自建免费的代理ip池
00x01--- 前言
因为爬虫被禁ip这样的反扒真的很凶,但自从建了一个代理ip池以后,反反扒就可以跟的上节奏。当然你也可以上网上各种代理平台自己付费。这些平台当然很方便提供api调用,还不用自己验证。但你不想付费的话,可以看看下面这个国外的开源项目,我是从某网站的评论信息里找到的,下面操作均是基于该网站:https://raw.githubusercontent.com/fate0/proxylist/master/proxy.list
00x02--- 获取代理的json信息
打开网站,不过需要墙,这是一个开源的项目

00x03 --- 分析
很明显每一行是一个json数据,但整个页面你拿到的也不过是字符串而已,每一行末都换行,也就是说每一行末都有"\n",那么思路很清晰,用requests获得整个页面的text(字符串),然后用split('\n') 将每一行分割之后组成的列表,便利这个列表用json.loads()方法,将每一行的字符串转换为json对象,最后取值。
00x04 --- 上代码
#!/usr/bin/env python3
# coding:utf-8
#lanxing import json
import telnetlib
import requests
import random proxy_url = 'https://raw.githubusercontent.com/fate0/proxylist/master/proxy.list'
# proxyList = [] #定义函数,验证代理ip是否有效
def verify(ip,port,type):
proxies = {}
try:
telnet = telnetlib.Telnet(ip,port=port,timeout=3) #用这个ip请访问,3s自动断开,返回tiemout
except:
print('unconnected')
else:
#print('connected successfully')
# proxyList.append((ip + ':' + str(port),type))
proxies['type'] = type
proxies['host'] = ip
proxies['port'] = port
proxiesJson = json.dumps(proxies)
#保存到本地的proxies_ip.json文件
with open('proxies_ip.json','a+') as f:
f.write(proxiesJson + '\n')
print("已写入:%s" % proxies) #定义函数,带着url地址去获取数据
def getProxy(proxy_url):
response = requests.get(proxy_url)
#print(type(response))
# 用split('\n') 将每一行分割之后组成的列表,消除换行影响
proxies_list = response.text.split('\n')
for proxy_str in proxies_list:
# 用json.loads()方法,将每一行的字符串转换为json对象,最后取值
proxy_json = json.loads(proxy_str)
host = proxy_json['host']
port = proxy_json['port']
type = proxy_json['type']
verify(host,port,type) #主函数,入口
if __name__ == '__main__':
getProxy(proxy_url)
00x05 --- 效果图
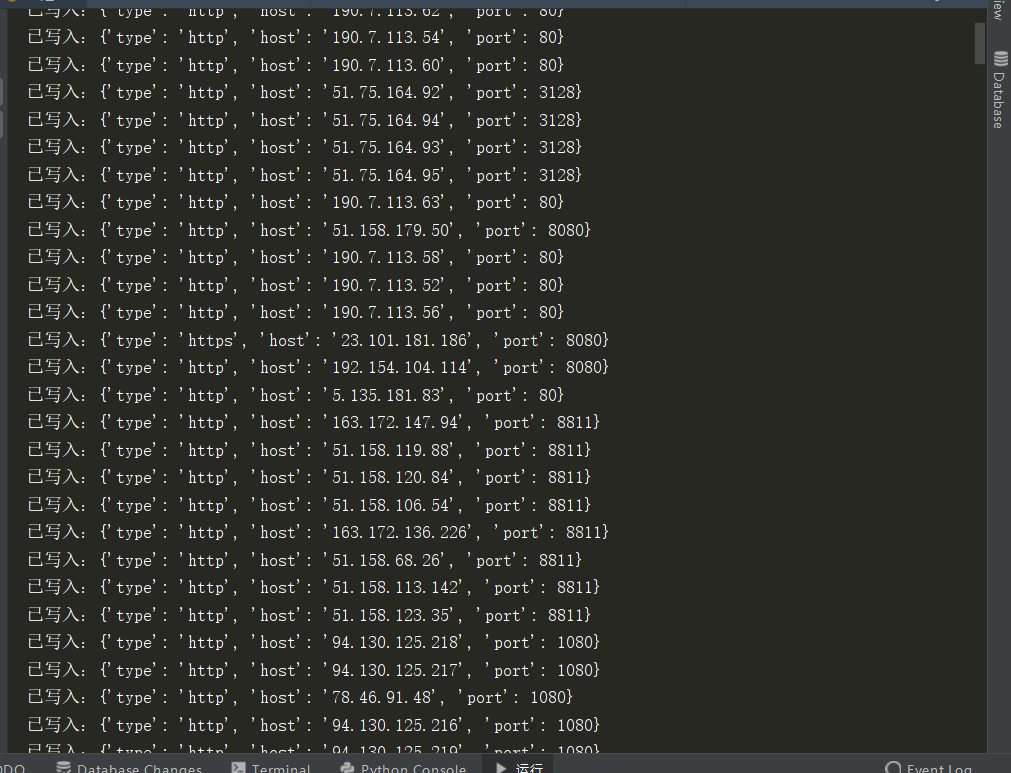

参考文章:https://blog.csdn.net/qq_42776455/article/details/83047883
自建免费的代理ip池的更多相关文章
- 基于后端和爬虫创建的代理ip池
搭建免费的代理ip池 需要解决的问题: 使用什么方式存储ip 文件存储 缺点: 打开文件修改文件操作较麻烦 mysql 缺点: 查询速度较慢 mongodb 缺点: 查询速度较慢. 没有查重功能 re ...
- 做了一个动态代理IP池项目,邀请大家免费测试~
现在出来创业了,目前公司在深圳. 做了啥呢, 做了一个动态代理 IP 池项目 现在邀请大家免费测试体验! 免费激活码:关注微信公众号:2808proxy (每人每天限领一次噢~) 网站:https:/ ...
- 利用代理IP池(proxy pool)搭建免费ip代理和api
先看这里!!!---->转载:Python爬虫代理IP池(proxy pool) WIIN10安装中遇到的问题: 一.先安装Microsoft Visual C++ Compiler for P ...
- 【python3】如何建立爬虫代理ip池
一.为什么需要建立爬虫代理ip池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制的,在某段时间内,当某个ip的访问量达到一定的阀值时,该ip会被拉黑.在一段时间内被禁止访问. 这种时候,可 ...
- Python爬虫代理IP池
目录[-] 1.问题 2.代理池设计 3.代码模块 4.安装 5.使用 6.最后 在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代 ...
- C#——做一个简单代理IP池
一.缘由. 抓取数据时,有一些网站 设置了一些反爬虫设置,进而将自己本地 IP 地址拉入系统黑名单.从而达到禁止本地 IP 访问数据的请求. 二.思路. 根据其他 代理 IP 网站,进行一个免费的代理 ...
- 构建一个给爬虫使用的代理IP池
做网络爬虫时,一般对代理IP的需求量比较大.因为在爬取网站信息的过程中,很多网站做了反爬虫策略,可能会对每个IP做频次控制.这样我们在爬取网站时就需要很多代理IP. 代理IP的获取,可以从以下几个途径 ...
- python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检 ...
- 爬虫入门到放弃系列05:从程序模块设计到代理IP池
前言 上篇文章吧啦吧啦讲了一些有的没的,现在还是回到主题写点技术相关的.本篇文章作为基础爬虫知识的最后一篇,将以爬虫程序的模块设计来完结. 在我漫(liang)长(nian)的爬虫开发生涯中,我通常将 ...
随机推荐
- iOS开发系列-Shell脚本编译SDK
Library静态库Shell脚本 #!/bin/bash #要build的target名 target_Name="IFlyMSC" #编译模式 Release.Debug bu ...
- SVN 分支操作
一 拉取分支 1 选择浏览 2 输入svn项目路径:https://IP/svn/ 3 选择拉取的项目 4 下载到本地路劲 右键选中的分支—CheckOut 选择本地路劲 二 分支合并 1 分支合并 ...
- Python全栈开发:django网络框架(一)
Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了ORM.模型绑定.模板引擎.缓存.Session等诸多功能. ...
- 字体jquery ---
You don’t need icons! Here are 100+ unicode symbols that you can use Danny Markov December 3rd, 2014 ...
- hive 总结二
本文参考:黑泽君相关博客 本文是我总结日常工作中遇到的坑,结合黑泽君相关博客,选取.补充了部分内容. 查询函数(Hive高级) NVL(cloumn,replace_with) 如果cloumn为NU ...
- ie9 jscript7 内存不足 页面无响应
花了我差不多一天时间 我是加载一个datagrid ,多表联查,查询几遍(不一定,又是1遍就死了)后 就卡死了...后台日志都是过的.... 后来我发现数据库某个表的数据很多有一模一样的两条,把一份删 ...
- 第四周课堂笔记4th
编码 Ascii美国 一个字节表示一个字符,必能表示汉子 大写字母65-90 小写字母97-122 265个位置 8位表示一个字节, 8bit=1byte GBK 中国 只包含本国文字 ...
- .NET中DataTable的常用操作
一.目的 在各种.NET开发中,DataTable都是一个非常常见且重要的类型,在与数据打交道的过程中可以说是必不可少的对象. 它功能强大,属性与功能也是相当丰富,用好的话,使我们在处理数据时,减少很 ...
- python3 使用aria2下载的一个脚本
import requests import time ariaurl="http://localhost:6800/jsonrpc" dlurl="http://xxx ...
- python 递归计算若干工作日后的日期
import datetime # 根据第一次计算出来的休息日数,计算还需要的工作日数.(递归调用) def get_next_date(self, start_date, weekend_days) ...