亲历者说:Kubernetes API 与 Operator,不为人知的开发者战争
如果我问你,如何把一个 etcd 集群部署在 Google Cloud 或者阿里云上,你一定会不假思索的给出答案:当然是用 etcd Operator!
实际上,几乎在一夜之间,Kubernetes Operator 这个新生事物,就成了开发和部署分布式应用的一项事实标准。时至今日,无论是 etcd、TiDB、Redis,还是 Kafka、RocketMQ、Spark、TensorFlow,几乎每一个你能叫上名字来的分布式项目,都由官方维护着各自的 Kubernetes Operator。而 Operator 官方库里,也一直维护着一个知名分布式项目的 Operator 汇总。
https://github.com/operator-framework/awesome-operators
短短一年多时间,这个列表的长度已经增长了几十倍。
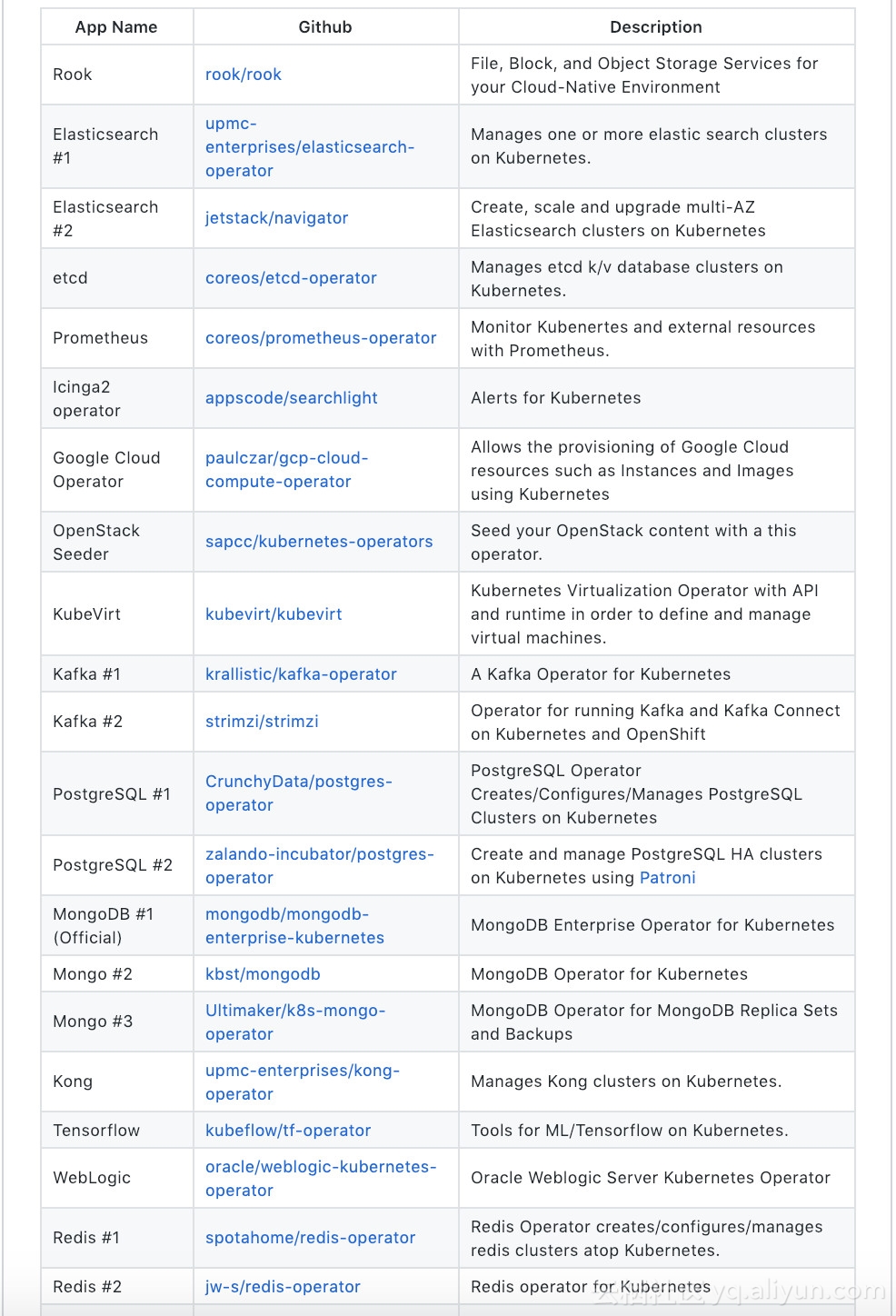
而且更有意思的是,如果你仔细翻阅这个 Operator 列表,你就不难发现这样一个有趣的事实:现今 Kubernetes Operator 的意义,恐怕已经远远超过了“分布式应用部署”的这个原始的范畴,而已然成为了容器化时代应用开发与发布的一个全新途径。所以,你才会在这个列表里看到,Android SDK 的开发者们,正在使用 Operator “一键”生成和更新 Android 开发环境;而 Linux 系统工程师们,则在使用Operator “一键”重现性能测试集群。
如果说,Docker 镜像的提出,完成了应用静态描述的标准化。那么 Kubernetes Operator 的出现,终于为应用的动态描述提出了一套行之有效的实现规范。更为重要的是,对于 TiDB、Kafka、RocketMQ 等分布式应用的开发者来说,这些应用运行起来之后的动态描述,才是对一个分布式应用真正有意义的信息。
而在此之前,用户如果要想将 TiDB、Kafka 这样的分布式应用很好的使用起来,就不得不去尝试编写一套复杂的管理脚本,甚至为此学习大量与项目本身无关的运维知识。更为麻烦的是,这些脚本、知识、和经验,并没有一个很好的办法能够有效的沉淀下来。而任何一种技术的传授,如果严重依赖于口口相传而不是固化的代码和逻辑的话,那么它的维护成本和使用门槛,就可以说是“灾难级”的。
所以说,Kubernetes Operator 发布之初最大的意义,就在于它将分布式应用的使用门槛直接降到了最低。
那么这个门槛具体有多低呢?
一般来说,无论这个分布式应用项目有多复杂,只要它为用户提供了 Operator,那么这个项目的使用就只需要两条命令即可搞定,以 Kafka 为例:

这两条命令执行完成后,一个 Kafka 集群运行所需的节点,以及它们所依赖的 ZooKeeper 节点,就会以容器的方式自动出现在你的 Kubernetes 集群里了。
不过,简化运维和部署,其实只是 Operator 在用户层面的表象。而在更底层的技术层面,Operator 最大的价值,在于它为“容器究竟能不能管理有状态应用”这个颇具争议话题,画上了一个优雅的句号。
要知道,在2014-2015年的时候,伴随着 Docker 公司和 Docker 项目的走红,整个云计算生态几乎都陷入了名为“容器”的狂热当中。然而,相比于 “容器化”浪潮的如火如荼,这个圈子却始终对“有状态应用”讳莫如深。
事实上,有状态应用(比如, 前面提到的Kafka )跟无状态应用(比如,一个简单的Jave Web网站)的不同之处,就在于前者对某些外部资源有着绑定性的依赖,比如远程存储,或者网络设备,以及,有状态应用的多个示例之间往往有着拓扑关系。这两种设计,在软件工程的世界里可以说再普通不过了,而且我们几乎可以下这样一个结论:所有的分布式应用都是有状态应用。
但是,在容器的世界里,分布式应用却成了一个“异类”。我们知道,容器的本质,其实就是一个被限制了“世界观”的进程。在这种隔离和限制的大基调下,容器技术本身的“人格基因”,就是对外部世界(即:宿主机)的“视而不见”和“充耳不闻”。所以我们经常说,容器的“状态”一定是“易失”的。其实,容器对它的“小世界”之外的状态和数据漠不关心,正是这种“隔离性”的主要体现。
但状态“易失”并不能说是容器的缺陷:我们既然对容器可以重现完整的应用执行环境的“一致性”拍手称赞,那就必然要对这种能力背后的限制了然于心。这种默契,也正是早期的 Docker 公司所向披靡的重要背景:在这个阶段,相比于“容器化”的巨大吸引力,开发者是可以暂时接受一部分应用不能运行在容器里的。
而分布式应用容器化的困境,其实就在于它成为了这种“容器化”默契的“终极破坏者”。
一个应用本身可以拥有多个可扩展的实例,这本来是容器化应用令人津津乐道的一个优势。但是一旦这些实例像分布式应用这样具有了拓扑关系,以及,这些实例本身不完全等价的时候,容器化的解决方案就再次变得“丑陋”起来:这种情况下,应用开发者们不仅又要为这些容器实例编写一套难以维护的管理脚本,还必须要想办法应对容器重启后状态丢失的难题。而这些容器状态的维护,实际上往往需要打破容器的隔离性、让容器对外部世界有所感知才能做到,这就使得容器化与有状态,成为了两种完全相悖的需求。
不过,从上面的叙述中相信你也应该已经察觉到,分布式应用容器化的难点,并不在于容器本身有什么重大缺陷,而在于我们一直以来缺乏一种对“状态”的合理的抽象与描述,使得状态可以和容器进程本身解耦开来。这也就解释了为什么,在 Kubernetes 这样的外部编排框架逐渐成熟起了之后,业界才逐渐对有状态应用管理开始有了比较清晰的理解和认识。
而我们知道, Kubernetes 项目最具价值的理念,就是它围绕 etcd 构建出来的一套“面向终态”编排体系,这套体系在开源社区里,就是大名鼎鼎的“声明式 API”。
“声明式 API”的核心原理,就是当用户向 Kubernetes 提交了一个 API 对象的描述之后,Kubernetes 会负责为你保证整个集群里各项资源的状态,都与你的 API 对象描述的需求相一致。更重要的是,这个保证是一项“无条件的”、“没有期限”的承诺:对于每个保存在 etcd 里的 API 对象,Kubernetes 都通过启动一种叫做“控制器模式”(Controller Pattern)的无限循环,不断检查,然后调谐,最后确保整个集群的状态与这个 API 对象的描述一致。
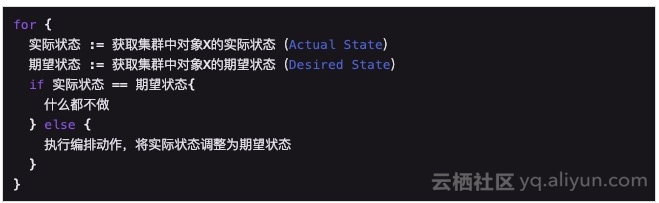
比如,你提交的 API 对象是一个应用,描述的是这个应用必须有三个实例,那么无论接下来你的 API 对象发生任何“风吹草动”,控制器都会检查一遍这个集群里是不是真的有三个应用实例在运行。并且,它会根据这次检查的结果来决定,是不是需要对集群做某些操作来完成这次“调谐”过程。当然,这里控制器正是依靠 etcd 的 Watch API 来实现对 API 对象变化的感知的。在整个过程中,你提交的 API 对象就是 Kubernetes 控制器眼中的“金科玉律”,是接下来控制器执行调谐逻辑要达到的唯一状态。这就是我们所说的“终态”的含义。
而 Operator 的设计,其实就是把这个“控制器”模式的思想,贯彻的更加彻底。在 Operator 里,你提交的 API 对象不再是一个单体应用的描述,而是一个完整的分布式应用集群的描述。这里的区别在于,整个分布式应用集群的状态和定义,都成了Kubernetes 控制器需要保证的“终态”。比如,这个应用有几个实例,实例间的关系如何处理,实例需要把数据存储在哪里,如何对实例数据进行备份和恢复,都是这个控制器需要根据 API 对象的变化进行处理的逻辑。
从上述叙述中,你就应该能够明白, Operator 其实就是一段代码,这段代码 Watch 了 etcd 里一个描述分布式应用集群的API 对象,然后这段代码通过实现 Kubernetes 的控制器模式,来保证这个集群始终跟用户的定义完全相同。而在这个过程中,Operator 也有能力利用 Kubernetes 的存储、网络插件等外部资源,协同的为应用状态的保持提供帮助。
所以说,Operator 本身在实现上,其实是在 Kubernetes 声明式 API 基础上的一种“微创新”。它合理的利用了 Kubernetes API 可以添加自定义 API 类型的能力,然后又巧妙的通过 Kubernetes 原生的“控制器模式”,完成了一个面向分布式应用终态的调谐过程。
而 Operator 本身在用法上,则是一个需要用户大量编写代码的的开发者工具。 不过,这个编写代码的过程,并没有像很多人当初料想的那样导致 Operator 项目走向小众,反而在短短三年的时间里, Operator 就迅速成为了容器化分布式应用管理的事实标准。时至今日,Operator 项目的生态地位已经毋庸置疑。就在刚刚结束的2018年 KubeCon 北美峰会上,Operator 项目和大量的用户案例一次又一次出现在聚光灯前,不断的印证着这个小小的“微创新”对整个云计算社区所产生的深远影响。
不过,在 Operator 项目引人瞩目的成长经历背后,你是否考虑过这样一个问题:
Kubernetes 项目一直以来,其实都内置着一个管理有状态应用的能力叫作 StatefulSet。而如果你稍微了解 Kubernetes 项目的话就不难发现,Operator 和 StatefulSet,虽然在对应用状态的抽象上有所不同,但它们的设计原理,几乎是完全一致的,即:这两种机制的本质,都是围绕Kubernetes API 对象的“终态”进行调谐的一个控制器(Controller)而已。
可是,为什么在一个开源社区里,会同时存在这样的两个核心原理完全一致、设计目标也几乎相同的有状态应用管理方案呢?作为 CoreOS 公司后来广为人知的“左膀右臂”之一(即:etcd 和 Operator),Operator 项目能够在 Kubernetes 生态里争取到今天的位置,是不是也是 CoreOS 公司的开源战略使然呢?
事实上,Operator 项目并没有像很多人想象的那样出生就含着金钥匙。只不过,在当时的确没有人能想到,当 CoreOS 的两名工程师带着一个业余项目从一间平淡无奇的公寓走出后不久,一场围绕着 Kubernetes API 生态、以争夺“分布式应用开发者”为核心的的重量级角逐,就徐徐拉开了序幕。
2016 年秋天,原 CoreOS 公司的工程师邓洪超像往常一样,来到了同事位于福斯特城(Foster City)的公寓进行结对编程。每周四相约在这里结对,是这两位工程师多年来约定俗成的惯例。

↑CoreOS 当年开发 etcd 所在的车库
不过,与以往不同的是,相比于往常天马行空般的头脑风暴,这一次,这两位工程师的脑子里正在琢磨着的,是一个非常“接地气”的小项目。
我们知道,Kubernetes 项目实现“容器编排”的核心,在于一个叫做“控制器模式”的机制,即:通过对 etcd 里的 API 对象的变化进行监视(Watch),Kubernetes 项目就可以在一个叫做 Controller 的组件里对这些变化进行响应。而无论是 Pod 等应用对象,还是 iptables、存储设备等服务对象,任何一个 API 对象发生变化,那么 Kubernetes 接下来需要执行的响应逻辑,就是对应的 Controller 里定义的编排动作。
所以,一个自然而然的想法就是,作为 Kubernetes 项目的用户,我能不能自己编写一个 Controller 来定义我所期望的编排动作呢?比如:当一个 Pod 对象被更新的时候,我的 Controller 可以在“原地”对 Pod 进行“重启”,而不是像 Deployment 那样必须先删除 Pod,然后再创建 Pod。
这个想法,其实是很多应用开发者以及 PaaS 用户的强烈需求,也是一直以来萦绕在 CoreOS 公司 CEO Alex Polvi 脑海里的一个念头。而在一次简单的内部讨论提及之后,这个念头很快就激发出了两位工程师的技术灵感,成为了周四结对编程的新主题。
而这一次,他们决定把这个小项目,起名叫做:Operator。
所以顾名思义,Operator 这个项目最开始的初衷,是用来帮助开发者实现运维(Operate)能力的。但 Operator 的核心思想,却并不是“替开发者做运维工作”,而是“让开发者自己编写运维工具”。更有意思的是,这个运维工具的编写标准,或者说,编写 Operator 代码可以参考的模板,正是 Kubernetes 的“控制器模式(Controller Pattern)”。
前面已经说过, Kubernetes 的“控制器模式”,是围绕着比如 Pod 这样的 API 对象,在 Controller 通过响应它的增删改查来定义对 Pod 的编排动作。
而 Operator 的设计思路,就是允许开发者在 Kubernetes 里添加一个新的 API 对象,用来描述一个分布式应用的集群。然后,在这个 API 对象的 Controller 里,开发者就可以定义对这个分布式应用集群的运维动作了。
举个例子, 假设下面这个 YAML 文件定义的,是一个 3 节点 etcd 集群的描述:
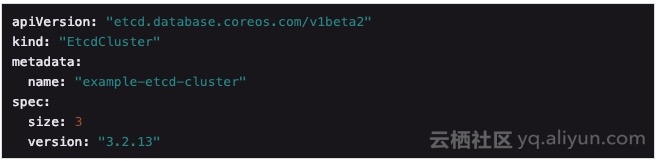
有了这样一个 etcdCluster 对象,那么开发者接下来要做的事情,就是编写一个 etcdCluster Controller,使得当任何用户提交这样一个 YAML 文件给 Kubernetes 之后,我们自己编写的 Controller 就会响应 etcdCluster “增加”事件,为用户创建出 3 个节点的 etcd 集群出来。然后,它还会按照我们在 Controller 编写的事件响应逻辑,自动的对这个集群的节点更新、删除等事件做出处理,执行我定义的其他运维功能。像这样一个 etcdCluster Controller,就是 etcd Operator 的核心组成部分了。
而作为 etcd 的开发者,CoreOS 的两位工程师把对 etcd 集群的运维工作编写成 Go 语言代码,一点都不困难。可是,要完成这个 Operator 真正困难在于:Kubernetes 只认识 Pod、Node、Service 等这些 Kubernetes 自己原生的 API 对象,它怎么可能认识开发者自己定义的这个 etcdCluster 对象呢?
在当时, Kubernetes 项目允许用户自己添加 API 对象的插件能力,叫做 Third Party Resource,简称:TPR。
TPR 允许你提交一个 YAML 文件,来定义你想要的的新 API 对象的名字,比如:etcdCluster;也允许你定义这个对象允许的合法的属性,比如:int 格式的 size 字段, string 格式的 version 字段。然后,你就可以提交一个具体的 etcdCluster 对象的描述文件给 Kubernetes,等待该对应的 Controller 进行处理。
而这个 Controller,就是 Operator 的主干代码了。
所以接下来,CoreOS 的两位工程师轻车熟路,在 Operator 里对 etcdCluster 对象的增、删、改事件的响应位置,写上了创建、删除、更新 etcd 节点的操作逻辑。然后,调试运行,看着一个 etcd 集群按照 YAML 文件里的描述被创建起来。大功告成!
就这样,在一个普通的周四下午,世界上第一个 Operator 诞生在了湾区的一所公寓当中。
而对于 CoreOS 的两位工程师来说,编写这个小工具的主要目的,就是借助 Kubernetes 的核心原理来自动化的管理 etcd 集群,更重要的是,不需要使用 Kubernetes 里自带的 StatefulSet。
你可能已经知道,Kubernetes 里本身就内置了一个叫做 StatefulSet 的功能,是专门用来管理有状态应用的。而 StatefulSet 的核心原理,其实是对分布式应用的两种状态进行了保持:
- 分布式应用的拓扑状态,或者说,节点之间的启动顺序;
- 分布式应用的存储状态,或者说,每个节点依赖的持久化数据。
可是,为了能够实现上述两种状态的保持机制,StatefulSet 的设计就给应用开发者带来了额外的束缚。
比如,etcd 集群各节点之间的拓扑关系,并不依赖于节点名字或者角色(比如 Master 或者 Slave)来确定,而是记录在每个 etcd 节点的启动参数当中。这使得 StatefulSet 通过“为节点分配有序的 DNS 名字”的拓扑保持方式,实际上没有了用武之地,反而还得要求开发者在节点的启动命令里添加大量的逻辑来生成正确的启动命令,非常不优雅。类似的,对于存储状态来说,etcd 集群对数据的备份和恢复方法,也跟 StatefulSet 依赖的的远程持久化数据卷方案并没有太大关系。
不难看到, StatefulSet 其实比较适用于应用本身节点管理能力不完善的项目,比如 MySQL。而对于 etcd 这种已经借助 Raft 实现了自管理的分布式应用来说, StatefulSet 的使用方法和带来的各种限制,其实是非常别扭的。
而带着工程师特有的较真儿精神,邓洪超和他的同事借助 Kubernetes 原生的扩展机制实现的,正是一个比 StatefulSet 更加灵活、能够把控制权重新交还给开发者的分布式应用管理工具。他们把这个工具起名叫做 Operator,并在几个月后的 KubeCon 上
进行了一次 Demo ,推荐大家尝试使用 Operator 来部署 etcd 集群。
没有人能想到的是,这个当时还处于 PoC 状态的小项目一经公布,就立刻激发起了整个社区的模仿和学习的热潮。
很快,大量的应用开发者纷纷涌进 Kubernetes 社区,争先恐后的宣布自己的分布式项目可以通过 Operator 运行起来。而敏锐的公有云提供商们很快看出了这其中的端倪:Operator 这个小框架,已然成为了分布式应用和有状态应用“上云”的必经之路。Prometheus,Rook,伴随着越来越多的、以往在容器里运行起来困难重重的应用,通过 Operator 走上了 Kubernetes 之后,Kubernetes 项目第一次出现在了开发者生态的核心位置。这个局面,已经远远超出了邓洪超甚至 CoreOS 公司自己的预期。
更重要的是,不同于 StatefulSet 等 Kubernetes 原生的编排概念,Operator 依赖的 Kubernetes 能力,只有最核心的声明式 API 与控制器模式;Operator 具体的实现逻辑,则编写在自定义 Controller 的代码中。这种设计给开发者赋予了极高的自由度,这在整个云计算和 PaaS 领域的发展过程中,都是非常罕见的。
此外,相比于 Helm、Docker Compose 等描述应用静态关系的编排工具,Operator 定义的乃是应用运行起来后整个集群的动态逻辑。得益于 Kubernetes 项目良好的声明式 API 的设计和开发者友好的 API 编程范式,Operator 在保证上述自由度的同时,又可以始终如一的展现出清晰的架构和设计逻辑,使得应用的开发者们,可以通过复制粘贴就快速搭建出一个 Operator 的框架,然后专注于填写自己的业务逻辑。
在向来讲究“用脚投票”的开发者生态当中,Operator 这样一个编程友好、架构清晰、方便代码复制粘贴的小工具,本身就已经具备了某些成功的特质。
然而,Operator 的意外走红,并没有让 CoreOS 公司“一夜成名”,反而差点将这个初出茅庐的项目,扼杀在萌芽状态。
在当时的 Kubernetes 社区里,跟应用开发者打交道并不是一个非常常见的事情。而 Operator 项目的诞生,却把 Kubernetes 项目第一次拉近到了开发者的面前,这让整个社区感觉了不适应。而作为 Kubernetes 项目 API 治理的负责人,Google 团队对这种冲突的感受最为明显。
对于 Google 团队来说,Controller 以及控制器模式,应该是一个隐藏在 Kubernetes 内部实现里的核心机制,并不适合直接开放给开发者来使用。退一步说,即使开放出去,这个 Controller 的设计和用法,也应该按照 Kubernetes 现有的 API 层规范来进行,最好能成为 Kubernetes 内置 Controller Manager 管理下的一部分。可是, Operator 却把直接编写 Controller 代码的自由度完全交给了开发者,成为了一个游离于 Kubernetes Controller Manager 之外的外部组件。
带着这个想法,社区里的很多团队从 Operator 项目诞生一开始,就对它的设计和演进方向提出了质疑,甚至建议将 Operator 的名字修改为 Custom Kubernetes Controller。而无巧不成书,就在 Google 和 CoreOS 在 Controller 的话语权上争执不下的时候, Kubernetes 项目的发起人之一 Brendan Burns 突然宣布加入了微软,这让 Google 团队和 Operator 项目的关系一下子跌倒了冰点。
你可能会有些困惑:Brendan Burns 与 Kubernetes 的关系我是清楚的,但这跟 Operator 又有什么瓜葛吗?
实际上,你可能很难想到,Brendan Burns 和他的团队,才是 TPR (Third Party Resource)这个特性最初的发起人。
所以,几乎在一夜之间,Operator 项目链路上的每一个环节,都与 Google 团队完美的擦肩而过。眼睁睁的看着这个正冉冉升起的开发者工具突然就跟自己完全没了关系,这个中滋味,确实不太好受。
于是,在 2017年初,Google 团队和 RedHat 公司开始主动在社区推广 UAS(User Aggregated APIServer),也就是后来 APIServer Aggregator 的雏形。APIServer Aggregator 的设计思路是允许用户编写一个自定义的 APIServer,在这里面添加自定义 API。然后,这个 APIServer 就可以跟 Kubernetes 原生的 APIServer 绑定部署在一起统一提供服务了。不难看到,这个设计与 Google 团队认为自定义 API 必须在 Kubernetes 现有框架下进行管理的想法还是比较一致的。
紧接着,RedHat 和 Google 联盟开始游说社区使用 UAS 机制取代 TPR,并且建议直接从 Kubernetes 项目里废弃 TPR 这个功能。一时间,社区里谣言四起,不少已经通过 TPR 实现的项目,也开始转而使用 UAS 来重构以求自保。 而 Operator 这个严重依赖于 TPR 的小项目,还没来得及发展壮大,就被推向了关闭的边缘。
面对几乎要与社区背道而驰的困境,CoreOS 公司的 CTO Brandon Philips 做出了一个大胆的决定:让社区里的所有开发者发声,挽救 TPR 和 Operator。
2017 年 2月,Brandon Philips 在 GitHub 上开了一个帖子(Gist), 号召所有使用 TPR 或者 Operator 项目的开发者在这里留下的自己的项目链接或者描述。这个帖子,迅速的成为了当年容器技术圈最热门的事件之一,登上了 HackerNews 的头条。有趣的是,这个帖子直到今天也仍然健在,甚至还在被更新,你可以点击这个链接去感受一下当时的盛况。https://gist.github.com/philips/a97a143546c87b86b870a82a753db14c
而伴随着 Kubernetes 项目的迅速崛起,短短一年时间不到,夹缝中求生存的 Operator 项目,开始对公有云市场产生了不可逆转的影响,也逐步改变了开发者们对“云”以及云上应用开发模式的基本认知。甚至就连 Google Cloud 自己最大的客户之一 Snapchat ,也成为了 Operator 项目的忠实用户。在来自社区的巨大压力下,在这个由成千上万开发者们自发维护起来的 Operator 生态面前,Google 和 RedHat 公司最终选择了反省和退让。
有意思的是,这个退让的结果,再一次为这次闹剧增添了几分戏剧性。
就在 Brandon Phillips 的开发者搜集帖发布了不到三个月后,RedHat 和 Google 公司的工程师突然在 Kubernetes 社区里宣布:TPR 即将被废弃,取而代之的是一个名叫 CRD,Custom Resource Definition 的东西。
于是,开发者们开始忧心忡忡的按照文档,将原本使用 TPR 的代码都升级成 CRD。而就在这时,他们却惊奇的发现,这两种机制除了名字之外,好像并没有任何不同。所谓的升级工作,其实就是将代码里的 TPR 字样全局替换成 CRD 而已。
难道,这只是虚惊一场?
其实,很少有人注意到,在 TPR 被替换成 CRD 之后,Brendan Burns 和微软团队就再也没有出现在“自定义 API”这个至关重要的领域里了。而 CRD 现在的负责人,都是来自 Google 和 RedHat 的工程师。
在这次升级事件之后不久,CoreOS 公司在它的官方网站上发布了一篇叫做:TPR Is Dead! Kubernetes 1.7 Turns to CRD 的博客(https://coreos.com/blog/custom-resource-kubernetes-v17),旨在指导用户从 TRP 升级成 CRD。不过,现在回头再看一眼这篇文章,平淡无奇的讲述背后,你能否感受到当年这场“开发者战争”的蛛丝马迹呢?
其实,Operator 并不平坦的晋级之路,只是 Kubernetes API 生态风起云涌的冰山一角。几乎在每个星期,甚至每一天,都有太多围绕着 Kubernetes 开发者生态的角逐,在这个无比繁荣的社区背后,以不为人知的方式开始或者谢幕。
而这一切纷争的根本原因却无比直白。Kubernetes 项目,已经被广泛认可为云计算时代应用开发者们的终端入口。这正是为何,无论是 Google、微软,还是 CoreOS 以及 Heptio,所有这个生态里的大小玩家,都在不遗余力的在 Kubernetes API 层上捍卫着自己的话语权,以期在这个未来云时代的开发者入口上,争取到自己的一席之地。
而在完成了对收 CoreOS 的收购之后,RedHat 终于在这一领域拿到了可以跟 Google 和微软一较高低的关键位置。2018年,RedHat 不失时机的发布了 Operator Framework,希望通过 Operator 周边工具和生态的进一步完善,把 Operator 确立成为分布式应用开发与管理的关键依赖。而伴随着 Operator 越来越多的介入到应用开发和部署流程之后, Kubernetes API 一定会继续向上演进,进一步影响开发者的认知和编程习惯。这,已经成为了云计算生态继续发展下去的必然趋势。
而作为这个趋势坚定不移的贯彻者,无论是 Istio,还是 Knative,都在用同样的经历告诉我们这样的道理:只有构建在 Kubernetes 这个云时代基础设施事实标准上的开发者工具,才有可能成为下一个开发者领域的 “Operator” 。
亲历者说:Kubernetes API 与 Operator,不为人知的开发者战争的更多相关文章
- 第24 章 : Kubernetes API 编程利器:Operator 和 Operator Framework
Kubernetes API 编程利器:Operator 和 Operator Framework 本节课程主要分享以下三方面的内容: operator 概述 operator framework 实 ...
- kubernetes之监控Operator部署Prometheus(三)
第一章和第二章中我们配置Prometheus的成本非常高,而且也非常麻烦.但是我们要考虑Prometheus.AlertManager 这些组件服务本身的高可用的话,成本就更高了,当然我们也完全可以用 ...
- 资深专家深度剖析Kubernetes API Server第2章(共3章)
欢迎来到深入学习Kubernetes API Server的系列文章的第二部分.在上一部分中我们对APIserver总体,相关术语及request请求流进行探讨说明.在本部分文章中,我们主要聚焦于探究 ...
- 资深专家深度剖析Kubernetes API Server第1章(共3章)
欢迎来到深入学习Kubernetes API Server的系列文章,在本系列文章中我们将深入的探究Kubernetes API Server的相关实现.如果你对Kubernetes的内部实现机制比较 ...
- 深度剖析Kubernetes API Server三部曲 - part 2
欢迎来到深入学习Kubernetes API Server的系列文章的第二部分.在上一部分中我们对APIserver总体,相关术语及request请求流进行探讨说明.在本部分文章中,我们主要聚焦于探究 ...
- 深度剖析Kubernetes API Server三部曲 - part 1
欢迎来到深入学习Kubernetes API Server的系列文章,在本系列文章中我们将深入的探究Kubernetes API Server的相关实现.如果你对Kubernetes 的内部实现机制比 ...
- Centos7部署kubernetes API服务(四)
1.准备软件包 [root@linux-node1 bin]# pwd /usr/local/src/kubernetes/server/bin [root@linux-node1 bin]# cp ...
- Gravitational Teleport 开源的通过ssh && kubernetes api 管理linux 服务器集群的网关
Gravitational Teleport 是一个开源的通过ssh && kubernetes api 管理linux 服务器集群的网关 支持以下功能: 基于证书的身份认证 ssh ...
- kubernetes API Server 权限管理实践
API Server权限控制方式介绍 API Server权限控制分为三种:Authentication(身份认证).Authorization(授权).AdmissionControl(准入控制). ...
随机推荐
- 1、linux常用命令的英文单词缩写
1.linux常用命令的英文单词缩写 命令缩写: ls:list(列出目录内容) cd:Change Directory(改变目录) su:switch user 切换用户 rpm:redhat pa ...
- ICPC 2018 焦作区域赛
// 2019.10.7 练习赛 // 赛题来源:2018 ICPC 焦作区域赛 // CF链接:http://codeforces.com/gym/102028 A Xu Xiake in Hena ...
- scrt 关闭退格键声音
options-> session Options -> Terminal -> audio bell (删除勾选) 这样就可以在secureCRT 在出错时不‘滴滴’的响了.
- spring MVC 全局的异常处理
1.使用SimpleMappingExceptionResolver实现异常处理 在Spring的配置文件applicationContext.xml中增加以下内容: <bean class=& ...
- C 删除字符串中某个指定的字符
#include <stdio.h> char *del_char(char *str, char ch) { unsigned char i=0,j=0; while(str[i] != ...
- 用Jquery写返回顶部代码
<!DOCTYPE html><html><head><meta charset="utf-8" /><title>jq ...
- java8--Stream的flatmap与map异同的理解
大纲: 异同点 示例 一.异同点 他们的相同点是接收的入参都是一个function. 不同点这个入参function的返回不同.map返回一个对象,flatmap返回一个stream. 这就使得map ...
- 校园商铺-2Logback配置与使用-3验证配置
1. 验证logback配置 1.1. 启动tomcat,得到CATALINA_BASE地址: 1.2 访问接口,查看日志 浏览器打开http://localhost:18080/o2o/supera ...
- NPM一Node包管理和分发工具
NPM 全称 Node Package Manager Node包管理和分发工具,可以把NPM理解为前端的Maven 我们通过npm可以很方便地下载js库,管理前端工程 最近版本的node.js已经集 ...
- 微服务配置中心实战:Spring + MyBatis + Druid + Nacos
在结合场景谈服务发现和配置中我们讲述了 Nacos 配置中心的三个典型的应用场景,包括如何在 Spring Boot 中使用 Nacos 配置中心将数据库连接信息管控起来,而在“原生”的 Spring ...