AI - TensorFlow - 过拟合(Overfitting)
过拟合
过拟合(overfitting,过度学习,过度拟合):
过度准确地拟合了历史数据(精确的区分了所有的训练数据),而对新数据适应性较差,预测时会有很大误差。
过拟合是机器学习中常见的问题,解决方法主要有下面几种:
1. 增加数据量
大部分过拟合产生的原因是因为数据量太少。
2. 运用正则化
例如L1、L2 regularization等等,适用于大多数的机器学习,包括神经网络。
3. Dropout
专门用在神经网络的正则化的方法。
Dropout regularization是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络。
只需要给予它一个不被drop掉的百分比,就能很好地降低overfitting。
也就是说,在训练的时候,随机忽略掉一些神经元和神经联结 ,使这个神经网络变得”不完整”,然后用一个不完整的神经网络训练一次。
到第二次再随机忽略另一些, 变成另一个不完整的神经网络。
有了这些随机drop掉的规则, 每一次预测结果都不会依赖于其中某部分特定的神经元。
Dropout的做法是从根本上让神经网络没机会过度依赖。
TensorFlow中的Dropout方法
TensorFlow提供了强大的dropout方法来解决overfitting问题。
示例
# coding=utf-8
from __future__ import print_function
import tensorflow as tf
from sklearn.datasets import load_digits # 使用sklearn中的数据
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '' digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) # X_train是训练数据, X_test是测试数据 def add_layer(inputs, in_size, out_size, layer_name, activation_function=None, ):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, )
Wx_plus_b = tf.matmul(inputs, Weights) + biases
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob) # dropout
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.summary.histogram(layer_name + '/outputs', outputs)
return outputs keep_prob = tf.placeholder(tf.float32) # keep_prob(保留的结果所占比例)作为placeholder在run时传入
xs = tf.placeholder(tf.float32, [None, 64])
ys = tf.placeholder(tf.float32, [None, 10]) l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh) # 隐含层
prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax) # 输出层 cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss between prediction and real data
tf.summary.scalar('loss', cross_entropy)
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.Session()
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter("logs/train", sess.graph)
test_writer = tf.summary.FileWriter("logs/test", sess.graph)
init = tf.global_variables_initializer()
sess.run(init) for i in range(500):
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5}) # keep_prob=0.5相当于50%保留
if i % 50 == 0:
train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1})
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1})
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i)
对比运行结果
在TensorBoard中查看。
训练中keep_prob=1时,暴露出overfitting问题,模型对训练数据的适应性优于测试数据,存在overfitting。
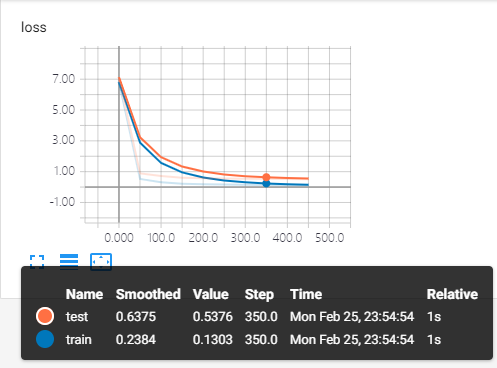
keep_prob=0.5时,dropout发挥了作用,减少了过拟合。

AI - TensorFlow - 过拟合(Overfitting)的更多相关文章
- AI - TensorFlow - 示例04:过拟合与欠拟合
过拟合与欠拟合(Overfitting and underfitting) 官网示例:https://www.tensorflow.org/tutorials/keras/overfit_and_un ...
- tensorflow学习4-过拟合-over-fitting
过拟合: 真实的应用中,并不是让模型尽量模拟训练数据的行为,而是希望训练数据对未知做出判断. 模型过于复杂后,模型会积极每一个噪声的部分,而不是学习数据中的通用 趋势.当一个模型的参数比训练数据还要多 ...
- 过拟合(Overfitting)和正规化(Regularization)
过拟合: Overfitting就是指Ein(在训练集上的错误率)变小,Eout(在整个数据集上的错误率)变大的过程 Underfitting是指Ein和Eout都变大的过程 从上边这个图中,虚线的左 ...
- AI - TensorFlow - 示例03:基本回归
基本回归 回归(Regression):https://www.tensorflow.org/tutorials/keras/basic_regression 主要步骤:数据部分 获取数据(Get t ...
- AI - TensorFlow - 示例01:基本分类
基本分类 基本分类(Basic classification):https://www.tensorflow.org/tutorials/keras/basic_classification Fash ...
- tensorflow神经网络拟合非线性函数与操作指南
本实验通过建立一个含有两个隐含层的BP神经网络,拟合具有二次函数非线性关系的方程,并通过可视化展现学习到的拟合曲线,同时随机给定输入值,输出预测值,最后给出一些关键的提示. 源代码如下: # -*- ...
- TensorFlow非线性拟合
1.心得: 在使用TensorFlow做非线性拟合的时候注意的一点就是输出层不能使用激活函数,这样就会把整个区间映射到激活函数的值域范围内无法收敛. # coding:utf-8 import ten ...
- AI - TensorFlow - 示例02:影评文本分类
影评文本分类 文本分类(Text classification):https://www.tensorflow.org/tutorials/keras/basic_text_classificatio ...
- AI - TensorFlow - 分类与回归(Classification vs Regression)
分类与回归 分类(Classification)与回归(Regression)的区别在于输出变量的类型.通俗理解,定量输出称为回归,或者说是连续变量预测:定性输出称为分类,或者说是离散变量预测. 回归 ...
随机推荐
- ImageMagick简介、GraphicsMagick、命令行使用示例
http://elf8848.iteye.com/blog/382528 ImageMagick资料 ------------------------------------------------- ...
- ESXI的安装和部署
1. 实验拓扑图: 2. 实验要求 (1) 新建一台exsi主机,安装exsi5.5系统. 步骤: 1)新建虚拟机,导入光盘. 2)安装esxi系统 (2)在exsi主机中,配置IP地址为1 ...
- 浅谈cookie,sessionStorage和localStorage
cookie:cookie在浏览器和服务器间来回传递 cookie数据不能超过4k 同时每次http请求都会携带cookie,所以cookie只适合保存很小的数据,比如会话标识 cookie只在设置的 ...
- java基础学习周计划之1--语言基础
JAVA语言基础第一天一. 知识点:1. 认识Linux操作系统2. JAVA开发环境3. Eclipse IDE二. 关键问题(理论):1. Linux中常用命令pwd.ls.cd的作用2. 简述J ...
- 转载iOS开发中常见的警告及错误
iOS警告收录及科学快速的消除方法 前言:现在你维护的项目有多少警告?看着几百条警告觉得心里烦么?你真的觉得警告又不是错误可以完全不管么? 如果你也被这些问题困惑,可以和我一起进行下面的操作. ...
- (4)STM32使用HAL库实现串口通讯——理论讲解
一.查询模式 1. 二.中断模式 1.中断接收. 1.1先看中断接收的流程(以 USART2 为例) 在启动文件中找到中断向量 USART2_IRQHandler 找到USART2_IRQHandle ...
- C语言文件 "w+"与"wb+"区别
这是我今天碰到的问题,现在已经解决, 希望我的整理能够帮助到你们! w+以纯文本方式读写,而wb+是以二进制方式进行读写. mode说明: w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会 ...
- Windows环境下消息中间件RabbitMq的搭建与应用
前言 消息中间件目前已经在很多大型的项目上得到了运用,我们常见的有 RabbitMq, activitymq,kafka,rocketmq,其中rocketmq是阿里自己在kafka的基础上用java ...
- 深入学习Redis(2):持久化
前言 在上一篇文章中,介绍了Redis的内存模型,从这篇文章开始,将依次介绍Redis高可用相关的知识——持久化.复制(及读写分离).哨兵.以及集群. 本文将先说明上述几种技术分别解决了Redis高可 ...
- Jenkins 集成 SonarQube Scanner
1. 安装Jenkins 下载安装包,这里我们下载war包 https://jenkins.io/download/ 运行jenkins.war的方式有两种: 第一种:将其放到tomcat中运行( ...