PageRank之基于C C#的基本实现
重点不是说PageRank是什么,而是怎么实现PageRank
什么是PageRank?
PageRank,网页排名,又称网页级别、Google左侧排名或佩奇排名,是一种由[1] 根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。Google的创始人拉里·佩奇和谢尔盖·布林于1998年在斯坦福大学发明了这项技术。
PageRank的诞生背景?
早期的搜索引擎经历了“不评价” 和“基于检索词”的评价两个阶段。 “基于检索词”的评价算法很直观,但是容易受到“Term Spam”的攻击。其实从搜索引擎出现的那天起,spammer和搜索引擎反作弊的斗法就没有停止过。Spammer是这样一群人——试图通过搜索引擎算法的漏洞来提高目标页面(通常是一些广告页面或垃圾页面)的重要性,使目标页面在搜索结果中排名靠前。用户很容易被带入垃圾网页,用户体验极差。PageRank也应运而生。
怎么实现PageRank?
简单的说PageRank让链接来"投票",一个页面的“得票数”由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(“链入页面”)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
最简单pagerank模型
网页,可以抽象成的图当中的结点,网页与网页当中的链接关系可以模型化为数据结构中逻辑结构图再具体点是有向图(表示哪个网页链接哪个网页),我们可以把链接关系用作离散数学图论当中的可达矩阵形象具体的表示,下面我来给大家具体的说明,如下面这个例子:

这个例子中有四个网页,如果当前在A网页,那么上网者将会各有1/3的概率浏览到B、C、D网页,这里的3表示A有3条出链,如果一个网页有k条出链,那么跳转任意一个出链上的概率是1/k,同理D到B的概率1,而B到C的概率为1。一般用转移矩阵表示上网者的跳转概率,如果用n表示网页的数目,则转移矩阵M是一个n*n的方阵(可由可达矩阵转换成转移矩阵);如果网页j有k个出链,那么对每一个出链指向的网页i,有M[i][j]=1/k,而其他网页的M[i][j]=0;上面示例图对应的可达矩阵如下:
A B C D
A 0 1 0 0
B 1 0 0 1
C 1 1 0 0
D 1 0 1 0
对应的转移矩阵为:
A B C D
A 0 0.5 0 0
B 0.33 0 0 1
C 0.33 0.5 0 0
D 0,33 0 1 0
刚开始的时候,假设上网者在每一个网页的概率都是相等的(这个假设确实存在,假设世界上只有n个网页,那么我只能开始的时候进入n个网页当中的一个,就是1/n),即1/n,于是开始的时候的概率分布就是一个所有值都为1/n的n维列向量V0(我们以概率分布向量的结果作为网页的质量结果,因为质量越高,被上网者浏览的概率越大,也称pr值的大小),在转移矩阵M去右乘概率分布向量V0,就得到了第一步之后上网者的概率分布向量MV0,(nXn)*(nX1)依然得到一个nX1的矩阵。下面是V1的计算过程:

注意矩阵M中M[i][j]不为0表示用一个链接从j指向i,M的第一行乘以V0,表示累加所有网页到网页A的概率即得到0.125。得到了V1后,再用V1去右乘M得到V2,一直下去,最终V会收敛,即Vn=MV(n-1),上面的图示例,不断的迭代,最终
V=[0.177,0.319,0.225,0.277]’
(算法的证明这里我们就不证明了,有兴趣的朋友可以百度一下)
终止点问题
上述上网者的行为是一个马尔科夫过程的实例,要满足收敛性,需要具备一个条件:
图是强连通的,即从任意网页可以到达其他任意网页.
但是在浩瀚的互联网中,网页肯定是不满足强连通特性的,我们设计模型的时候想要达到强连通特性是很简单的,但是在互联网上有一些网页不指向任何网页,如果按照上面的计算,当浏览到这个没有指向的网页的时候那是不是就无法出去了呢?,导致前面累计得到的转移概率被清零,这样下去,最终的得到的概率分布向量所有元素几乎都为0。假设我们把上面图中B到A的链接丢掉,A变成了一个终止点,得到下面这个图:
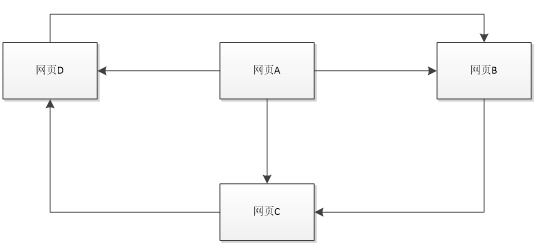
对应的转移矩阵为:
A B C D
A 0 0 0 0
B 0.33 0 0 1
C 0.33 1 0 0
D 0.33 0 1 0
连续迭代下去,最终所有元素都为0。
陷阱问题
要是有投机取巧这想到用网页自己链接自己,让我们浏览这中了这个无线循环的陷阱怎么办呢?:
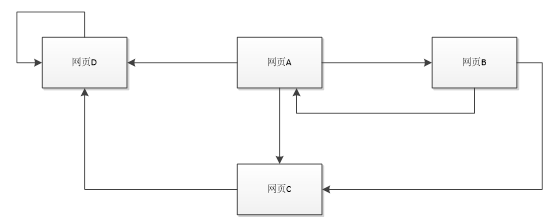
上网者跑到D网页后,再也不能从D中出来,将最终导致概率分布值全部转移到D上来,这使得其他网页的概率分布值为0,从而整个网页排名就失去了意义。如果按照上面图对应的转移矩阵为:
A B C D
A 0 0.5 0 0
B 0.33 0 0 0
C 0.33 0.5 0 0
D 0,33 0 1 1
不断的迭代下去,的结果一定会是[0,0,0,1]的
解决终止点问题和陷阱问题
其实会出现这两个问题,是因为最开始构建模型的时候我们忽略了一个东西:上网者可以随时跳出他浏览的网页(浏览器上输入网址就行了),而不需要担心,要是浏览的网页没有链接那不就是不能出去了吗?(结果只需要输入网址就可以跳出去),那浏览的网页连接了自己浏览这不就一直在浏览这个了吗?(结果是浏览者发现这是陷阱都在重复浏览一个网页的时候,他可以轻松跳过去,只需要输入网址即可),当然正常情况他也是可以输入网址跳转任何他想去的网页,这个时候我们需要引入一个概念:阻尼系数(简单来说就是点击网页的概率-实际上就是用户感到无聊,停止点击,随机跳到新URL的概率),这里我们取α = 0.8,当然也有很多的觉得0.85是好的,这个概念已经给出,数值看我们自己~(觉得能让你的结果符合预期就ok啦..)。 从而我们得到了更加完善的公式:
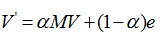
由于这些是数学上的计算,有了公式是比较容易推出结果来的,所以就不在举例啦~~
如何通过代码具体的实现?
可以把每个网页所构成的复杂的关系模型化成数据结构的逻辑结构图(有向图),每个网页就是一个结点,当一个网页(网页A)链接着另一个网页(网页B)的时候可以抽象的看出A->B,即通过出度和入度来描述链接和被链接数,当你通过创建有向图的时候其实就相当于模拟了网页之间的关系(当然浩瀚的互联网中网页数不胜数,我这里只是通过一个小的环境模拟这个算法的实现),通过PageRank算法加之迭代,使其每个网页的pr(衡量网页质量的参数)值都趋于稳定的时候,由pr值大小排序出来的网页的先后顺序可以相对准确的衡量网页质量。
我先是通过c语言模型化PageRank的算法 算出每个结点(网页)的pr值。
需要构建有向图来模型化网页(c语言的结点是手动输入的,因为为了测试方便嘛~)
- #include <stdio.h>
- #include <stdlib.h>
- #include <math.h>
- #define OK 1
- #define ERROR -1
- #define FALSE 0
- #define TRUE 1
- #define MAXVER 20 //定义最大顶点数
- #define MAXQSIZE 100
- //#define OVERFLOW -2
- typedef char verType; //顶点类型
- typedef int Status;
- typedef int Boolean;
- typedef struct
- {
- verType verx[MAXVER];
- int arcs[MAXVER][MAXVER]; //邻接矩阵
- int vernum, arcnum; //定义最大顶点数 和 弧
- }MGraph;
- Boolean visited[MAXVER]; //顶点开始都没有被访问过
- int locate(MGraph G, verType ch); //查找顶点在数组中的下标
- Status CreateDG(MGraph *G,int v); //创建有向图
- void Create_Transfer_matrix(MGraph G, double ***F); //创建转移矩阵
- double** Mat_mul(double **M1, int num); //矩阵相乘
- int GetNum(MGraph G, int h, int l); //得到每一行非0项的个数
- double *Iteration(double *M1, double **M2, double *M, int num); //迭代法
- int main(void)
- {
- double **F = NULL;
- MGraph G;
- CreateDG(&G, );
- Create_Transfer_matrix(G, &F);
- Mat_mul(F, G.vernum);
- return ;
- }
- double *Iteration(double *M1, double **M2, double *M, int num)
- {//迭代法
- double *M3, temp = ;
- int i, j;
- M3 = malloc(num * sizeof(double));
- printf("\n");
- for(i = ; i < num; i++)
- {
- printf("@ = %0.10lf\n", M[i]);
- }
- for (i = ; i < num; i++)
- {
- for (j = ; j < num; j++)
- {
- temp = M1[j] * M2[i][j] + temp;
- }
- M3[i] = temp + M[i];
- temp = ;
- }
- putchar();
- for (i = ; i < num; i++)
- {
- printf("%.10lf\n", M3[i]);
- }
- putchar();
- return M3;
- }
- double** Mat_mul(double **M1, int num)
- {
- int i,j;
- double *M2, *M3, temp = , *M;
- M3 = malloc(num *sizeof(double));
- M2 = malloc(num * sizeof(double));
- for (i = ; i < num; i++) //初始化概率分布矩阵
- {
- M2[i] = (1.0 / num * 1.0);
- }
- for (i = ; i < num; i++)
- {
- for (j = ; j < num; j++)
- {
- temp = M1[i][j] * M2[j] + temp;
- }
- M3[i] = temp + M2[i] * 0.2;
- temp = ;
- }
- for (i = ; i < num; i++)
- {
- printf("%.10lf\n", M3[i]);
- }
- for (j = ; j < num; j++)
- {
- M2[j] = M2[j] * 0.2;
- }
- M = Iteration(M3, M1, M2, num); //调用函数实现转移矩阵和概率向量的相乘
- while (fabs(M[] - M3[]) > 0.0000000001) //设置迭代结束条件
- {
- M3 = M;
- M = Iteration(M3, M1, M2, num);
- }
- for (i = ; i < num; i++)
- {
- M[i] = M[i] * 0.8 + 0.2 / num;
- }
- for (i = ; i < num; i++)
- printf(" - %.10lf\n", M3[i] - 0.0000000001);
- return M1;
- }
- void Create_Transfer_matrix(MGraph G, double ***F)
- {//创建转移矩阵
- int i, j;
- (*F) = malloc(G.vernum * sizeof(double *));
- for (i = ; i < G.vernum; i++)
- {
- (*F)[i] = malloc(G.vernum * sizeof(double));
- }
- for (i = ; i < G.vernum; i++)
- {
- for (j = ; j < G.vernum; j++)
- {
- if (GetNum(G, G.vernum, i) == )
- (*F)[j][i] = ;
- else
- (*F)[j][i] = 0.8 * (G.arcs[j][i] / (GetNum(G, G.vernum, i) * 1.0));
- }
- }
- putchar();
- printf("\n转移矩阵为:\n");
- for (i = ; i < G.vernum; i++)
- {
- for (j = ; j < G.vernum; j++)
- {
- printf("%.10lf ", (*F)[i][j]);
- }
- printf("\n");
- }
- printf("\n");
- }
- int locate(MGraph G, verType ch)
- {
- int i;
- for (i = ; i < G.vernum && ch != G.verx[i]; i++);
- return i;
- }
- Status CreateDG(MGraph *G,int v)
- {
- int i, j, k;
- verType ch1, ch2;
- printf("请输入有向图的顶点数和弧数,格式如(0 0): ");
- scanf("%d %d", &G->vernum, &G->arcnum);
- fflush(stdin); //除缓存
- printf("请输入顶点符号:\n");
- for (i = ; i < G->vernum; i++)
- {
- scanf("%c", &G->verx[i]);
- fflush(stdin);
- }
- for (i = ; i < G->vernum; i++)
- {
- for (j = ; j < G->vernum; j++)
- {
- G->arcs[i][j] = ; //赋初值
- }
- }
- printf("请输入有连接的点: 格式(A B)\n");
- for (i = ; i < G->arcnum; i++)
- {
- printf("请输入第%d对值\n", i + );
- scanf("%c %c", &ch1, &ch2); //输入顶点符号
- fflush(stdin);
- k = locate(*G, ch1); //获得顶点下标
- j = locate(*G, ch2);
- G->arcs[j][k] = ; //为邻接矩阵赋值
- }
- return OK;
- }
- int GetNum(MGraph G, int h, int l) //得到每一列非0的个数
- {
- int i, Num = ;
- for (i = ; i < h; i++)
- {
- if (G.arcs[i][l] > )
- {
- Num++;
- }
- }
- return Num;
- }
虽然实现了PageRank的算法但是仅仅是实现了而且,想要有趣一点的话可以简单模拟一下PageRank的应用背景:我在一个文件夹下面建立的多个HTML的网页(相互之间有链接),通过PageRank算法把每个网页的质量进行了排名,由程序给出排名顺序反馈给用户(通过C#实现的)
这个是提前创好的简单的HTML网页(我的目的是模拟,所有网页只有一个标签,有的连标签都没有……)
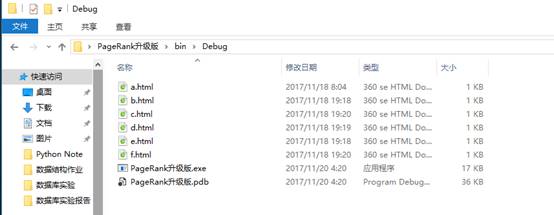
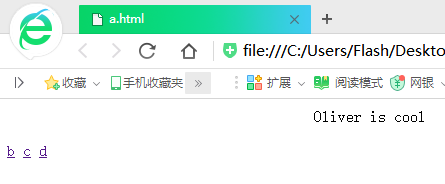

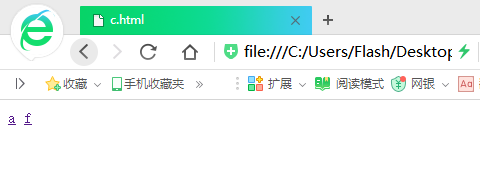
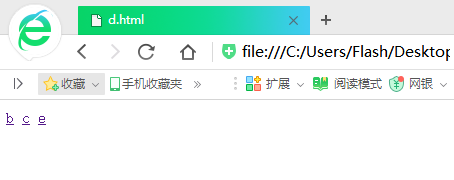
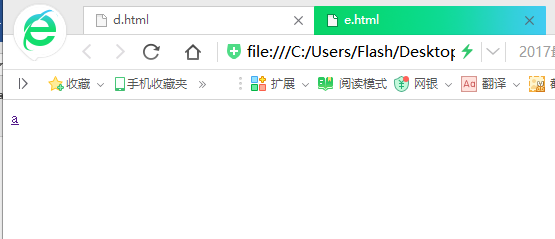
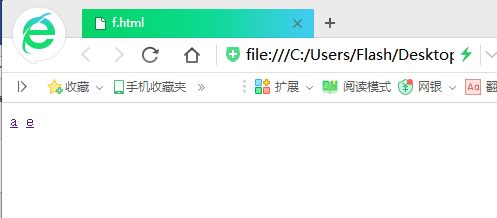
大家可以看出a是被链接最多的网页,其他的被链接的先后顺序相信大家也可以看出来,下面开始演示程序:
1.首先输入网页所在的文件夹:
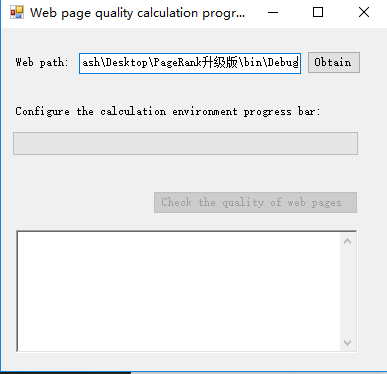
2.通过配置计算环境及其其他的相关事宜:
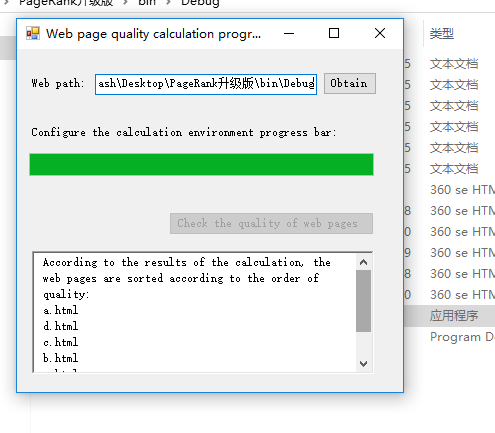
3.获得网页质量:

通过程序的排序已经将质量相当大小反馈给用户,用户可以选择性的浏览网页
我们用C语言的来验证每个网页的pr值是否真如此程序所言

(注意 – 是一个标志,表示最终迭代的结果…) 由上到下依次为A~F的pr值,正如C#的程序排序所言,证明这个是合理的
------由于c#的代码不是一两张图片就可以解释的清楚的,所有有兴趣的朋友可以一起探讨和分享。
(这个程序是我才学习了C#写的,如果有什么不足或者错误之处请多多包涵)
需要源码的朋友可以评论区或者私信我留下你们的邮件,我看到后会尽快发给你们源码滴,大家一起进步一起学习
PageRank之基于C C#的基本实现的更多相关文章
- 论文--Topic-Sensitive PageRank
背景 原有的PageRank方法:通过web上链接结构信息得到页面之间相对的重要性,和特定的查询内容无关 论文涉及到的其他算法 HITS Hilltop,处理常见的流行查询 popular query ...
- 我眼中的PageRank算法详解
随着互联网的发展,网络上已有的网页数量庞大,并且每天都会有很多网页发布,如何权衡这些重要度的排名是一个很重要的问题.我们今天就来了解一下PageRank算法. 首先我们要来了解一下图的概念,请看图1. ...
- Google搜索排名优化-面向搜索引擎的网站设计
内容摘要:网站在搜索营销方面最主要的缺点: 行业知识:不知道搜索引擎对吸引的新用户的重要性,在搜索引擎排名服务中追求“傻瓜相关”,购买一些其实没有太多实际意义的行业关键词.其实能够用户输入的关键词越多 ...
- 基于Neo4j的个性化Pagerank算法文章推荐系统实践
新版的Neo4j图形算法库(algo)中增加了个性化Pagerank的支持,我一直想找个有意思的应用来验证一下此算法效果.最近我看Peter Lofgren的一篇论文<高效个性化Pagerank ...
- 基于胜率矩阵的PageRank排序
在做博弈模型评估的时候,遇到一个问题是如何评价多个模型的优劣.例如我有训练好的三个围棋模型A,B,C,两两之间对打之后有一个胜负关系,如何对这三个模型进行排序呢?通常对于人类选手这种水平有波动的情 ...
- PageRank理论与实践及用户评分应用PeopleRank算法
PageRank,网页排名,又称网页级别.Google左侧排名或佩奇排名,是一种由根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一. Google用它来体现网页的相关性和重要性,在搜索引擎 ...
- RDD:基于内存的集群计算容错抽象(转)
原文:http://shiyanjun.cn/archives/744.html 该论文来自Berkeley实验室,英文标题为:Resilient Distributed Datasets: A Fa ...
- 张洋:浅析PageRank算法
本文引自http://blog.jobbole.com/23286/ 很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看 ...
- 谷歌的网页排序算法(PageRank Algorithm)
本文将介绍谷歌的网页排序算法(PageRank Algorithm),以及它如何从250亿份网页中捞到与你的搜索条件匹配的结果.它的匹配效果如此之好,以至于“谷歌”(google)今天已经成为一个被广 ...
随机推荐
- struts2基于注解配置action
如果使用struts2,就需要配置文件或者注解,关于struts2的配置文件struts.xml非常熟悉,对于注解可能spring使用的比较多.配置文件的繁琐衬托出了注解的简洁方便,一条或者几条注解解 ...
- 自己动手写泛型dao
在经过一系列的问题得到解决之后,泛型dao终于写出来了.泛型dao相比于以前写的dao最大的好处就是,大大提高了代码的复用性,以往我们要对数据库中表中的数据进行操作的时候,每张表都需要写一个dao来操 ...
- SqlSever数据库实践周
资源下载 进行了为期5天的数据库设计,虽然以前用过数据库,但是这一次是使用书上规范的设计流程设计的数据库,感觉有必要记录一下,希望对其他人有帮助. 我的收获:在这个博客中会体现到我的收获,对于将要进行 ...
- 设置placeholder字体的颜色
::-webkit-input-placeholder { /* WebKit browsers */ color:#999; } :-moz-placeholder { /* Mozilla Fir ...
- Spring AOP: 织入的顺序
spring AOP 采用和 AspectJ 一样的优先顺序来织入增强处理:在进入连接点时,高优先级的增强处理将先被织入:在退出连接点时,高优先级的增强处理会后被织入. 当不同的切面里的两个增强处理需 ...
- 最近用spring4.x整合Jackson------>java.lang.ClassNotFoundException:
最近用spring4.x整合Jackson,结果莫名其妙的一直报错,网上收索的结果都是在maven或者gradle的环境下配置依赖条件解决的:但是eclipseIDE环境下的jar包应该是会自动依赖影 ...
- Matlab绘图基础——绘制等高线图
% 等高线矩阵的获取 C = contourc(peaks(20),3); % 获取3个等级的等高线矩阵 % 等高线图形的绘制 contour(peaks(20),10);c ...
- node.js应用脚手架:koa2、sequelize、mysql
自制了一个 nodejs 应用的脚手架. 基于 koa2 的,所以需要保证 node 环境至少为 7.6.0 吸取了以前的踩坑教训,添加了守护进程,确保应用不会因为异常导致网站直接挂掉(使用了 for ...
- [BZOJ 4419][Shoi2013]发微博
4419: [Shoi2013]发微博 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 665 Solved: 364[Submit][Status] ...
- 【Spring源码深度解析学习系列】默认标签解析(三)
Spring的标签包括默认标签和自定义标签两种 默认标签的解析方法: ###DefaultBeanDefinitionDocumentReader.java### private void parse ...