大数据篇:HDFS
HDFS

HDFS是什么?
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
如果没有HDFS!
- 大文件的储存我们必须要拓展硬盘。
- 硬盘拓展到一定的量以后,我们就不能在一个硬盘上储存文件了,要换一个硬盘,这样文件管理就成了问题。
- 为了防止文件的损坏吗,我们需要创建副本,副本的管理也成了问题。
- 分布式计算非常麻烦。
1 HDFS出现原因
1.1 早期文件服务器
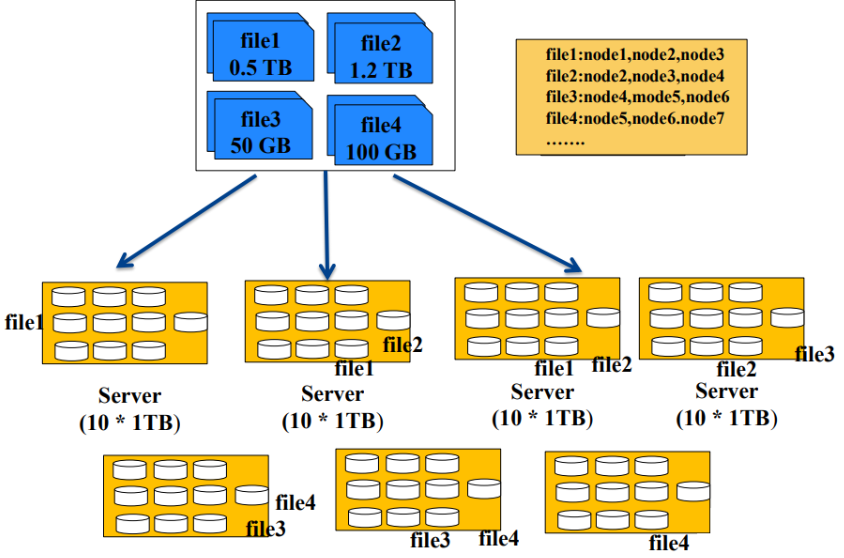
- 从上图中,我们可以看出,存储一个文件,我们一直往一个机子上面存是不够的,那么我们在储存量不够的时候就会加机子。
- 但是如果一个文件放在一台机子上,如果该机器挂了,那么文件就丢失了,不安全。
所以我们会把一个文件放在多台机子上,创建一个索引文件来储存文件的指针,如图中的file1存储在node1,node2,node3上面,以此类推 - 缺点:
- 难以实现负载均衡
- 文件大小不同,负载均衡不易实现
- 用户自己控制文件大小
- 难以并行化处理
- 只能利用一个节点资源处理一个文件
- 无法动用集群资源处理同一个文件
- 难以实现负载均衡
1.2 HDFS文件服务器
- HDFS前提和设计目标
- 存储超大文件
- HDFS适合存储大文件,单个文件大小通常在百MB以上
- HDFS适合存储海量文件,总存储量可达PB,EB级
- 硬件容错
- 基于普通机器搭建,硬件错误是常态而不是异常,因此错误检测和快速、自动的恢复是HDFS最核心的架构目标
- 流式数据访问
- 为数据批处理而设计,关注数据访问的高吞吐量
- 简单的一致性模型
- 一次写入,多次读取
- 一个文件经过创建、写入和关闭之后就不需要改变
- 如果是update操作其实是增加了版本号,并没有修改源文件
- 本地计算
- 将计算移动到数据附近(数据在哪个节点就在哪里计算)
- 存储超大文件

- 从上图我们看出,HDFS是把一个大的数据,拆成很多个block块,然后在将block存储在各个机子上。
创建文件对应block的指针文件,和block对应的节点node的指针文件。 - 源自于Google的GFS论文
- 发表于2003年10月
- HDFS是GFS克隆版
- 易于扩展的分布式文件系统
- 运行在大量普通廉价机器上,提供容错机制
- 为大量用户提供性能不错的文件存取服务
1.3 HDFS优缺点
- 优点
- 高容错性
- 数据自动保存多个副本
- 副本丢失后,自动恢复
- 适合批处理
- 移动计算而非数据
- 数据位置暴露给计算框架
- 适合大数据处理
- GB、TB、甚至PB级数据
- 百万规模以上的文件数量
- 10K+节点规模
- 流式文件访问
- 一次性写入,多次读取
- 保证数据一致性
- 可构建在廉价机器上
- 通过多副本提高可靠性
- 提供了容错和恢复机制
- 高容错性
- 缺点
- 低延迟数据访问(慢)
- 比如毫秒级
- 低延迟与高吞吐率
- 小文件存取
- 占用NameNode大量内存
- 寻道时间超过读取时间
- 并发写入、文件随机修改
- 一个文件只能有一个写者
- 仅支持append(追加)
- 低延迟数据访问(慢)
- 适用场景:适合一次写入,多次读出的场景,支持追加数据且不支持文件的修改。
1.4 基本构成
- 数据块
- 文件以块为单位进行切分存储,块通常设置的比较大(最小6M,默认128M),根据网络带宽计算最佳值。
- 块越大,寻址越快,读取效率越高,但同时由于MapReduce任务也是以块为最小单位来处理,所以太大的块不利于于对数据的并行处理。
- 一个文件至少占用一个块(如果一个1KB文件,占用一个块,但是占用空间还是1KB)
- 我们在读取HDFS上文件的时候,NameNode会去寻找block地址,寻址时间为传输时间的1%时,则为最佳状态。
- 目前磁盘的传输速度普遍为100MB/S
- 如果寻址时间约为10ms,则传输时间=10ms/0.01=1000ms=1s
- 如果传输时间为1S,传输速度为100MB/S,那么一秒钟我们就可以向HDFS传送100MB文件,设置块大小128M比较合适。
- 如果带宽为200MB/S,那么可以将block块大小设置为256M比较合适。
- Namenode(master管理者)
- 管理HDFS的文件树及名称空间
- 数据复制策略
- 管理数据块(Block)的映射信息
- 处理客户端读写请求。
- Datanode(slave实际操作者)
- 存储实际的数据块
- 执行数据块的读写请求
- Client(客户端)
- 文件切分,上传HDFS时,将文件切分成一个一个Block,然后进行上传。
- 与Namenode交互,获取文件位置信息。
- 与Datanode交互,读取或者写入数据。
- 提供API来管理HDFS。
- SecondaryNameNode
- 并非是NameNode的热备,当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
- 辅助NameNode,比如根据检查点,定期合并Fsimage和Edits,并推送给NameNode。
1.5 所处角色
2 HDFS物理网络环境(集群结构)

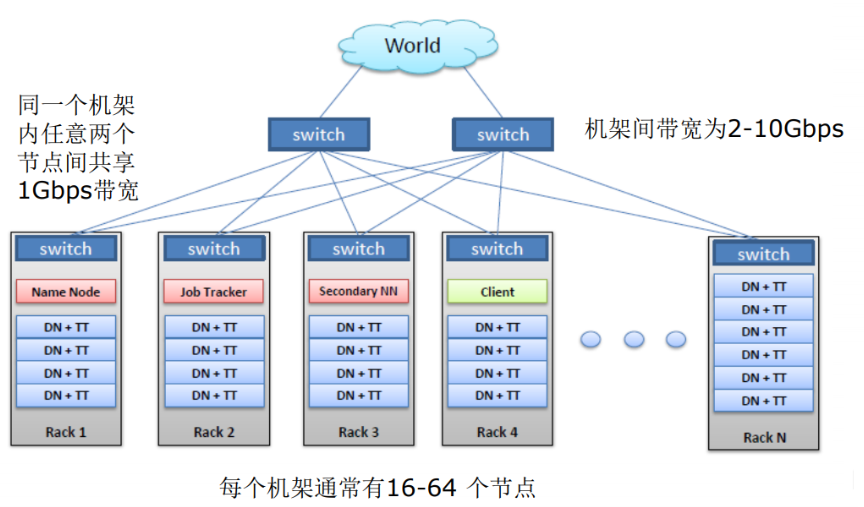
- 比较重要服务功能最好能部署在不同的节点上,如:NN。
- 不重要的可以在一个节点上,如:DN。
- 副本选择机制:当副本为3的时候,第一个为本地最近的节点,第二个为同机架的不同节点,第三个为不同机架的不同节点。
3 HDFS 读写工作原理
3.1 HDFS文件写入流程
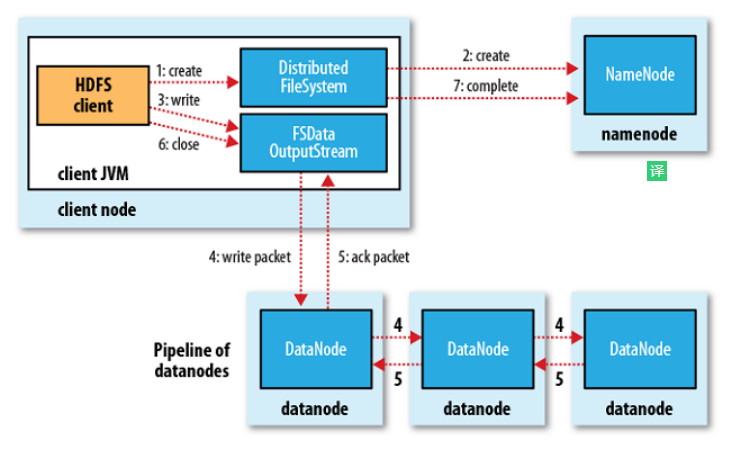
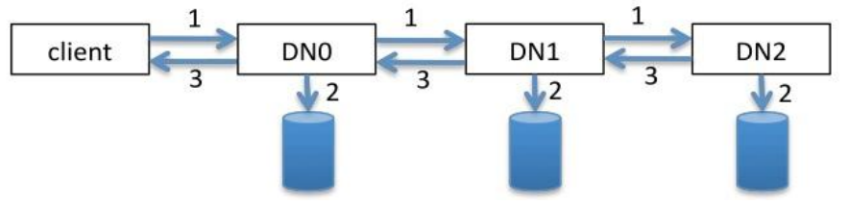
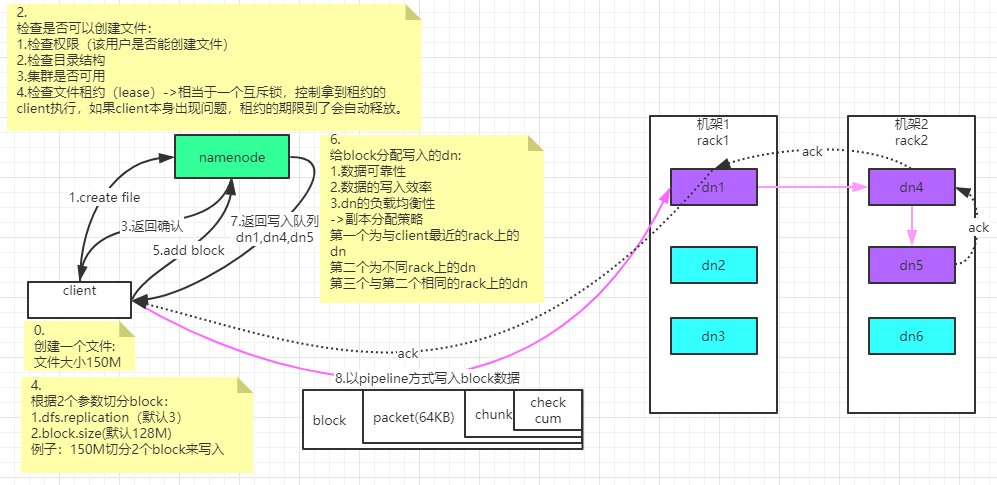
- 客户端创建 DistributedFileSystem 对象.
- DistributedFileSystem 对象调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件,并标识为“上传中”状态,即可以看见,但不能使用。
- DistributedFileSystem 返回 DFSOutputStream,客户端用于写数据。
- 客户端开始写入数据,DFSOutputStream 将数据分成块,写入 data queue(Data queue 由 Data Streamer 读取),并通知元数据节点分配数据节点,用来存储数据块(每块默认复制 3 块)。分配的数据节点放在一个 pipeline 里。Data Streamer 将数据块写入 pipeline 中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。注意:并不是第一个数据节点完全接收完 block 后再发送给后面的数据节点,而是接收到一部分 就发送,所以三个节点几乎是同时接收到完整的 block 的。DFSOutputStream 为发出去的数据块保存了 ack queue,等待 pipeline 中的数据节点告知数据已经写入成功。如果 block 在某个节点的写入的过程中失败:关闭 pipeline,将 ack queue 放 至 data queue 的开始。已经写入节点中的那些 block 部分会被元数据节点赋予新 的标示,发生错误的节点重启后能够察觉其数据块是过时的,会被删除。失败的节点从 pipeline 中移除,block 的其他副本则写入 pipeline 中的另外两个数据节点。元数据节点则被通知此 block 的副本不足,将来会再创建第三份备份。
- ack queue 返回成功。
- 客户端结束写入数据,则调用 stream 的 close 函数,
- 最后通知元数据节点写入完毕
总结:
客户端切分文件 Block,按 Block 线性地和 NN 获取 DN 列表(副本数),验证 DN 列表后以更小的单位流式传输数据,各节点两两通信确定可用,Block 传输结束后,DN 向 NN 汇报 Block 信息,DN 向 Client 汇报完成,Client 向 NN 汇报完成,获取下一个 Block 存放的 DN 列表,最终 Client 汇报完成,NN 会在写流程更新文件状态。
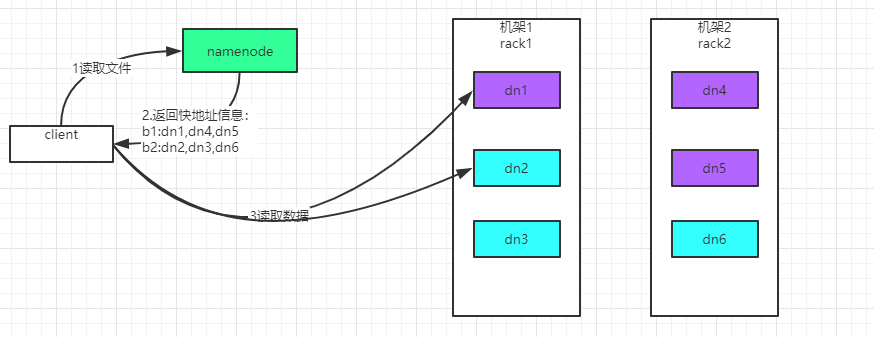
3.2 HDFS文件读取流程
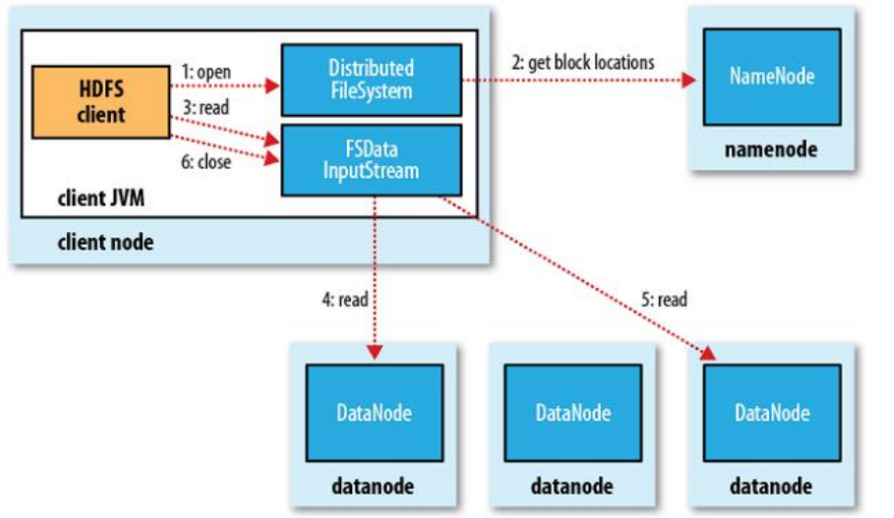
- 客户端(client)用 FileSystem 的 open()函数打开文件。
- DistributedFileSystem 调用元数据节点,得到文件的数据块信息。对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
- DistributedFileSystem 返回 FSDataInputStream 给客户端,用来读取数据。
- 客户端调用 stream 的 read()函数开始读取数据(也会读取 block 的元数据)。DFSInputStream 连接保存此文件第一个数据块的最近的数据节点(优先读取同机架的 block)。
- Data 从数据节点读到客户端。当此数据块读取完毕时,DFSInputStream 关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
- 当客户端读取完毕数据的时候,调用 FSDataInputStream 的 close 函数。
- 在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
总结:
客户端和 NN 获取一部分 Block(获取部分 block 信息,而不是整个文件全部的 block 信 息,读完这部分 block 后,再获取另一个部分 block 的信息)副本位置列表,线性地和 DN 获取 Block,最终合并为一个文件,在 Block 副本列表中按距离择优选取,如果选取到的副本完整就返回,否则找下一个副本。
4 深入
4.1 NameNode和SecondaryNameNode
- 作用:
- Namespace管理:负责管理文件系统中的树状目录结构以及文件与数据块的映射关系
- 块信息管理:负责管理文件系统中文件的物理块与实际存储位置的映射关系BlocksMap
- 集群信息管理:机架信息,datanode信息
- 集中式缓存管理:从Hadoop2.3 开始,支持datanode将文件缓存到内存中,这部分缓存通过NN集中管理
- 存储结构:
- 内存: Namespace数据,BlocksMap数据,其他信息
- 文件:
- 已持久化的namespace数据:FsImage
- 未持久化的namespace操作:Edits
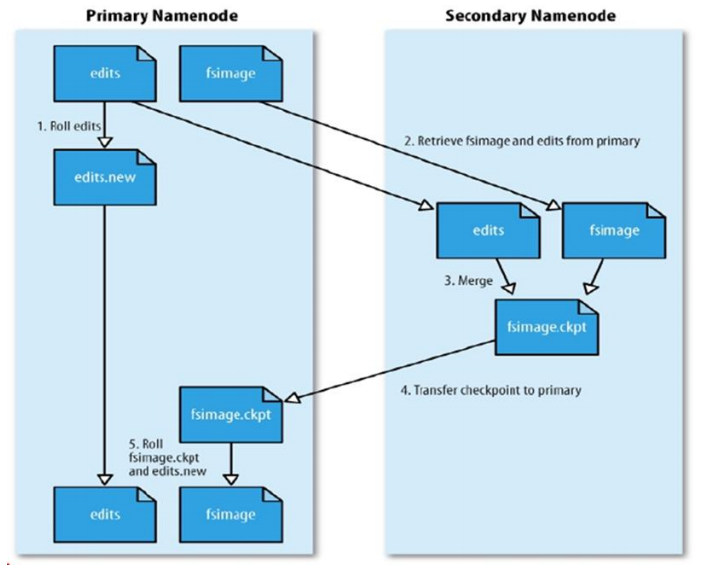
合并流程:
- NN 创建一个新的 edits log 来接替老的 edits 的工作
- NN 将 fsimage 和旧的 edits 拷备到 SNN 上
- SNN 上进行合并操作,产生一个新的 fsimage
- 将新的 fsimage 复制一份到 NN 上
- 使用新的 fsimage 和新的 edits log
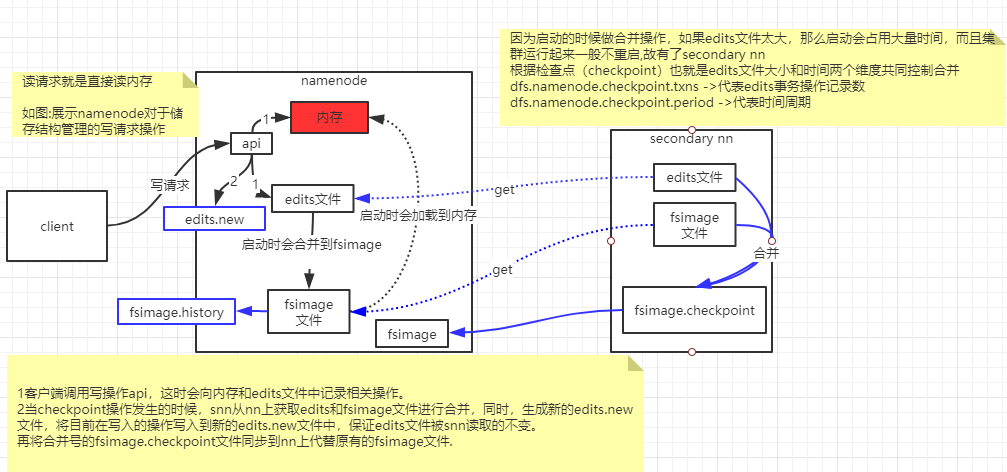
4.2 集群启动过程
开启安全模式:不能执行数据修改操作
加载fsimage
逐个执行所有Edits文件中的每一条操作将操作合并到fsimage,完成后生成一个空的edits文件
接收datanode发送来的心跳消息和块信息
根据以上信息确定文件系统状态
退出安全模式
4.3 安全模式
- 安全模式:文件系统只接受读数据请求,而不接受删除、修改等变更请求
- 什么情况下进入:NameNode主节点启动时,HDFS进入安全模式
- 什么时候时候退出:系统达到安全标准时,HDFS退出安全模式
- dfs.namenode.safemode.min.datanodes: 最小可用datanode数量
- dfs.namenode.safemode.threshold-pct: 副本数达到最小要求的block占系统总文件block数的百分比
- 总文件block数100个,每个block需要有3个副本,满足3个副本的block数量为70个,那么pct=70%(默认0.999)
- 常见进入安全模式不退出就是因为学习机器不够,副本数低于3,这个参数进行验证不通过。
- dfs.namenode.safemode.extension: 稳定时间
- 相关命令:
- hdfs dfsadmin -safemode get:查看当前状态
- hdfs dfsadmin -safemode enter:进入安全模式
- hdfs dfsadmin -safemode leave:强制离开安全模式
- hdfs dfsadmin -safemode wait:一直等待直到安全模式结束
5 HDFS Federation (联邦)
通过多个 namenode/namespace 把元数据的存储和管理分散到多个节点中,使到namenode/namespace 可以通过增加机器来进行水平扩展。能把单个 namenode 的负载分散到多个节点中,在 HDFS 数据规模较大的时候不会也降低 HDFS 的性能。可以通过多个namespace 来隔离不同类型的应用,把不同类型应用的 HDFS 元数据的存储和管理分派到不同的 namenode 中。核心:多台 namenode 管理的是同一个集群!
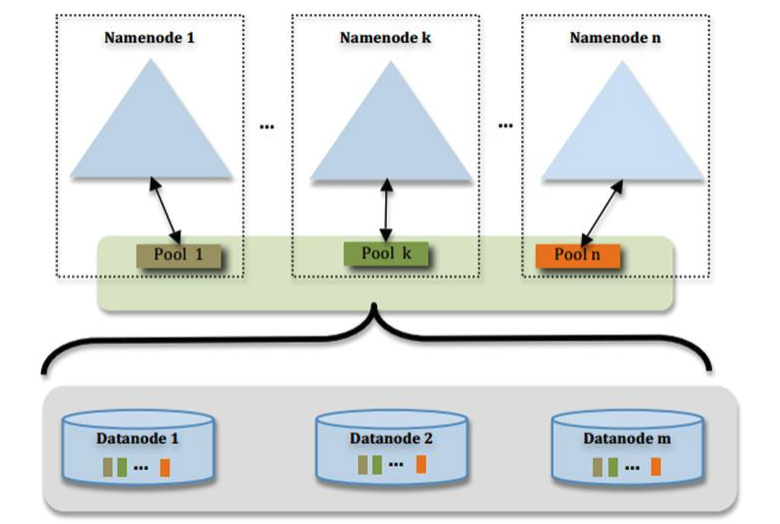
假设服务器内存:128G=137438953472字节 ,一个块大概使用150字节,那么可以存储的块数量为:916259689g个,因为一个默认块大小为128M,那么可以储存的文件大小为109PB左右,远远达不到大数据的规模(目前有些大公司能达到一台NameNode管理上EB的数据),这个时候就需要Federation(联邦),多个NameNode管理一套集群。
6 HDFS HA(High Availability高可用)
6.1 高可用架构图
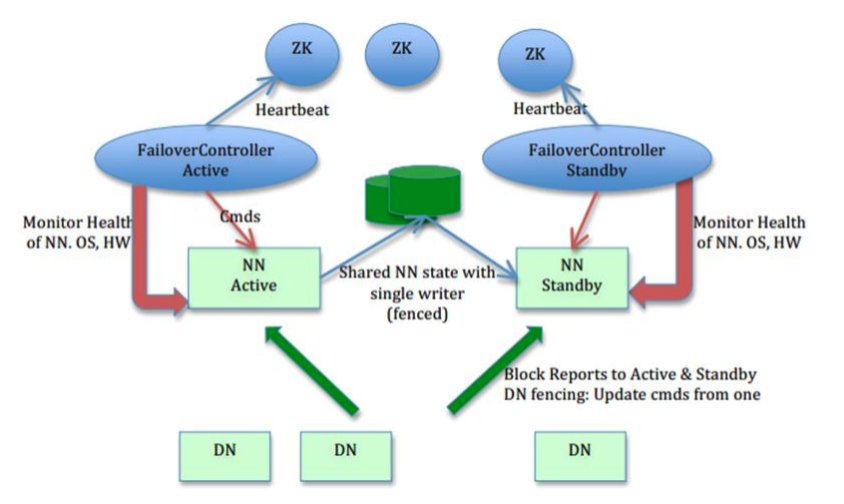
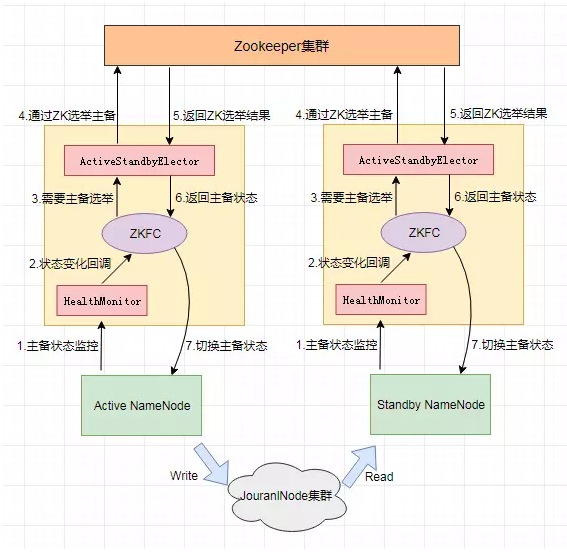
- 主备 NameNode,解决单点故障:
- ANN:ActiveNameNode,对外提供服务,SNN 同步 ANN 元数据,以待切换。
- SNN:StandbyNameNode,完成了 edits.log 文件的合并产生新的 image,推送回 ANN。
- JNN:JournalNode,ANN 和 SNN 通过 JNN 集群来共享信息。两个 NameNode 为了数据同步,会通过一组称作 JournalNodes 的独立进程进行相互通信。当 ANN 的命名空间有任何修改时,会告知大部分的 JournalNodes 进程。SNN 有能力读取 JNs 中的变更信息,并且一直监控 edit log 的变化,把变化应用于自己的命名空间。SNN 可以确保在集群出错时,命名空间状态已经完全同步了。在 HA 架构里面 SecondaryNameNode 这个冷备角色已经不存在了,为了保持 SNN 实时的与 ANN 的元数据保持一致,他们之间交互通过一系列守护的轻量级进程 JournalNode。基本原理就是用 2N+1 台 JN 存储 editlog,每次写数据操作有超过 半数(>=N+1)返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍 的是最多有 N 台机器挂掉,如果多于 N 台挂掉,这个算法就失效了。任何修改操作在 ANN上执行时,JN 进程同时也会记录修改 log 到至少半数以上的 JN 中,这时 SNN 监测到 JN 里面的同步 log 发生变化了会读取 JN 里面的修改 log,然后同步到自己的的目录镜像树里面。当发生故障时,ANN 挂掉后,SNN 会在它成为 ANN 前,读取所有的 JN 里面的修改日志,这样就能高可靠的保证与挂掉的 NN 的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
- DN:同时向两个 NameNode 汇报数据块信息(位置)。
- 两个 NN 之间的切换:
- 手动切换:通过命令实现主备之间的切换,可以用 HDFS 升级等场合。
- 自动切换:基于 Zookeeper 实现。
- HDFS 2.x 提供了 ZookeeperFailoverController 角色,部署在每个 NameNode 的节点上,作为一个 deamon 进程, 简称 zkfc,zkfc 主要包括三个组件:
- HealthMonitor:监控 NameNode 是否处于 unavailable 或 unhealthy 状态。当前通过RPC 调用 NN 相应的方法完成。
- ActiveStandbyElector:管理和监控自己在 ZK 中的状态。
- ZKFailoverController:它订阅 HealthMonitor 和 ActiveStandbyElector 的事件,并管理NameNode 的状态。
- 简称ZKFC,就是Zookeeper客户端。
- ZKFailoverController 主要职责:
- 健康监测:周期性的向它监控的 NN 发送健康探测命令,从而来确定某个NameNode 是否处于健康状态,如果机器宕机,心跳失败,那么 zkfc 就会标记它处于一个不健康的状态
- 会话管理:如果 NN 是健康的,zkfc 就会在 zookeeper 中保持一个打开的会话,如果 NameNode 同时还是 Active 状态的,那么 zkfc 还会在 Zookeeper 中占有一个类型为短暂类型的 znode,当这个 NN 挂掉时,这个 znode 将会被删除,然后备用的NN,将会得到这把锁,升级为主 NN,同时标记状态为 Active,当宕机的 NN 新启动时,它会再次注册 zookeper,发现已经有 znode 锁了,便会自动变为 Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置 2 个 NN.
- master 选举:如上所述,通过在 zookeeper 中维持一个短暂类型的 znode,来实现抢占式的锁机制,从而判断那个 NameNode 为 Active 状态。
6.2 故障转移流程
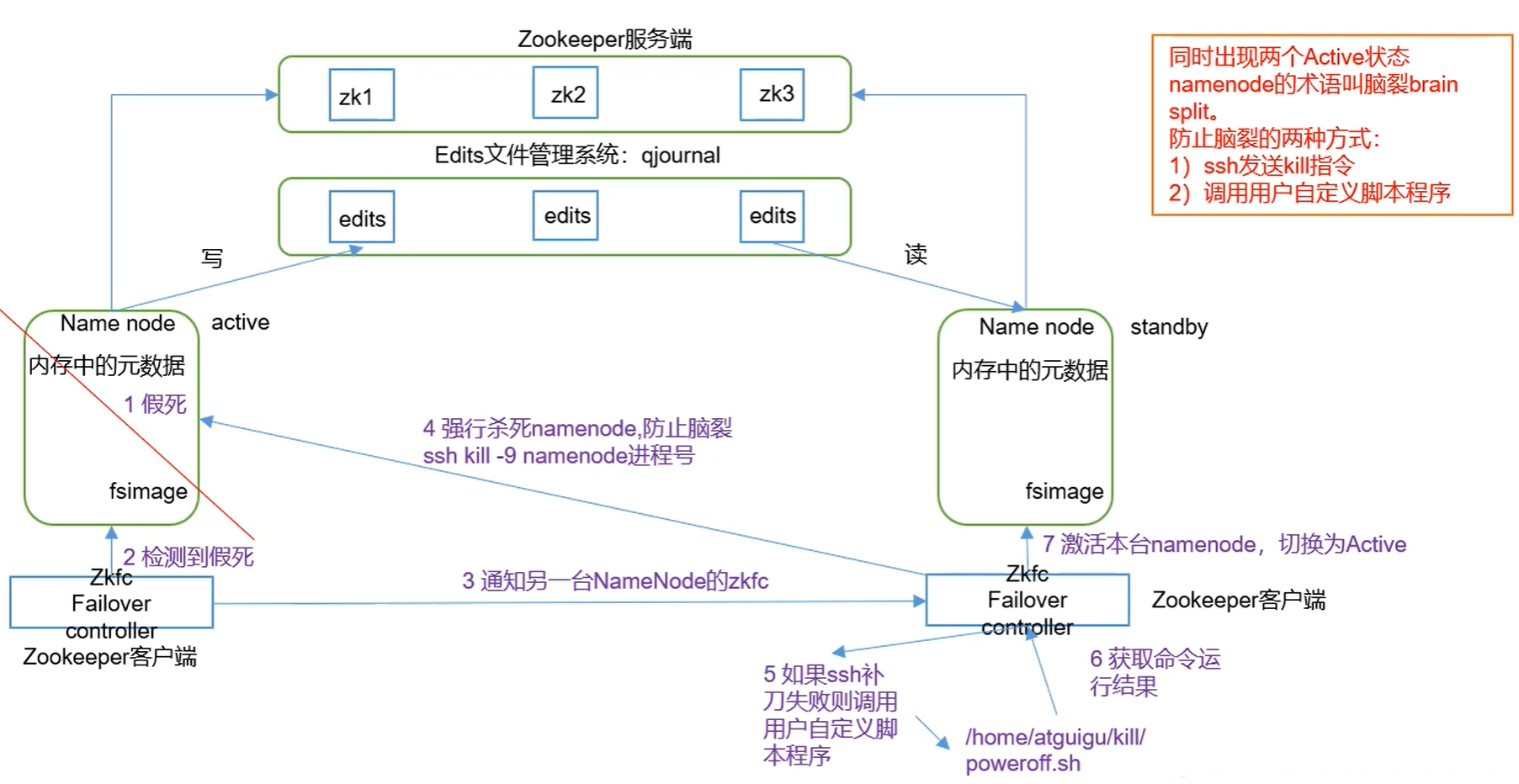
- 上图注意:SecondaryNameNode被另一台NameNode取代,edits文件交由qjournal管理。
6.3 CM配置HA注意点:

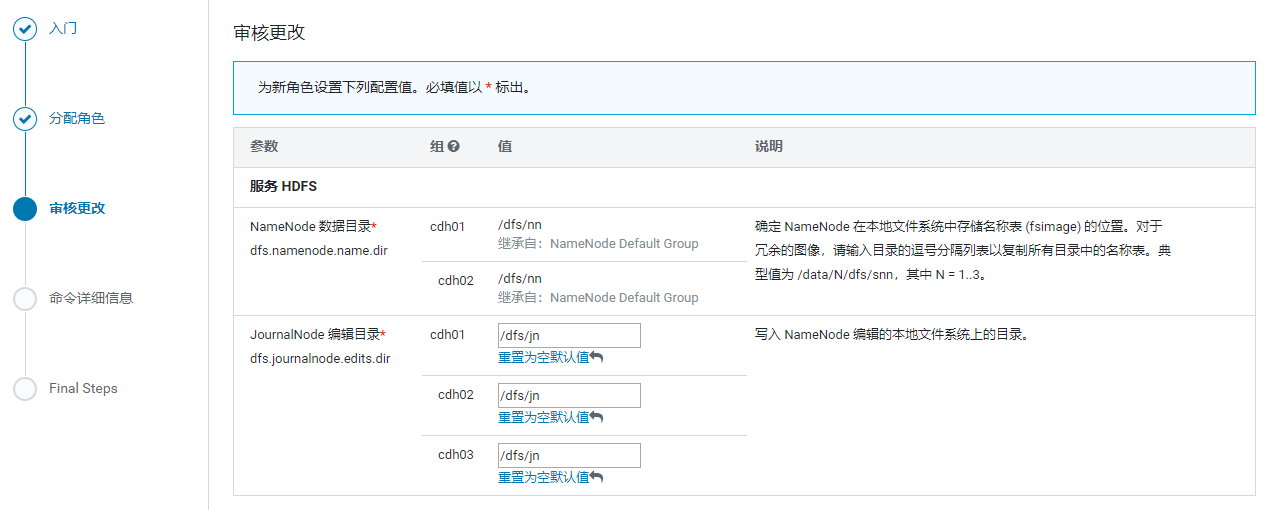
cdh01.com--------
QuorumPeerMain(zk)
DFSZKFailoverController
NameNode
JournalNode
cdh02.com--------
QuorumPeerMain(zk)
DFSZKFailoverController
JournalNode
DataNode
cdh03.com--------
QuorumPeerMain(zk)
JournalNode
DataNode
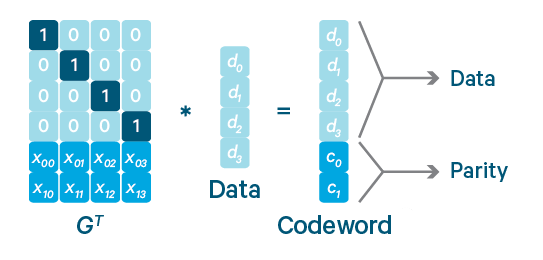
7 HDFS纠删码(时间换空间)
hdfs3.0后引入纠删码
- 复制策略:1tb数据,需要3tb磁盘空间
纠删码:只需要复制策略一半左右的磁盘空间,而且同样可以保证数据的可靠性
a=1
b=2
c=3
a+b+c=6
a+2b+3c=14
a+3b+4c=19
我们需要求出a,b,c的值,那么最少需要的方程数为?3个
如果有4个方程,就允许丢失任意一个方程
如果有5个方程,就允许丢失任意两个方程
a=1
b=2
c=3
视为数据
a+b+c=6
a+2b+3c=14
a+3b+4c=19
视为一个效验/沉余数据
如果是复制策略,要允许丢失任意2份数据,我们需要3*3=9份空间
如果是究删码策略,要允许丢失任意2份数据,我们需要3+2=5份空间
8 HDFS文件类型
| 文件格式 | 类型 | 存储方式 | 是否带schema | 特点描述 | 出处 |
|---|---|---|---|---|---|
| txt,json,csv | 行式 | 文本 | 否 | 默认存储方式(txt),数据内容可以直接cat查看,存储效率较高,处理效率低。压缩比较低 | Hadoop |
| Sequence file | 行式 | 二进制 | 是 | 以key,value对的方式存储。压缩比中等 | Hadoop |
| Avro | 行式 | 二进制 | 是 | 数据序列化框架,同时支持RPC,数据自带schema,支持比较丰富的数据类型。与protobuf, thrift 类似。压缩比中等 | Hadoop |
| RC(record columnar) | 列式 | 二进制 | 是 | 列式存储,将数据按照行组分块,读取以行组为单位,但是行组中可以跳过不需要的列。压缩比中等 | Hive |
| ORC(optimized record columnar) | 列式 | 二进制 | 是 | 升级版的RC,使用了更优化的存储结构,从而获得更好的性能,另外支持对数据的修改和ACID。压缩比高 | Hive |
| Parquet | 列式 | 二进制 | 是 | 支持嵌套类型,可高效实现对列的查询或统计。压缩比高 | Impala |
9 数据压缩类型
| 压缩格式 | split | 压缩率 | 压缩速度 | 是否 hadoop自带 | linux命令 | 换成压缩格式后,原来的应用程序是否要修改 | 使用建议 |
|---|---|---|---|---|---|---|---|
| gzip | 否 | 很高 | 比较快 | 是 | 有 | 和文本处理一样,不需要修改 | • 使用方便 • 当每个文件压缩之后在130M以内的(1个块大小内),都可以考虑用gzip压缩格式 |
| lzo | 是 | 比较高 | 很快 | 否,需要安装 | 有 | 需要建索引,还需要指定输入格式 | • 压缩率和压缩速度综合考虑 • 支持split,是hadoop中最流行的压缩格式; • 一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,lzo优点越明显 • cloudera&twitter |
| snappy | 否 | 比较高 | 很快 | 否,需要安装 | 没有 | 和文本处理一样,不需要修改 | • 压缩率和压缩速度综合考虑 • 当mapreduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式 • spark默认压缩格式 • google出品 |
| bzip2 | 是 | 最高 | 慢 | 是 | 有 | 和文本处理一样,不需要修改 | • 压缩率高 • 适合对速度要求不高,但需要较高的压缩率,比如数据比较大,需要压缩存档减少磁盘空间并且以后数据用得比较少的情况 |
10 HDFS常用命令
-help:输出这个命令参数。如:hadoop fs -help ls (输出ls命令的参数)-ls:显示目录信息。如:hadoop fs -ls / (查询hdfs上根目录的目录,,递归创建加 -R参数)-mkdir:在hdfs上创建目录。如:hadoop fs -mkdir /haha (根目录下创建haha文件夹,递归创建加 -p参数)-moveFromLocal:从本地剪切粘贴到hdfs。如:hadoop fs -moveFromLocal /haha/xixi.txt / (将本地haha文件夹下的xixi.txt文件剪切粘贴到hdfs的根目录下)-copyFromLocal:从本地拷贝到hdfs上。如:用法同上-copyToLocal:从hdfs上拷贝到本地。如:用法同上-cp:从hdfs的一个路径拷贝到hdfs的另一个路径。如:方法同上-mv:从hdfs上的一个路径移动到hdfs的另一个路径。如:方法同上-appendToFile:追加一个文件到已经存在的文件末尾。如:hadoop fs -appendToFile /haha/lala.txt /xixi.txt (将本地lala.txt文件内容追加到hdfs上xixi.txt里)-cat:显示文件内容。如:hadoop fs -cat /xixi.txt (查看xixi.txt)-tail:显示一个文件的末尾。-chmod:修改文件权限。如:hadoop fs -chmod 777 /xixi.txt (修改xixi.txt文件的权限)-get:等同于copyToLocal,就是从hdfs下载文件到本地。如:hadoop fs -get /xixi.txt ./ (下载到当前本地路径)-getmerge:合并下载多个文件,如:hadoop fs -getmerge /log/*.txt ./sum.txt (将hdfs上log文件夹下的所有.txt文件整合在一起,下载到本地,名字为sum.txt)-put:等同于copyFromLocal,就是上传文件到hdfs。如:hadoop fs -put /xixi.txt / (上传到hdfs的根路径)-rmr:删除文件或目录-df:统计文件系统的可用空间信息。如:hadoop fs -df -h /-du:统计文件夹的大小信息。如:-s总大小、-h单位-count:统计一个指定目录下的文件节点数。如:结果2 2 199 (第一个参数说的是最多有几级目录,第二个参数说的是一共有多少文件)
11 HDFS SHELL操作
11.1 hdfs常用基础命令
- 帮助:hadoop fs -help

- 查看结构:hdfs dfs -ls [/查看目录名称]

- 上传:hdfs dfs -put [文件] [/上传目录名称]

- 拷贝:hdfs dfs -cp [源文件名] [目标文件名]

- 查看文件:hdfs dfs -cat [文件名]

- 删除:hdfs dfs -rmr [文件]
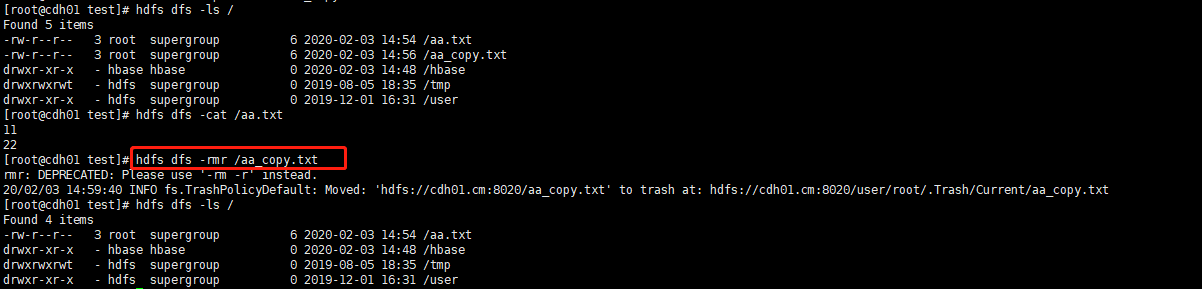
- 修改权限(同linux):hdfs dfs -chmod [权限级别] [文件]

- 查看硬盘:hdfs dfs -df -h

- 查看每个文件占用大小:hdfs dfs -du -h [目录]

11.2 本地->HDFS命令
- 上传:hdfs dfs -put [文件] [/上传目录名称]
- 上传(同put):hdfs dfs -copyFromLocal [文件] [/上传目录名称]

- 剪切上传:hdfs dfs -moveFromLocal [文件] [/上传目录名称]
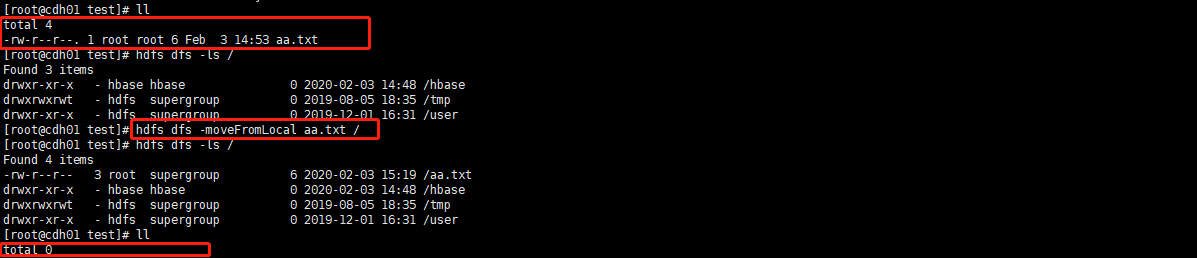
- 追加:hdfs dfs -appendToFile [源文件] [/需要追加的文件]

11.3 HDFS->本地命令
- 下载:hdfs dfs -get [/HDFS源文件] [本地路径]

- 下载(同get):hdfs dfs -copyToLocal [/HDFS源文件] [本地路径]

- 合并下载:hdfs dfs -getmerge [/HDFS源文件] [本地文件名]

11.4 合并小文件
- 打包:hadoop archive -archiveName [har包名称] -p [/需要打包文件] [/打包文件存放地址]
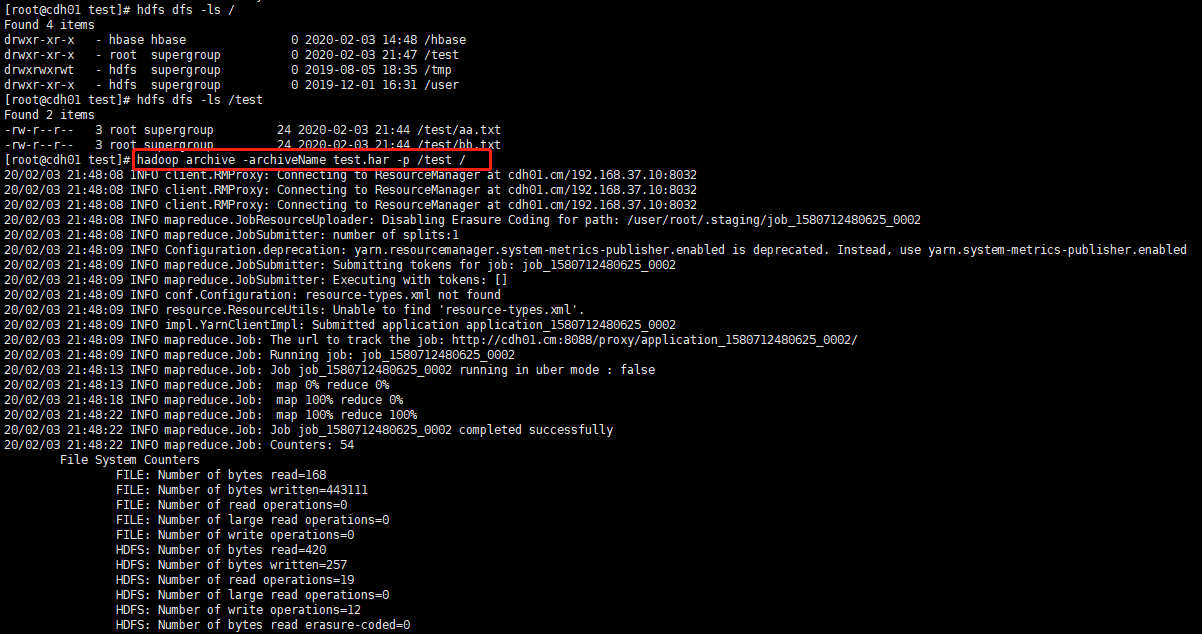


- 查看包:hdfs dfs -ls har://[har包文件]

12 windows 大数据开发环境配置
- 下载winutils解压
- 配置对应版本的环境变量名为:HADOOP_HOME 值为:解压目录如上F:\bigdatasoft\hadoop\winutils-master\hadoop-3.0.0
- 环境变量Path添加:%HADOOP_HOME%\bin
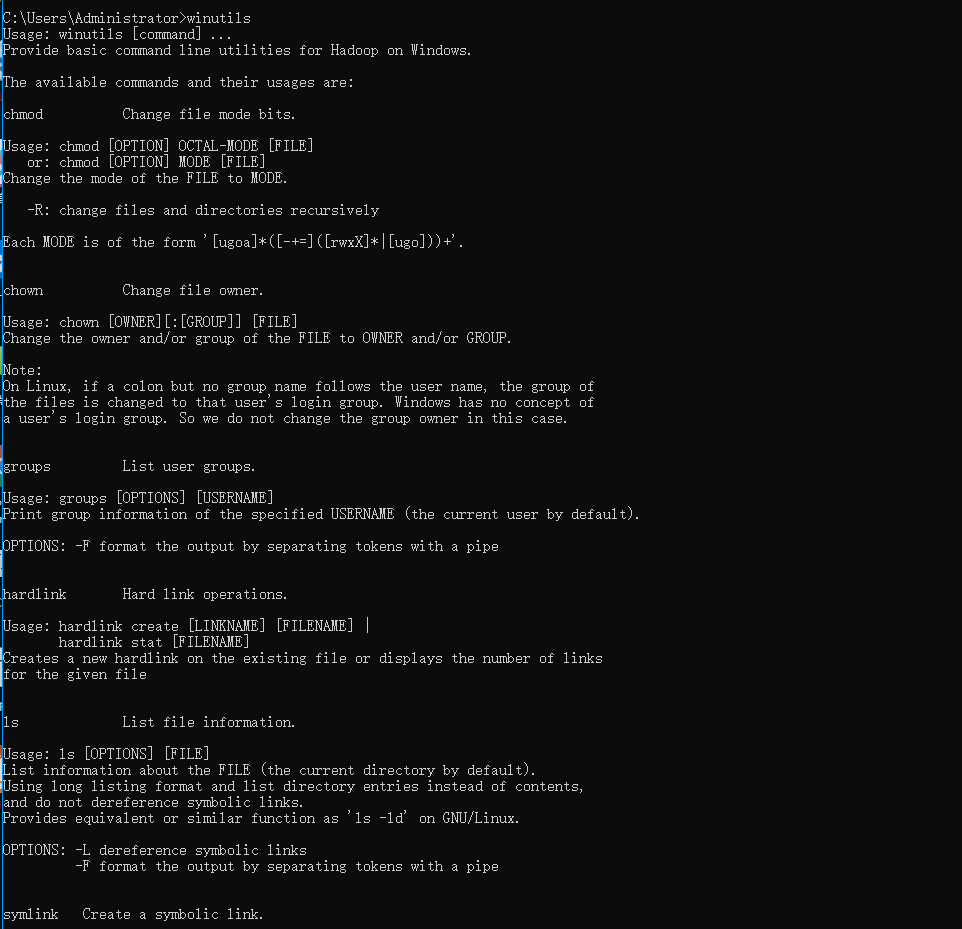
- 重启电脑,打开cmd,输入winutils,出现下图证明配置成功

13 基本API使用
项目地址:https://github.com/70416450/Bigdata-Util
- 修改hdfs.properties中的配置信息
- 使用单元测试类测试每一个API吧。
大数据篇:HDFS的更多相关文章
- 大数据篇:Zookeeper
Zookeeper 1 Zookeeper概念 Zookeeper是什么 是一个基于观察者设计模式的分布式服务管理框架,它负责和管理需要关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Z ...
- 大数据篇:YARN
YARN YARN是什么? YARN是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率.资源统一管理和数据共享等方面带来了巨大 ...
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 大数据篇:ElasticSearch
ElasticSearch ElasticSearch是什么 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口. ...
- 大数据篇:Hive
大数据篇:Hive hive.apache.org Hive是什么? Hive是Facebook开源的用于解决海量结构化日志的数据统计,是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射 ...
- 大数据篇:Hbase
大数据篇:Hbase Hbase是什么 Hbase是一个分布式.可扩展.支持海量数据存储的NoSQL数据库,物理结构存储结构(K-V). 如果没有Hbase 如何在大数据场景中,做到上亿数据秒级返回. ...
- 大数据篇:Spark
大数据篇:Spark Spark是什么 Spark是一个快速(基于内存),通用,可扩展的计算引擎,采用Scala语言编写.2009年诞生于UC Berkeley(加州大学伯克利分校,CAL的AMP实验 ...
- 大数据篇:一文读懂@数据仓库(PPT文字版)
大数据篇:一文读懂@数据仓库 1 网络词汇总结 1.1 数据中台 数据中台是聚合和治理跨域数据,将数据抽象封装成服务,提供给前台以业务价值的逻辑概念. 数据中台是一套可持续"让企业的数据用起 ...
- FusionInsight大数据开发---HDFS应用开发
HDFS应用开发 HDFS(Dadoop Distributed File System) HDFS概述 高容错性 高吞吐量 大文件存储 HDFS架构包含三部分 Name Node DataNode ...
随机推荐
- CCPC-Wannafly Winter Camp Day1 (Div2 ABCFJ) 待补...
Day1 Div2 场外链接 按题目顺序~ A 机器人 传送门 题意:有两条平行直线A.B,每条直线上有n个点,编号为1~n.在同一直线上,从a站点到b站点耗时为两点间的距离.存在m个特殊站点,只有在 ...
- 自学 JAVA 的几点建议
微信公众号:一个优秀的废人 如有问题或建议,请后台留言,我会尽力解决你的问题. 前言 许久不见,最近公众号多了很多在校的师弟师妹们.有很多同学都加了我微信问了一些诸如 [如何自学 Java ]的问题, ...
- C语言编译成dll
首先c语言在开始要加上 #ifdef __cplusplus extern "C" { #endif …被导出的方法名称 #ifdef __cplusplus } #endif 不 ...
- 递推 dp
工大要建新教学楼了,一座很高很高的楼,它有n层.学校为了减少排电梯的队伍,建造了好多好多电梯,共有m个.为了让电梯有序,学校给每个电梯设定了独特的可停楼层,如 x1 x2 y1 y2 表示,x1楼层到 ...
- CF - 一直交换元素的规律
Dima is a beginner programmer. During his working process, he regularly has to repeat the following ...
- Vue中的nextTick()浅析
引言 在开发过程中,我们经常遇到这样的问题:我明明已经更新了数据,为什么当我获取某个节点的数据时,却还是更新前的数据? 一,浅析 为什么会这样呢?带着这个疑问先往下看. 先看一个小的例子: <d ...
- AVR单片机教程——串口接收
本文隶属于AVR单片机教程系列. 上一讲中,我们实现了单片机开发板向电脑传输数据.在这一讲中,我们将通过电脑向单片机发送指令,让单片机根据指令控制LED.这一次,两端的TX与RX需要交叉连接,单片 ...
- Activiti 启动事件(Start Event)
Activiti 启动事件(Start Event) 作者:Jesai 生活里,没有容易二字,忧伤是一种本能,而微笑是一种能力 版权所有,未经允许,禁止引用.如需引用,请注明出处. 前言: 启动事件是 ...
- mongdb角色的授权
开启cmd窗口切换到cd D:\programs\mongoDB\bin D:\programs\mongoDB\bin>mongo MongoDB shell version v3.4.6 c ...
- 【Vue】强化表单的9个Vue输入库
一个设计不当的表单可能会使用户远离你的网站.幸运的是,对Vue开发者,有大量可用的Vue输入库让你轻松整理表单. 拥有直观而且对用户友好的表单有诸多好处,比如: 更高的转化率 更好的用户体验 更专业的 ...