【机器学习】主成分分析PCA(Principal components analysis)
1. 问题
真实的训练数据总是存在各种各样的问题:
1、 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余。
2、 拿到一个数学系的本科生期末考试成绩单,里面有三列,一列是对数学的兴趣程度,一列是复习时间,还有一列是考试成绩。我们知道要学好数学,需要有浓厚的兴趣,所以第二项与第一项强相关,第三项和第二项也是强相关。那是不是可以合并第一项和第二项呢?
3、 拿到一个样本,特征非常多,而样例特别少,这样用回归去直接拟合非常困难,容易过度拟合。比如北京的房价:假设房子的特征是(大小、位置、朝向、是否学区房、建造
年代、是否二手、层数、所在层数),搞了这么多特征,结果只有不到十个房子的样例。要拟合房子特征‐>房价的这么多特征,就会造成过度拟合。
4、 这个与第二个有点类似,假设在 IR 中我们建立的文档‐词项矩阵中,有两个词项为“learn”和“study”,在传统的向量空间模型中,认为两者独立。然而从语义的角度来讲,两者是相似的,而且两者出现频率也类似,是不是可以合成为一个特征呢?
5、 在信号传输过程中,由于信道不是理想的,信道另一端收到的信号会有噪音扰动,那么怎么滤去这些噪音呢?
回顾我们之前介绍的《模型选择和规则化》,里面谈到的特征选择的问题。但在那篇中要剔除的特征主要是和类标签无关的特征。比如“学生的名字”就和他的“成绩”无关,使用的是互信息的方法。
而这里的特征很多是和类标签有关的,但里面存在噪声或者冗余。在这种情况下,需要一种特征降维的方法来减少特征数,减少噪音和冗余,减少过度拟合的可能性。
下面探讨一种称作主成分分析(PCA)的方法来解决部分上述问题。 PCA 的思想是将 n维特征映射到 k 维上(k<n),这 k 维是全新的正交特征。这 k 维特征称为主元,是重新构造出来的 k 维特征,而不是简单地从 n 维特征中去除其余 n‐k 维特征。
2. PCA 计算过程
整个 PCA 过程貌似及其简单,就是求协方差的特征值和特征向量,然后做数据转换。


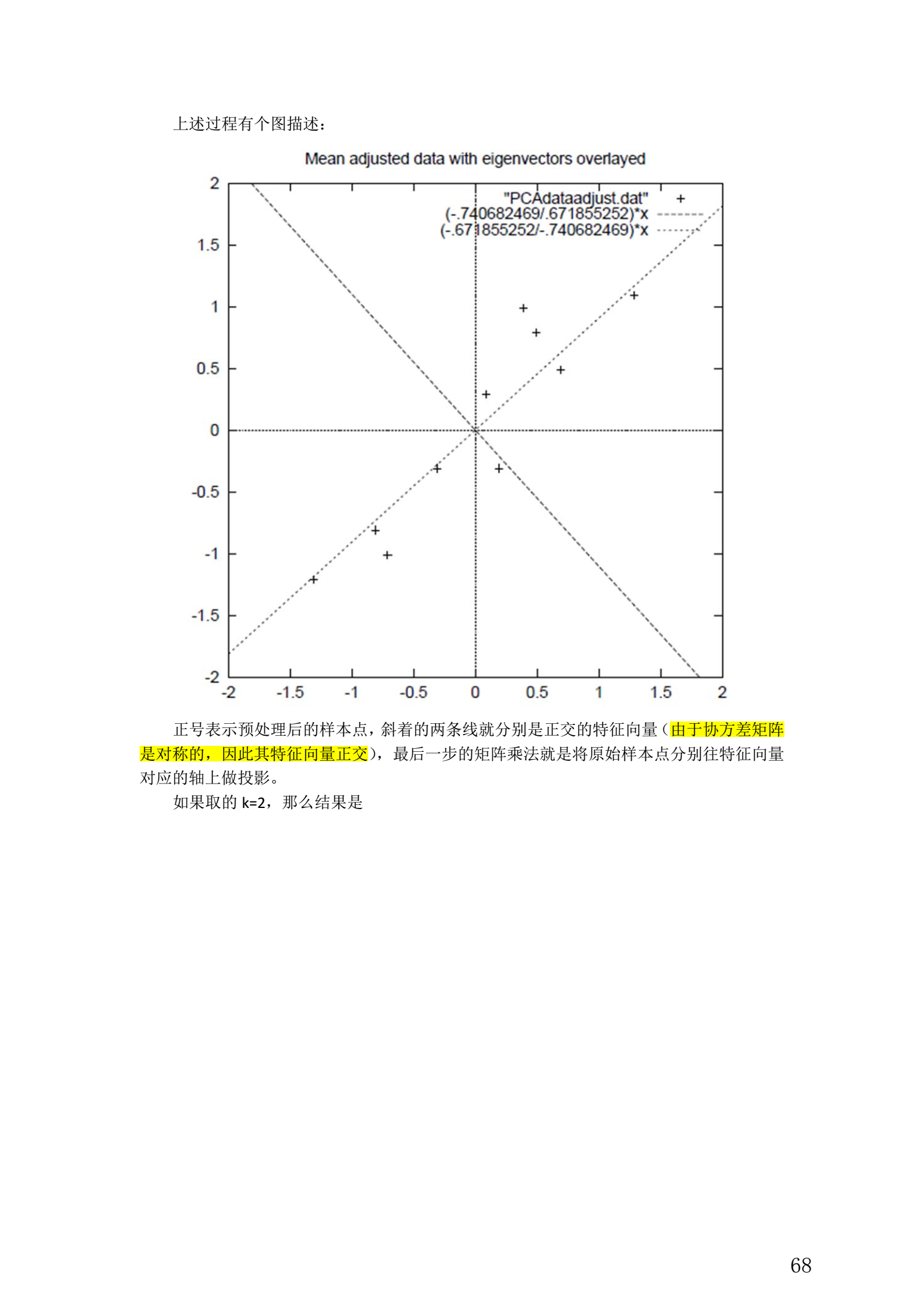
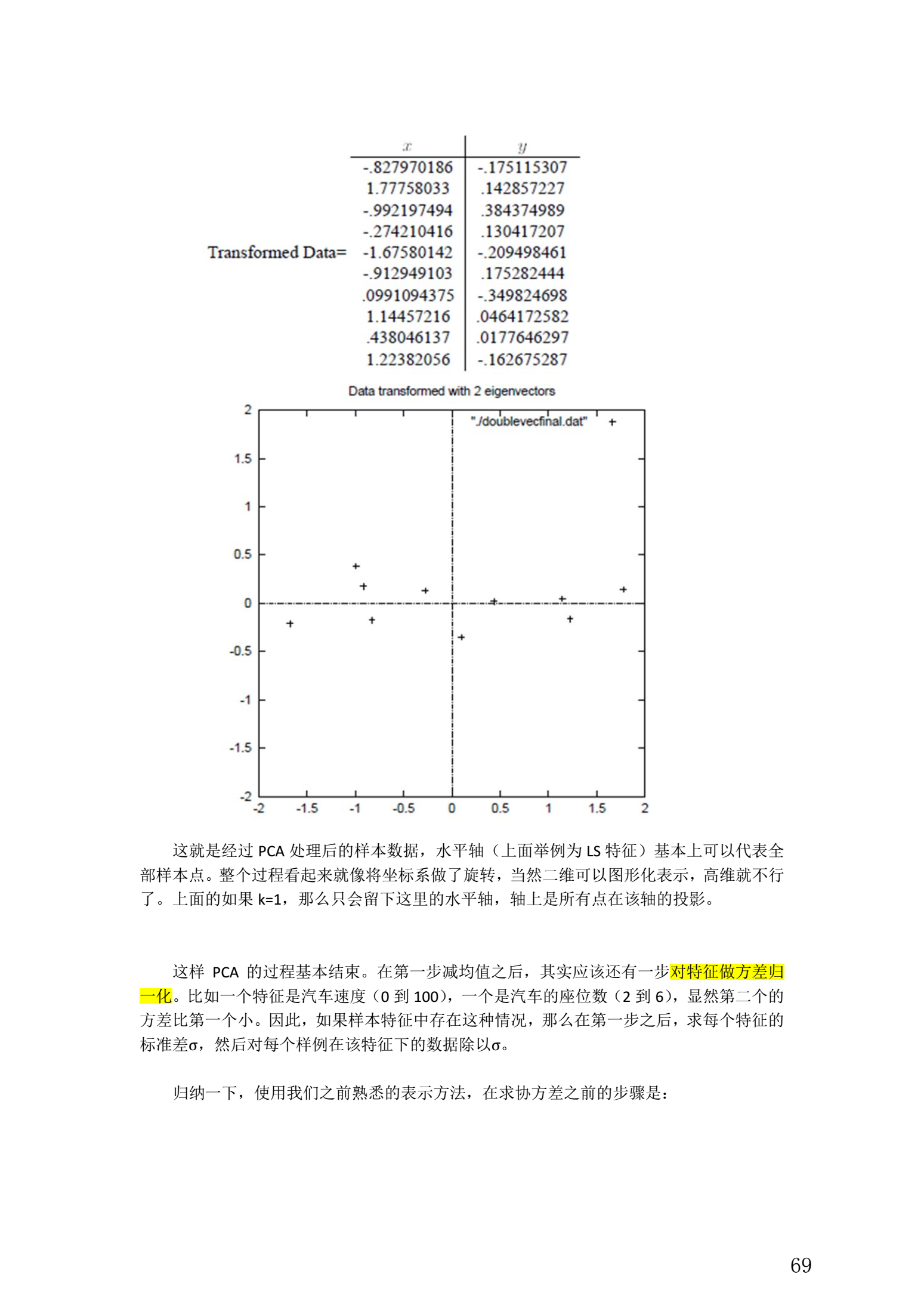

5. 总结与讨论
- PCA 技术的一大好处是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
- PCA 技术的一个很大的优点是,它是完全无参数限制的。在 PCA 的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
- 但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
- 在非高斯分布的情况下, PCA方法得出的主元可能并不是最优的
- 另外 PCA 还可以用于预测矩阵中缺失的元素
【机器学习】主成分分析PCA(Principal components analysis)的更多相关文章
- 主成分分析(principal components analysis, PCA)
原理 计算方法 主要性质 有关统计量 主成分个数的选取 ------------------------------------------------------------------------ ...
- 主成分分析(principal components analysis, PCA)——无监督学习
降维的两种方式: (1)特征选择(feature selection),通过变量选择来缩减维数. (2)特征提取(feature extraction),通过线性或非线性变换(投影)来生成缩减集(复合 ...
- Stat2—主成分分析(Principal components analysis)
最近在猛撸<R in nutshell>这本课,统计部分涉及的第一个分析数据的方法便是PCA!因此,今天打算好好梳理一下,涉及主城分析法的理论以及R实现!come on…gogogo… 首 ...
- 主成分分析(Principal components analysis)-最大方差解释
原文:http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html 在这一篇之前的内容是<Factor Analysis> ...
- R: 主成分分析 ~ PCA(Principal Component Analysis)
本文摘自:http://www.cnblogs.com/longzhongren/p/4300593.html 以表感谢. 综述: 主成分分析 因子分析 典型相关分析,三种方法的共同点主要是用来对数据 ...
- PCA 主成分分析(Principal components analysis )
问题 1. 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余. 2. 拿到一个数学系的本科生期末考试成绩单,里面有三列, ...
- PCA(Principal Components Analysis)主成分分析
全是图片..新手伤不起.word弄的,结果csdn传不了..以后改. .
- <转>主成分分析(Principal components analysis)-最大方差解释,最小平方差解释
转自http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html http://www.cnblogs.com/jerrylead/ ...
- Andrew Ng机器学习公开课笔记–Principal Components Analysis (PCA)
网易公开课,第14, 15课 notes,10 之前谈到的factor analysis,用EM算法找到潜在的因子变量,以达到降维的目的 这里介绍的是另外一种降维的方法,Principal Compo ...
- 主成分分析 | Principal Components Analysis | PCA
理论 仅仅使用基本的线性代数知识,就可以推导出一种简单的机器学习算法,主成分分析(Principal Components Analysis, PCA). 假设有 $m$ 个点的集合:$\left\{ ...
随机推荐
- Instagram/IGListKit 实践谈(UICollectionView框架)
简单介绍 IGListKit是Instagram推出的新的UICollectionView框架,使用数据驱动,旨在创造一个更快更灵活的列表控件. github地址:https://github.com ...
- 自动化部署必备技能—搭建YUM仓库
导言: YUM主要用于自动安装.升级rpm软件包,它能自动查找并解决rpm包之间的依赖关系.要成功的使用YUM工具安装更新软件或系统,就需要有一个包含各种rpm软件包的repository(软件仓库) ...
- win8 应用商店程序使用SQLITE数据库
http://www.cnblogs.com/zhuzhenyu/archive/2012/11/27/2790193.html using SQLite; using System; using S ...
- git server 搭建指南
搭建git服务器的经验总结 一: Server端的设置 1. 安装 git, git-core 2. 安装 ssh-server. (代码上传通道) 3. 创建git 用户 指定其目录 和所在组 4. ...
- win10 docker 安装部署
Docker 安装教程: https://blog.csdn.net/hunan961/article/details/79484098 安装docker前需要首先开启虚拟服务:重启电脑-->F ...
- android check box 自定义图片
http://blog.csdn.net/competerh_programing/article/details/7417074
- Nginx(六):Nginx HTTP负载均衡和反向代理的配置与优化
一.什么是负载均衡和反向代理 随着网站访问量的快速增长,单台服务器已经无法承担大量用户的并发访问,必须釆用多台服务器协同工作,以提高计算机系统的处理能力和计算强度,满足当前业务量的需求.而如何在完成同 ...
- 如何在Google Play商店发布多个版本apk
原文:http://android.eoe.cn/topic/android_sdk 多种apk的支持是一个特点在Google Play,它允许你发布不同的APKs为你的应用匹配不同尺寸的设备.每个A ...
- 在vultr中安装coreos
1.coreos必须使用key文件. 2.生成ssh key -C "your_email@mail.com" 3.拷贝ssh公钥文件内容.默认为id_rsa.pub 4.编辑vu ...
- 在Android Studio 和 Eclipse 的 git 插件操作 "代码提交"以及"代码冲突"
面向对象:曾经使用过SVN的同学. (因为Git 它 可以说是双重的SVN (本地一个服务器,远程一个服务器)),提交代码要有两次步骤,先提交到本地服务器,再把本地服务器在提交到远程服务器. 所以连S ...