改善深层神经网络(三)超参数调试、Batch正则化和程序框架
1、超参数调试:
(1)超参数寻找策略:
对于所有超参数遍历求最优参数不可取,因为超参数的个数可能很多,可选的数据过于庞大.
由于最优参数周围的参数也可能比较好,所以可取的方法是:在一定的尺度范围内随机取值,先寻找一个较好的参数,再在该参数所在的区域更精细的寻找最优参数.
(2)选择合适的超参数范围:
假设 n[l] 可选取值 50~100:在整个范围内随机均匀取值
选取神经网络层数 #layers,L的可选取值为 2~4:在整个范围内随机均匀取值
学习速率 α 的可选取值 0.0001~1:在对数轴上随机均匀取值
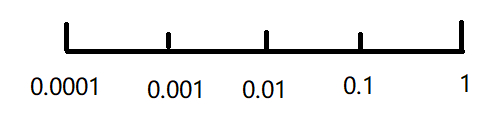
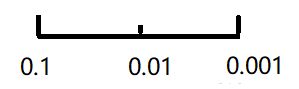
β 的可选取值 0.9~0.999:在 1-β 的对数轴上随机均匀取值
2、Batch归一化:
(1)问题背景:
a[1] a[2] a[3]
之前介绍的正则化输入是对 X 进行正则化,那么能否对 a[2] 进行正则化(本质是对 z[2] 正则化),以更快地训练 w[3] 和 b[3] ?
(2)Batch归一化流程:
给出参数:Z(1) ... Z(m)
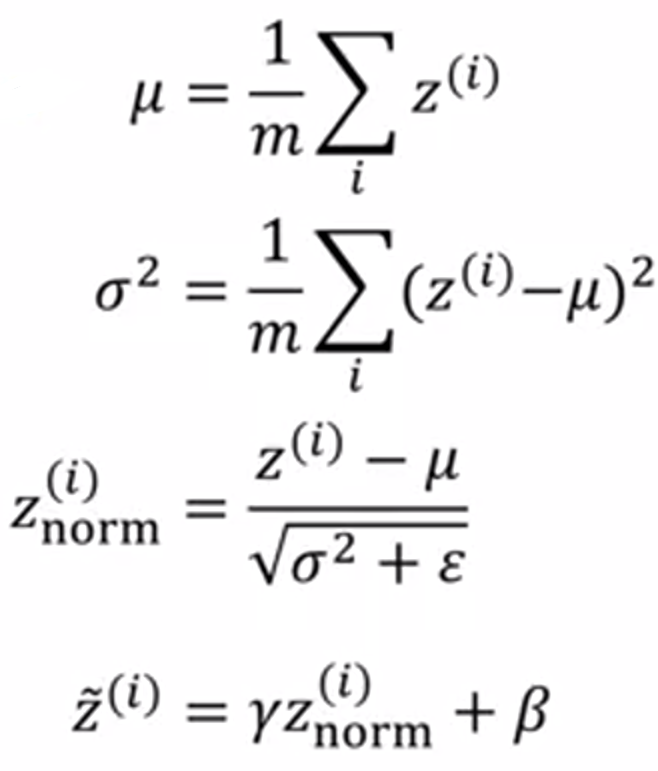
其中 γ 和 β 为学习参数,作用是:可以随意设置 Z~(i) 的平均值和方差.
传播过程:
X — w[1],b[1] —> Z[1] — γ[1], β[1] —> Z~[1] —g(Z~[1]) —> A[1] — w[2],b[2] —> Z[2] — ... —> Y^
需要优化的参数:
W[1], b[1], ..., W[L], b[L]
γ[1], β[1], ..., γ[L], β[L]
一个小的简化:
由于在计算 Z~(i) 前会通过正则化把均值设成0,那么参数 b 可以不用加上.
(3)应用:
for t = 1 ... num_MiniBatches:
Compute forward prop on X{t}
In each hidden layer,use Batch Norm to replace Z[l] with Z~[l]
Use backprop to compute dW[l], dβ[l], dγ[l]
Update parameters W[l], β[l], γ[l]
(Work with momentum、RMSprop、Adam)
3、Softmax回归:
(1)举例说明:
Softmax回归适用于多类别分类,以4分类为例:
神经网络模型:
假设 Z[L] = [5, 2, -1, 3]T
t = [e5, e2, e-1, e3]T ≈ [148.4, 7.4, 0.4, 20.1]T
∑ t = 176.3
a[L] = t / ∑ t = [0.842, 0.042, 0.002, 0.114]T
即是分类0的概率是0.842,分类1的概率是0.042,分类2的概率是0.002,分类3的概率是0.114.
(2)Softmax分类器损失函数:
训练结果集:Y = [y(1), y(2), ..., y(m)],每一个 y(i) 都是一个列向量.
预测结果集:Y^ = [y^(1), y^(2), ..., y^(m)]
单个训练样本的损失函数: L(y^, y) = - ∑ yj * log(y^j)
整个训练集的损失函数:J(w[1], b[1], ...) = 1 / m * ∑ L(y^(i), y(i))
4、TensorFlow使用举例:
最小化 J = (w - 5)² = w² - 10w + 25:
(1)写法①:
w = tf.Variable(0, dtype = tf.float32)
cost = tf.add(tf.add(w**2, tf.multiply(-10, w)), 25)
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
print(session.run(w))
#输出0.0
for i in range(1000):
session.run(train)
print(session.run(w))
#输出4.99999
(2)写法②:
coefficients = np.array([[1.], [-10.], [25.]])
w = tf.Variable(0, dtype = tf.float32)
x = tf.placeholder(tf.float32, [3,1])
cost = x[0][0]*w**2 + x[1][0]*w + x[2][0]
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
print(session.run(w))
#输出0.0
for i in range(1000):
session.run(train, feed_dicts(x:coefficients))
print(session.run(w))
#输出4.99999
改善深层神经网络(三)超参数调试、Batch正则化和程序框架的更多相关文章
- Deep Learning.ai学习笔记_第二门课_改善深层神经网络:超参数调试、正则化以及优化
目录 第一周(深度学习的实践层面) 第二周(优化算法) 第三周(超参数调试.Batch正则化和程序框架) 目标: 如何有效运作神经网络,内容涉及超参数调优,如何构建数据,以及如何确保优化算法快速运行, ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 Batch归一化 Softmax
摘抄:https://xienaoban.github.io/posts/2106.html 1. 调试(Tuning) 超参数 取值 #学习速率:\(\alpha\) Momentum:\(\bet ...
- DeepLearning.ai学习笔记(二)改善深层神经网络:超参数调试、正则化以及优化--Week2优化算法
1. Mini-batch梯度下降法 介绍 假设我们的数据量非常多,达到了500万以上,那么此时如果按照传统的梯度下降算法,那么训练模型所花费的时间将非常巨大,所以我们对数据做如下处理: 如图所示,我 ...
- Andrew Ng - 深度学习工程师 - Part 2. 改善深层神经网络:超参数调试、正则化以及优化(Week 2. 优化算法)
===========第2周 优化算法================ ===2.1 Mini-batch 梯度下降=== epoch: 完整地遍历了一遍整个训练集 ===2.2 理解Mini-bat ...
- deeplearning.ai 改善深层神经网络 week3 超参数调试、Batch正则化和程序框架 听课笔记
这一周的主体是调参. 1. 超参数:No. 1最重要,No. 2其次,No. 3其次次. No. 1学习率α:最重要的参数.在log取值空间随机采样.例如取值范围是[0.001, 1],r = -4* ...
- deeplearning.ai 改善深层神经网络 week3 超参数调试、Batch Normalization和程序框架
这一周的主体是调参. 1. 超参数:No. 1最重要,No. 2其次,No. 3其次次. No. 1学习率α:最重要的参数.在log取值空间随机采样.例如取值范围是[0.001, 1],r = -4* ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 正则化以及梯度相关
笔记:Andrew Ng's Deeping Learning视频 参考:https://xienaoban.github.io/posts/41302.html 参考:https://blog.cs ...
- 吴恩达《深度学习》第二门课(3)超参数调试、Batch正则化和程序框架
3.1调试处理 (1)不同超参数调试的优先级是不一样的,如下图中的一些超参数,首先最重要的应该是学习率α(红色圈出),然后是Momentum算法的β.隐藏层单元数.mini-batch size(黄色 ...
- 跟我学算法-吴恩达老师(超参数调试, batch归一化, softmax使用,tensorflow框架举例)
1. 在我们学习中,调试超参数是非常重要的. 超参数的调试可以是a学习率,(β1和β2,ε)在Adam梯度下降中使用, layers层数, hidden units 隐藏层的数目, learning_ ...
随机推荐
- C#设置自定义文件图标实现双击启动
修改注册表,双击文件直接打开 string strProject = "Exec"; string p_FileTypeName =".cdb";//文件后缀 ...
- [javascript] 利用chrome的overrides实时调试线上js
chrome的开发者工具,在source选项卡下,可以看到js的源代码,有一个断点调试功能,就是在js的源代码行号那里点击一下,出现一个箭头,当再次刷新页面并且进行了相应操作时,就会停在断点的地方.我 ...
- 微信小程序入门笔记-审核上线(5)
1.点击上传 2.填写版本号.备注 3.https://mp.weixin.qq.com/回到微信公众平台,点击版本管理就可以看到开发版本 4.点击提交审核(提交之前填写小程序基本资料,才可提交审核) ...
- mysql必知必会--创建计算字段
计算字段 存储在数据库表中的数据一般不是应用程序所需要的格式.下面举 几个例子. * 如果想在一个字段中既显示公司名,又显示公司的地址,但这两 个信息一般包含在不同的表列中. * 城市.州和邮政编码存 ...
- python实现串口通讯小程序(GUI界面)
python实现串口通讯小程序(GUI界面) 使用python实现串口通讯需要使用python的pyserial库来实现,这个库在安装python的时候没有自动进行安装,需要自己进行安装. 1.安装p ...
- SpringBoot整合NoSql--(四)Session共享
简介: 正常情况下,HttpSession是通过Servlet 容器创建并进行管理的,创建成功之后都是保存在内存中.如果开发者需要对项目进行横向扩展搭建集群,那么可以利用一些硬件或者软件工具来做负载均 ...
- Oracle实例占用超高CPU排查
CPU主要功能:处理指令.执行操作.要求进行动作.控制时间.处理数据. 结合数据库实例CPU占用高,可能的原因是数据库在执行大量的操作(全表查询.大量排序等). 由于公司没有DBA,遇到数据库问题只能 ...
- spring mvc5 的 配置文件 pom.xml
spring mvc5 的 配置文件 pom.xml <?xml version="1.0" encoding="UTF-8"?> <pro ...
- PyCharm2019 永久激活(测试通过)
2019.1.1 专业版 永久期限,需要下载补丁,以及配置文件 补丁地址:https://pan.baidu.com/s/16ALpz_BCXjsRkpS_PtD23A 1,下载安装pycharm程序 ...
- 数据库MySQL之存储过程
存储过程的定义 存储过程是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象.其在思想上与面向对象编程中函数的定义与调用一致,存储过程只是SQL语言维度上的封装与运用. 存储过程的优缺点 优 ...