Flume与Logstash比较
Flume与Logstash相比,个人的体会如下:
- Logstash比较偏重于字段的预处理;而Flume偏重数据的传输;
- Logstash有几十个插件,配置灵活;FLume则是强调用户的自定义开发(source和sink的种类也有一二十个吧,channel就比较少了)。
- Logstash的input和filter还有output之间都存在buffer,进行缓冲;Flume直接使用channel做持久化(可以理解为没有filter)
一、Logstash浅谈:
- input负责数据的输入(产生或者说是搜集,以及解码decode);
- Filter负责对采集的日志进行分析,提取字段(一般都是提取关键的字段,存储到elasticsearch中进行检索分析);
- output负责把数据输出到指定的存储位置(如果是采集agent,则一般是发送到消息队列中,如kafka,redis,mq;如果是分析汇总端,则一般是发送到elasticsearch中)
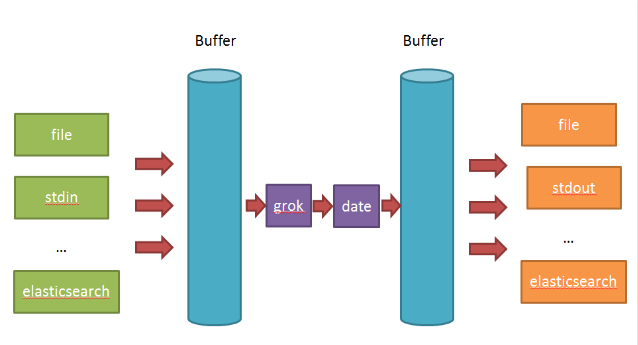
在Logstash比较看重input,filter,output之间的协同工作,因此多个输入会把数据汇总到input和filter之间的buffer中。filter则会从buffer中读取数据,进行过滤解析,然后存储在filter于output之间的Buffer中。当buffer满足一定的条件时,会触发output的刷新。
二、Flume浅谈
在Flume中:
- source 负责与Input同样的角色,负责数据的产生或搜集(一般是对接一些RPC的程序或者是其他的flume节点的sink)
- channel 负责数据的存储持久化(一般都是memory或者file两种)
- sink 负责数据的转发(用于转发给下一个flume的source或者最终的存储点——如HDFS)
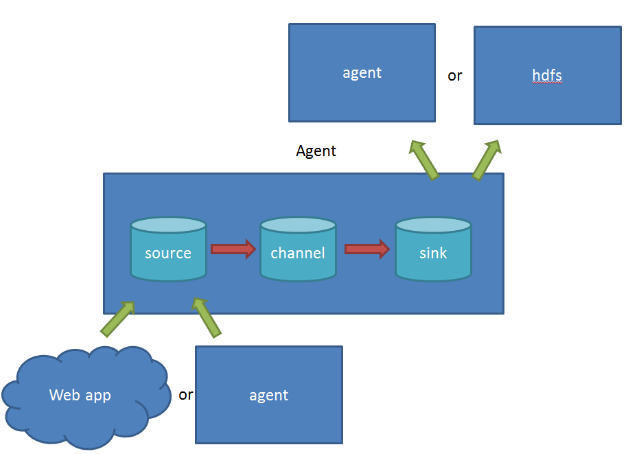
Flume比较看重数据的传输,因此几乎没有数据的解析预处理。仅仅是数据的产生,封装成event然后传输。传输的时候flume比logstash多考虑了一些可靠性。因为数据会持久化在channel中(一般有两种可以选择,memoryChannel就是存在内存中,另一个就是FileChannel存储在文件种),数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS;也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。
不过flume的持久化也是有容量限制的,比如内存如果超过一定的量,也一样会爆掉。
参见:http://www.cnblogs.com/xing901022/p/5631445.html
Flume与Logstash比较的更多相关文章
- 聊聊Flume和Logstash的那些事儿
在某个Logstash的场景下,我产生了为什么不能用Flume代替Logstash的疑问,因此查阅了不少材料在这里总结,大部分都是前人的工作经验下,加了一些我自己的思考在里面,希望对大家有帮助. 本文 ...
- Flume日志采集系统——初体验(Logstash对比版)
这两天看了一下Flume的开发文档,并且体验了下Flume的使用. 本文就从如下的几个方面讲述下我的使用心得: 初体验--与Logstash的对比 安装部署 启动教程 参数与实例分析 Flume初体验 ...
- 【大数据实战】Logstash采集->Kafka->ElasticSearch检索
1. Logstash概述 Logstash的官网地址为:https://www.elastic.co/cn/products/logstash,以下是官方对Logstash的描述. Logstash ...
- Logstash介绍及Input插件介绍
一.Logstash简介 Logstash是一个开源数据收集引擎,具有实时管道功能.Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地. Logstash管 ...
- Openstack Basic
html,body { } .CodeMirror { height: auto } .CodeMirror-scroll { } .CodeMirror-lines { padding: 4px 0 ...
- linux日志审计项目案例实战(生产环境日志审计项目解决方案)
所谓日志审计,就是记录所有系统及相关用户行为的信息,并且可以自动分析.处理.展示(包括文本或者录像) 推荐方法:sudo配合syslog服务,进行日志审计(信息较少,效果不错) 1.安装sudo命令. ...
- Kafka connect快速构建数据ETL通道
摘要: 作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 业余时间调研了一下Kafka connect的配置和使用,记录一些自己的理解和心得,欢迎 ...
- Linux实战教学笔记14:用户管理初级(下)
第十四节 用户管理初级(下) 标签(空格分隔): Linux实战教学笔记-陈思齐 ---更多资料点我查看 1,用户查询相关命令id,finger,users,w,who,last,lastlog,gr ...
- ELK日志套件安装与使用
1.ELK介绍 ELK不是一款软件,而是elasticsearch+Logstash+kibana三款开源软件组合而成的日志收集处理套件,堪称神器.其中Logstash负责日志收集,elast ...
随机推荐
- 《数字图像处理原理与实践(MATLAB版)》一书之代码Part1
本文系<数字图像处理原理与实践(MATLAB版)>一书之代码系列的Part1(P1~42).代码运行结果请參见原书配图. P20 I = imread('lena.jpg');BW1 = ...
- 鼠标上下滚动支持combobox选中
首先需要jquery插件来支持: 1.代码SVN检出https://github.com/jquery/jquery-mousewheel 2.点击这里下载jquery.mousewheel.zip ...
- logback-kafka-appender
logback 日志写入kafka队列 logback-kafka-appender Logback incompatibility Warning Due to a bug in logback-c ...
- struts-config.xml配置详解
<struts-config>是struts的根元素,它主要有8个子元素,DTD定义如下: <!ELEMENT struts-config (data-sources?,form-b ...
- springboot项目启动多个实例的方法
我现在需要实现这样的功能:将一个服务提供者启动多个实例,下面我列出在eclipse中启动多个实例的方法: 首先看一下我的服务提供者的项目文件结构: springboot默认的配置文件是applicat ...
- NetCore中使用DynamicExpresso、Z.Expressions、LambdaParser进行安字符串求值
例子如下: Z.Expressions从2.0开始支持了NetCore,但是收费的.其它两者免费.建议使用DynamicExpresso,免费而且速度快.LambdaParser目前支持太少. sta ...
- eclipse 远程调试程序
最近遇到一个非常恶心的问题,本地调试没有问题,到了线上就复发,逼于无奈只能使用eclipse远程调试,下面把步骤记录一下: 1.修改服务器的启动脚本,添加如下内容: export JPDA_ADDRE ...
- VB数组的清除
在一个程序中,同一数组只能用Dim语句定义一次.但有时可能需要清除数组的内容或对数组重新定义,这可以用:Erase语句来实现. 格式:Erase(数组名)[,(数组名)] 功能:用于重新初始化静态数组 ...
- 解决mybatis报错Result Maps collection does not contain value for java.lang.Integer
解决办法:1.检查mybatis的xml配置 2.在某处肯定有配错了的,如"resultMap" -->"resultType" [html] view ...
- Java 实现的SnowFlake生成UUID (Java代码实战-007)
SnowFlake所生成的ID一共分成四部分: 1.第一位占用1bit,其值始终是0,没有实际作用. 2.时间戳占用41bit,精确到毫秒,总共可以容纳约69 年的时间. 3.工作机器id占用10bi ...