zookeeper 源码(一) 选举和同步数据
前言
在开始阅读代码前我们先来了解一下zk 的大致结构,具体大概要实现的核心功能有那些,心中有个大概的框架阅读代码时再深入其中的细节,就会非常好懂,本人觉得这是一个阅读源码的好方法,可以最快地切入到源码中,先知大体,后知细节。
我们先不考虑权限控制的问题,zk底层使用 zab ,是一种分布式一致性协议,服务的对象是客户端,需要做持久化,根据这些我们可以大致做出以下功能视图。
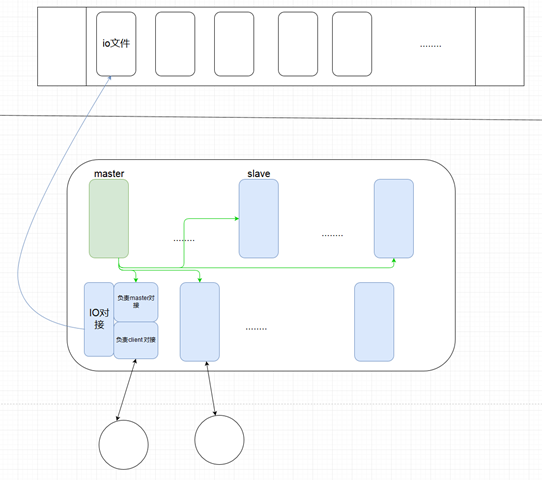
更加细化 zk 底层细节可以从这几个方面学习 :
- master 与 peer , peer 与 peer 之间的消息通信
- Fast Election 过程
- 同步过程
- 执行事务过程
- 客户端连接,服务端如何执行任务,session 管理
- 信息持久化和通信协议
上面的几点都是我们学习的目标,我们通过在阅读代码中进行总结。
配置文件
单机模式 zoo.cfg 示例
tickTime=2000 dataDir=/usr/zdatadir dataLogDir=/usr/zlogdir clientPort=2181 initLimit=5 syncLimit=2 集群模式 zoo.cfg 示例 tickTime=2000 dataDir=/usr/zdatadir dataLogDir=/usr/zlogdir clientPort=2181 initLimit=5 syncLimit=2 server.1=cloud:2888:3888 server.2=cloud02:2888:3888 server.3=cloud03:2888:3888 server.4=cloud04:2888:3888 server.5=cloud05:2888:3888
源码解读
集群模式概述
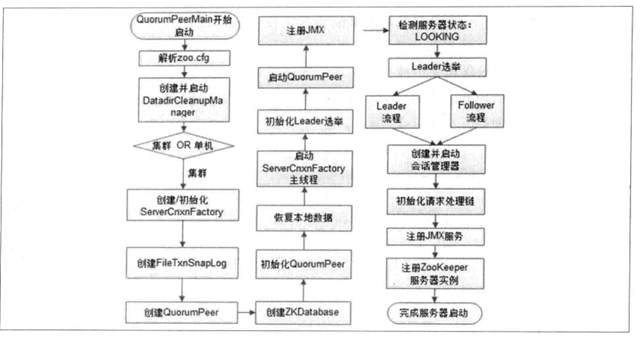
我安装window版本的 zk, 通过查看 startup.cmd ,我们直接看 QuorumPeerMain 这个类 ,该类内部持有一个 protected QuorumPeer quorumPeer的字段。
/**
* To start the replicated server specify the configuration file name on
* the command line.
* @param args path to the configfile
*
* 做了两件事 :
* - 加载配置
* - 开始监听(listen),开始选举 (send)
*/
public static void main(String[] args) {
args = new String[1];
args[0] = "D:\\java_project_out\\zk\\zkben\\cofig\\zoo_sample.cfg";
QuorumPeerMain main = new QuorumPeerMain();
try {
//重点执行逻辑
main.initializeAndRun(args);
} catch (IllegalArgumentException e) {
LOG.error("Invalid arguments, exiting abnormally", e);
LOG.info(USAGE);
System.err.println(USAGE);
System.exit(2);
} catch (ConfigException e) {
LOG.error("Invalid config, exiting abnormally", e);
System.err.println("Invalid config, exiting abnormally");
System.exit(2);
} catch (Exception e) {
LOG.error("Unexpected exception, exiting abnormally", e);
System.exit(1);
}
LOG.info("Exiting normally");
System.exit(0);
} /**
* 可以看到当 config.servers.size() > 1 的时候就是集群版本
*/
protected void initializeAndRun(String[] args)
throws ConfigException, IOException
{
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]);
} // Start and schedule the the purge task
// 启动一个定时器,用于清理过期日志
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start(); //判断参数
if (args.length == 1 && config.servers.size() > 0) {
//集群模式,看方法名就可以知道应该会根据配置执行某些操作
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
ZooKeeperServerMain.main(args);
}
}
接着看 runfromConfig 这个方法 。
public void runFromConfig(QuorumPeerConfig config) throws IOException {
try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer");
try {
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
//创建这样一个对象
quorumPeer = getQuorumPeer();
quorumPeer.setQuorumPeers(config.getServers());
//读写文件相关(log)
quorumPeer.setTxnFactory(new FileTxnSnapLog(
new File(config.getDataLogDir()),
new File(config.getDataDir())));
//各种参数
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setQuorumVerifier(config.getQuorumVerifier());
quorumPeer.setClientPortAddress(config.getClientPortAddress());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
// ZKDatabase 是数据加载内存的体现 (data in memory )
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
// sets quorum sasl authentication configurations
quorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);
if(quorumPeer.isQuorumSaslAuthEnabled()){
quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);
quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);
quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);
quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);
quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);
}
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
我们看到这个方法就是为 QuorumPeer quorumPeer 这个字段设置了属性,然后调用 start 方法,那么真正执行就到 QuorumPeer这个类中了。
既然 QuorumPeer 继承了 Thread 了,那么start 方法实际就是调用它的 run 方法 。
@Override
public void run() {
setName("QuorumPeer" + "[myid=" + getId() + "]" +
cnxnFactory.getLocalAddress()); LOG.debug("Starting quorum peer");
try {
jmxQuorumBean = new QuorumBean(this);
MBeanRegistry.getInstance().register(jmxQuorumBean, null);
for (QuorumServer s : getView().values()) {
ZKMBeanInfo p;
if (getId() == s.id) {
p = jmxLocalPeerBean = new LocalPeerBean(this);
try {
MBeanRegistry.getInstance().register(p, jmxQuorumBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxLocalPeerBean = null;
}
} else {
p = new RemotePeerBean(s);
try {
MBeanRegistry.getInstance().register(p, jmxQuorumBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
}
}
}
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxQuorumBean = null;
} //发送请求
try {
/*
* Main loop 主循环一直进行
*/
while (running) {
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING"); if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer"); // Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(
logFactory, this,
new ZooKeeperServer.BasicDataTreeBuilder(),
this.zkDb); // Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
//
//一个线程被使用到这里,不然的话它将随着每一个选举策略而改变,这将产生不必要的代码连接
//
//
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
//监听来自客户端的请求,notify ,同时开始选举了
try {
roZkMgr.start();
setBCVote(null);
//选举的逻辑,经过了选举,ServerStatue 一定会改变状态,有可能是 Leading 或是其他
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
setBCVote(null);
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
observer.shutdown();
setObserver(null);
setPeerState(ServerState.LOOKING);
}
break;
case FOLLOWING:
try {
//假如自己变成了一名跟随者,那么更新属性
//进入一个 while 循环等待命令
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
//正常请求进入这个方法就一直while 出不来
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
//出来了关闭,设置状态
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
}
}
} finally {
LOG.warn("QuorumPeer main thread exited");
try {
MBeanRegistry.getInstance().unregisterAll();
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
jmxQuorumBean = null;
jmxLocalPeerBean = null;
}
}
ReadOnlyZooKeeperServer 的 startup 方法,此处会调用父类 startup 方法。
@Override
public synchronized void startup() {
// check to avoid startup follows shutdown
if (shutdown) {
LOG.warn("Not starting Read-only server as startup follows shutdown!");
return;
}
registerJMX(new ReadOnlyBean(this), self.jmxLocalPeerBean);
super.startup();
self.cnxnFactory.setZooKeeperServer(this);
LOG.info("Read-only server started");
} 父类 ZookeeperServer startup 方法
/**
* - 开始 session 监听
* - 启动处理请求处理器
* - 注册到 JMX
* - 更改状态
*/
public synchronized void startup() {
if (sessionTracker == null) {
createSessionTracker();
}
//wait 在这里面调用
startSessionTracker();
//处理器链,使用责任链设计模式
setupRequestProcessors(); registerJMX(); setState(State.RUNNING);
//为什么这时候要 notifyAll(),因为只有启动完成后才可以处理来自客户端的请求
notifyAll();
}
选举操作
回到QuorumPeer 的 run 方法,在while内部,开始选举操作,具体就是 lookForLeader方法。
public Vote lookForLeader() throws InterruptedException {
try {
self.jmxLeaderElectionBean = new LeaderElectionBean();
MBeanRegistry.getInstance().register(
self.jmxLeaderElectionBean, self.jmxLocalPeerBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
self.jmxLeaderElectionBean = null;
}
if (self.start_fle == 0) {
self.start_fle = Time.currentElapsedTime();
}
try {
//收到的某个服务器的 vote, <发送者的地址,对应的退票>
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
//已经结束的选举
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
synchronized (this) {
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
//初始化发送自身的 vote 让别人来为你 投票
LOG.info("New election. My id = " + self.getId() +
", proposed zxid=0x" + Long.toHexString(proposedZxid));
sendNotifications();
/*
* Loop in which we exchange notifications until we find a leader
*
* 循环知道我们找到 leader
*
*/
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)) {
/*
* Remove next notification from queue, times out after 2 times
* the termination time
*/
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
/*
* Sends more notifications if haven't received enough.
* Otherwise processes new notification.
*
* 如果收到的信息不够多,发多点,否则处理一个新的信息
*/
if (n == null) {
if (manager.haveDelivered()) {
sendNotifications();
} else {
manager.connectAll();
}
/*
* Exponential backoff
*/
int tmpTimeOut = notTimeout * 2;
notTimeout = (tmpTimeOut < maxNotificationInterval ?
tmpTimeOut : maxNotificationInterval);
LOG.info("Notification time out: " + notTimeout);
} else if (validVoter(n.sid) && validVoter(n.leader)) {
/*
* Only proceed if the vote comes from a replica in the
* voting view for a replica in the voting view.
*
*/
switch (n.state) {
case LOOKING:
// If notification > current, replace and send messages out
// 如果收到的也是 LOOKING 的信息,比较后,假如比“我”新,则继续 sendNotifation
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
// 收到比自己新的,之前收到的选票都扔掉了
recvset.clear();
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
if (LOG.isDebugEnabled()) {
LOG.debug("Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x"
+ Long.toHexString(n.electionEpoch)
+ ", logicalclock=0x" + Long.toHexString(logicalclock.get()));
}
break;
// n.electionEpoch == logicalclock.get()
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
if (LOG.isDebugEnabled()) {
LOG.debug("Adding vote: from=" + n.sid +
", proposed leader=" + n.leader +
", proposed zxid=0x" + Long.toHexString(n.zxid) +
", proposed election epoch=0x" + Long.toHexString(n.electionEpoch));
}
// notif 大于或是等于自己的,才会走到这一步,有可能收到好几个 epoch 都是一样的,那么 recvset 里面就会放进多个vote
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//是否应该停止选举了:停止选举,肯定是收到了大部分的选票
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
// 接收的信息中刚好有一条是这条vote 的最新消息,更新后再次放在接收的消息里
while ((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new
* relevant message from the reception queue
*/
if (n == null) {
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING : learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid,
logicalclock.get(),
proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
LOG.debug("Notification from observer: " + n.sid);
break;
case FOLLOWING:
case LEADING:
/*
* Consider all notifications from the same epoch
* together.
*
* 假如收到一个 LEADING 的信号,那必须比自身的数据大才可以啊,然后 ack 回 leader
*
*/
if (n.electionEpoch == logicalclock.get()) {
recvset.put(n.sid, new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch));
if (ooePredicate(recvset, outofelection, n)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING : learningState());
Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
/*
* Before joining an established ensemble, verify
* a majority is following the same leader.
*/
outofelection.put(n.sid, new Vote(n.version,
n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch,
n.state));
if (ooePredicate(outofelection, outofelection, n)) {
synchronized (this) {
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING : learningState());
}
Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
LOG.warn("Notification state unrecognized: {} (n.state), {} (n.sid)",
n.state, n.sid);
break;
}
} else {
if (!validVoter(n.leader)) {
LOG.warn("Ignoring notification for non-cluster member sid {} from sid {}", n.leader, n.sid);
}
if (!validVoter(n.sid)) {
LOG.warn("Ignoring notification for sid {} from non-quorum member sid {}", n.leader, n.sid);
}
}
}
return null;
} finally {
try {
if (self.jmxLeaderElectionBean != null) {
MBeanRegistry.getInstance().unregister(
self.jmxLeaderElectionBean);
}
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
self.jmxLeaderElectionBean = null;
LOG.debug("Number of connection processing threads: {}",
manager.getConnectionThreadCount());
}
}
可以看到要离开 lookforleader 循环有一个条件就是自身的状态不为 LOOKING ,就是说在 while 循环里面肯定会改变自身的状态,或者说确定自己的身份。
其中
/**
* Check if a pair (server id, zxid) succeeds our
* current vote.
* 该方法决定是否要更新自身所持有的选票信息
* @param id Server identifier
* @param zxid Last zxid observed by the issuer of this vote
*/
protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch) {
LOG.debug("id: " + newId + ", proposed id: " + curId + ", zxid: 0x" +
Long.toHexString(newZxid) + ", proposed zxid: 0x" + Long.toHexString(curZxid));
if (self.getQuorumVerifier().getWeight(newId) == 0) {
return false;
} /*
* We return true if one of the following three cases hold:
* 1- New epoch is higher
* 2- New epoch is the same as current epoch, but new zxid is higher
* 3- New epoch is the same as current epoch, new zxid is the same
* as current zxid, but server id is higher.
*/ return ((newEpoch > curEpoch) ||
((newEpoch == curEpoch) &&
((newZxid > curZxid) || ((newZxid == curZxid) && (newId > curId)))));
} /**
* Termination predicate. Given a set of votes, determines if
* have predicate to declare the end of the election round.
*
* @param votes Set of votes <服务器id,选票></>
* @param l Identifier of the vote received last
* @param zxid zxid of the the vote received last
*
* 该函数用于判断Leader选举是否结束,即是否有一半以上的服务器选出了相同的Leader,
* 其过程是将收到的选票与当前选票进行对比,选票相同的放入同一个集合,之后判断选票相同的集合是否超过了半数。
*/
protected boolean termPredicate(
HashMap<Long, Vote> votes,
Vote vote) { //同一个vote对应的服务器
HashSet<Long> set = new HashSet<Long>(); /*
* First make the views consistent. Sometimes peers will have
* different zxids for a server depending on timing.
*/
for (Map.Entry<Long, Vote> entry : votes.entrySet()) {
if (vote.equals(entry.getValue())) {
set.add(entry.getKey());
}
} return self.getQuorumVerifier().containsQuorum(set);
}
上面基本上就可以知道了选举的过程,还有一个地方需要注意的是我们的选票是没有做持久化的,原因也很好理解,要是选举过程中有 peer 挂了,那么重新启动继续参与选举就行了,或是参与成为 follower 就行了。那么假如此时,某个 peer 已经选定了 leader ,那么它的状态就不为 LOOKING , 假如它成为了一个 follower ,那么我们回到QuorumPeer 的run方法,进入 FOLLOWING 的执行逻辑。
//假设经过 lookforleading 后,该服务器变成了 following
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
成为leader 或是成为 follower
上一节结束了选举的过程,接下来就是向leader注册 follower ,与 follower同步数据的过程。可以看到 FOLLOWING 和 LEADING 的执行逻辑很像,都是创建一个角色(创建一个leader 或是 一个follower ),我们先来看一下follower 的执行逻辑,执行 followerLeading 方法。

/**
* the main method called by the follower to follow the leader
*
* 注意 : 里面有个 while 循环一直等待leader 的请求
*
* 主要做了几件事 :
* - 查找 leader
* - 连接 leader
* - 握手协议(重点),方便后面同步数据
* - 同步leader数据
* - while 循环等待处理来自leader 或其他peer的请求
*
* @throws InterruptedException
*/
void followLeader() throws InterruptedException {
self.end_fle = Time.currentElapsedTime();
long electionTimeTaken = self.end_fle - self.start_fle;
self.setElectionTimeTaken(electionTimeTaken);
LOG.info("FOLLOWING - LEADER ELECTION TOOK - {}", electionTimeTaken);
self.start_fle = 0;
self.end_fle = 0;
fzk.registerJMX(new FollowerBean(this, zk), self.jmxLocalPeerBean);
try {
QuorumServer leaderServer = findLeader();
try {
connectToLeader(leaderServer.addr, leaderServer.hostname);
//
long newEpochZxid = registerWithLeader(Leader.FOLLOWERINFO); //check to see if the leader zxid is lower than ours
//this should never happen but is just a safety check
long newEpoch = ZxidUtils.getEpochFromZxid(newEpochZxid);
if (newEpoch < self.getAcceptedEpoch()) {
LOG.error("Proposed leader epoch " + ZxidUtils.zxidToString(newEpochZxid)
+ " is less than our accepted epoch " + ZxidUtils.zxidToString(self.getAcceptedEpoch()));
throw new IOException("Error: Epoch of leader is lower");
}
syncWithLeader(newEpochZxid);
QuorumPacket qp = new QuorumPacket();
while (this.isRunning()) {
readPacket(qp);
processPacket(qp);
}
} catch (Exception e) {
LOG.warn("Exception when following the leader", e);
try {
sock.close();
} catch (IOException e1) {
e1.printStackTrace();
} // clear pending revalidations
pendingRevalidations.clear();
}
} finally {
zk.unregisterJMX((Learner)this);
}
}
选举完后就是 leader 和 follower 之间的信息交互了,如下图
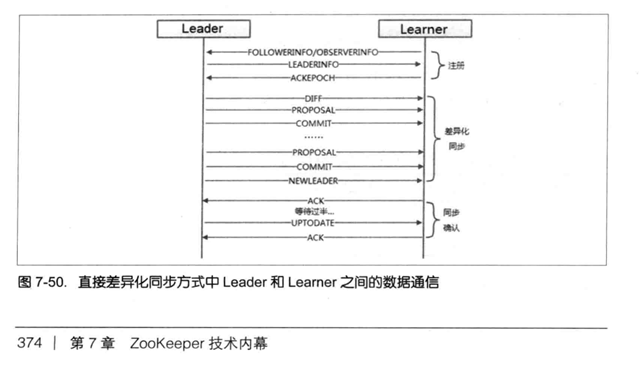
先看一下 registerWithLeader 方法
读到了这里注册到leader 的逻辑,主要要了解的有两个方面 :
- follower 给 leader 传了什么东西
- 用什么方式传的
先说第二个问题,发送的消息使用了 jute 进行了(发送方)序列化和(接收方)反序列化。jute 基本的使用如下 :
以下两张图片来自《从Paxos到Zookeeper 分布式一致性原理与实践》一书


第一个问题,follower给 leader 传了已接受的 epoch 和 sid 过去。 现在看一下 leader 如何处理这些信息。 leader 处理的逻辑交给了 LeaderHander 这个类来处理。
看 LeaderHander 这里类之前我们先来看两个重要的字段 :
- toBeApplied : 是一个已经得到大部分同意,但是没有被每个peer commit 的请求
- outstandingProposals : 还没有得到大部分同意的请求。当zk服务器接收到客户端的请求的使用首先会放到 outstandingProposals 中,当得到大部分 peer 的 同意的时候,就会从 outstandingProposals 删除,然后放在 toBeApplied 中。
leader 的 lead 方法 。
/**
* This method is main function that is called to lead
*
* - 开启 LearnerCnxAcceptor,用于处理来自followers 的连接
* - 启动 LeaderZooKeeperServer
* - 之后 while 循环 ping followers
*
*
* @throws IOException
* @throws InterruptedException
*/
void lead() throws IOException, InterruptedException {
self.end_fle = Time.currentElapsedTime();
long electionTimeTaken = self.end_fle - self.start_fle;
self.setElectionTimeTaken(electionTimeTaken);
LOG.info("LEADING - LEADER ELECTION TOOK - {}", electionTimeTaken);
self.start_fle = 0;
self.end_fle = 0; zk.registerJMX(new LeaderBean(this, zk), self.jmxLocalPeerBean); try {
self.tick.set(0);
zk.loadData(); leaderStateSummary = new StateSummary(self.getCurrentEpoch(), zk.getLastProcessedZxid()); // Start thread that waits for connection requests from
// new followers.
// 开线程等待来自follower的连接
cnxAcceptor = new LearnerCnxAcceptor();
cnxAcceptor.start(); readyToStart = true;
long epoch = getEpochToPropose(self.getId(), self.getAcceptedEpoch()); zk.setZxid(ZxidUtils.makeZxid(epoch, 0)); //这里加锁
synchronized(this){
lastProposed = zk.getZxid();
}
// NEWLEADER 消息
newLeaderProposal.packet = new QuorumPacket(NEWLEADER, zk.getZxid(),
null, null); if ((newLeaderProposal.packet.getZxid() & 0xffffffffL) != 0) {
LOG.info("NEWLEADER proposal has Zxid of "
+ Long.toHexString(newLeaderProposal.packet.getZxid()));
} waitForEpochAck(self.getId(), leaderStateSummary);
self.setCurrentEpoch(epoch); // We have to get at least a majority of servers in sync with
// us. We do this by waiting for the NEWLEADER packet to get
// acknowledged
try {
waitForNewLeaderAck(self.getId(), zk.getZxid());
} catch (InterruptedException e) {
shutdown("Waiting for a quorum of followers, only synced with sids: [ "
+ getSidSetString(newLeaderProposal.ackSet) + " ]");
HashSet<Long> followerSet = new HashSet<Long>();
for (LearnerHandler f : learners)
followerSet.add(f.getSid()); if (self.getQuorumVerifier().containsQuorum(followerSet)) {
LOG.warn("Enough followers present. "
+ "Perhaps the initTicks need to be increased.");
}
Thread.sleep(self.tickTime);
self.tick.incrementAndGet();
return;
} //leader中持有一个 LeaderZooKeeperServer ,这里将会启动 LeaderZooKeeperServer
startZkServer(); /**
* WARNING: do not use this for anything other than QA testing
* on a real cluster. Specifically to enable verification that quorum
* can handle the lower 32bit roll-over issue identified in
* ZOOKEEPER-1277. Without this option it would take a very long
* time (on order of a month say) to see the 4 billion writes
* necessary to cause the roll-over to occur.
*
* This field allows you to override the zxid of the server. Typically
* you'll want to set it to something like 0xfffffff0 and then
* start the quorum, run some operations and see the re-election.
*/
String initialZxid = System.getProperty("zookeeper.testingonly.initialZxid");
if (initialZxid != null) {
long zxid = Long.parseLong(initialZxid);
zk.setZxid((zk.getZxid() & 0xffffffff00000000L) | zxid);
} if (!System.getProperty("zookeeper.leaderServes", "yes").equals("no")) {
self.cnxnFactory.setZooKeeperServer(zk);
}
// Everything is a go, simply start counting the ticks
// WARNING: I couldn't find any wait statement on a synchronized
// block that would be notified by this notifyAll() call, so
// I commented it out
//synchronized (this) {
// notifyAll();
//}
// We ping twice a tick, so we only update the tick every other
// iteration
boolean tickSkip = true; while (true) {
Thread.sleep(self.tickTime / 2);
if (!tickSkip) {
self.tick.incrementAndGet();
}
HashSet<Long> syncedSet = new HashSet<Long>(); // lock on the followers when we use it.
syncedSet.add(self.getId()); for (LearnerHandler f : getLearners()) {
// Synced set is used to check we have a supporting quorum, so only
// PARTICIPANT, not OBSERVER, learners should be used
if (f.synced() && f.getLearnerType() == LearnerType.PARTICIPANT) {
syncedSet.add(f.getSid());
}
f.ping();
} // check leader running status
if (!this.isRunning()) {
shutdown("Unexpected internal error");
return;
} if (!tickSkip && !self.getQuorumVerifier().containsQuorum(syncedSet)) {
//if (!tickSkip && syncedCount < self.quorumPeers.size() / 2) {
// Lost quorum, shutdown
shutdown("Not sufficient followers synced, only synced with sids: [ "
+ getSidSetString(syncedSet) + " ]");
// make sure the order is the same!
// the leader goes to looking
return;
}
tickSkip = !tickSkip;
}
} finally {
zk.unregisterJMX(this);
}
}
先来看一下 LearnerCnxAcceptor。
class LearnerCnxAcceptor extends ZooKeeperThread{
private volatile boolean stop = false;
public LearnerCnxAcceptor() {
super("LearnerCnxAcceptor-" + ss.getLocalSocketAddress());
}
@Override
public void run() {
try {
while (!stop) {
try{
// accept 方法一直都会阻塞在这里,每连接一个创建一个LearnerHandler(LH是线程的子类,内部处理follower等的消息)
Socket s = ss.accept();
// start with the initLimit, once the ack is processed
// in LearnerHandler switch to the syncLimit
s.setSoTimeout(self.tickTime * self.initLimit);
s.setTcpNoDelay(nodelay);
BufferedInputStream is = new BufferedInputStream(
s.getInputStream());
LearnerHandler fh = new LearnerHandler(s, is, Leader.this);
fh.start();
} catch (SocketException e) {
if (stop) {
LOG.info("exception while shutting down acceptor: "
+ e);
// When Leader.shutdown() calls ss.close(),
// the call to accept throws an exception.
// We catch and set stop to true.
stop = true;
} else {
throw e;
}
} catch (SaslException e){
LOG.error("Exception while connecting to quorum learner", e);
}
}
} catch (Exception e) {
LOG.warn("Exception while accepting follower", e);
}
}
public void halt() {
stop = true;
}
}
看一次 LeaderHandler 的处理逻辑 :
/**
* This thread will receive packets from the peer and process them and
* also listen to new connections from new peers.
*/
@Override
public void run() {
try {
leader.addLearnerHandler(this);
tickOfNextAckDeadline = leader.self.tick.get()
+ leader.self.initLimit + leader.self.syncLimit;
ia = BinaryInputArchive.getArchive(bufferedInput);
bufferedOutput = new BufferedOutputStream(sock.getOutputStream());
oa = BinaryOutputArchive.getArchive(bufferedOutput);
QuorumPacket qp = new QuorumPacket();
ia.readRecord(qp, "packet");
//第一个请求不是 FOLLOWERINFO 或是 OBSERVERINFO 直接就返回了
if(qp.getType() != Leader.FOLLOWERINFO && qp.getType() != Leader.OBSERVERINFO){
LOG.error("First packet " + qp.toString()
+ " is not FOLLOWERINFO or OBSERVERINFO!");
return;
}
byte learnerInfoData[] = qp.getData();
if (learnerInfoData != null) {
if (learnerInfoData.length == 8) {
ByteBuffer bbsid = ByteBuffer.wrap(learnerInfoData);
this.sid = bbsid.getLong();
} else {
LearnerInfo li = new LearnerInfo();
ByteBufferInputStream.byteBuffer2Record(ByteBuffer.wrap(learnerInfoData), li);
this.sid = li.getServerid();
this.version = li.getProtocolVersion();
}
} else {
this.sid = leader.followerCounter.getAndDecrement();
}
LOG.info("Follower sid: " + sid + " : info : "
+ leader.self.quorumPeers.get(sid));
if (qp.getType() == Leader.OBSERVERINFO) {
learnerType = LearnerType.OBSERVER;
}
// following 发来的 zxid
long lastAcceptedEpoch = ZxidUtils.getEpochFromZxid(qp.getZxid());
long peerLastZxid;
StateSummary ss = null;
long zxid = qp.getZxid();
// 有阻塞操作,直到收到大多数 peer 的 FollowerInfo
long newEpoch = leader.getEpochToPropose(this.getSid(), lastAcceptedEpoch);
//到了这里,说明已经有大多数 follower 连接到该leader
if (this.getVersion() < 0x10000) {
// we are going to have to extrapolate the epoch information
long epoch = ZxidUtils.getEpochFromZxid(zxid);
ss = new StateSummary(epoch, zxid);
// fake the message
leader.waitForEpochAck(this.getSid(), ss);
} else {
byte ver[] = new byte[4];
ByteBuffer.wrap(ver).putInt(0x10000);
//发送一个新的 newEpoch 要求 peer更新, 回应刚才 follower 发来的 FOLLOWERINFO
QuorumPacket newEpochPacket = new QuorumPacket(Leader.LEADERINFO, ZxidUtils.makeZxid(newEpoch, 0), ver, null);
oa.writeRecord(newEpochPacket, "packet");
bufferedOutput.flush();
QuorumPacket ackEpochPacket = new QuorumPacket();
ia.readRecord(ackEpochPacket, "packet");
if (ackEpochPacket.getType() != Leader.ACKEPOCH) {
LOG.error(ackEpochPacket.toString()
+ " is not ACKEPOCH");
return;
}
ByteBuffer bbepoch = ByteBuffer.wrap(ackEpochPacket.getData());
//leader 保存 follower 收到的当前的 epoch 和最后一个接收的 zxid
ss = new StateSummary(bbepoch.getInt(), ackEpochPacket.getZxid());
// 有阻塞操作,等待大多数的 follower 的响应 ACKEPOTH
leader.waitForEpochAck(this.getSid(), ss);
}
//这里就结束了选举的所有流程,接下来就是同步操作了
//---------------------------------------------------------------
//同步操作开始
peerLastZxid = ss.getLastZxid();
/* the default to send to the follower */
int packetToSend = Leader.SNAP;
long zxidToSend = 0;
long leaderLastZxid = 0;
/** the packets that the follower needs to get updates from **/
long updates = peerLastZxid;
/* we are sending the diff check if we have proposals in memory to be able to
* send a diff to the
*/
ReentrantReadWriteLock lock = leader.zk.getZKDatabase().getLogLock(); //同步读写锁
ReadLock rl = lock.readLock();
try {
rl.lock();
final long maxCommittedLog = leader.zk.getZKDatabase().getmaxCommittedLog();
final long minCommittedLog = leader.zk.getZKDatabase().getminCommittedLog();
LOG.info("Synchronizing with Follower sid: " + sid
+" maxCommittedLog=0x"+Long.toHexString(maxCommittedLog)
+" minCommittedLog=0x"+Long.toHexString(minCommittedLog)
+" peerLastZxid=0x"+Long.toHexString(peerLastZxid));
LinkedList<Proposal> proposals = leader.zk.getZKDatabase().getCommittedLog();
if (peerLastZxid == leader.zk.getZKDatabase().getDataTreeLastProcessedZxid()) {
// Follower is already sync with us, send empty diff
LOG.info("leader and follower are in sync, zxid=0x{}",
Long.toHexString(peerLastZxid));
packetToSend = Leader.DIFF;
zxidToSend = peerLastZxid;
} else if (proposals.size() != 0) {
LOG.debug("proposal size is {}", proposals.size());
if ((maxCommittedLog >= peerLastZxid)
&& (minCommittedLog <= peerLastZxid)) {
LOG.debug("Sending proposals to follower");
// as we look through proposals, this variable keeps track of previous
// proposal Id.
long prevProposalZxid = minCommittedLog;
// Keep track of whether we are about to send the first packet.
// Before sending the first packet, we have to tell the learner
// whether to expect a trunc or a diff
boolean firstPacket=true;
// If we are here, we can use committedLog to sync with
// follower. Then we only need to decide whether to
// send trunc or not
packetToSend = Leader.DIFF;
zxidToSend = maxCommittedLog;
for (Proposal propose: proposals) {
// skip the proposals the peer already has
if (propose.packet.getZxid() <= peerLastZxid) {
prevProposalZxid = propose.packet.getZxid();
continue;
} else {
// If we are sending the first packet, figure out whether to trunc
// in case the follower has some proposals that the leader doesn't
if (firstPacket) {
firstPacket = false;
// Does the peer have some proposals that the leader hasn't seen yet
// peer 有些提案是我们没有的,直接替换成 leader的
if (prevProposalZxid < peerLastZxid) {
// send a trunc message before sending the diff
packetToSend = Leader.TRUNC;
zxidToSend = prevProposalZxid;
updates = zxidToSend;
}
}
queuePacket(propose.packet);
QuorumPacket qcommit = new QuorumPacket(Leader.COMMIT, propose.packet.getZxid(),
null, null);
queuePacket(qcommit);
}
}
} else if (peerLastZxid > maxCommittedLog) {
LOG.debug("Sending TRUNC to follower zxidToSend=0x{} updates=0x{}",
Long.toHexString(maxCommittedLog),
Long.toHexString(updates));
packetToSend = Leader.TRUNC;
zxidToSend = maxCommittedLog;
updates = zxidToSend;
} else {
LOG.warn("Unhandled proposal scenario");
}
} else {
// just let the state transfer happen
LOG.debug("proposals is empty");
}
//上面的sync更新的是内存树中的
LOG.info("Sending " + Leader.getPacketType(packetToSend));
//最后都会根据到leader.startForwarding()进行最终的更新
leaderLastZxid = leader.startForwarding(this, updates);
} finally {
rl.unlock();
}
//同步操作结束
//-----------------------------------------------------------------
QuorumPacket newLeaderQP = new QuorumPacket(Leader.NEWLEADER,
ZxidUtils.makeZxid(newEpoch, 0), null, null);
if (getVersion() < 0x10000) {
oa.writeRecord(newLeaderQP, "packet");
} else {
queuedPackets.add(newLeaderQP);
}
bufferedOutput.flush();
//Need to set the zxidToSend to the latest zxid
if (packetToSend == Leader.SNAP) {
zxidToSend = leader.zk.getZKDatabase().getDataTreeLastProcessedZxid();
}
oa.writeRecord(new QuorumPacket(packetToSend, zxidToSend, null, null), "packet");
bufferedOutput.flush();
/* if we are not truncating or sending a diff just send a snapshot */
if (packetToSend == Leader.SNAP) {
LOG.info("Sending snapshot last zxid of peer is 0x"
+ Long.toHexString(peerLastZxid) + " "
+ " zxid of leader is 0x"
+ Long.toHexString(leaderLastZxid)
+ "sent zxid of db as 0x"
+ Long.toHexString(zxidToSend));
// Dump data to peer
leader.zk.getZKDatabase().serializeSnapshot(oa);
oa.writeString("BenWasHere", "signature");
}
bufferedOutput.flush();
// Start sending packets
new Thread() {
public void run() {
Thread.currentThread().setName(
"Sender-" + sock.getRemoteSocketAddress());
try {
sendPackets();
} catch (InterruptedException e) {
LOG.warn("Unexpected interruption",e);
}
}
}.start();
//---------------------------------------------------------------
//同步操作结束
/*
* Have to wait for the first ACK, wait until
* the leader is ready, and only then we can
* start processing messages.
*/
qp = new QuorumPacket();
ia.readRecord(qp, "packet");
if(qp.getType() != Leader.ACK){
LOG.error("Next packet was supposed to be an ACK");
return;
}
LOG.info("Received NEWLEADER-ACK message from " + getSid());
//等待接受大部分 peer 的回应
leader.waitForNewLeaderAck(getSid(), qp.getZxid());
syncLimitCheck.start();
// now that the ack has been processed expect the syncLimit
sock.setSoTimeout(leader.self.tickTime * leader.self.syncLimit);
/*
* Wait until leader starts up
*/
synchronized(leader.zk){
while(!leader.zk.isRunning() && !this.isInterrupted()){
leader.zk.wait(20);
}
}
// 发送一个 UPDATE ,表明从现在开始接受事务提案
// Mutation packets will be queued during the serialize,
// so we need to mark when the peer can actually start
// using the data
//
queuedPackets.add(new QuorumPacket(Leader.UPTODATE, -1, null, null));
//while true 会一直循环
while (true) {
qp = new QuorumPacket();
ia.readRecord(qp, "packet");
long traceMask = ZooTrace.SERVER_PACKET_TRACE_MASK;
if (qp.getType() == Leader.PING) {
traceMask = ZooTrace.SERVER_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logQuorumPacket(LOG, traceMask, 'i', qp);
}
tickOfNextAckDeadline = leader.self.tick.get() + leader.self.syncLimit;
ByteBuffer bb;
long sessionId;
int cxid;
int type;
switch (qp.getType()) {
case Leader.ACK:
if (this.learnerType == LearnerType.OBSERVER) {
if (LOG.isDebugEnabled()) {
LOG.debug("Received ACK from Observer " + this.sid);
}
}
syncLimitCheck.updateAck(qp.getZxid());
leader.processAck(this.sid, qp.getZxid(), sock.getLocalSocketAddress());
break;
case Leader.PING:
// Process the touches
ByteArrayInputStream bis = new ByteArrayInputStream(qp
.getData());
DataInputStream dis = new DataInputStream(bis);
while (dis.available() > 0) {
long sess = dis.readLong();
int to = dis.readInt();
leader.zk.touch(sess, to);
}
break;
case Leader.REVALIDATE:
bis = new ByteArrayInputStream(qp.getData());
dis = new DataInputStream(bis);
long id = dis.readLong();
int to = dis.readInt();
ByteArrayOutputStream bos = new ByteArrayOutputStream();
DataOutputStream dos = new DataOutputStream(bos);
dos.writeLong(id);
boolean valid = leader.zk.touch(id, to);
if (valid) {
try {
//set the session owner
// as the follower that
// owns the session
leader.zk.setOwner(id, this);
} catch (SessionExpiredException e) {
LOG.error("Somehow session " + Long.toHexString(id) + " expired right after being renewed! (impossible)", e);
}
}
if (LOG.isTraceEnabled()) {
ZooTrace.logTraceMessage(LOG,
ZooTrace.SESSION_TRACE_MASK,
"Session 0x" + Long.toHexString(id)
+ " is valid: "+ valid);
}
dos.writeBoolean(valid);
qp.setData(bos.toByteArray());
queuedPackets.add(qp);
break;
case Leader.REQUEST:
bb = ByteBuffer.wrap(qp.getData());
sessionId = bb.getLong();
cxid = bb.getInt();
type = bb.getInt();
bb = bb.slice();
Request si;
if(type == OpCode.sync){
si = new LearnerSyncRequest(this, sessionId, cxid, type, bb, qp.getAuthinfo());
} else {
si = new Request(null, sessionId, cxid, type, bb, qp.getAuthinfo());
}
si.setOwner(this);
leader.zk.submitRequest(si);
break;
default:
LOG.warn("unexpected quorum packet, type: {}", packetToString(qp));
break;
}
}
} catch (IOException e) {
if (sock != null && !sock.isClosed()) {
LOG.error("Unexpected exception causing shutdown while sock "
+ "still open", e);
//close the socket to make sure the
//other side can see it being close
try {
sock.close();
} catch(IOException ie) {
// do nothing
}
}
} catch (InterruptedException e) {
LOG.error("Unexpected exception causing shutdown", e);
} finally {
LOG.warn("******* GOODBYE "
+ (sock != null ? sock.getRemoteSocketAddress() : "<null>")
+ " ********");
shutdown();
}
}
虽然代码非常长,但是逻辑很清晰先是要求 leader 得到大部分 peer 的回应,之后,开始同步数据,对于不一致的数据分为以下情况处理 :
先回滚再差异化同步 TRUNC + DIFF
通俗点说就是去掉 peer 与leader 不同的提案,然后补上缺的(follower 相对于 leader 缺少的提案)
仅回滚同步(TRUNC)
超前了当前 leader 本地中保存的最大的提案记录,所以之前回滚和 leader 一样
全量同步 (SNAP)
与 leader 存在差距,直接复制leader 的提案。
从上面的同步策略同步的最终目的是使所有的 peer 的数据一致,但是对于 TRUNC + DIFF这种策略有可能会丢弃掉最新的提案。
总结
我们从启动的开始,介绍了选举的过程和同步数据的过程,主干思路算是弄清楚,再根据这个线索去了解 zk 其他方面的问题就不难了。
参考资料
- 《从 Paxos 到 Zookeeper 》
- ZooKeeper的一致性算法赏析
zookeeper 源码(一) 选举和同步数据的更多相关文章
- Zookeeper 源码(五)Leader 选举
Zookeeper 源码(五)Leader 选举 前面学习了 Zookeeper 服务端的相关细节,其中对于集群启动而言,很重要的一部分就是 Leader 选举,接着就开始深入学习 Leader 选举 ...
- Zookeeper源码(启动+选举)
简介 关于Zookeeper,目前普遍的应用场景基本作为服务注册中心,用于服务发现.但这只是Zookeeper的一个的功能,根据Apache的官方概述:"The Apache ZooKeep ...
- Zookeeper 源码(六)Leader-Follower-Observer
Zookeeper 源码(六)Leader-Follower-Observer 上一节介绍了 Leader 选举的全过程,本节讲解一下 Leader-Follower-Observer 服务器的三种角 ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- Zookeeper 源码分析-启动
Zookeeper 源码分析-启动 博客分类: Zookeeper 本文主要介绍了zookeeper启动的过程 运行zkServer.sh start命令可以启动zookeeper.入口的main ...
- Zookeeper 源码(七)请求处理
Zookeeper 源码(七)请求处理 以单机启动为例讲解 Zookeeper 是如何处理请求的.先回顾一下单机时的请求处理链. // 单机包含 3 个请求链:PrepRequestProcessor ...
- Zookeeper 源码(四)Zookeeper 服务端源码
Zookeeper 源码(四)Zookeeper 服务端源码 Zookeeper 服务端的启动入口为 QuorumPeerMain public static void main(String[] a ...
- Zookeeper 源码(三)Zookeeper 客户端源码
Zookeeper 源码(三)Zookeeper 客户端源码 Zookeeper 客户端主要有以下几个重要的组件.客户端会话创建可以分为三个阶段:一是初始化阶段.二是会话创建阶段.三是响应处理阶段. ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
随机推荐
- Android 开发 ThreadPool(线程池) 总结
本文是介绍线程池的基础篇. 一.线程池的作用 创建异步线程的弊端: 1.每次new Thread创建对象,导致性能变差. 2.缺乏统一的管理,可能导致无限制的线程运行,严重的后果就是OOM 或者死机. ...
- Jquery插件 之 zTree树加载
原文链接:https://blog.csdn.net/jiaqu2177/article/details/80626730 zTree树加载 zTree 是一个依靠 jQuery 实现的多功能 “树插 ...
- C#画图超出屏幕的部分无法显示的解决方法
C#画图超出屏幕的部分无法显示,通过AutoScrollMinSize属性及相关方法解决问题. 可以实现 到 的转变. 代码如下: using System.Drawing; using System ...
- LitElement(六)生命周期
1.概述 基于LitElement的组件通过响应观察到的属性更改而异步更新. 属性更改是分批进行的,如果在请求更新后,更新开始之前,发生更多属性更改,则所有更改都将捕获在同一次更新中. 在较高级别上, ...
- 剑指offer 面试题. 按之字形顺序打印二叉树
题目描述 请实现一个函数按照之字形打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三行按照从左到右的顺序打印,其他行以此类推. 方法1: 正常层次遍历,利用普通队列.逢 ...
- python3 求一个list的所有子集
python3 求一个list的所有子集 def PowerSetsBinary(items): N = len(items) for i in range(2 ** N):#子集的个数 combo ...
- AcWing 差分一维加二维
一维 #include<bits/stdc++.h> using namespace std ; ; int n,m; int a[N],b[N]; //a为前缀和,b为差分 差分和前缀和 ...
- SpringMVC-时间类型转换
在上一篇SpringMVC的提交表单中,我们使用的日期为String型,可以将日期转换为Date型,然后使用initBinder函数进行显示,具体代码如下: (1)首先更改User.java的birt ...
- 网络、芯片、专利、产业链……影响5G手机走势的因素有哪些?
近段时间,备受关注的5G手机迎来一个爆发的小高潮.中国质量认证中心官网显示8款5G手机获得3C认证.其中华为有4款 ,一加.中兴.OPPO和vivo各有一款5G手机获得3C认证.随后在7月23日,中兴 ...
- mysql忘记密码,更改密码
对MySQL有研究的读者,可能会发现MySQL更新很快,在安装方式上,MySQL提供了两种经典安装方式:解压式和一键式,虽然是两种安装方式,但我更提倡选择解压式安装,不仅快,还干净.在操作系统上,My ...