Hadoop源码解析 1 --- Hadoop工程包架构解析
1 Hadoop中各工程包依赖简述 Google的核心竞争技术是它的计算平台。Google的大牛们用了下面5篇文章,介绍了它们的计算设施。 GoogleCluster: http://research.google.com/archive/googlecluster.html Chubby:http://labs.google.com/papers/chubby.html GFS:http://labs.google.com/papers/gfs.html BigTable:http://labs.google.com/papers/bigtable.html MapReduce:http://labs.google.com/papers/mapreduce.html 很快,Apache上就出现了一个类似的解决方案,目前它们都属于Apache的Hadoop项目,对应的分别是: Chubby-->ZooKeeper GFS-->HDFS BigTable-->HBase MapReduce-->Hadoop 目前,基于类似思想的Open Source项目还很多,如Facebook用于用户分析的Hive。 HDFS作为一个分布式文件系统,是所有这些项目的基础。分析好HDFS,有利于了解其他系统。由于Hadoop的HDFS和MapReduce是同一个项目,我们就把他们放在一块,进行分析。 Hadoop包之间的依赖关系比较复杂,原因是HDFS提供了一个分布式文件系统, 该系统提供API,可以屏蔽本地文件系统和分布式文件系统,甚至象Amazon S3这样的在线存储系统。这就造成了分布式文件系统的实现,或者是分布式 文件系统的底层的实现,依赖于某些貌似高层的功能。功能的相互引用,造成了蜘蛛网型的依赖关系。一个典型的例子就是包conf,conf用于读取系统配 置,它依赖于fs,主要是读取配置文件的时候,需要使用文件系统,而部分的文件系统的功能,在包fs中被抽象了。
2 Hadoop和Google分布式系统对应产品

3 Hadoop工程中各工程包依赖图示
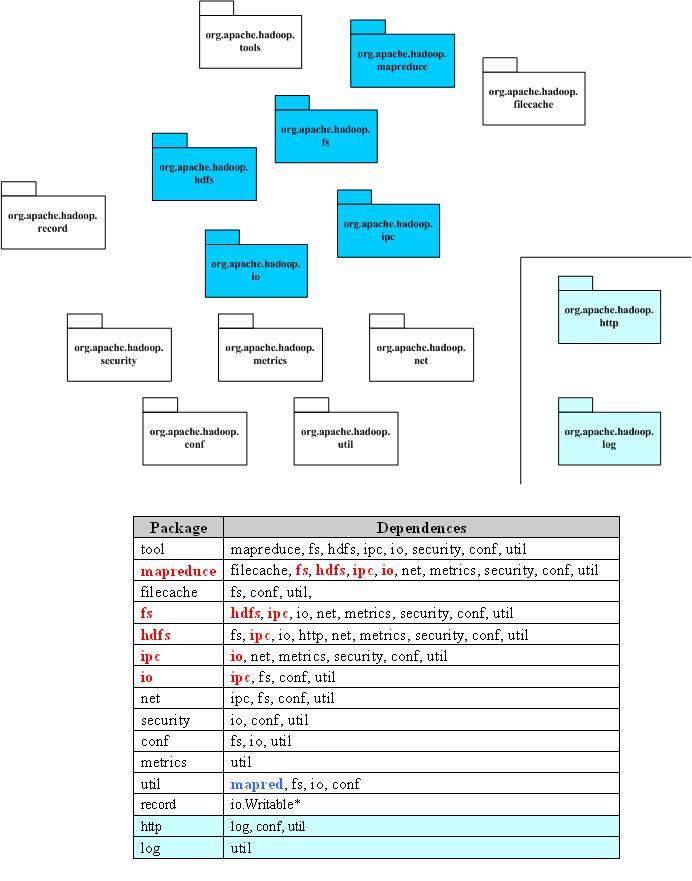
4 Hdoop工程中各工程包文件夹图示

5 各包功能
|
Package |
Dependences |
|
tool |
提供一些命令行工具,如DistCp,archive |
|
mapreduce |
Hadoop的Map/Reduce实现 |
|
filecache |
提供HDFS文件的本地缓存,用于加快Map/Reduce的数据访问速度 |
|
fs |
文件系统的抽象,可以理解为支持多种文件系统实现的统一文件访问接口 |
|
hdfs |
HDFS,Hadoop的分布式文件系统实现 |
|
ipc |
一个简单的IPC的实现,依赖于io提供的编解码功能 参考:http://zhangyu8374.iteye.com/blog/86306 |
|
io |
表示层。将各种数据编码/解码,方便于在网络上传输 |
|
net |
封装部分网络功能,如DNS,socket |
|
security |
用户和用户组信息 |
|
conf |
系统的配置参数 |
|
metrics |
系统统计数据的收集,属于网管范畴 |
|
util |
工具类 |
|
record |
根据DDL(数据描述语言)自动生成他们的编解码函数,目前可以提供C++和Java |
|
http |
基于Jetty的HTTP Servlet,用户通过浏览器可以观察文件系统的一些状态信息和日志 |
|
log |
提供HTTP访问日志的HTTP Servlet |
原创文章欢迎转载,转载时请注明出处。
作者推荐文章:
》如何获取系统信息(包括操作系统、jvm、cpu、内存、硬盘、网络等)
Hadoop源码解析 1 --- Hadoop工程包架构解析的更多相关文章
- Hadoop工程包架构解析
Hadoop源码解析 1 --- Hadoop工程包架构解析 1 Hadoop中各工程包依赖简述 Google的核心竞争技术是它的计算平台.Google的大牛们用了下面5篇文章,介绍了它们的计算 ...
- (转)把hadoop源码关联到eclipse工程
把hadoop源码关联到eclipse工程 转:http://www.superwu.cn/2013/08/04/355 在eclipse中阅读源码非常方便,利于我们平时的学习,下面讲述如何把 ...
- hadoop源码import到eclipse工程
1.解压hadoop-1.1.2.tar.gz,重点在src文件夹 2.在eclipse中通过菜单栏创建一个java工程,工程名随便 3.在创建的工程上,点击右键,在弹出菜单中选择最后一项,在弹出窗口 ...
- 使用其他Java工程导入hadoop源码用于在hadoop工程中查看源码
疑问:在开发hadoop程序的时候,有时候需要查看hadoop的源码,但是开发环境看不到,甚是烦恼,经过网上搜索和琢磨,终于实现了,虽然有点绕,但是目的达到了. 第一步:下载hadoop的源码包:ha ...
- hadoop源码分析(2):Map-Reduce的过程解析
一.客户端 Map-Reduce的过程首先是由客户端提交一个任务开始的. 提交任务主要是通过JobClient.runJob(JobConf)静态函数实现的: public static Runnin ...
- Hadoop源码分析(1):HDFS读写过程解析
一.文件的打开 1.1.客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public F ...
- Hadoop源码分析:Hadoop编程思想
60页的ppt讲述Hadoop的编程思想 下载地址 http://download.csdn.net/detail/popsuper1982/9544904
- Hadoop源码分析(3): Hadoop的运行痕迹
在使用hadoop的时候,可能遇到各种各样的问题,然而由于hadoop的运行机制比较复杂,因而出现了问题的时候比较难于发现问题. 本文欲通过某种方式跟踪Hadoop的运行痕迹,方便出现问题的时候可以通 ...
- Hadoop源码编译过程
一. 为什么要编译Hadoop源码 Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Libraries)的概念,通 ...
随机推荐
- dva框架使用详解及Demo教程
dva框架的使用详解及Demo教程 在前段时间,我们也学习讲解过Redux框架的基本使用,但是有很多同学在交流群里给我的反馈信息说,redux框架理解上有难度,看了之后还是一脸懵逼不知道如何下手,很多 ...
- ios常用数据库、完美无缺
直接copy过去就能用,我们不用再去造轮子,现在的xocod9.4更加人性化了,不用再添加依赖库,这点苹果你让我开始喜欢了,哈哈. 需要这兄弟拉进去的哈 下班标的1,2,3,4就是就截图的4个文件,没 ...
- 复习宝典之Redis
查看更多宝典,请点击<金三银四,你的专属面试宝典> 第八章:Redis Redis是一个key-value的nosql数据库.先存到内存中,会根据一定的策略持久化到磁盘,即使断电也不会丢失 ...
- React组件的使用
一.index.js 文件[基本配置] //react语法塘 import React from 'react'; //reactDom用来操作虚拟DOM import ReactDom from ...
- angular2路由之routerLinkActive指令
angular2的routerLinkActive指令在路由激活时添加样式class .red{ color: red;} <a routerLink="/user/login ...
- python学习——面向对象的三大特性
一.继承 继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类又可称为基类或超类,新建的类称为派生类或子类. 1.python中类的继承分为:单继承和多继承 class P ...
- C语言,初次见面~
C语言是一门介于低级语言(如汇编语言)和高级语言(如Java,Python)之间的一门编程语言,所以它兼有两类语言的一些优点,并且具有自身的一些特点. 1.c语言的高效性.c语言具有通常是汇编语言才具 ...
- 破解使用SMB协议的Windows用户密码:acccheck
一.工作原理 Acccheck是一款针对微软的SMB协议的探测工具(字典破解用户名和密码),本身不具有漏洞利用的能力. SMB协议:SMB(Server Message Block)通信协议主要是作为 ...
- 成都Uber优步司机奖励政策(2月17日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- LSD_SLAM(一)运行数据集
虽然按照作者的推荐使用的是OpenCV 2.4.8,但编译依然通不过,一直有错误: 因为lsd_slam是2014年出的,用的ros编译系统不是catkin而是rosbuild,有一些不理解的地方. ...