【机器学习】机器学习入门08 - 聚类与聚类算法K-Means
时间过得很快,这篇文章已经是机器学习入门系列的最后一篇了。短短八周的时间里,虽然对机器学习并没有太多应用和熟悉的机会,但对于机器学习一些基本概念已经差不多有了一个提纲挈领的了解,如分类和回归,损失函数,以及一些简单的算法——kNN算法、决策树算法等。
那么,今天就用聚类和K-Means算法来结束我们这段机器学习之旅。
1. 聚类
1.1 什么是聚类
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。
——摘自**百度百科**“聚类”词条
聚类分析(英语:Cluster analysis)亦称为群集分析,是对于统计数据分析的一门技术,在许多领域受到广泛应用,包括机器学习,数据挖掘,模式识别,图像分析以及生物信息。聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性,常见的包括在坐标系中更加短的空间距离等。一般把数据聚类归纳为一种非监督式学习。
——摘自**Wikipedia**“聚类分析”词条
翻译一下,聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集成为一个“簇”。
通过这样的划分,每个簇可能对应于一些潜在的概念(也就是类别),如“浅色瓜” “深色瓜”,“有籽瓜” “无籽瓜”,甚至“本地瓜” “外地瓜”等;需说明的是,这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇对应的概念语义由使用者来把握和命名。(摘自 https://www.jianshu.com/p/caef1926adf7)
1.2 聚类和分类的区别
聚类是无监督的学习算法,分类是有监督的学习算法。所谓有监督就是有已知标签的训练集(也就是说提前知道训练集里的数据属于哪个类别),机器学习算法在训练集上学习到相应的参数,构建模型,然后应用到测试集上。而聚类算法是没有标签的,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起。
用小球来举例:
- 准备若干个盒子,分别标明“蓝色”、“红色”、“绿色”、“黄色”,把若干个上述四色的小球按照颜色投进相应的盒子里——分类
- 准备若干个盒子,盒子与盒子之间没有任何区别。把若干个小球按心情分到不同的盒子里(如:颜色相差较大时,按照颜色分类;颜色接近时按照大小分类;大小也接近时按照柔软程度。抑或同时考虑这一系列因素)。
简单来说,分类是把小球按照指定的标准扔到预先定制好的盒子里,聚类是把小球实时按照未知的标准扔到几个完全相同的盒子里。
2. 簇
聚类划分得到的每一组对象称为一个对象簇。要想进行有意义的聚类分析,获得有用的对象簇是最为关键的一步。以下是几种常用的簇:
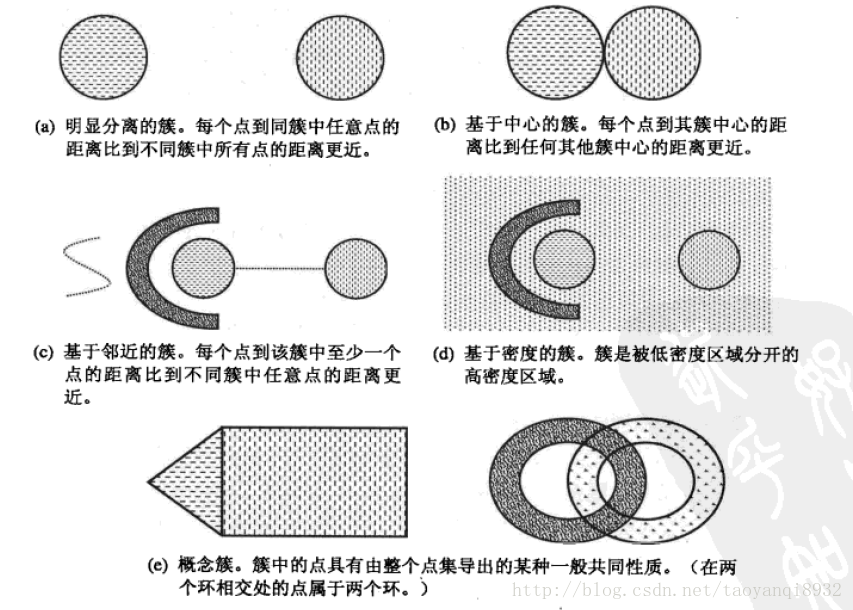
(摘自 https://blog.csdn.net/taoyanqi8932/article/details/53727841)
其中,基于中心的簇是我们接下来要研究的K-Means算法所要用到的簇类型。
提到距离,再重复一下之前的文章里提到过的各种距离类型。

我们最常用的,仍然是欧式距离(即差向量的2-范数)
3. K-Means算法
3.1 什么是K-Means算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
——摘自**百度百科**“K均值聚类算法”词条
K-平均算法(英文:k-means clustering)源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。k-平均聚类的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。这个问题将归结为一个把数据空间划分为Voronoi cells的问题。这个问题在计算上是NP困难的,不过存在高效的启发式算法。一般情况下,都使用效率比较高的启发式算法,它们能够快速收敛于一个局部最优解。这些算法通常类似于通过迭代优化方法处理高斯混合分布的最大期望算法(EM算法)。而且,它们都使用聚类中心来为数据建模;然而k-平均聚类倾向于在可比较的空间范围内寻找聚类,期望-最大化技术却允许聚类有不同的形状。k-平均聚类与k-近邻之间没有任何关系(后者是另一流行的机器学习技术)。
——摘自**Wikipedia**“K-Means算法”词条
简而言之,K-Means算法做的事情是:对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
3.2 K-Means算法的优缺点
- 优点:
- 简单,易于理解和实现;收敛快,一般仅需5-10次迭代即可,高效
- 缺点:
- 对K值得选取把握不同对结果有很大的不同
- 对于初始点的选取敏感,不同的随机初始点得到的聚类结果可能完全不同
- 对于不是凸的数据集比较难收敛
- 对噪点过于敏感,因为算法是根据基于均值的
- 结果不一定是全局最优,只能保证局部最优
- 对球形簇的分组效果较好,对非球型簇、不同尺寸、不同密度的簇分组效果不好。
3.3 K-Means算法描述和代码实现
K-Means算法的流程描述如下:

给出一段参考的Python代码实现:
import numpy as np
import pandas as pd
import random
import sys
import time
class KMeansClusterer:
def __init__(self,ndarray,cluster_num):
self.ndarray = ndarray
self.cluster_num = cluster_num
self.points=self.__pick_start_point(ndarray,cluster_num)
def cluster(self):
result = []
for i in range(self.cluster_num):
result.append([])
for item in self.ndarray:
distance_min = sys.maxsize
index=-1
for i in range(len(self.points)):
distance = self.__distance(item,self.points[i])
if distance < distance_min:
distance_min = distance
index = i
result[index] = result[index] + [item.tolist()]
new_center=[]
for item in result:
new_center.append(self.__center(item).tolist())
# 中心点未改变,说明达到稳态,结束递归
if (self.points==new_center).all():
return result
self.points=np.array(new_center)
return self.cluster()
def __center(self,list):
'''计算一组坐标的中心点
'''
# 计算每一列的平均值
return np.array(list).mean(axis=0)
def __distance(self,p1,p2):
'''计算两点间距
'''
tmp=0
for i in range(len(p1)):
tmp += pow(p1[i]-p2[i],2)
return pow(tmp,0.5)
def __pick_start_point(self,ndarray,cluster_num):
if cluster_num <0 or cluster_num > ndarray.shape[0]:
raise Exception("簇数设置有误")
# 随机点的下标
indexes=random.sample(np.arange(0,ndarray.shape[0],step=1).tolist(),cluster_num)
points=[]
for index in indexes:
points.append(ndarray[index].tolist())
return np.array(points)
4. 结语
好了,为期八周的机器学习入门到这里就结束了。希望这段学习经历能够或多或少能在将来起到一些作用。
那么,笔者也终于可以全心全意开始课程设计和期末复习啦。Bye~
参考资料:
https://www.jianshu.com/p/caef1926adf7
https://blog.csdn.net/taoyanqi8932/article/details/53727841
https://zh.wikipedia.org/wiki/聚类分析
https://zh.wikipedia.org/wiki/K-平均算法
https://baike.baidu.com/item/K均值聚类算法/15779627?fr=aladdin
https://baike.baidu.com/item/聚类/593695?fr=aladdin
【机器学习】机器学习入门08 - 聚类与聚类算法K-Means的更多相关文章
- 聚类和EM算法——K均值聚类
python大战机器学习——聚类和EM算法 注:本文中涉及到的公式一律省略(公式不好敲出来),若想了解公式的具体实现,请参考原著. 1.基本概念 (1)聚类的思想: 将数据集划分为若干个不想交的子 ...
- 机器学习课程-第8周-聚类(Clustering)—K-Mean算法
1. 聚类(Clustering) 1.1 无监督学习: 简介 在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签 ...
- python大战机器学习——聚类和EM算法
注:本文中涉及到的公式一律省略(公式不好敲出来),若想了解公式的具体实现,请参考原著. 1.基本概念 (1)聚类的思想: 将数据集划分为若干个不想交的子集(称为一个簇cluster),每个簇潜在地对应 ...
- 【机器学习与R语言】11- Kmeans聚类
目录 1.理解Kmeans聚类 1)基本概念 2)kmeans运作的基本原理 2.Kmeans聚类应用示例 1)收集数据 2)探索和准备数据 3)训练模型 4)评估性能 5)提高模型性能 1.理解Km ...
- [ZZ]机器学习的入门
转载自: http://www.cnblogs.com/mq0036/p/7131678.html 本篇虽不是这一个月的流水账,但是基本按照下面的思路对着一个月做了一次总结: 什么是机器学习? 机器学 ...
- 机器学习简易入门(四)- logistic回归
摘要:使用logistic回归来预测某个人的入学申请是否会被接受 声明:(本文的内容非原创,但经过本人翻译和总结而来,转载请注明出处) 本文内容来源:https://www.dataquest.io/ ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- 机器学习实战 - 读书笔记(11) - 使用Apriori算法进行关联分析
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第11章 - 使用Apriori算法进行关联分析. 基本概念 关联分析(associat ...
- 【机器学习笔记之一】深入浅出学习K-Means算法
摘要:在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 在数据挖掘中,K-Means算法是一种c ...
随机推荐
- 接口测试 java+httpclient+testng+excel
最近项目不忙,研究了下java实现接口自动化,借助testng+excel实现数据驱动 目前只用post方式测试,返回结果列没有通过列名去找 另外,请求参数是转义之后的,接口之间的依赖也是个问题,批量 ...
- TopCoder代码格式模板
$BEGINCUT$ $PROBLEMDESC$ $ENDCUT$ #include<bits/stdc++.h> using namespace std; class $CLASSNAM ...
- eclipse配置外部工具利用javah编译生成头文件
1. 点击eclipse工具栏外部工具按钮,打开配置外部工具 2. 新建一个启动配置,起名为Generate C and C++ Header File,按照下图配置好相应的参数 3. 运行该工具时, ...
- Mysql保留字列表
Mysql保留字列表.吠品整理. 尝试使用一个识别符,例如使用嵌入式MySQL 数据类型或函数名作为表名或列名,例如TIMESTAMP 或GROUP,会造成一个常见问题.允许你这样操作( 例如,A ...
- 移动端click点透bug
移动端click点透bug click点透bug有一个特定的产生情况: 当上层元素是tap事件,且tap后消失,下层元素是click事件.这个时候,tap上层元素的时候就会触发下层元素的click事件 ...
- [kuangbin带你飞]专题一 简单搜索 - D - Fliptile
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> us ...
- 通过apiservice反向代理访问service
第一种:NodePort类型 type: NodePort ports: - port: 80 targetPort: 80 nodePort: 30008 第二种:ClusterIP类型 typ ...
- 接着上回,导包正确之后,出现javabean.Friend cannot be cast to java.util.List,的错误。找了很久。以为是User user0作为参数,改成了String username还是错误,看了看listFriend.jsp没有错误,我想会不会是包多了,导致类型复杂。最后发现包少了一个:
import org.apache.commons.dbutils.handlers.BeanListHandler;这个包,BeanListHandler让我发现List<Friend> ...
- MybatisPlus联合分页查询
跟单表分页查询差不多 1.编写查询语句 public interface QuestionMapper extends BaseMapper<Question> { @Select(&qu ...
- Linux 实用指令(5)--组管理和权限管理
目录 组管理和权限管理 1 Linux组基本介绍 2 文件/目录 所有者 2.1 查看文件的所有者 2.2 修改文件所有者 3 组的创建 3.1 基本指令 3.2 应用实例 4 文件/目录 所在组 4 ...