PostgreSQL逻辑复制之slony篇
Slony是PostgreSQL领域中最广泛的复制解决方案之一。它不仅是最古老的复制实现之一,它也是一个拥有最广泛的外部工具支持的工具,比如pgAdmin3。多年来,Slony是在PostgreSQL中复制数据的惟一可行的解决方案。Slony使用逻辑复制;Slony-I一般要求表有主键,或者唯一键;Slony的工作不是基于PostgreSQL事务日志的;而是基于触发器的;基于逻辑复制高可用性;PostgreSQL除了slony;还有Londiste,BDR等等后续文章会讲到
1. 安装Slony
下载地址:http://www.slony.info;安装步骤:
# tar -jxvf slony1-2.2.5.tar.bz2
# cd slony1-2.2.5
# ./configure --with-pgconfigdir=/opt/pgsql96/bin
# make
# make install
安装完成!
执行./configure时;会在当前目录是否可以找到pg_config命令;本例pg_config在/opt/pgsql96/bin目录下;
2. Slony架构图
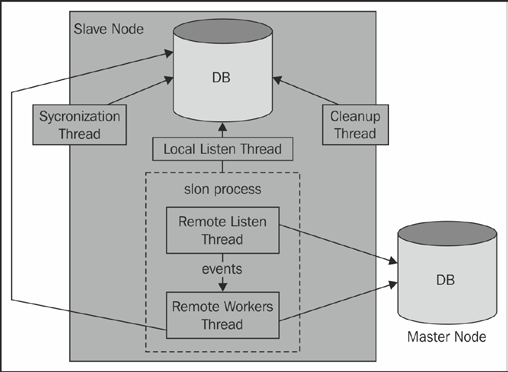
3. 复制表
现有实验环境:
| 主机名 | IP | 角色 |
| PostgreSQL201 | 192.168.1.201 | master |
| PostgreSQL202 | 192.168.1.202 | slave |
3.1 在两台数据库中都创建一个slony的超级用户;专为slony服务
create user slony superuser password 'li0924';
3.2 本实验两台主机都有lottu数据库;以lottu数据库中的表作为实验对象;在两个数据库中以相同的方式创建该表synctab,因为表结构不会自动复制。
create table synctab(id int primary key,name text);
3.3 在所有节点设置允许Slony-I用户远程登录;在pg_hba.conf文件添加
host all slony 192.168.1.0/24 trust
3.4 设置slony(在master主机操作)
编写一个slonik脚本用于注册这些节点的脚本如下所示:
[postgres@Postgres201 ~]$ cat slony_setup.sh
#!/bin/sh
MASTERDB=lottu
SLAVEDB=lottu
HOST1=192.168.1.201
HOST2=192.168.1.202
DBUSER=slony
slonik<<_EOF_
cluster name = first_cluster;
# define nodes (this is needed by pretty much
# all slonik scripts)
node admin conninfo = 'dbname=$MASTERDB host=$HOST1 user=$DBUSER';
node admin conninfo = 'dbname=$SLAVEDB host=$HOST2 user=$DBUSER';
# init cluster
init cluster ( id=, comment = 'Master Node');
# group tables into sets
create set (id=, origin=, comment='Our tables');
set add table (set id=, origin=, id=, fully qualified name = 'lottu.synctab', comment='sample table');
store node (id=, comment = 'Slave node', event node=);
store path (server = , client = , conninfo='dbname=$MASTERDB host=$HOST1 user=$DBUSER');
store path (server = , client = , conninfo='dbname=$SLAVEDB host=$HOST2 user=$DBUSER');
_EOF_
现在这个表在Slony的控制下,我们可以开始订阅脚本如下所示:
[postgres@Postgres201 ~]$ cat slony_subscribe.sh
#!/bin/sh
MASTERDB=lottu
SLAVEDB=lottu
HOST1=192.168.1.201
HOST2=192.168.1.202
DBUSER=slony
slonik<<_EOF_
cluster name = first_cluster;
node admin conninfo = 'dbname=$MASTERDB host=$HOST1 user=$DBUSER';
node admin conninfo = 'dbname=$SLAVEDB host=$HOST2 user=$DBUSER';
subscribe set ( id = , provider = , receiver = , forward = no);
_EOF_
在master主机执行脚本
[postgres@Postgres201 ~]$ ./slony_setup.sh
[postgres@Postgres201 ~]$ ./slony_subscribe.sh &
[]
定义了我们想要复制的东西之后,我们可以在每台主机启动slon守护进程
slon first_cluster 'host=192.168.1.201 dbname=lottu user=slony' &
slon first_cluster 'host=192.168.1.202 dbname=lottu user=slony' &
3.5 验证slony-I是否配置成功?
在master主机执行dml操作
[postgres@Postgres201 ~]$ psql lottu lottu
psql (9.6.0)
Type "help" for help. lottu=# \d synctab
Table "lottu.synctab"
Column | Type | Modifiers
--------+---------+-----------
id | integer | not null
name | text |
Indexes:
"synctab_pkey" PRIMARY KEY, btree (id)
Triggers:
_first_cluster_logtrigger AFTER INSERT OR DELETE OR UPDATE ON synctab FOR EACH ROW EXECUTE PROCEDURE _first_cluster.logtrigger('_first_cluster', '', 'k')
_first_cluster_truncatetrigger BEFORE TRUNCATE ON synctab FOR EACH STATEMENT EXECUTE PROCEDURE _first_cluster.log_truncate('')
Disabled user triggers:
_first_cluster_denyaccess BEFORE INSERT OR DELETE OR UPDATE ON synctab FOR EACH ROW EXECUTE PROCEDURE _first_cluster.denyaccess('_first_cluster')
_first_cluster_truncatedeny BEFORE TRUNCATE ON synctab FOR EACH STATEMENT EXECUTE PROCEDURE _first_cluster.deny_truncate() lottu=# insert into synctab values (1001,'lottu');
INSERT 0 1
在slave主机查看是否对应变化
[postgres@Postgres202 ~]$ psql
psql (9.6.0)
Type "help" for help. postgres=# \c lottu lottu
You are now connected to database "lottu" as user "lottu".
lottu=> select * from synctab ;
id | name
------+-------
1001 | lottu
(1 row)
4. Slony-I相关表或者视图查看
4.1 配置成功;会在所在的数据库中生成一个schema
[postgres@Postgres201 ~]$ psql lottu lottu
psql (9.6.0)
Type "help" for help. lottu=# \dn
List of schemas
Name | Owner
----------------+----------
_first_cluster | slony
lottu | lottu
public | postgres
(3 rows)
4.2 查看集群中的节点信息
lottu=# select * from _first_cluster.sl_node;
no_id | no_active | no_comment | no_failed
-------+-----------+-------------+-----------
1 | t | Master Node | f
2 | t | Slave node | f
(2 rows)
4.3 查看集群中的集合信息
lottu=# select * from _first_cluster.sl_set;
set_id | set_origin | set_locked | set_comment
--------+------------+------------+-------------
1 | 1 | | Our tables
(1 row)
4.4 查看集群中的表信息
lottu=# select * from _first_cluster.sl_table;
-[ RECORD 1 ]-------------
tab_id | 1
tab_reloid | 57420
tab_relname | synctab
tab_nspname | lottu
tab_set | 1
tab_idxname | synctab_pkey
tab_altered | f
tab_comment | sample table
5. 日常维护
5.1 Slony-I向现有集群中增加一个复制表
以表synctab2为例:
create table synctab2(id int primary key,name text,reg_time timestamp);
我们要创建一个新的表格集;脚本是这样的
[postgres@Postgres201 ~]$ cat slony_add_table_set.sh
#!/bin/sh
MASTERDB=lottu
SLAVEDB=lottu
HOST1=192.168.1.201
HOST2=192.168.1.202
DBUSER=slony
slonik<<_EOF_
cluster name = first_cluster;
node admin conninfo = 'dbname=$MASTERDB host=$HOST1 user=$DBUSER';
node admin conninfo = 'dbname=$SLAVEDB host=$HOST2 user=$DBUSER';
create set (id=, origin=, comment='a second replication set');
set add table (set id=, origin=, id=, fully qualified name ='lottu.synctab2', comment='second table');
subscribe set(id=, provider=,receiver=);
subscribe set(id=, provider=,receiver=);
merge set(id=, add id=,origin=);
_EOF_
执行slony_add_table_set.sh脚本
[postgres@Postgres201 ~]$ ./slony_add_table_set.sh
<stdin>: subscription in progress before mergeSet. waiting
<stdin>: subscription in progress before mergeSet. waiting
查看是否添加成功
lottu=# select * from _first_cluster.sl_table;
-[ RECORD ]--------------
tab_id |
tab_reloid |
tab_relname | synctab
tab_nspname | lottu
tab_set |
tab_idxname | synctab_pkey
tab_altered | f
tab_comment | sample table
-[ RECORD ]--------------
tab_id |
tab_reloid |
tab_relname | synctab2
tab_nspname | lottu
tab_set |
tab_idxname | synctab2_pkey
tab_altered | f
tab_comment | second table
5.2 Slony-I向现有集群中删除一个复制表
[postgres@Postgres201 ~]$ cat slony_drop_table.sh
#!/bin/sh
MASTERDB=lottu
SLAVEDB=lottu
HOST1=192.168.1.201
HOST2=192.168.1.202
DBUSER=slony
slonik<<_EOF_
cluster name = first_cluster;
node admin conninfo = 'dbname=$MASTERDB host=$HOST1 user=$DBUSER';
node admin conninfo = 'dbname=$SLAVEDB host=$HOST2 user=$DBUSER';
set drop table (id=, origin=);
_EOF_
执行slony_drop_table.sh脚本
[postgres@Postgres201 ~]$ ./slony_drop_table.sh
查看是否删除成功
lottu=# select * from _first_cluster.sl_table;
tab_id | tab_reloid | tab_relname | tab_nspname | tab_set | tab_idxname | tab_altered | tab_comment
--------+------------+-------------+-------------+---------+--------------+-------------+--------------
1 | 57420 | synctab | lottu | 1 | synctab_pkey | f | sample table
(1 row)
5. 3删除slony
[postgres@Postgres201 ~]$ cat slony_drop_node.sh
#!/bin/sh
MASTERDB=lottu
SLAVEDB=lottu
HOST1=192.168.1.201
HOST2=192.168.1.202
DBUSER=slony
slonik<<_EOF_
cluster name = first_cluster;
node admin conninfo = 'dbname=$MASTERDB host=$HOST1 user=$DBUSER';
node admin conninfo = 'dbname=$SLAVEDB host=$HOST2 user=$DBUSER';
uninstall node (id = );
uninstall node (id = );
_EOF_
执行脚本如下:
[postgres@Postgres201 ~]$ ./slony_drop_node.sh
<stdin>:: NOTICE: Slony-I: Please drop schema "_first_cluster"
<stdin>:: NOTICE: drop cascades to other objects
DETAIL: drop cascades to table _first_cluster.sl_node
drop cascades to table _first_cluster.sl_nodelock
drop cascades to table _first_cluster.sl_set
drop cascades to table _first_cluster.sl_setsync
drop cascades to table _first_cluster.sl_table
drop cascades to table _first_cluster.sl_sequence
drop cascades to table _first_cluster.sl_path
drop cascades to table _first_cluster.sl_listen
drop cascades to table _first_cluster.sl_subscribe
drop cascades to table _first_cluster.sl_event
drop cascades to table _first_cluster.sl_confirm
drop cascades to table _first_cluster.sl_seqlog
drop cascades to function _first_cluster.sequencelastvalue(text)
drop cascades to table _first_cluster.sl_log_1
drop cascades to table _first_cluster.sl_log_2
drop cascades to table _first_cluster.sl_log_script
drop cascades to table _first_cluster.sl_registry
drop cascades to table _first_cluster.sl_apply_stats
drop cascades to view _first_cluster.sl_seqlastvalue
drop cascades to view _first_cluster.sl_failover_targets
drop cascades to sequence _first_cluster.sl_local_node_id
drop cascades to sequence _first_cluster.sl_event_seq
drop cascades to sequence _first_cluster.sl_action_seq
drop cascades to sequence _first_cluster.sl_log_status
drop cascades to table _first_cluster.sl_config_lock
drop cascades to table _first_cluster.sl_event_lock
drop cascades to table _first_cluster.sl_archive_counter
drop cascades to table _first_cluster.sl_components
drop cascades to type _first_cluster.vactables
drop cascades to function _first_cluster.createevent(name,text)
drop cascades to function _first_cluster.createevent(name,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text,text,text,text,text)
drop cascades to function _first_cluster.denyaccess()
drop cascades to trigger _first_cluster_denyaccess on table lottu.synctab
drop cascades to function _first_cluster.lockedset()
drop cascades to function _first_cluster.getlocalnodeid(name)
drop cascades to function _first_cluster.getmoduleversion()
drop cascades to function _first_cluster.resetsession()
drop cascades to function _first_cluster.logapply()
drop cascades to function _first_cluster.logapplysetcachesize(integer)
drop cascades to function _first_cluster.logapplysavestats(name,integer,interval)
drop cascades to function _first_cluster.checkmoduleversion()
drop cascades to function _first_cluster.decode_tgargs(bytea)
drop cascades to function _first_cluster.logtrigger()
drop cascades to trigger _first_cluster_logtrigger on table lottu.synctab
drop cascades to function _first_cluster.terminatenodeconnections(integer)
drop cascades to function _first_cluster.killbackend(integer,text)
drop cascades to function _first_cluster.seqtrack(integer,bigint)
drop cascades to function _first_cluster.slon_quote_brute(text)
drop cascades to function _first_cluster.slon_quote_input(text)
drop cascades to function _first_cluster.slonyversionmajor()
drop cascades to function _first_cluster.slonyversionminor()
drop cascades to function _first_cluster.slonyversionpatchlevel()
drop cascades to function _first_cluster.slonyversion()
drop cascades to function _first_cluster.registry_set_int4(text,integer)
drop cascades to function _first_cluster.registry_get_int4(text,integer)
drop cascades to function _first_cluster.registry_set_text(text,text)
drop cascades to function _first_cluster.registry_get_text(text,text)
drop cascades to function _first_cluster.registry_set_timestamp(text,timestamp with time zone)
drop cascades to function _first_cluster.registry_get_timestamp(text,timestamp with time zone)
drop cascades to function _first_cluster.cleanupnodelock()
drop cascades to function _first_cluster.registernodeconnection(integer)
drop cascades to function _first_cluster.initializelocalnode(integer,text)
drop cascades to function _first_cluster.storenode(integer,text)
drop cascades to function _first_cluster.storenode_int(integer,text)
drop cascades to function _first_cluster.enablenode(integer)
drop cascades to function _first_cluster.enablenode_int(integer)
drop cascades to function _first_cluster.disablenode(integer)
drop cascades to function _first_cluster.disablenode_int(integer)
drop cascades to function _first_cluster.dropnode(integer[])
drop cascades to function _first_cluster.dropnode_int(integer)
drop cascades to function _first_cluster.prefailover(integer,boolean)
drop cascades to function _first_cluster.failednode(integer,integer,integer[])
drop cascades to function _first_cluster.failednode2(integer,integer,bigint,integer[])
drop cascades to function _first_cluster.failednode3(integer,integer,bigint)
drop cascades to function _first_cluster.failoverset_int(integer,integer,bigint)
drop cascades to function _first_cluster.uninstallnode()
drop cascades to function _first_cluster.clonenodeprepare(integer,integer,text)
drop cascades to function _first_cluster.clonenodeprepare_int(integer,integer,text)
drop cascades to function _first_cluster.clonenodefinish(integer,integer)
drop cascades to function _first_cluster.storepath(integer,integer,text,integer)
drop cascades to function _first_cluster.storepath_int(integer,integer,text,integer)
drop cascades to function _first_cluster.droppath(integer,integer)
drop cascades to function _first_cluster.droppath_int(integer,integer)
drop cascades to function _first_cluster.storelisten(integer,integer,integer)
drop cascades to function _first_cluster.storelisten_int(integer,integer,integer)
drop cascades to function _first_cluster.droplisten(integer,integer,integer)
drop cascades to function _first_cluster.droplisten_int(integer,integer,integer)
drop cascades to function _first_cluster.storeset(integer,text)
drop cascades to function _first_cluster.storeset_int(integer,integer,text)
drop cascades to function _first_cluster.lockset(integer)
drop cascades to function _first_cluster.unlockset(integer)
drop cascades to function _first_cluster.moveset(integer,integer)
drop cascades to function _first_cluster.moveset_int(integer,integer,integer,bigint)
and other objects (see server log for list)
<stdin>:: NOTICE: Slony-I: Please drop schema "_first_cluster"
<stdin>:: NOTICE: drop cascades to other objects
DETAIL: drop cascades to table _first_cluster.sl_node
drop cascades to table _first_cluster.sl_nodelock
drop cascades to table _first_cluster.sl_set
drop cascades to table _first_cluster.sl_setsync
drop cascades to table _first_cluster.sl_table
drop cascades to table _first_cluster.sl_sequence
drop cascades to table _first_cluster.sl_path
drop cascades to table _first_cluster.sl_listen
drop cascades to table _first_cluster.sl_subscribe
drop cascades to table _first_cluster.sl_event
drop cascades to table _first_cluster.sl_confirm
drop cascades to table _first_cluster.sl_seqlog
drop cascades to function _first_cluster.sequencelastvalue(text)
drop cascades to table _first_cluster.sl_log_1
drop cascades to table _first_cluster.sl_log_2
drop cascades to table _first_cluster.sl_log_script
drop cascades to table _first_cluster.sl_registry
drop cascades to table _first_cluster.sl_apply_stats
drop cascades to view _first_cluster.sl_seqlastvalue
drop cascades to view _first_cluster.sl_failover_targets
drop cascades to sequence _first_cluster.sl_local_node_id
drop cascades to sequence _first_cluster.sl_event_seq
drop cascades to sequence _first_cluster.sl_action_seq
drop cascades to sequence _first_cluster.sl_log_status
drop cascades to table _first_cluster.sl_config_lock
drop cascades to table _first_cluster.sl_event_lock
drop cascades to table _first_cluster.sl_archive_counter
drop cascades to table _first_cluster.sl_components
drop cascades to type _first_cluster.vactables
drop cascades to function _first_cluster.createevent(name,text)
drop cascades to function _first_cluster.createevent(name,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text,text,text,text)
drop cascades to function _first_cluster.createevent(name,text,text,text,text,text,text,text,text,text)
drop cascades to function _first_cluster.denyaccess()
drop cascades to trigger _first_cluster_denyaccess on table lottu.synctab
drop cascades to function _first_cluster.lockedset()
drop cascades to function _first_cluster.getlocalnodeid(name)
drop cascades to function _first_cluster.getmoduleversion()
drop cascades to function _first_cluster.resetsession()
drop cascades to function _first_cluster.logapply()
drop cascades to function _first_cluster.logapplysetcachesize(integer)
drop cascades to function _first_cluster.logapplysavestats(name,integer,interval)
drop cascades to function _first_cluster.checkmoduleversion()
drop cascades to function _first_cluster.decode_tgargs(bytea)
drop cascades to function _first_cluster.logtrigger()
drop cascades to trigger _first_cluster_logtrigger on table lottu.synctab
drop cascades to function _first_cluster.terminatenodeconnections(integer)
drop cascades to function _first_cluster.killbackend(integer,text)
drop cascades to function _first_cluster.seqtrack(integer,bigint)
drop cascades to function _first_cluster.slon_quote_brute(text)
drop cascades to function _first_cluster.slon_quote_input(text)
drop cascades to function _first_cluster.slonyversionmajor()
drop cascades to function _first_cluster.slonyversionminor()
drop cascades to function _first_cluster.slonyversionpatchlevel()
drop cascades to function _first_cluster.slonyversion()
drop cascades to function _first_cluster.registry_set_int4(text,integer)
drop cascades to function _first_cluster.registry_get_int4(text,integer)
drop cascades to function _first_cluster.registry_set_text(text,text)
drop cascades to function _first_cluster.registry_get_text(text,text)
drop cascades to function _first_cluster.registry_set_timestamp(text,timestamp with time zone)
drop cascades to function _first_cluster.registry_get_timestamp(text,timestamp with time zone)
drop cascades to function _first_cluster.cleanupnodelock()
drop cascades to function _first_cluster.registernodeconnection(integer)
drop cascades to function _first_cluster.initializelocalnode(integer,text)
drop cascades to function _first_cluster.storenode(integer,text)
drop cascades to function _first_cluster.storenode_int(integer,text)
drop cascades to function _first_cluster.enablenode(integer)
drop cascades to function _first_cluster.enablenode_int(integer)
drop cascades to function _first_cluster.disablenode(integer)
drop cascades to function _first_cluster.disablenode_int(integer)
drop cascades to function _first_cluster.dropnode(integer[])
drop cascades to function _first_cluster.dropnode_int(integer)
drop cascades to function _first_cluster.prefailover(integer,boolean)
drop cascades to function _first_cluster.failednode(integer,integer,integer[])
drop cascades to function _first_cluster.failednode2(integer,integer,bigint,integer[])
drop cascades to function _first_cluster.failednode3(integer,integer,bigint)
drop cascades to function _first_cluster.failoverset_int(integer,integer,bigint)
drop cascades to function _first_cluster.uninstallnode()
drop cascades to function _first_cluster.clonenodeprepare(integer,integer,text)
drop cascades to function _first_cluster.clonenodeprepare_int(integer,integer,text)
drop cascades to function _first_cluster.clonenodefinish(integer,integer)
drop cascades to function _first_cluster.storepath(integer,integer,text,integer)
drop cascades to function _first_cluster.storepath_int(integer,integer,text,integer)
drop cascades to function _first_cluster.droppath(integer,integer)
drop cascades to function _first_cluster.droppath_int(integer,integer)
drop cascades to function _first_cluster.storelisten(integer,integer,integer)
drop cascades to function _first_cluster.storelisten_int(integer,integer,integer)
drop cascades to function _first_cluster.droplisten(integer,integer,integer)
drop cascades to function _first_cluster.droplisten_int(integer,integer,integer)
drop cascades to function _first_cluster.storeset(integer,text)
drop cascades to function _first_cluster.storeset_int(integer,integer,text)
drop cascades to function _first_cluster.lockset(integer)
drop cascades to function _first_cluster.unlockset(integer)
drop cascades to function _first_cluster.moveset(integer,integer)
drop cascades to function _first_cluster.moveset_int(integer,integer,integer,bigint)
and other objects (see server log for list)
完美;一切归零!
查考文献
https://www.cnblogs.com/ilifeilong/p/7009322.html
https://www.cnblogs.com/gaojian/p/3196244.html
PostgreSQL逻辑复制之slony篇的更多相关文章
- PostgreSQL逻辑复制之pglogical篇
PostgreSQL逻辑复制之slony篇 一.pglogical介绍 pglogical 是 PostgreSQL 的拓展模块, 为 PostgreSQL 数据库提供了逻辑流复制发布和订阅的功能. ...
- PostgreSQL逻辑复制使用记录
之前逻辑复制刚刚出来的时候就使用过,但是没有进行整理,这次一个项目需要逻辑复制的自动迁移,再次拾起逻辑复制. 在此之前有两个疑问: 1)同一个表,既有流复制,又有逻辑复制,这样数据会有两份吗? --不 ...
- Windows 环境搭建 PostgreSQL 逻辑复制高可用架构数据库服务
本文主要介绍 Windows 环境下搭建 PostgreSQL 的主从逻辑复制,关于 PostgreSQl 的相关运维文章,网络上大多都是 Linux 环境下的操作,鲜有在 Windows 环境下配置 ...
- PostgreSQL逻辑复制解密
在数字化时代的今天,我们都认同数据会创造价值.为了最大化数据的价值,我们不停的建立着数据迁移的管道,从同构到异构,从关系型到非关系型,从云下到云上,从数仓到数据湖,试图在各种场景挖掘数据的价值.而在这 ...
- PostgreSQL逻辑复制槽
Schema | Name | Result data type | Argument data types | Type ------------+------------------------- ...
- PostgreSQL逻辑复制到kafka-实践
kafka 安装 wget http://mirror.bit.edu.cn/apache/kafka/2.3.0/kafka_2.12-2.3.0.tgz cp kafka_2.12-2.0.1.t ...
- Windows 环境搭建 PostgreSQL 物理复制高可用架构数据库服务
PostgreSQL 高可用数据库的常见搭建方式主要有两种,逻辑复制和物理复制,上周已经写过了关于在Windows环境搭建PostgreSQL逻辑复制的教程,这周来记录一下 物理复制的搭建方法. 首先 ...
- postgresql从库搭建--逻辑复制
1 物理复制及逻辑复制对比 前文做了PostgreSQL物理复制的部署,其有如下主要优点 物理层面完全一致,是主要的复制方式,其类似于Oracle的DG 延迟低,事务执行过程中产生REDO recor ...
- 跨 PostgreSQL 大版本复制怎么做?| 逻辑复制
当需要升级PostgreSQL时,可以使用多种方法.为了避免应用程序停机,不是所有升级postgres的方法都适合,如果避免停机是必须的,那么可以考虑使用复制作为升级方法,并且根据方案,可以选择使用逻 ...
随机推荐
- SwipeBackLayout侧滑返回显示桌面
SwipeBackLayout是一个很好的类库,它可以让Android实现类似iOS系统的右滑返回效果,但是很多用户在使用官方提供的Demo会发现,可能出现黑屏或者返回只是看到桌面背景而没有看到上一个 ...
- linux 卸载mysql
RPM包安装方式的MySQL卸载 1: 检查是否安装了MySQL组件. [root@DB-Server init.d]# rpm -qa | grep -i mysql MySQL-devel-5 ...
- r语言 load Rdata 获取表名 并直接转为数据表
首先指定 load结果为一个对象 然后此对象的值 即为 str的 数据表名 然后使用 eval(parse(text = l)) 两个函数 将字符串 转可执行对象 即可完成重新赋值 > l & ...
- 关于Unity中的本地存储
本地存储 在做游戏的时候,经常需要在本机存储一些数据,比如闯关类游戏要记录闯到第几关,做单机的时候要把数据保存到本地,下次启动的时候数据存在,就是把数据保存到磁盘里面或者手机的flash闪存里面. U ...
- python 进行后端分页详细代码
后端分页 两个接口 思路: 1. 先得到最大页和最小页数(1, 20) --> 传递给前端, 这样前端就可以知道有多少个页数 2. 通过传递页数得到当前页对应数据库的最大值和最小值 3. 通过s ...
- [转载]在澳洲做IT人士的收入差别
澳洲跟中国一样高税收,但最大的好处是,福利返还很多:1.如果家里有孩子,每2周会有各种税收福利,就是所谓的family tax benefits (a/b):2.每财年结束还有退税:3.看病不用钱,因 ...
- C语言中内存分配问题:
推荐: C语言中内存分配 Linux size命令和C程序的存储空间布局 本大神感觉,上面的链接的内容,已经很好的说明了: 总结一下: 对于一个可执行文件,在linux下可以使用 size命令列出目标 ...
- Java数组填充和初始化
Java中,如何填充(一次初始化)数组? 示例 此示例使用Java Util类的Array.fill(arrayname,value)方法和Array.fill(arrayname,starting ...
- python3两个字典的合并
两个字典的合并其实很简单,直接用dict的update即可,代码如下: # /usr/bin/python3 # -*- encoding: utf-8 -*- ", "" ...
- 学习Unity的步骤
作者:王选易链接:https://www.zhihu.com/question/23790314/answer/46815232来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...