Linux安装ElasticSearch与MongoDB分布式集群环境下数据同步
ElasticSearch有一个叫做river的插件式模块,可以将外部数据源中的数据导入elasticsearch并在上面建立索引。River在集群上是单例模式的,它被自动分配到一个节点上,当这个节点挂掉后,river会被自动分配到另外的一个节点上。目前支持的数据源包括:Wikipedia, MongoDB, CouchDB, RabbitMQ, RSS, Sofa, JDBC, FileSystem,Dropbox等。River有一些指定的规范,依照这些规范可以开发适合于自己的应用数据的插件。
1、安装MongoDB的River:https://github.com/richardwilly98/elasticsearch-river-mongodb、http://blog.csdn.net/huwei2003/article/details/40407555
git clone https://github.com/richardwilly98/elasticsearch-river-mongodb.git
cd elasticsearch-river-mongodb
git tag
git checkout elasticsearch-river-mongodb-2.0.5
mvn clean
mvn compile
mvn package vim install-local.sh --把plugin --remove 改成 plugin remove;注释掉最后一行sudo命令,因为没有plugin命令的url参数了。
./install-local.sh
cd target/releases/


cd /usr/share/elasticsearch/plugins/ mkdir mongodb cd mongodb mv /data/elasticsearch-river-mongodb/target/releases/elasticsearch-river-mongodb-2.0..zip ./ cd ../head/ cp plugin-descriptor.properties ../mongodb/ cd - vim plugin-descriptor.properties --修改description,name的信息为mongo mkdir _site cp -r /data/elasticsearch-river-mongodb/src/site/* /usr/share/elasticsearch/plugins/mongodb/_site/ --复制mongo网站目录到plugins/mongodb/_site cd _site service elasticsearch restart



2、浏览器输入:http://192.168.7.131:9200/_plugin/mongodb/
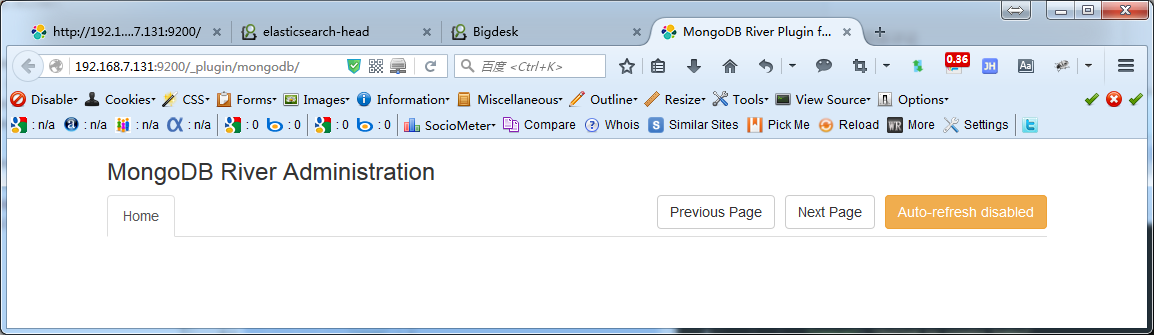
3、配置Mongo&ElasticSearch数据互通:https://github.com/richardwilly98/elasticsearch-river-mongodb/wiki、http://blog.csdn.net/huwei2003/article/details/40407555
创建river并索引的标准模版如下:
$ curl -XPUT "localhost:9200/_river/${es.river.name}/_meta" -d '
{
"type": "mongodb",
"mongodb": {
"servers":
[
{ "host": ${mongo.instance1.host}, "port": ${mongo.instance1.port} },
{ "host": ${mongo.instance2.host}, "port": ${mongo.instance2.port} }
],
"options": {
"secondary_read_preference" : true,
"drop_collection": ${mongo.drop.collection},
"exclude_fields": ${mongo.exclude.fields},
"include_fields": ${mongo.include.fields},
"include_collection": ${mongo.include.collection},
"import_all_collections": ${mongo.import.all.collections},
"initial_timestamp": {
"script_type": ${mongo.initial.timestamp.script.type},
"script": ${mongo.initial.timestamp.script}
},
"skip_initial_import" : ${mongo.skip.initial.import},
"store_statistics" : ${mongo.store.statistics},
},
"credentials":
[
{ "db": "local", "user": ${mongo.local.user}, "password": ${mongo.local.password} },
{ "db": "admin", "user": ${mongo.db.user}, "password": ${mongo.db.password} }
],
"db": ${mongo.db.name},
"collection": ${mongo.collection.name},
"gridfs": ${mongo.is.gridfs.collection},
"filter": ${mongo.filter}
},
"index": {
"name": ${es.index.name},
"throttle_size": ${es.throttle.size},
"bulk_size": ${es.bulk.size},
"type": ${es.type.name}
"bulk": {
"actions": ${es.bulk.actions},
"size": ${es.bulk.size},
"concurrent_requests": ${es.bulk.concurrent.requests},
"flush_interval": ${es.bulk.flush.interval}
}
}
}'
一些配置项的解释如下,具体可以查看github的wiki:
- db为同步的数据库名,
- host mongodb的ip地址(默认为localhost)
- port mongodb的端口
- collection 要同步的表名
- fields 要同步的字段名(用逗号隔开,默认全部)
- gridfs 是否是gridfs文件(如果collection是gridfs的话就设置成true)
- local_db_user local数据库的用户名(没有的话不用写)
- local_db_password local数据库的密码(没有的话不用写)
- db_user 要同步的数据库的密码(没有的话不用写)
- db_password 要同步的数据库的密码(没有的话不用写)
- index.name 要建立的索引名,最好是小写(应该是必须小写,并且索引名称必须唯一,之前不能存在,建议使用“数据库名+集合名+index”方式命名)
- index:type collection名,即该索引对应的数据集合名
- type 类型 后面是 mongodb 因为用的是 mongodb 数据库
- bulk_size 批量添加的最大数
- bulk_timeout 批量添加的超时时间
例如添加mongodb数据到elasticsearch里面:
curl -XPUT "http://ip地址:端口号/river_dbname/collectionname/_meta" -d'
{
"type":"mongodb",
"mongodb":{
"servers":[
{"host":"mongodb的ip地址","port":mongodb的访问端口},
{"host":"mongodb的ip地址","port":mongodb的访问端口},
{"host":"mongodb的ip地址","port":mongodb的访问端口}
],
"db":"dbname", (实际数据库名称)
"collection":"collectionname", (实际集合名称)
"gridfs":false,
"credentials":[
{ "db": "admin", "user": "user", "password": "user" }
],
"options":{
"secondary_read_preference":true (使用副本集)
}
},
"index":{
"name":"collectionname_index", (全部小写字母)
"type":"collectionname" (实际集合名称)
}
}'
添加成功,如下图:

使用head插件观察结果:


也可以通过get方式获取
GET /river_dbname/collectionname/_meta
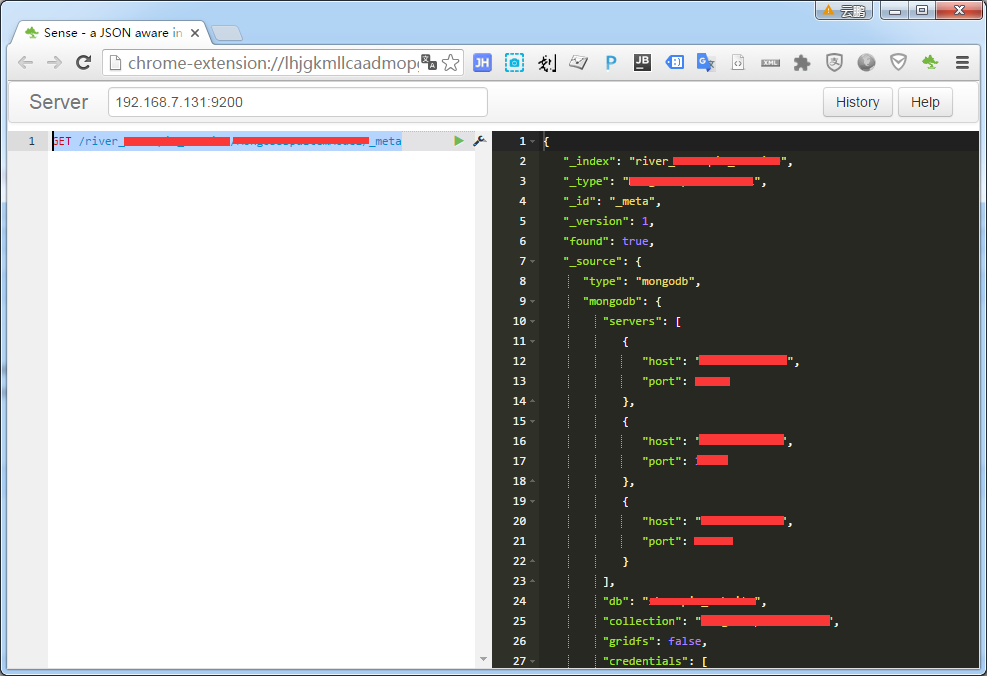
转:
http://blog.csdn.net/huwei2003/article/details/40407555
Linux安装ElasticSearch与MongoDB分布式集群环境下数据同步的更多相关文章
- elasticsearch与mongodb分布式集群环境下数据同步
1.ElasticSearch是什么 ElasticSearch 是一个基于Lucene构建的开源.分布式,RESTful搜索引擎.它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索 ...
- 在Hadoop1.2.1分布式集群环境下安装hive0.12
在Hadoop1.2.1分布式集群环境下安装hive0.12 ● 前言: 1. 大家最好通读一遍过后,在理解的基础上再按照步骤搭建. 2. 之前写过两篇<<在VMware下安装Ubuntu ...
- 分布式集群环境下,如何实现session共享三(环境搭建)
这是分布式集群环境下,如何实现session共享系列的第三篇.在上一篇:分布式集群环境下,如何实现session共享二(项目开发)中,准备好了一个通过原生态的servlet操作session的案例.本 ...
- 分布式集群环境下,如何实现session共享五(spring-session+redis 实现session共享)
这是分布式集群环境下,如何实现session共享系列的第五篇.在上一篇:分布式集群环境下,如何实现session共享四(部署项目测试)中,针对nginx不同的负载均衡策略:轮询.ip_hash方式,测 ...
- 分布式集群环境下,如何实现session共享四(部署项目测试)
这是分布式集群环境下,如何实现session共享系列的第四篇.在上一篇:分布式集群环境下,如何实现session共享三(环境搭建)中,已经准备好了相关的环境:tomcat.nginx.redis.本篇 ...
- 分布式集群环境下,如何实现session共享二(项目开发)
在上一篇分布式集群环境下,如何实现session共享一(应用场景)中,介绍了在分布式集群下,需要实现session共享的应用场景.并且最后留下了一个问题:在集群环境下,如何实现session的共享呢? ...
- 基于HBase Hadoop 分布式集群环境下的MapReduce程序开发
HBase分布式集群环境搭建成功后,连续4.5天实验客户端Map/Reduce程序开发,这方面的代码网上多得是,写个测试代码非常容易,可是真正运行起来可说是历经挫折.下面就是我最终调通并让程序在集群上 ...
- 分布式集群环境下,如何实现session共享一(应用场景)
在web应用中,由于http的请求响应式,无状态.要记录用户相关的状态信息,比如电商网站的购物车,比如用户是否登录等,都需要使用session.我们知道session是由servlet容器创建和管理, ...
- 分布式集群环境下运行Wordcount程序
1.分布式环境的Hadoop提交作业方式与本地安装的Hadoop作业提交方式相似,但有两点不同: 1)作业输入输出都存储在HDFS 2)本地Hadoop提交作业时将作业放在本地JVM执行,而分布式集群 ...
随机推荐
- Sphinx + Coreseek 实现中文分词搜索
Sphinx + Coreseek 实现中文分词搜索 Sphinx Coreseek 实现中文分词搜索 全文检索 1 全文检索 vs 数据库 2 中文检索 vs 汉化检索 3 自建全文搜索与使用Goo ...
- 运行代码时报linker command failed with exit code 1 错误
一个c语言项目,在.h文件中原来只有一些方法的声明,后来我加入了一些变量声明后,编译的时候报错: 运行代码时报linker command failed with exit code 1 错误 怎么回 ...
- wget获取整站
wget -m -e robots=off https://www.baidu.com -m是克隆整个网站,-e robots=off是让wget忽视robots.txt 如果网站有中文路径,最好用以 ...
- Robotframework(4):创建变量的类型和使用
转载:http://www.cnblogs.com/CCGGAAG/p/7800321.html 实际的测试过程中,编写脚本时,我们需要创建一些变量来暂时或者永久性的存储数据,那么在Robotfram ...
- yii源码二 -- interfaces
path:framework/base/interfaces.php overview:This file contains core interfaces for Yii framework. in ...
- ZH奶酪:LAMP环境中如何重新部署一个Yii2.0 web项目
使用Yii2.0 framework开发的项目,使用Github进行版本控制,现在要把这个项目部署到一个新的电脑/系统中: (1)安装LAMP (2)在/var/www/html目录下执行 git c ...
- Unbuntu和Centos中部署同时多版本PHP的详细过程
镜像制作:Unbuntu14 部署LAMP过程 1.Azure经典版中创建源Ubuntu14,并使用Xshell连接,并切换到root帐户下. 2.安装php5.4,新建/var/local/ ...
- Go语言中使用SQLite数据库
Go语言中使用SQLite数据库 1.驱动 Go支持sqlite的驱动也比较多,但是好多都是不支持database/sql接口的 https://github.com/mattn/go-sqlite3 ...
- 两个自定义对象List列表取交集(intersection)
public static void main(String[] args) { List<Fpxx> list = ListUtils.intersection(getFpList1() ...
- MySQL general log
1:查看版本 SELECT VERSION(); 2:查看当前的日志保存方式 mysql> SHOW VARIABLES LIKE '%log_output%'; +-------------- ...