Java泛型方法与数据查询
在使用JDBC查询数据库中数据时,返回的结果是ResultSet对象,使用十分不方便。Commons DbUtils组件提供了将ResultSet转化为Bean列表的方法,但是该方法在使用时需要根据不同的Bean对象创建不同的查询方法。本实例将在该方法的基础上使用泛型进行包装,使其通用性更强。
思路分析:
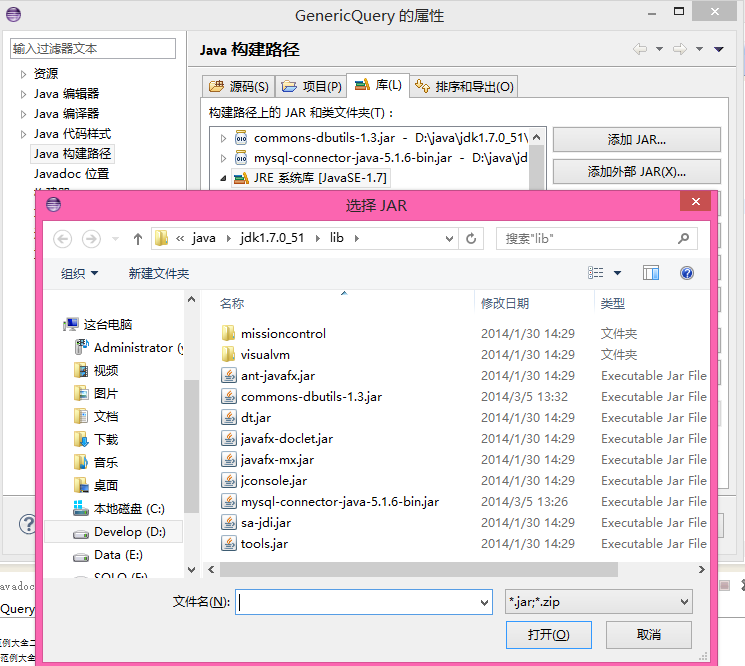
- 凡是要进行数据库操作的肯定都要额外导入包,比如mysql-connector-java-5.1.6-bin.jar与commons-dbutils-1.3.jar。我就很奇怪为毛JDK的默认包里不带这些呢。导入包的操作为在项目的“JRE系统库”选项上单击鼠标右键,选择构建路径——>配置构建路径——>添加外部JAR,如图所示:
- 从数据表里查询信息后,要想将查到的信息分别显示出来,就得根据数据表的结构来定义类了,一般来说,对于要显示的每个字段,都要在类中为其定义成员变量、get()方法与set()方法,代码如下:Books.java:
package cn.edu.xidian.crytoll; public class Books { private int id;
private String name; public int getId() {
return id;
} public void setId(int id) {
this.id = id;
} public String getName() {
return name;
} public void setName(String name) {
this.name = name;
} @Override
public String toString() {
return id + ":" + name;
}
} - 接下来要编写数据库操作类,在该类中定义数据库进行连接、查询等操作的方法。因为是泛型查询,所以查询方法的返回值就是<T> List<T>类型的,参数嘛一个是SQL语句,一个就是上一步定义的类Class<T> type了,代码如下:GenericQuery.java:
package cn.edu.xidian.crytoll;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.List;
import org.apache.commons.dbutils.DbUtils;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler; public class GenericQuery { private static String URL = "jdbc:mysql://localhost:3306/db_database13";
private static String DRIVER = "com.mysql.jdbc.Driver";
private static String USERNAME = "root";
private static String PASSWORD = "密码";
private static Connection conn; public static Connection getConnection() {
DbUtils.loadDriver(DRIVER);
try {
conn = DriverManager.getConnection(URL, USERNAME, PASSWORD);
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
} public static <T> List<T> query(String sql, Class<T> type) {
QueryRunner qr = new QueryRunner();
List<T> list = null;
try {
list = qr.query(getConnection(), sql, new BeanListHandler<T>(type));
} catch (SQLException e) {
e.printStackTrace();
} finally {
DbUtils.closeQuietly(conn);
}
return list;
}
} - 最后就是编写主方法啦,在主方法中创建一个泛型对象,并调用上一步中的查询方法,然后使用foreach()循环将要查询的信息显示出来,代码如下:
GenericQueryTest.java:
package cn.edu.xidian.crytoll; import java.util.List; public class GenericQueryTest {
public static void main(String[] args) {
String sql = "select * from books;";
List<Books> list = GenericQuery.query(sql, Books.class);
System.out.println("明日科技新书:");
for (Books books : list) {
System.out.println(books);
}
}
}效果如图:

Java泛型方法与数据查询的更多相关文章
- java连接mysql数据查询数据
package com.cn.peitest.connectDatabase; import java.sql.Connection; import java.sql.DriverManager; i ...
- Java网页数据采集器[下篇-数据查询]【转载】
本期概述 上一期我们学习了如何将html采集到的数据存储到MySql数据库中,这期我们来学习下如何在存储的数据中查询我们实际想看到的数据. 数据采集页面 2011-2012赛季英超球队战绩 如果是初学 ...
- Elasticsearch集群搭建及使用Java客户端对数据存储和查询
本次博文发两块,前部分是怎样搭建一个Elastic集群,后半部分是基于Java对数据进行写入和聚合统计. 一.Elastic集群搭建 1. 环境准备. 该集群环境基于VMware虚拟机.CentOS ...
- GeoMesa Java API-写入与查询数据
GeoMesa Java API-写入与查询数据 写入数据 DataStore SimpleFeatureType SimpleFeature 写入 查询数据 几个常用查询条件 设置最大返回条目: 设 ...
- 技术分享:如何用Solr搭建大数据查询平台
0×00 开头照例扯淡 自从各种脱裤门事件开始层出不穷,在下就学乖了,各个地方的密码全都改成不一样的,重要帐号的密码定期更换,生怕被人社出祖宗十八代的我,甚至开始用起了假名字,我给自己起一新网名”兴才 ...
- Spring Data:企业级Java的现代数据访问技术(影印版)
<Spring Data:企业级Java的现代数据访问技术(影印版)>基本信息原书名:Spring Data:Modern Data Access for Enterprise Java作 ...
- 数据库(学习整理)----4--Oracle数据查询(基础点1)
其他: 计算机中的内存是线性的,一维. length('')计算字符的个数,而不是字节的个数 Oracle中的日期类型和数值类型的数据可以做运算符(>,=,<,<>)比较 如果 ...
- 工作流activiti-03数据查询(流程定义 流程实例 代办任务) 以及个人小练习
在做数据查询的时候通过调用api来查询数据是相当的简单 对分页也进行了封装listPage(0, 4) ;listPage:分页查询 0:表示起始位置,4:表示查询长度 但是公司的框架封装了分页数据 ...
- JDBC在javaweb中的应用之分页数据查询
分页查询 分页查询是java web开发中经常使用到的技术.在数据库中数据量非常大的情况下,不适合将所有的数据全部显示到一个页面中,同时为了节约程序以及数据库的资源,就需要对数据进行分页查询操作. 通 ...
随机推荐
- 网页QQ弹出
<script language="javascript"> function cdyht(){ window.location.href='tencent://Mes ...
- SQLServer 错误: 15404,无法获取有关 Windows NT 组
右击-属性-所有者改成sa 测试一下 右击 --- 作业开始步骤---执行成功
- 给data设置数据
console.log(JSON.stringify(that.data.navigator[0].content) + "--____+" + JSON.stringify(th ...
- C#/.NET 学习之路——从入门到放弃
原文链接地址:http://blog.liuhaoyang.me/dotnet/2016/11/25/csharp-books/ 向架构师大步迈进的书单 C# 入门 <C# 本质论> &l ...
- TCP长连接保持连接状态TCP keepalive设置
如有转载,请注明出处:http://blog.csdn.net/embedded_sky/article/details/42077321 作者:super_bert@csdn 对于TCP长连接保活是 ...
- 自然语言交流系统 phxnet团队 创新实训 项目博客 (十)
关于本项目中使用到的庖丁分词的总结: Paoding 详细介绍 庖丁中文分词库是一个使用Java开发的,可结合到Lucene应用中的,为互联网.企业内部网使用的中文搜索引擎分词组件.Paodi ...
- android wifi RSSI达到阈值自动断开
设置wifi的RSSI达到阈值之后自动断开. wifi状态改变,会更新状态栏,在状态栏中更改. --- a/packages/SystemUI/src/com/android/systemui/sta ...
- swing包含了各种组件的类
javax.swing 最常用的pachage,包含了各种swing组件的类 javax.swing.border 包含与swing组件外框有关的类 javax..swing.colorchooser ...
- Xianfeng轻量级Java中间件平台:权限管理
权限管理:是通过系统对用户的行为进行控制的一套业务规则,可以做得很简单,比如通过硬编码的方式进行控制,也可以做得很复杂,比如通过一些复杂的权限模型去实现一些复杂的权限控制,比如菜单访问权限.按钮操作权 ...
- 联想服务器X3650 M2 配置 RAID5 + 热备盘
实验环境: 1. 服务器型号联想 System X3650 M2 2. 六块300G SAS硬盘 实验目的: 配置RAID 5 ,搭建重要文件备份服务器. 标注:本教程六块硬盘,其中五块硬盘做R ...