*转载 Tarjan有向图详解
注意!
文章转自:https://www.cnblogs.com/liwenchi/p/7259306.html,如有造成任何侵权行为,请与我联系。我会在第一时间删除。
不过说实话,这大佬写的真的强,治好了各种疑难杂症 :)
原文内容
全网最详细tarjan算法讲解,我不敢说别的。反正其他tarjan算法讲解,我看了半天才看懂。我写的这个,读完一遍,发现原来tarjan这么简单!
tarjan算法,一个关于 图的联通性的神奇算法。基于DFS(迪法师)算法,深度优先搜索一张有向图。!注意!是有向图。根据树,堆栈,打标记等种种神(che)奇(dan)方法来完成剖析一个图的工作。而图的联通性,就是任督二脉通不通。。的问题。
了解tarjan算法之前你需要知道:
强连通,强连通图,强连通分量,解答树(解答树只是一种形式。了解即可)
不知道怎么办!!!
神奇海螺~:嘟噜噜~!
强连通(strongly connected): 在一个有向图G里,设两个点 a b 发现,由a有一条路可以走到b,由b又有一条路可以走到a,我们就叫这两个顶点(a,b)强连通。
强连通图: 如果 在一个有向图G中,每两个点都强连通,我们就叫这个图,强连通图。
强连通分量strongly
connected components):在一个有向图G中,有一个子图,这个子图每2个点都满足强连通,我们就叫这个子图叫做 强连通分量
[分量::把一个向量分解成几个方向的向量的和,那些方向上的向量就叫做该向量(未分解前的向量)的分量]
举个简单的栗子:
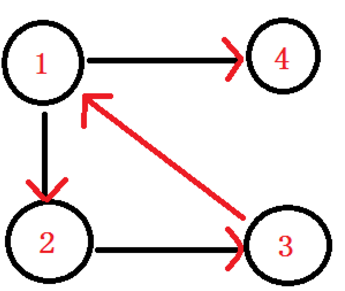
比如说这个图,在这个图中呢,点1与点2互相都有路径到达对方,所以它们强连通.
而在这个有向图中,点1 2 3组成的这个子图,是整个有向图中的强连通分量。
解答树:就是一个可以来表达出递归枚举的方式的树(图),其实也可以说是递归图。。反正都是一个作用,一个展示从“什么都没有做”开始到“所有结求出来”逐步完成的过程。“过程!”
神奇海螺结束!!!

tarjan算法,之所以用DFS就是因为它将每一个强连通分量作为搜索树上的一个子树。而这个图,就是一个完整的搜索树。
为了使这颗搜索树在遇到强连通分量的节点的时候能顺利进行。每个点都有两个参数。
1,DFN[]作为这个点搜索的次序编号(时间戳),简单来说就是 第几个被搜索到的。%每个点的时间戳都不一样%。
2,LOW[]作为每个点在这颗树中的,最小的子树的根,每次保证最小,like它的父亲结点的时间戳这种感觉。如果它自己的LOW[]最小,那这个点就应该从新分配,变成这个强连通分量子树的根节点。
ps:每次找到一个新点,这个点LOW[]=DFN[]。
而为了存储整个强连通分量,这里挑选的容器是,堆栈。每次一个新节点出现,就进站,如果这个点有
出度
就继续往下找。直到找到底,每次返回上来都看一看子节点与这个节点的LOW值,谁小就取谁,保证最小的子树根。如果找到DFN[]==LOW[]就说明这个节点是这个强连通分量的根节点(毕竟这个LOW[]值是这个强连通分量里最小的。)最后找到强连通分量的节点后,就将这个栈里,比此节点后进来的节点全部出栈,它们就组成一个全新的强连通分量。
先来一段伪代码压压惊:
tarjan(u){
DFN[u]=Low[u]=++Index // 为节点u设定次序编号和Low初值
Stack.push(u) // 将节点u压入栈中
for each (u, v) in E // 枚举每一条边
if (v is not visted) // 如果节点v未被访问过
tarjan(v) // 继续向下找
Low[u] = min(Low[u], Low[v])
else if (v in S) // 如果节点u还在栈内
Low[u] = min(Low[u], DFN[v])
if (DFN[u] == Low[u]) // 如果节点u是强连通分量的根
repeat v = S.pop // 将v退栈,为该强连通分量中一个顶点
print v
until (u== v)
}
首先来一张有向图。网上到处都是这个图。我们就一点一点来模拟整个算法。
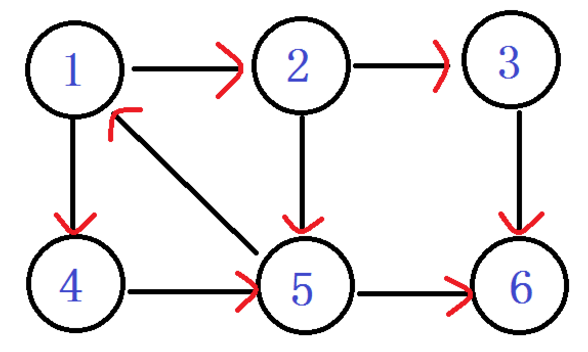
从1进入 DFN[1]=LOW[1]= ++index ----1
入栈 1
由1进入2 DFN[2]=LOW[2]= ++index ----2
入栈 1 2
之后由2进入3 DFN[3]=LOW[3]= ++index ----3
入栈 1 2 3
之后由3进入 6 DFN[6]=LOW[6]=++index ----4
入栈 1 2 3 6
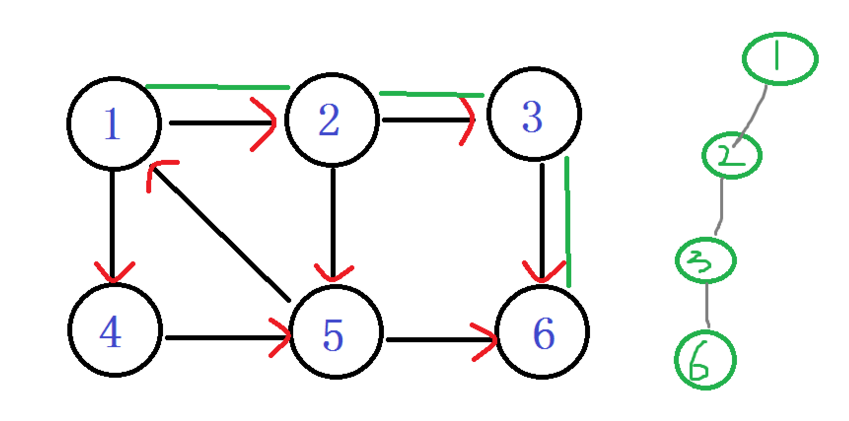
之后发现 嗯? 6无出度,之后判断 DFN[6]==LOW[6]
说明6是个强连通分量的根节点:6及6以后的点 出栈。
栈: 1 2 3
之后退回 节点3 Low[3] = min(Low[3], Low[6]) LOW[3]还是 3
节点3 也没有再能延伸的边了,判断 DFN[3]==LOW[3]
说明3是个强连通分量的根节点:3及3以后的点 出栈。
栈: 1 2
之后退回 节点2 嗯?!往下到节点5
DFN[5]=LOW[5]= ++index -----5
入栈 1 2 5
ps:你会发现在有向图旁边的那个丑的(划掉)搜索树 用红线剪掉的子树,那个就是强连通分量子树。每次找到一个。直接。一剪子下去。半个子树就没有了。。
结点5 往下找,发现节点6 DFN[6]有值,被访问过。就不管它。
继续 5往下找,找到了节点1 他爸爸的爸爸。。DFN[1]被访问过并且还在栈中,说明1还在这个强连通分量中,值得发现。 Low[5] = min(Low[5], DFN[1])
确定关系,在这棵强连通分量树中,5节点要比1节点出现的晚。所以5是1的子节点。so
LOW[5]= 1
由5继续回到2 Low[2] = min(Low[2], Low[5])
LOW[2]=1;
由2继续回到1 判断 Low[1] = min(Low[1], Low[2])
LOW[1]还是 1
1还有边没有走过。发现节点4,访问节点4
DFN[4]=LOW[4]=++index ----6
入栈 1 2 5 4
由节点4,走到5,发现5被访问过了,5还在栈里,
Low[4] = min(Low[4], DFN[5]) LOW[4]=5
说明4是5的一个子节点。
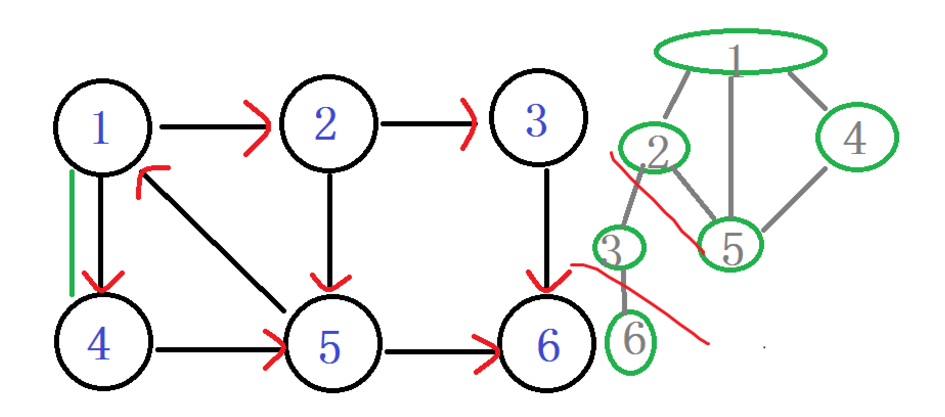
由4回到1.
回到1,判断 Low[1] = min(Low[1], Low[4])
LOW[1]还是 1 。
判断 LOW[1] == DFN[1]
诶?!相等了 说明以1为根节点的强连通分量已经找完了。
将栈中1以及1之后进栈的所有点,都出栈。
栈 :(鬼都没有了)
这个时候就完了吗?!
你以为就完了吗?!
然而并没有完,万一你只走了一遍tarjan整个图没有找完怎么办呢?!
所以。tarjan的调用最好在循环里解决。
like 如果这个点没有被访问过,那么就从这个点开始tarjan一遍。
因为这样好让每个点都被访问到。
*转载 Tarjan有向图详解的更多相关文章
- Tarjan算法详解
Tarjan算法详解 今天偶然发现了这个算法,看了好久,终于明白了一些表层的知识....在这里和大家分享一下... Tarjan算法是一个求解极大强联通子图的算法,相信这些东西大家都在网络上百度过了, ...
- [转载]Linux 命令详解:./configure、make、make install 命令
[转载]Linux 命令详解:./configure.make.make install 命令 来源:https://www.cnblogs.com/tinywan/p/7230039.html 这些 ...
- Tarjan 算法详解
一个神奇的算法,求最大连通分量用O(n)的时间复杂度,真实令人不可思议. 废话少说,先上题目 题目描述: 给出一个有向图G,求G连通分量的个数和最大连通分量. 输入: n,m,表示G有n个点,m条边 ...
- [转载] 多图详解Spring框架的设计理念与设计模式
转载自http://developer.51cto.com/art/201006/205212_all.htm Spring作为现在最优秀的框架之一,已被广泛的使用,51CTO也曾经针对Spring框 ...
- 【转载】log4j详解使用
log4j详解 日志论 在应用程序中输出日志有有三个目的:(1)监视代码中变量的变化情况,把数据周期性地记录到文件中供其他应用进行统计分析工作. (2)跟踪代码运行进轨迹,作为日后审计的依据. ...
- 【转载】GitHub详解
原文:GitHub详解 GitHub详解 GitHub 是一个共享虚拟主机服务,用于存放使用Git版本控制的软件代码和内容项目.它由GitHub公司(曾称Logical Awesome)的开发者Chr ...
- [转载]ssget 用法详解 by yxp
总结得很好的ssget用法.....如此好文,必须转载. 原文地址: http://blog.csdn.net/yxp_xa/article/details/72229202 ssget 用法详解 b ...
- (转载)实例详解Android快速开发工具类总结
实例详解Android快速开发工具类总结 作者:LiJinlun 字体:[增加 减小] 类型:转载 时间:2016-01-24我要评论 这篇文章主要介绍了实例详解Android快速开发工具类总结的相关 ...
- [转载]Fiddler界面详解
转载地址:http://www.cnblogs.com/chengchengla1990/p/5681775.html Statistics 页签 完整页签如下图: Statistics 页签显示当前 ...
随机推荐
- Java IP白名单相关工具类
关于设置IP白名单相关的一些方法,整理,记录了一下. package com.tools.iptool; import java.util.ArrayList; import java.util.Ha ...
- Linux -- date 日期命令
Linux -- date 日期命令 date 用法:date [选项]... [+格式] 以给定的格式显示当前时间,或是设置系统日期. 1.使用 date 命令查看当前日期或当前时间 [root@l ...
- Redis的数据类型以及各类型的操作
讲完安装和配置,接下来就是所有数据库的重头戏,数据结构和常用操作的增删改查了 redis是key-value的数据结构,每条数据都是⼀个键值对 键的类型是字符串 注意:键不能重复 值的类型分为五种: ...
- Redis服务端和客户端的命令
服务器端 服务器端的命令为redis-server 可以使⽤help查看帮助⽂档 redis-server --help 个人习惯 ps aux | grep redis 查看redis服务器进程su ...
- 开源框架:DBUtils使用详解
一.先熟悉DBUtils的API: 简介:DbUtils是一个为简化JDBC操作的小类库. (一)整个dbutils总共才3个包: 1.包org.apache.commons.dbutils 接 ...
- 从tomcat下载文件的配置方法(很全呢)
前几天我做的项目有个下载文件的东西让我苦恼了一下,上传的文件没有放到OSS服务器,而是直接放到tomcat内, 我就想做一个a标签直接下载的得了,结果点开一直都说没有该文件,我查了很多资料找到了如何配 ...
- 第3章 jQuery中的DOM操作
parent() .parents().closest() 区别示例: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitiona ...
- 数据库5.7-jdbc版本8.0.12驱动连接
现在版本的jdbc连接方式和原来不一样了, 假如你使用String driver = "com.mysql.jdbc.Driver"; 会抛出错误: Loading class ` ...
- php.ini修改后,重启无效
今天做项目,上传图,需要修改php.ini.发现修改后,多次长期服务器也没用,在网上找了好多方案.介绍一下我的流程 1.使用phpinfo()找到php.ini的位置,如果位置不准确,修改肯定没有任何 ...
- 【MYSQL笔记】
1.去重取出id最小的记录 tip:在laravel框架里配置信息database设置了'strict' => true,所以在groupBy时只能select出groupBy后的字段,当想搜索 ...