- Spark机器学习基础-监督学习
监督学习 0.线性回归(加L1.L2正则化) from __future__ import print_function from pyspark.ml.regression import Linea ...
- Spark机器学习基础-无监督学习
0.K-means from __future__ import print_function from pyspark.ml.clustering import KMeans#硬聚类 #from p ...
- Spark机器学习基础-特征工程
对连续值处理 0.binarizer/二值化 from __future__ import print_function from pyspark.sql import SparkSession fr ...
- Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API
Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API 关键词:Local vector,Labeled point,Local matrix,Distrib ...
- Spark机器学习4·分类模型(spark-shell)
线性模型 逻辑回归--逻辑损失(logistic loss) 线性支持向量机(Support Vector Machine, SVM)--合页损失(hinge loss) 朴素贝叶斯(Naive Ba ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
随机推荐
- WinForm中DataGridView对XML文件的读取
转自http://www.cnblogs.com/a1656344531/archive/2012/11/28/2792863.html c#读取XML XML文件是一种常用的文件格式,例如Win ...
- ;(function(){})()这种写法分号的作用 todomvc
常看到一些大牛的JS源码 在function 前面加; ;function($,undefined) 是什么用处 ? ;(function($){$.extend($.fn... 在前面加分号可以有多 ...
- 如何通过织云 Lite 愉快地玩转 TSW
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 织云 Lite & TSW 织云 Lite 是一款轻量型服务管理平台,提供标准化的应用打包操作,可连接持续集成系统,完成线上程序分发 ...
- MySQL 大表优化方案
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- 「WC 2018」州区划分
题目大意: 给一个无向图$G(V,E)$满足$|V|<=21$,对于某一种将$G(V,E)$划分为k个的有序集合方案,若每一个子集$G_i(V_i,E_i)$,$E_i=\{(x,y)|x\in ...
- bzoj 2821 作诗 分块
基本思路和蒲公英一样 还是预处理出每两个块间的答案 询问时暴力跑两边的贡献 #include<cstdio> #include<cstring> #include<ios ...
- BZOJ_3436_小K的农场_差分约束
BZOJ_3436_小K的农场_差分约束 题意: 小K在MC里面建立很多很多的农场,总共n个,以至于他自己都忘记了每个农场中种植作物的具体数量了,他只记得 一些含糊的信息(共m个),以下列三种形式描述 ...
- Postman----打开postman console控制台,查看接口测试打印log
经常在脚本中使用变量时,你可能需要看到变量获取到的值,你可以使用Postman Console去实现的.操作步骤:应用菜单-->View--->Show Postman Console,去 ...
- selenium+python,解决selenium弹出新页面,无法定位元素的问题(报错:Unable to locate element:元素)
1.问题发生描述: 从一个页面进行点击等操作,页面跳转到第二个页面,对第二个页面中的元素,采取任何措施定位都报错,问题报错点如下: 2.出现问题的原因: 窗口句柄还停留在上一个页面,对于当前新弹出的页 ...
- 从零开始学 Web 之 CSS(三)链接伪类、背景、行高、盒子模型、浮动
大家好,这里是「 Daotin的梦呓 」从零开始学 Web 系列教程.此文首发于「 Daotin的梦呓 」公众号,欢迎大家订阅关注.在这里我会从 Web 前端零基础开始,一步步学习 Web 相关的知识 ...