YOLOv2-darknet 内容解析
YOLOv2-darknet 内容解析
1. 改进之处
YOLO v2受到faster rcnn的启发,引入了anchor。同时使用了K-Means方法,对anchor数量进行了讨论,在精度和速度之间做出折中。并且修改了网络结构,去掉了全连接层,改成了全卷积结构。在训练时引入了世界树(WordTree)结构,将检测和分类问题做成了一个统一的框架,并且提出了一种层次性联合训练方法,将ImageNet分类数据集和COCO检测数据集同时对模型训练。
- 使用一系列的方法对YOLO进行了改进,在保持原有速度的同时提升精度得到YOLOv2。
- 提出了一种目标分类与检测的联合训练方法,同时在COCO和ImageNet数据集中进行训练得到YOLO9000,实现9000多种物体的实时检测。
- 文章主要从better,Faster,Stronger三个角度讲述
2. Better
使用Batch normalization
神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度。
解决办法之一是对数据都要做一个归一化预处理。YOLOv2网络通过在每一个卷积层后添加batch normalization,极大的改善了收敛速度同时减少了对其它regularization方法的依赖(舍弃了dropout(一种常用的过拟合处理方法)优化后依然没有过拟合),使得mAP获得了2%的提升。
高分辨率
所有state-of-the-art的检测方法基本上都会使用ImageNet预训练过的模型(classifier)来提取特征,例如AlexNet输入图片会被resize到不足256 * 256,这导致分辨率不够高,给检测带来困难。所以YOLO(v1)先以分辨率224*224训练分类网络,然后需要增加分辨率到448*448,这样做不仅切换为检测算法也改变了分辨率。所以作者想能不能在预训练的时候就把分辨率提高了,训练的时候只是由分类算法切换为检测算法。
YOLOv2首先修改预训练分类网络的分辨率为448*448,在ImageNet数据集上训练10轮(10 epochs)。这个过程让网络有足够的时间调整filter去适应高分辨率的输入。然后fine tune为检测网络。mAP获得了4%的提升。
引入anchor Box
YOLO(v1)使用全连接层数据进行bounding box预测(要把1470*1的全链接层reshape为7*7*30的最终特征),这会丢失较多的空间信息定位不准。YOLOv2借鉴了Faster R-CNN中的anchor思想: 简单理解为卷积特征图上进行滑窗采样,每个中心预测9种不同大小和比例的建议框。由于都是卷积不需要reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个cell一一对应。而且用预测相对偏移(offset)取代直接预测坐标简化了问题,方便网络学习。
具体做法:
去掉最后的池化层确保输出的卷积特征图有更高的分辨率。
缩减网络,让图片输入分辨率为416 * 416,目的是让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。因为作者观察到,大物体通常占据了图像的中间位置,可以只用一个中心的cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测,这个技巧可稍稍提升效率。
使用卷积层降采样(factor 为32),使得输入卷积网络的416 * 416图片最终得到13 * 13的卷积特征图(416/32=13)。
把预测类别的机制从空间位置(cell)中解耦,由anchor box同时预测类别和坐标。因为YOLO是由每个cell来负责预测类别,每个cell对应的2个bounding box 负责预测坐标(回想YOLO中 最后输出7*7*30的特征,每个cell对应1*1*30,前10个主要是2个bounding box用来预测坐标,后20个表示该cell在假设包含物体的条件下属于20个类别的概率,具体请参考 图解YOLO 的图示) 。YOLOv2中,不再让类别的预测与每个cell(空间位置)绑定一起,而是让全部放到anchor box中。下面是特征维度示意图(仅作示意并非完全正确)
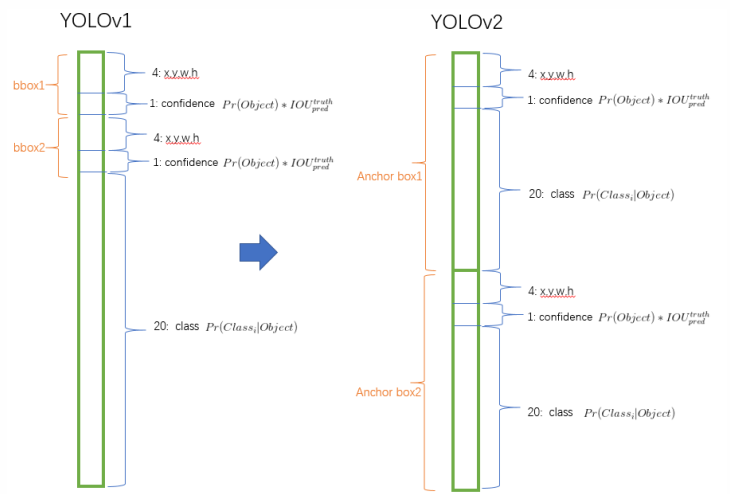
加入了anchor boxes后,可以预料到的结果是召回率上升,准确率下降。我们来计算一下,假设每个cell预测9个建议框,那么总共会预测13 * 13 * 9 = 1521个boxes,而之前的网络仅仅预测7 * 7 * 2 = 98个boxes。具体数据为:没有anchor boxes,模型recall为81%,mAP为69.5%;加入anchor boxes,模型recall为88%,mAP为69.2%。这样看来,准确率只有小幅度的下降,而召回率则提升了7%,说明可以通过进一步的工作来加强准确率,的确有改进空间。
Dimension Clusters(维度聚类)
K-means聚类方法,通过对数据集中的ground true box做聚类,找到ground true box的统计规律。以聚类个数k为anchor boxs个数,以k个聚类中心box的宽高维度为anchor box的维度。
如果按照标准k-means使用欧式距离函数,大boxes比小boxes产生更多error。但是,我们真正想要的是产生好的IOU得分的boxes(与box的大小无关)。因此采用了如下距离度量:
\[
d(box,centroid)=1-IOU(box,centroid)
\]直接坐标预测
使用anchor boxes的另一个问题是模型不稳定,尤其是在早期迭代的时候。大部分的不稳定现象出现在预测box的(x,y)坐标时。
在区域建议网络(RPN)中会预测坐标就是预测tx,ty。对应的中心点(x,y)按如下公式计算:
\[
x=(t_x\times w_a)+x_a\\
y=(t_y\times h_a)+y_a\\
\]
这个公式没有任何限制,无论在什么位置进行预测,任何anchor boxes可以在图像中任意一点。模型随机初始化之后将需要很长一段时间才能稳定预测敏感的物体偏移。因此作者没有采用这种方法,而是预测相对于grid cell的坐标位置,同时把ground truth限制在0到1之间(利用logistic激活函数约束网络的预测值来达到此限制)。
最终,网络在特征图(13 *13 )的每个cell上预测5个bounding boxes,每一个bounding box预测5个坐标值:tx,ty,tw,th,to。如果这个cell距离图像左上角的边距为(cx,cy)以及该cell对应的box维度(bounding box prior)的长和宽分别为(pw,ph),那么对应的box为:
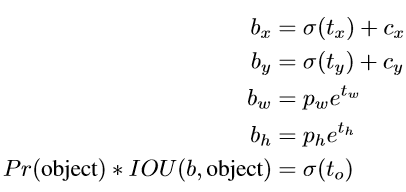
细粒度特征
修改后的网络最终在13 * 13的特征图上进行预测,虽然这足以胜任大尺度物体的检测,如果用上细粒度特征的话可能对小尺度的物体检测有帮助。Faser R-CNN和SSD都在不同层次的特征图上产生区域建议以获得多尺度的适应性。YOLOv2使用了一种不同的方法,简单添加一个 passthrough layer,把浅层特征图(分辨率为26 * 26)连接到深层特征图。
passthroughlaye把高低分辨率的特征图做连结,叠加相邻特征到不同通道(而非空间位置),类似于Resnet中的identity mappings。这个方法把26 * 26 * 512的特征图叠加成13 * 13 * 2048的特征图,与原生的深层特征图相连接。
YOLOv2的检测器使用的就是经过扩展后的的特征图,它可以使用细粒度特征,使得模型的性能获得了1%的提升。
多尺度训练
不同于固定网络输入图片尺寸的方法,每经过10批训练(10 batches)就会随机选择新的图片尺寸。网络使用的降采样参数为32,于是使用32的倍数{320,352,…,608},最小的尺寸为320 * 320,最大的尺寸为608 * 608。 调整网络到相应维度然后继续进行训练。
这种机制使得网络可以更好地预测不同尺寸的图片,同一个网络可以进行不同分辨率的检测任务,在小尺寸图片上YOLOv2运行更快,在速度和精度上达到了平衡。
3. Faster
YOLO使用的是基于Googlenet的自定制网络,比VGG-16更快,一次前向传播仅需85.2亿次运算,不过它的精度要略低于VGG-16。224 * 224图片取 single-crop, top-5 accuracy,YOLO的定制网络得到88%(VGG-16得到90%)。
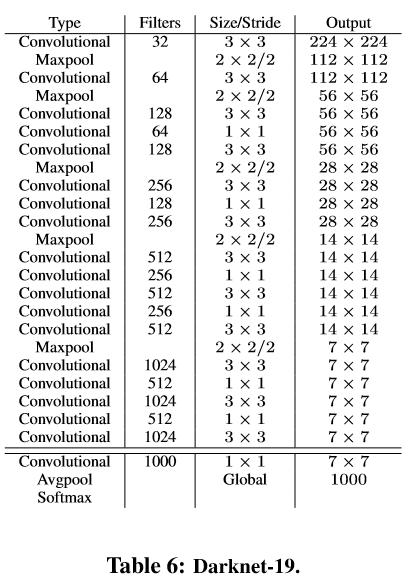
Darknet-19
YOLOv2使用了一个新的分类网络作为特征提取部分,参考了前人的工作经验。类似于VGG,网络使用了较多的3 * 3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,网络使用了全局平均池化(global average pooling)做预测,把1 * 1的卷积核置于3 * 3的卷积核之间,用来压缩特征。使用batch normalization稳定模型训练,加速收敛,正则化模型。
最终得出的基础模型就是Darknet-19,包含19个卷积层、5个最大值池化层(max pooling layers )。Darknet-19处理一张照片需要55.8亿次运算,imagenet的top-1准确率为72.9%,top-5准确率为91.2%。
Training for classification
作者使用Darknet-19在标准1000类的ImageNet上训练了160次,用随机梯度下降法,starting learning rate 为0.1,polynomial rate decay 为4,weight decay为0.0005 ,momentum 为0.9。训练的时候仍然使用了很多常见的数据扩充方法(data augmentation),包括random crops, rotations, and hue, saturation, and exposure shifts。(参数都是基于作者的darknet框架)
初始的224 * 224训练后把分辨率上调到了448 * 448,使用同样的参数又训练了10次,学习率调整到了\[ 10^{-3} \]。高分辨率下训练的分类网络top-1准确率76.5%,top-5准确率93.3%。
也添加了passthrough layer,从最后3 * 3 * 512的卷积层连到倒数第二层,使模型有了细粒度特征。
学习策略是:先以\(10^{-3}\)的初始学习率训练了160次,在第60次和第90次的时候学习率减为原来的十分之一。weight decay为0.0005,momentum为0.9,以及类似于Faster-RCNN和SSD的数据扩充(data augmentation)策略: random crops, color shifting, etc。使用相同的策略在 COCO 和VOC上训练。
4. Stronger
论文提出了一种联合训练的机制:使用识别数据集训练模型识别相关部分,使用分类数据集训练模型分类相关部分。
众多周知,检测数据集的标注要比分类数据集打标签繁琐的多,所以ImageNet分类数据集比VOC等检测数据集高出几个数量级。所以在YOLOv1中,边界框的预测其实并不依赖于物体的标签,YOLOv2实现了在分类和检测数据集上的联合训练。对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类,而对于分类数据集可以仅用来学习分类,但是其可以大大扩充模型所能检测的物体种类。
作者选择在COCO和ImageNet数据集上进行联合训练,遇到的第一问题是两者的类别并不是完全互斥的,比如"Norfolk terrier"明显属于"dog",所以作者提出了一种层级分类方法(Hierarchical classification),根据各个类别之间的从属关系(根据WordNet)建立一种树结构WordTree,结合COCO和ImageNet建立的词树(WordTree)
5. 总结
通过对YOLOv1网络结构和训练方法的改进,提出了YOLOv2/YOLO9000实时目标检测系统。YOLOv2在YOLOv1的基础上进行了一系列的改进,在快速的同时达到state of the art。同时,YOLOv2可以适应不同的输入尺寸,根据需要调整检测准确率和检测速度(值得参考)。作者综合了ImageNet数据集和COCO数据集,采用联合训练的方式训练,使该系统可以识别超过9000种物品。除此之外,作者提出的WordTree可以综合多种数据集的方法可以应用于其它计算机数觉任务中。但是对于重叠的分类,YOLOv2依然无法给出很好的解决方案。
reference
https://zhuanlan.zhihu.com/p/25167153
YOLOv2-darknet 内容解析的更多相关文章
- YOLOv3-darknet 内容解析
目录 Yolov3-darknet 内容解析 多标签分类预测 跨尺度预测 网络结构改变 reference Yolov3-darknet 内容解析 YOLOv3是到目前为止,速度和精度最均衡的目标检测 ...
- gradle相关配置内容解析
gradle 项目的构建工具,基于groovy语言.主要用于管理依赖包. as中一般将gradle下载在C:\Documents and Settings<用户名>.gradle\wrap ...
- Android 之内容提供者 内容解析者 内容观察者
contentProvider:ContentProvider在Android中的作用是对外提供数据,除了可以为所在应用提供数据外,还可以共享数据给其他应用,这是Android中解决应用之间数据共享的 ...
- YOLOv1-darknet 内容解析
目录 YOLOv1-darknet 内容解析 1. 核心思想 2. 特点 3. 缺点 4. 算法流程 5. 详细内容 6. 主要参考 YOLOv1-darknet 内容解析 1. 核心思想 目标检测分 ...
- JVM系列文章(三):Class文件内容解析
作为一个程序猿,只知道怎么用是远远不够的.起码,你须要知道为什么能够这么用.即我们所谓底层的东西. 那究竟什么是底层呢?我认为这不能一概而论.以我如今的知识水平而言:对于Web开发人员,TCP/IP. ...
- Web 前端性能优化相关内容解析
Web 前端性能优化相关内容,来源于<Google官方网页载入速度检测工具PageSpeed Insights 使用教程>一文中PageSpeed Insights 的相关说明.大家可以对 ...
- Web 前端性能优化相关内容解析[转]
Web 前端性能优化相关内容,来源于<Google官方网页载入速度检测工具PageSpeed Insights 使用教程>一文中PageSpeed Insights 的相关说明.大家可以对 ...
- 爬虫实战【6】Ajax内容解析-今日头条图集
Ajax技术 AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML). Ajax并不是新的编程语言,而是一种使用现有标准的新方法,当然 ...
- Lua string文件类型判断和内容解析
[1]文件名称类型判断和解析 local fileName = "shanxi201904npsdr1_200000.zip" print("len : " . ...
随机推荐
- python 面向对象 析构方法
实例化但从来没有调用他,就浪费了,就应该自动删除它 这个实例一直存在内存里 python有个垃圾自动回收机制 , 每段时间会自动刷新整个内存,把内存垃圾东西删除 析构函数: 在实例释放.销毁的时候 ...
- Linux Packages Search
网站 : https://www.pkgs.org/ https://centos.pkgs.org/
- 003-Nginx 设置Header 获取真实IP
1.X-Forwarded-For的定义: X-Forwarded-For:简称XFF头,它代表客户端,也就是HTTP的请求端真实的IP,只有在通过了HTTP 代理或者负载均衡服务器时才会添加该项.它 ...
- Vue.js - 概述
概述 Vue.js(读音 /vjuː/, 类似于 view)是一个构建数据驱动的 web 界面的库.Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件. Vue.js ...
- zkSNARK 零知识验证
参考文献 ZCash7篇,有社区翻译版,但还是推荐看原汁原味的 https://z.cash/blog/snark-explain.html Vitalik3篇,小天才作者我就不介绍了,这三篇 ...
- (转)Elasticsearch NoNodeAvailableException None of the configured nodes are available
问题背景:将es部署到内网中两台服务器,其Ip地址分别为:192.111.222.5,192.111.222.1(部署方式完全一样,是将192.111.222.1服务器上es整个部署包,拷贝到了192 ...
- C#webBrowser使用代理服务器的方法winform
其实在C#中使用webBrowser大家应该都会了,论坛也有很多相前的例子大家可以查询一下就知道了但是像直接使用浏览器一样设置代理 的方法可能很多人还不知道吧.这个其实是调用一个Dll文件进行设置的, ...
- html02
复习:HTML标记 p h1~h6 font table>tr>td ul>li ol>li div span form:input>typy :password rad ...
- zookeeper 安装以及集群搭建
安装环境: jdk1.7 zookeeper-3.4.10.tar.gz VM虚拟机redhat6.5-x64:192.168.1.200 192.168.1.201 192.168.1.202 ...
- Java内存管理(一):深入Java内存区域
本文转自:http://www.cnblogs.com/gw811/archive/2012/10/18/2730117.html#undefined 推荐查看原文,原文格式更好一些. 本文引用自:深 ...