【spring源码分析】IOC容器初始化(三)
前言:在【spring源码分析】IOC容器初始化(二)中已经得到了XML配置文件的Document实例,下面分析bean的注册过程。
XmlBeanDefinitionReader#registerBeanDefinitions(Document doc, Resource resource)
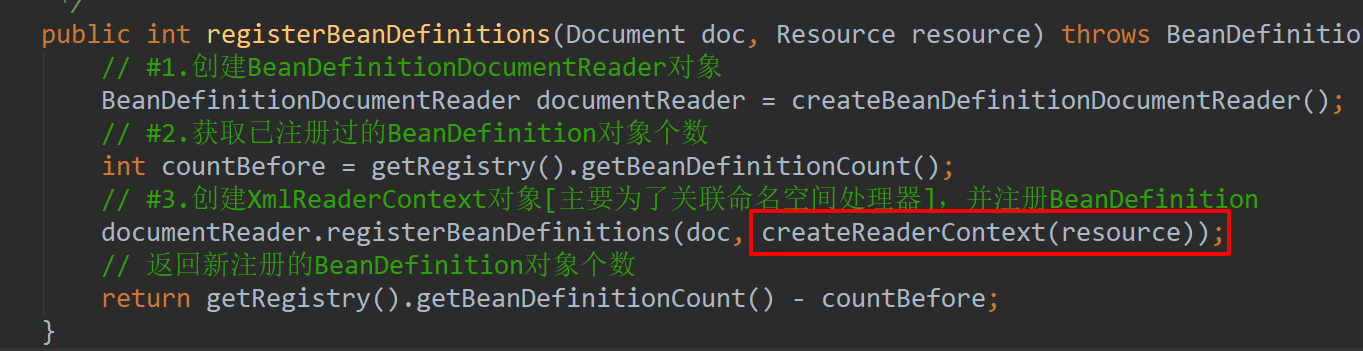
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
// #1.创建BeanDefinitionDocumentReader对象
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
// #2.获取已注册过的BeanDefinition对象个数
int countBefore = getRegistry().getBeanDefinitionCount();
// #3.创建XmlReaderContext对象[主要为了关联命名空间处理器],并注册BeanDefinition
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 返回新注册的BeanDefinition对象个数
return getRegistry().getBeanDefinitionCount() - countBefore;
}
分析:
- 首先创建BeanDefinitionDocumentReader对象。
- 获取已注册过的BeanDefinition个数。
- 然后进入核心处理流程,注册BeanDefinition。
- 最后返回新注册的BeanDefinition个数。
XmlBeanDefinitionReader#createBeanDefinitionDocumentReader
protected BeanDefinitionDocumentReader createBeanDefinitionDocumentReader() {
return BeanDefinitionDocumentReader.class.cast(BeanUtils.instantiateClass(this.documentReaderClass));
}
分析:通过反射得到BeanDefinitionDocumentReader对象。
DefaultListableBeanFactory#getBeanDefinitionCount
/**
* 存储beanName->BeanDefinition的集合map<br/>
* Map of bean definition objects, keyed by bean name.
*/
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256); public int getBeanDefinitionCount() {
return this.beanDefinitionMap.size();
}
分析:逻辑简单,就是从beanDefinitionMap中获取当前的size,注意beanDefinitionMap存储的就是注册的BeanDefinition集合。
DefaultBeanDefinitionDocumentReader#registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
// 获取XML Document对象的root元素
Element root = doc.getDocumentElement();
// 执行注册
doRegisterBeanDefinitions(root);
}
分析:
- 首先获取XML Document对象的root元素。
- 执行注册。
这里需要注意一点:registerBeanDefinitions的第二个入参,调用入口如下:
注意这里调用了XmlBeanDefinitionReader#createReaderContext:
/**
* 创建一个文档资源读取器<br/>
* Create the {@link XmlReaderContext} to pass over to the document reader.
*/
public XmlReaderContext createReaderContext(Resource resource) {
return new XmlReaderContext(resource, this.problemReporter, this.eventListener,
this.sourceExtractor, this, getNamespaceHandlerResolver());
}
分析:
这里主要关注XmlBeanDefinitionReader#getNamespaceHandlerResolver()函数:
/**
* 主要就是获得默认空间处理器,为后续解析标签做准备<br/>
* Lazily create a default NamespaceHandlerResolver, if not set before.
*
* @see #createDefaultNamespaceHandlerResolver()
*/
public NamespaceHandlerResolver getNamespaceHandlerResolver() {
if (this.namespaceHandlerResolver == null) {
this.namespaceHandlerResolver = createDefaultNamespaceHandlerResolver();
}
return this.namespaceHandlerResolver;
} /**
* Create the default implementation of {@link NamespaceHandlerResolver} used if none is specified.
* Default implementation returns an instance of {@link DefaultNamespaceHandlerResolver}.
*/
protected NamespaceHandlerResolver createDefaultNamespaceHandlerResolver() {
ClassLoader cl = (getResourceLoader() != null ? getResourceLoader().getClassLoader() : getBeanClassLoader());
return new DefaultNamespaceHandlerResolver(cl);
}
分析:
该函数主要是获得默认空间处理器,为后续解析标签做准备。最终切入DefaultNamespaceHandlerResolver中。DefaultNamespaceHandlerResolver中有两个函数值得我们关注:
public NamespaceHandler resolve(String namespaceUri) {
// 获取所有已经配置的Handler映射
Map<String, Object> handlerMappings = getHandlerMappings();
// 根据namespaceUri获取handler信息:这里一般都是类路径
Object handlerOrClassName = handlerMappings.get(namespaceUri);
// 不存在
if (handlerOrClassName == null) {
return null;
// 已经初始化
} else if (handlerOrClassName instanceof NamespaceHandler) {
return (NamespaceHandler) handlerOrClassName;
// 需要进行初始化
} else {
String className = (String) handlerOrClassName;
try {
// 通过反射获得类,并创建NamespaceHandler对象
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
// 初始化NameSpaceHandler
namespaceHandler.init();
// 添加到缓存
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
} catch (ClassNotFoundException ex) {
throw new FatalBeanException("Could not find NamespaceHandler class [" + className +
"] for namespace [" + namespaceUri + "]", ex);
} catch (LinkageError err) {
throw new FatalBeanException("Unresolvable class definition for NamespaceHandler class [" +
className + "] for namespace [" + namespaceUri + "]", err);
}
}
}
private Map<String, Object> getHandlerMappings() {
Map<String, Object> handlerMappings = this.handlerMappings;
// 这里使用了double-check的方式,进行延迟加载
if (handlerMappings == null) {
synchronized (this) {
handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
if (logger.isTraceEnabled()) {
logger.trace("Loading NamespaceHandler mappings from [" + this.handlerMappingsLocation + "]");
}
try {
// 读取handlerMappingsLocation
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
if (logger.isTraceEnabled()) {
logger.trace("Loaded NamespaceHandler mappings: " + mappings);
}
// 初始化到handlerMappings中
handlerMappings = new ConcurrentHashMap<>(mappings.size());
CollectionUtils.mergePropertiesIntoMap(mappings, handlerMappings);
this.handlerMappings = handlerMappings;
} catch (IOException ex) {
throw new IllegalStateException(
"Unable to load NamespaceHandler mappings from location [" + this.handlerMappingsLocation + "]", ex);
}
}
}
}
return handlerMappings;
}
分析:
- resolve主要是通过命名空间uri得到命名空间处理器,如果没有初始化,则会进行初始化,并缓存。
- getHandlerMappings函数使用了Double-Check进行延迟加载,获取所有命名空间处理器。
DefaultBeanDefinitionDocumentReader#doRegisterBeanDefinitions
protected void doRegisterBeanDefinitions(Element root) {
// Any nested <beans> elements will cause recursion in this method. In
// order to propagate and preserve <beans> default-* attributes correctly,
// keep track of the current (parent) delegate, which may be null. Create
// the new (child) delegate with a reference to the parent for fallback purposes,
// then ultimately reset this.delegate back to its original (parent) reference.
// this behavior emulates a stack of delegates without actually necessitating one.
// 记录老的BeanDefinitionParserDelegate对象
BeanDefinitionParserDelegate parent = this.delegate;
// 创建BeanDefinitionParserDelegate对象,并对delegate进行默认设置
this.delegate = createDelegate(getReaderContext(), root, parent);
// 检测<beans/>标签的命名空间是否为空,或者是否为"http://www.springframework.org/schema/beans"
if (this.delegate.isDefaultNamespace(root)) {
// 处理profile属性
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
// 如果profile属性有值,则使用分隔符进行切分,因为可能有多个profile
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
// 检测profile是否有效,如果无效,则不进行注册
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
// 解析xml前置处理,该方法为空,主要留给用户自定义处理,增强扩展性
preProcessXml(root);
// 核心函数,进行xml解析
parseBeanDefinitions(root, this.delegate);
// 解析xml后置处理,该方法也为空,主要留给用户自定义处理,增强扩展性
postProcessXml(root);
// 将delegate回到老的BeanDefinitionParserDelegate对象
this.delegate = parent;
}
分析:
- 首先记录旧的BeanDefinitionParserDelegate,然后创建一个新的BeanDefinitionParserDelegate对象,因为对BeanDefinition的解析会进行委托。
- 检测<beans/>标签的正确性,处理profile属性。
- preProcessXml:解析xml的前置处理,默认为空,主要留给用户自定义实现,增强扩展性;postProcessXml:解析xml的后置处理,默认也为空,同样留给用户自定义实现。
- parseBeanDefinitions:解析xml的核心函数,将在下面进行详细分析。
DefaultBeanDefinitionDocumentReader#parseBeanDefinitions
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// 如果根节点使用默认命名空间,则执行默认解析
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
// 遍历子节点
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// 如果该节点使用默认命名空间,则执行默认解析
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
// 如果该节点使用非默认命名空间,则执行自定义解析
} else {
delegate.parseCustomElement(ele);
}
}
}
// 否则使用自定义解析根节点
} else {
delegate.parseCustomElement(root);
}
}
分析:
首先判断根节点是否使用默认命名空间:
- 如果是默认命名空间,则遍历其子节点进行解析。
- 如果不是默认命名空间,则直接使用parseCustomElement进行解析。
DefaultBeanDefinitionDocumentReader#parseDefaultElement
/**
* 解析默认标签
*
* @param ele 当前元素节点
* @param delegate BeanDefinition解析委托
*/
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
// import标签
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
// 主要流程获取import标签的source属性,然后通过loadBeanDefinitions加载BeanDefinition
importBeanDefinitionResource(ele);
} else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) { // alias标签
processAliasRegistration(ele);
} else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) { // bean标签,主要解析标签
processBeanDefinition(ele, delegate);
} else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) { // beans标签
// recurse
doRegisterBeanDefinitions(ele);
}
}
分析:
默认标签的解析分为4个分支:①import;②alias;③bean;④beans标签(进行递归,再进行解析)。这里我们主要分析日常中最常用的bean标签,其他标签解析的大致流程差不多,后面进行补充。
DefaultBeanDefinitionDocumentReader#processBeanDefinition
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 进行bean标签解析
// 如果解析成功,则返回BeanDefinitionHolder,BeanDefinitionHolder为name和alias的BeanDefinition对象
// 如果解析失败,则返回null
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
// 进行标签处理,主要对bean标签的相关属性进行处理 如: p:name="测试用例"
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 注册BeanDefinition
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
} catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// 发出响应时间,通知监听器,已完成该bean标签的解析
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
分析:
- 首先使用委托对bean标签进行基础解析(核心处理流程)。
- 解析成功后,再处理bean标签的一些其他属性。
- 最后注册BeanDefintion。
BeanDefinitionParserDelegate#parseBeanDefinitionElement
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {
return parseBeanDefinitionElement(ele, null);
}
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
// 解析id和name属性
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
// 计算别名集合
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
// beanName,优先使用id
String beanName = id;
// 若beanName为空,则使用alias的第一个
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
// 将alias第一个元素移除别名集合
beanName = aliases.remove(0);
if (logger.isTraceEnabled()) {
logger.trace("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
// 检查beanName的唯一性
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
// 解析bean标签的属性,构造AbstractBeanDefinition
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
// 如果beanName为空
if (!StringUtils.hasText(beanName)) {
try {
// 如果containingBean不为null
if (containingBean != null) {
// 生成唯一的beanName
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
} else {
// 生成唯一的beanName
beanName = this.readerContext.generateBeanName(beanDefinition);
// Register an alias for the plain bean class name, if still possible,
// if the generator returned the class name plus a suffix.
// This is expected for Spring 1.2/2.0 backwards compatibility.
// 判断beanName是否被使用
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isTraceEnabled()) {
logger.trace("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
} catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
// 创建BeanDefinitionHolder对象
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
分析:
- 获取bean标签的id与name属性,spring在解析bean的时候,优先使用的id值。
- 检查beanName的唯一性,如果不唯一,则会报错。
- (核心)解析bean的属性,构造AbstractBeanDefinition对象。
- 如果beanDefiniton对象的beanName为空,还要为其生成一个beanName,为注册BeanDefinition做准备。
- 最后返回BeanDefinitionHolder对象。
BeanDefinitionParserDelegate#parseBeanDefinitionElement
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, @Nullable BeanDefinition containingBean) { // 为解析bean元素加一个状态
this.parseState.push(new BeanEntry(beanName)); // 解析class属性
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
// 解析parent属性
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
} try {
// 创建承载属性的AbstractBeanDefinition对象
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 解析bean的各种默认属性
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
// 提取description
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT)); // 这里会解析bean标签内部的很多子元素,放入bd中 // #1.解析元数据 <meta/>
parseMetaElements(ele, bd);
// #2.解析lookup-method属性 <lookup-method/>
// lookup-method:获取器注入,把一个方法声明为返回某种类型的bean,但方法的实际返回的bean是在配置文件里配置的
parseLookupOverrideSubElements(ele, bd.getMethodOverrides()); // #3.解析replace-method属性 <replace-method/>
// replace-method:可在运行时调用新的方法替换现有的方法,还能动态的更新原有方法的逻辑
parseReplacedMethodSubElements(ele, bd.getMethodOverrides()); // #4.解析构造函数参数 <constructor-arg/>
parseConstructorArgElements(ele, bd);
// #5.解析property子元素 <property/>
parsePropertyElements(ele, bd);
// #6.解析qualifier子元素 <qualifier/>
parseQualifierElements(ele, bd); // 设置resource
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele)); return bd;
} catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
} catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
} catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
} finally {
this.parseState.pop();
} return null;
}
分析:
- 首先获取bean标签的class和parent属性,用于创建承载属性的AbstractBeanDefinition对象[由这两个属性就可以创建AbstractBeanDefinition对象了]。
- 接下来就是对bean标签进行各种解析,并将解析的数据赋值到AbstractBeanDefinition中。
BeanDefinitionParserDelegate#createBeanDefinition
protected AbstractBeanDefinition createBeanDefinition(@Nullable String className, @Nullable String parentName)
throws ClassNotFoundException { return BeanDefinitionReaderUtils.createBeanDefinition(
parentName, className, this.readerContext.getBeanClassLoader());
} //BeanDefinitionReaderUtils#creatBeanDefinition public static AbstractBeanDefinition createBeanDefinition(
@Nullable String parentName, @Nullable String className, @Nullable ClassLoader classLoader) throws ClassNotFoundException { // 创建GenericBeanDefinition对象
GenericBeanDefinition bd = new GenericBeanDefinition();
// 设置parentName
bd.setParentName(parentName);
// 在className不为空的情况下,进行相关属性的设置
if (className != null) {
// 如果classLoader不为空,这里就会直接通过反射加载类 ?为了提升速度
if (classLoader != null) {
bd.setBeanClass(ClassUtils.forName(className, classLoader));
}
// 设置beanClassName的名字
else {
bd.setBeanClassName(className);
}
}
return bd;
}
分析:
BeanDefinition的创建是通过BeanDefinitionReaderUtils#createBeanDefinition方法实现的,代码逻辑简单,主要注意生成的BeanDefinition对象是GenericBeanDefinition。
BeanDefinitionParserDelegate#parseBeanDefinitionAttributes
public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName,
@Nullable BeanDefinition containingBean, AbstractBeanDefinition bd) {
// 如果有singleton属性则抛出异常,因为singleton属性已进行升级
if (ele.hasAttribute(SINGLETON_ATTRIBUTE)) {
error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);
// 解析scope属性
} else if (ele.hasAttribute(SCOPE_ATTRIBUTE)) {
bd.setScope(ele.getAttribute(SCOPE_ATTRIBUTE));
// 如果BeanDefinition不为空,则使用当前BeanDefinition的scope
} else if (containingBean != null) {
// Take default from containing bean in case of an inner bean definition.
bd.setScope(containingBean.getScope());
}
// 解析abstract属性
if (ele.hasAttribute(ABSTRACT_ATTRIBUTE)) {
bd.setAbstract(TRUE_VALUE.equals(ele.getAttribute(ABSTRACT_ATTRIBUTE)));
} // 解析lazy-init属性 lazy-init属性默认为false
String lazyInit = ele.getAttribute(LAZY_INIT_ATTRIBUTE);
if (isDefaultValue(lazyInit)) {
lazyInit = this.defaults.getLazyInit();
}
bd.setLazyInit(TRUE_VALUE.equals(lazyInit)); // 解析autowire属性
String autowire = ele.getAttribute(AUTOWIRE_ATTRIBUTE);
bd.setAutowireMode(getAutowireMode(autowire)); // 解析depends-on属性
if (ele.hasAttribute(DEPENDS_ON_ATTRIBUTE)) {
String dependsOn = ele.getAttribute(DEPENDS_ON_ATTRIBUTE);
bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, MULTI_VALUE_ATTRIBUTE_DELIMITERS));
} // 解析autowire-candidate属性
String autowireCandidate = ele.getAttribute(AUTOWIRE_CANDIDATE_ATTRIBUTE);
if (isDefaultValue(autowireCandidate)) {
String candidatePattern = this.defaults.getAutowireCandidates();
if (candidatePattern != null) {
String[] patterns = StringUtils.commaDelimitedListToStringArray(candidatePattern);
bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));
}
} else {
bd.setAutowireCandidate(TRUE_VALUE.equals(autowireCandidate));
} // 解析primary属性
if (ele.hasAttribute(PRIMARY_ATTRIBUTE)) {
bd.setPrimary(TRUE_VALUE.equals(ele.getAttribute(PRIMARY_ATTRIBUTE)));
} // 解析init-method属性 设置bean的初始值方法
if (ele.hasAttribute(INIT_METHOD_ATTRIBUTE)) {
String initMethodName = ele.getAttribute(INIT_METHOD_ATTRIBUTE);
bd.setInitMethodName(initMethodName);
} else if (this.defaults.getInitMethod() != null) {
bd.setInitMethodName(this.defaults.getInitMethod());
bd.setEnforceInitMethod(false);
} // 解析destroy-method属性
if (ele.hasAttribute(DESTROY_METHOD_ATTRIBUTE)) {
String destroyMethodName = ele.getAttribute(DESTROY_METHOD_ATTRIBUTE);
bd.setDestroyMethodName(destroyMethodName);
} else if (this.defaults.getDestroyMethod() != null) {
bd.setDestroyMethodName(this.defaults.getDestroyMethod());
bd.setEnforceDestroyMethod(false);
} // 解析factory-method属性
if (ele.hasAttribute(FACTORY_METHOD_ATTRIBUTE)) {
bd.setFactoryMethodName(ele.getAttribute(FACTORY_METHOD_ATTRIBUTE));
}
// 解析factory-bean属性
if (ele.hasAttribute(FACTORY_BEAN_ATTRIBUTE)) {
bd.setFactoryBeanName(ele.getAttribute(FACTORY_BEAN_ATTRIBUTE));
} return bd;
}
分析:
该函数是对bean标签的默认属性做解析,最终解析后的值封装在BeanDefinition中,代码逻辑简单,函数中已给出相应注释。这里要注意一点lazy-init属性的默认值为false。
介于篇幅原因,这里不在分析bean标签默认属性的解析过程,后续会对一些重要的方法进行补充,下面将分析BeanDefinition的注册过程。
总结
本文主要分析了BeanDefinition注册之前的一些准备工作,还未进入核心流程,后面将进入BeanDefinition注册的核心流程。
ps:笔者希望每篇文章不要写太长,尽量做到短小精悍。
by Shawn Chen,2018.12.8日,下午。
【spring源码分析】IOC容器初始化(三)的更多相关文章
- SPRING源码分析:IOC容器
在Spring中,最基本的IOC容器接口是BeanFactory - 这个接口为具体的IOC容器的实现作了最基本的功能规定 - 不管怎么着,作为IOC容器,这些接口你必须要满足应用程序的最基本要求: ...
- Spring源码解析-ioc容器的设计
Spring源码解析-ioc容器的设计 1 IoC容器系列的设计:BeanFactory和ApplicatioContext 在Spring容器中,主要分为两个主要的容器系列,一个是实现BeanFac ...
- spring源码分析---IOC(1)
我们都知道spring有2个最重要的概念,IOC(控制反转)和AOP(依赖注入).今天我就分享一下spring源码的IOC. IOC的定义:直观的来说,就是由spring来负责控制对象的生命周期和对象 ...
- spring 源码之 ioc 容器的初始化和注入简图
IoC最核心就是两个过程:IoC容器初始化和IoC依赖注入,下面通过简单的图示来表述其中的关键过程:
- Spring源码阅读-IoC容器解析
目录 Spring IoC容器 ApplicationContext设计解析 BeanFactory ListableBeanFactory HierarchicalBeanFactory Messa ...
- Spring 源码剖析IOC容器(一)概览
目录 一.容器概述 二.核心类源码解读 三.模拟容器获取Bean ======================= 一.容器概述 spring IOC控制反转,又称为DI依赖注入:大体是先初始化bean ...
- Spring源码解析-IOC容器的实现
1.IOC容器是什么? IOC(Inversion of Control)控制反转:本来是由应用程序管理的对象之间的依赖关系,现在交给了容器管理,这就叫控制反转,即交给了IOC容器,Spring的IO ...
- Spring源码解析-IOC容器的实现-ApplicationContext
上面我们已经知道了IOC的建立的基本步骤了,我们就可以用编码的方式和IOC容器进行建立过程了.其实Spring已经为我们提供了很多实现,想必上面的简单扩展,如XMLBeanFacroty等.我们一般是 ...
- Spring源码之IOC容器创建、BeanDefinition加载和注册和IOC容器依赖注入
总结 在SpringApplication#createApplicationContext()执行时创建IOC容器,默认DefaultListableBeanFactory 在AbstractApp ...
随机推荐
- mapbox.gl源码解析——基本架构与数据渲染流程
加载地图 Mapbox GL JS是一个JavaScript库,使用WebGL渲染交互式矢量瓦片地图和栅格瓦片地图.WebGL渲染意味着高性能,MapboxGL能够渲染大量的地图要素,拥有流畅的交互以 ...
- building tool
Build Tool的含义是什么? building tool中文名称叫构建工具,BuildTools.jar是我们构建Bukkit,CraftBukkit,Spigot和Spigot-API的解决方 ...
- PopupWindowMenuUtil【popupwindow样式菜单项列表】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 实现PopupWindow样式的Menu菜单. 效果图 代码分析 使用PopupWindow实现. 列表使用的是Recyclervi ...
- jquery快速入门(四)
jQuery 遍历 向上遍历 DOM 树 parent() parent() 方法返回被选元素的直接父元素.该方法只会向上一级对 DOM 树进行遍历. parents() parents() 方法返回 ...
- Centos7+LVS-DR+Apache负载均衡web实验
一.简介 1.理论已经在上一篇博客简述,不了解得可以看看 https://www.cnblogs.com/zhangxingeng/p/10497279.html 2.LVS-DR优缺点复习 关于这种 ...
- 配置Nginx部署静态资源和自动跳转到https
一.首先在阿里云后台添加域名解析: 二.两个网站的静态资源在以下目录: /www/temp/blog/public 三.在服务器端配置nginx: cd /etc/nginx/conf.d 添加两个文 ...
- &,^,|,的简化计算与理解
(全部和2进制有关 , 凡是2的次方数都是独立数列,都要先分解再计算的,该计算方式仅供手工计算理解,电脑会自动进行换算的) (第二个等号后面为2进制的结果,不够位在前面补0,1为真,0为假) A^ ...
- DevExpress AspxGridView分页使用隐藏系统默认英文分页
1第一篇文章研究了怎么汉化,但是在实际使用过程中发现汉化的有小问题,DevExpress支持自定义按钮,也可以在属性中设置成中文,这样避免汉化不准确的问题 <dx:ASPxGridView ID ...
- 浅谈Quartz.Net 从无到有创建实例
一.Quartz.Net介绍 Quartz.NET是一个开源的作业调度框架,非常适合在平时的工作中,定时轮询数据库同步,定时邮件通知,定时处理数据等. Quartz.NET允许开发人员根据时间间隔(或 ...
- 自己实现的TypeOf函数2
自己实现的typeOf函数:返回传入参数的类型 主要用于解决,js自带的typeof返回结果不精确:Ext JS中typeOf对字符串对象.元素节点.文本节点.空白文本节点判断并不准确的问题 与上一篇 ...