python lock, semaphore, event实现线程同步
lock 机制不管你是java, C#, 还是python都是常用的线程同步机制, 相比较C# 的锁机制, python的加锁显得比较简单, 直接调用threading 标准库的lock 就可以了. python 的 lock类有两个函数, 分别是acquire 函数以及 release 函数, 前者起到锁定的作用, 将状态设置为锁定状态, 后者则是解锁, 将状态设置为未锁定状态. 我们看看代码:
# python 多线程同步 lock
import threading
from time import sleep num = 0
lock = threading.Lock() def func(st):
global num
print(threading.currentThread().getName() + ' try to acquire the lock')
if lock.acquire(): # 将状态修改为locked
print(threading.currentThread().getName() + ' acquire the lock.')
print(threading.currentThread().getName() + " :%s" % str(num))
num += 1
# sleep(st)
print(threading.currentThread().getName() + ' release the lock.')
lock.release() # 将状态修改为unlocked t1 = threading.Thread(target=func, args=(8,))
t2 = threading.Thread(target=func, args=(4,))
t3 = threading.Thread(target=func, args=(2,))
t1.start()
t2.start()
t3.start()
我们开了三个线程去调用同一个func 函数, 由于线程的不确定性, 如果没有加锁, 此时运行的话就会很混乱, 三个线程去执行同一个函数, 如果涉及到了变量的数据变化更是坑!因此我们加了锁, 确保数据的正确性, 函数执行的顺序性!
semaphore 信号量机制在python 里面也很简单就能够实现线程的同步。如果对操作系统有一定的了解, 那么对操作系统的PV原语操作应该有印象, 信号量其实就是基于这个机制的.semaphore 类是threading 模块下的一个类, 主要两个函数: acquire 函数, release 函数这和lock 类的函数是一样的, 只不过功能不一样, semaphore 机制的acquire 函数的参数允许你自己设置最大的并发量, 就是说允许多少个线程来操作同一个函数或是变量, 同时执行一次就会递减一次, release 函数则是递增, 如果计数到了0, 则阻塞起线程, 不再允许线程访问该方法或是变量.
# python 多线程同步 semaphore
import threading # 初始化信号量数量...当调用acquire 将数量置为 0, 将阻塞线程等待其他线程调用release() 函数
semaphore = threading.Semaphore(2) def func():
if semaphore.acquire():
for i in range(5):
print(threading.currentThread().getName() + ' get semaphore')
semaphore.release()
print(threading.currentThread().getName() + ' release semaphore') if __name__ == '__main__':
for i in range(4):
t1 = threading.Thread(target=func)
t1.start()
我们一次允许两个线程同时执行函数, 这可以从截图看出来: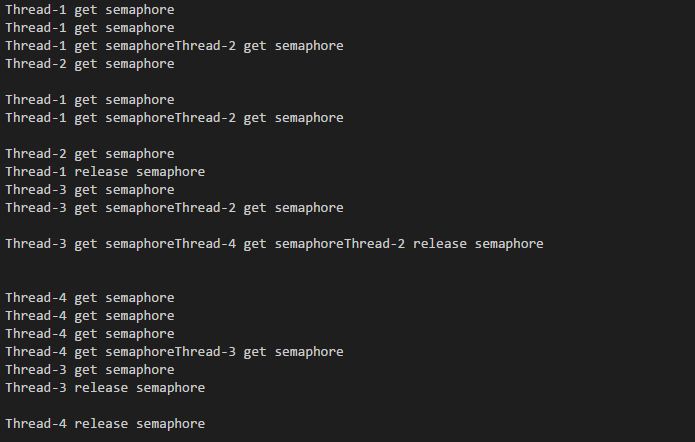
event 机制不仅能够实现线程间的通信, 也是实现线程同步的一个好方法。事件是线程之间通信的最简单的机制之一, 一个线程指示一个事件和其他线程等待它.
event.py 是threading 模块下的一个类, 相比较前面两个机制, 这个类提供了四个方法, 分别是 is_set() 函数, set() 函数, clear() 函数, wait() 函数.
is_set判断事件管理标志是不是为true, 只有为true时, 才会返回
set 将标志设置为true
clear 将标志设置为flase
wait 等到标志为true时, 才会停止阻塞线程
import logging
import threading
import time # 打印线程名以及日志信息
logging.basicConfig(level=logging.DEBUG, format="(%(threadName)-10s : %(message)s", ) def wait_for_event_timeout(e, t):
"""Wait t seconds and then timeout"""
while not e.isSet():
logging.debug("wait_for_event_timeout starting")
event_is_set = e.wait(t) # 阻塞, 等待设置为true
logging.debug("event set: %s" % event_is_set)
if event_is_set:
logging.debug("processing event")
else:
logging.debug("doing other work") e = threading.Event() # 初始化为false
t2 = threading.Thread(name="nonblock", target=wait_for_event_timeout, args=(e, 2))
t2.start()
logging.debug("Waiting before calling Event.set()")
# time.sleep(7)
e.set() # 唤醒线程, 同时将event 设置为true
logging.debug("Event is set")
python lock, semaphore, event实现线程同步的更多相关文章
- python类库32[多进程同步Lock+Semaphore+Event]
python类库32[多进程同步Lock+Semaphore+Event] 同步的方法基本与多线程相同. 1) Lock 当多个进程需要访问共享资源的时候,Lock可以用来避免访问的冲突. imp ...
- Python并行编程(三):线程同步之Lock
1.基础概念 当两个或以上对共享内存操作的并发线程中,如果有一个改变数据,又没有同步机制的条件下,就会产生竞争条件,可能会导致执行无效代码.bug等异常行为. 竞争条件最简单的解决方法是使用锁.锁的操 ...
- Python多线程(2)——线程同步机制
本文介绍Python中的线程同步对象,主要涉及 thread 和 threading 模块. threading 模块提供的线程同步原语包括:Lock.RLock.Condition.Event.Se ...
- Python并行编程(五):线程同步之信号量
1.基本概念 信号量是由操作系统管理的一种抽象数据类型,用于在多线程中同步对共享资源的使用.本质上说,信号量是一个内部数据,用于标明当前的共享资源可以有多少并发读取. 同样在threading中,信号 ...
- [b0034] python 归纳 (十九)_线程同步_条件变量
代码: # -*- coding: utf-8 -*- """ 学习线程同步,使用条件变量 逻辑: 生产消费者模型 一个有3个大小的产品库,一个生产者负责生产,一个消费者 ...
- [b0031] python 归纳 (十六)_线程同步_锁
# -*- coding: utf-8 -*- """ 学习 多线程同步 使用锁 threading.Lock() 逻辑: 2 个线程,操作同一个整型变量,一个加法,另外 ...
- 线程高级应用-心得5-java5线程并发库中Lock和Condition实现线程同步通讯
1.Lock相关知识介绍 好比我同时种了几块地的麦子,然后就等待收割.收割时,则是哪块先熟了,先收割哪块. 下面举一个面试题的例子来引出Lock缓存读写锁的案例,一个load()和get()方法返回值 ...
- Python并行编程(七):线程同步之事件
1.基本概念 事件是线程之间用于通讯的对象.有的线程等待信号,有的线程发出信号.基本上事件对象都会维护一个内部变量,可以通过set方法设置为true,也可以通过clear方法设置为false.wait ...
- Python并行编程(四):线程同步之RLock
1.基本概念 如果想让只有拿到锁的线程才能释放该锁,那么应该使用RLock()对象.当需要在类外面保证线程安全,又要在类内使用同样方法的时候RLock()就很使用. RLock叫做Reentrant ...
随机推荐
- NET中小型企业级项目开发架构系列(一)
前端时间我们开发了基于Net的一套搭建sprint.NET+NHibernate+MVC+WCF+EasyUI等中小型企业级系统开发平台,现在把整个开发过程中的步步进展整理出来和大家分享,这个系列可能 ...
- (NO.00005)iOS实现炸弹人游戏(九):游戏主角(二)
大熊猫猪·侯佩原创或翻译作品.欢迎转载,转载请注明出处. 如果觉得写的不好请多提意见,如果觉得不错请多多支持点赞.谢谢! hopy ;) 上篇介绍了游戏主角的初始化方法,下面我们一次来实现主角的其他方 ...
- [ExtJS5学习笔记]第四节 欢迎来到extjs5-手把手教你实现你的第一个应用
本文地址:http://blog.csdn.net/sushengmiyan/article/details/38331347 本文作者:sushengmiyan ------------------ ...
- "ORA-20100: 为 FND_FILE 创建文件 o0003167.tmp 失败"
今天在运行请求时候得到如下的错误日志: 原因:由于ORA-20100:为FND_FILE创建文件o0003167.tmp失败. 在请求日志的错误原因中您会找到更详细的信息. 查找了一些资料,总结 ...
- Hessian源码分析--HessianProxyFactory
HessianProxyFactory是HessianProxy的工厂类,其通过HessianProxy来生成代理类. 如下面代码: HessianProxyFactory factory = new ...
- IOS中 浅谈iOS中MVVM的架构设计与团队协作
今天写这篇文章是想达到抛砖引玉的作用,想与大家交流一下思想,相互学习,博文中有不足之处还望大家批评指正.本篇文章的内容沿袭以往博客的风格,也是以干货为主,偶尔扯扯咸蛋(哈哈~不好好工作又开始发表博客啦 ...
- Cocos2D中的纹理(textures)的解释
大熊猫猪·侯佩原创或翻译作品.欢迎转载,转载请注明出处. 如果觉得写的不好请告诉我,如果觉得不错请多多支持点赞.谢谢! hopy ;) 免责申明:本博客提供的所有翻译文章原稿均来自互联网,仅供学习交流 ...
- Oracle开发环境搭建
一.软件准备 地址:oracle官网 安装包:因为个人学习用,所以就安装服务器端就可以了,不需要客户端. 一共两个压缩文件,解压时一起解压到到一个文件夹. 本人使用的:win32_11gR2_data ...
- Socket编程实践(8) --Select-I/O复用
五种I/O模型介绍 (1)阻塞I/O[默认] 当上层应用App调用recv系统调用时,如果对等方没有发送数据(Linux内核缓冲区中没有数据),上层应用Application1将阻塞;当对等方发送了数 ...
- (二十六)静态单元格(Cell)
制作类似iOS系统设置的页面,如果使用代码来实现,将会比较麻烦,可以通过静态单元格技术方便的实现. 注意:静态单元格只支持TableViewController. 可以通过storyboard直接操作 ...