HBase之HFile解析
Sumary:
Protobuf
BinarySearch
本篇主要讲HFileV2的相关内容,包括HFile的构成、解析及怎么样从HFile中快速找到相关的KeyValue.基于Hbase 0.98.1-hadoop2,本文大部分参考了官方的资源,大家可以先阅读下这篇官方文档,Reference Guide:http://hbase.apache.org/book/apes03.html。其实也就是跟我们发行包内dos/book下的其中一篇。dos下有很多有用的文章,有时间的时候建议大家还是细读一下。
研究HFile也有一些时间了,源码也大概研究了下,做了不少试验,庖丁解牛远远谈不上,但是还是很详细地分享一下HFile的方方面面,像拆零件一样,把它一件一件地拆开看看,究竟是什么东西,怎么组织在一起的。
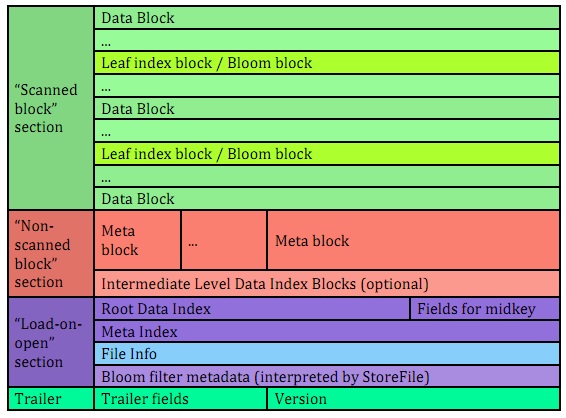
图1
这张图也是摘自上面那篇文章,主要分四部分:Scanned block section,Non-scanned block section,Load-on-open-section,以及Trailer.
Scanned block section: 即存储数据block部分
Non-scanned block section:元数据block部分,主要存放meta信息,即BloomFilter信息。
Load-on-open-section:这部分数据在RegionServer启动时,实例化Region并创建HStore时会将所有StoreFile的Load-on-open-section加载进内存,主要存放了Root Data Index,meta Index,File Info及BooleamFilter的metadata等。除了Fields for midkey外,每部分都是一个HFileBlock.下面会详细去讲这块。
Trailer:文件尾,主要记录version版本,不同的版本Trailer的字段不一样,及Trailer的字段相关信息。
在拆解HFile过程中,我们从下而上地开始分析,HBase本身也是这样,首先要知道Version版本,才知道怎么去加载它们。在开始讲解之前,我们应先获得一份HFile数据,其实很简单,直接从hdfs上下载到本地即可,我使用的数据是我上一篇文章中做测试生成的,10W rows, 70W KeyValue,26M左右。
Trailer:
文件最后4位,即一个整型数字,为version信息,我们知道是V2.而V2的Trailer长度为212字节。除去MagicCode(BlockType) 8字节及 Version 4字节外,剩余206字节记录了整个文件的一些重要的字段信息,而这些字段信息是由protobuf组成的,下面我们尝试山寨一把,自主解析下Trailer的所有信息。
实践1:
step1: 准备一份描述Trailer的Protobuf.
Hbase的源码包下,有一个hbase-protocol sub module.它包含了HBase的所有Protobuf,包括序列化要用到的实体及RPC的定义。我们找到HFile.proto,我们只选取一小部分
新建我们自已的Protobuf文件 : HFile.proto
option java_package = "com.bdifn.hbase.hfile.proto";
option java_outer_classname = "HFileProtos";
option java_generic_services = true;
option java_generate_equals_and_hash = true;
option optimize_for = SPEED; message FileTrailerProto {
optional uint64 file_info_offset = ; //fileInfo起始偏移量
optional uint64 load_on_open_data_offset = ; //加载到内存区域起始偏移量
optional uint64 uncompressed_data_index_size = ; //未压缩的数据索引大小
optional uint64 total_uncompressed_bytes = ; //KeyValue未压缩的总大小
optional uint32 data_index_count = ; //Root DataIndex 的个数,如果只有1级索引的话,往往也是datablock个数
optional uint32 meta_index_count = ; //元数据索引个数
optional uint64 entry_count = ; //KeyValue总个数
optional uint32 num_data_index_levels = ; //数据索引的级别,
optional uint64 first_data_block_offset = ; //第一个数据块的偏移量
optional uint64 last_data_block_offset = ; //最后一个数据块的偏移量
optional string comparator_class_name = ; //比较器类名
optional uint32 compression_codec = ; //编码
optional bytes encryption_key = ; //加密相关
}
从proto文件可以看出,Trailer主要记录了Load-on-open-section相关的信息,应该花点时间去做些结合和对比。
step2:使用Protobuf命令生成java代码.(刚好我之前在hadoop环境中编译过源码,安装了protobuf)
protoc HFile.proto --java_out=.
将生成的java类拷到我们的项目中.
step3. 编写java代码解析Trailer.
public static void main(String[] args) throws Exception {
Configuration config = new Configuration();
// 我已经将文件拷到了f盘根目录
String pathStr = "file:///f:/0a99d83b2b0a49c0adbc371d4bfe021e";
Path path = new Path(pathStr);
FileSystem fs = FileSystem.get(URI.create(pathStr), config);
FSDataInputStream input = fs.open(path);
long length = input.available();
int trailerSize = ;
input.seek(length - trailerSize);
byte[] trailerBytes = new byte[trailerSize];
input.read(trailerBytes);
ByteBuffer trailerBuf = ByteBuffer.wrap(trailerBytes);
trailerBuf.position(trailerSize - );
int version = trailerBuf.getInt();
//3, 0, 0, 2
//最后三位是majorVersion
int majorVersion = version & 0x00ffffff;
//高位是 minorVersion
int minorVersion = version >>> ;
String magicCode = Bytes.toString(Arrays.copyOfRange(trailerBytes, , ));
// 除去头8个字节MagicCode ,除去尾4个字节version信息。咱就是这么暴力。
FileTrailerProto hfileProtos = FileTrailerProto.PARSER
.parseDelimitedFrom(new ByteArrayInputStream(trailerBytes, ,
trailerSize - ));
System.out.println(String.format("MagicCode:%s,majorVersion:%d,:minorVersion:%d",magicCode,majorVersion,minorVersion));
System.out.println(hfileProtos);
}
输出结果:

至此,Trailer已经完全解析完成,接下来开始下一部分:
Load-on-open-section:
RegionServer托管着0...n个Region,Region管理着一个或多个HStore,其中HStore就管理着一个MemStore及多个StoreFile.
所在RegionServer启动时,会扫描所StoreFile,加载StoreFile的相关信息到内存,而这部分内容就是Load-on-open-section,主要包括 Root数据索引,miidKyes(optional),Meta索引,File Info,及BloomFilter metadata等.
数据索引:
数据索引是分层的,可以1-3层,其中第一层,即Root level Data Index,这部分数据是处放在内存区的。一开始,文件比较小,只有single-level,rootIndex直接定位到了DataBlock。当StoreFile变大时,rootIndex越来越大,随之所耗内存增大,会以多层结构存储数据索引.当采用multi-level方式,level=2时,使用root index和leaf index chunk,即内存区的rootIndex定位到的是 leafIndex,再由leafIndex定位到Datablock。当一个文件的datablock非常多,采用的是三级索引,即rootIndex定位到intermediate index,再由intermediate index定位到leaf index,最后定位到data block.可以看看上面图1所示,各个level的index都是分布在不同的区域的。但每部分index是以HFileBlock格式存放的,后面会比较详细地讲HFileBlock,说白了,就是HFile中的一个块。
Fileds for midKey:
这部分数据是Optional的,保存了一些midKey信息,可以快速地定位到midKey,常常在HFileSplit的时候非常有用。
MetaIndex:
即meta的索引数据,和data index类似,但是meta存放的是BloomFilter的信息,关于BloomFilter由于篇幅就不深入讨论了.
FileInfo:
保存了一些文件的信息,如lastKey,avgKeylen,avgValueLen等等,一会我们将会写程序将这部分内容解析出来并打印看看是什么东西。同样,FileInfo使用了Protobuf来进行序列化。
Bloom filter metadata:
分为GENERAL_BLOOM_META及DELETE_FAMILY_BLOOM_META二种。
OK,下面开始操刀分割下Load-on-open-section的各个小块,看看究竟有什么东西。在开始分析之前,上面提到了一个HFileBlock想先看看。从上面可以看出来,其实基本每个小块都叫HFileBlock(除field for midkey),在Hbase中有一个类叫HFileBlock与之对应。从V2开始,即我们当前用的HFile版本,HFileBlock是支持checksum的,默认地使用CRC32,由此HFileBlock由header,data,checksum三部分内容组成,如下图所示。其中Header占了33个字节,字段是一样的,而每个block的组织会有些小差异.
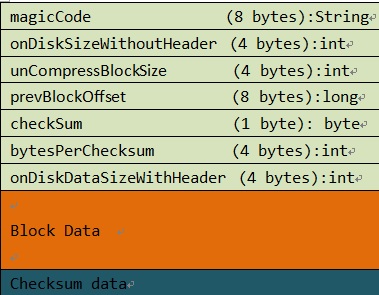
图2
了解了HFileBlock的结构,我们下面开始正式解析内存区中的各个index的block内容。首先我们根据图2我们抽象出一个简单的HFileBlock实体。
实验2: HFileBlock的解析.及BlockReader内部类
public class MyHFileBlock {
public static class Header {
private String magicCode ;
int onDiskSizeWithoutHeader;
int unCompressBlockSize;
long prevBlockOffset;
byte checkSum;
int bytesPerChecksum;
int onDiskDataSizeWithHeader;
}
private Header header;
private ByteBuffer blockBuf;
private byte [] checkSum ;
....
public static class BlockIndexReader {
public BlockIndexReader(MyHFileBlock block) {
....
}
public BlockIndexReader parseMultiLevel(int numEntries, String expectedMagicCode, int level) throws Exception {
.....
}
.......
}
}
2.编写HFileBlock遍历器,代码有点长,折叠起来吧,有兴趣可以看看,详细完整代码还是下载附件项目吧,
public class MyHFileBlockIterator {
private ByteBuffer loadOnOpenBuffer;
public MyHFileBlockIterator(FSDataInputStream data, long offset, int length) {
try {
data.seek(offset);
byte[] loadOnOpenBytes = new byte[length];
data.read(loadOnOpenBytes);
loadOnOpenBuffer = ByteBuffer.wrap(loadOnOpenBytes);
} catch (IOException e) {
e.printStackTrace();
}
}
public MyHFileBlockIterator(byte [] data) {
loadOnOpenBuffer = ByteBuffer.wrap(data);
}
public MyHFileBlock nextBlock() {
MyHFileBlock block = new MyHFileBlock(loadOnOpenBuffer);
Header header = block.getHeader();
int currentBlockLength = block.getHeader()
.getOnDiskDataSizeWithHeader();
int dataSize = currentBlockLength - MyHFileBlock.HARDER_SIZE;
byte[] dataBlockArray = new byte[dataSize];
loadOnOpenBuffer.get(dataBlockArray);
ByteBuffer dataBlock = ByteBuffer.wrap(dataBlockArray);
block.setBlockBuf(dataBlock);
int checkSumChunks = header.getOnDiskSizeWithoutHeader()
/ header.getBytesPerChecksum();
if (header.getOnDiskSizeWithoutHeader() % header.getBytesPerChecksum() != ) {
checkSumChunks++;
}
int checkSumBytes = checkSumChunks * ;
byte[] checkSum = new byte[checkSumBytes];
loadOnOpenBuffer.get(checkSum);
block.setCheckSum(checkSum);
return block;
}
public boolean hasNext(){
return loadOnOpenBuffer.position() < loadOnOpenBuffer.capacity();
}
}
开始解析Root Data Index和metaIndex .在Trailer解析后,我们可以得到Load-on-open-section内容的相关信息,可以构造字节数组,将这部分字节码load进内存进行解析,在解析之前先讲下FileInfo
FileInfo的内容是以ProtoBuf放式存放的,与Trailer类似,我们先创建FileInfo.proto
option java_package = "com.bdifn.hbase.hfile.proto";
option java_outer_classname = "FileInfoProtos";
option java_generic_services = true;
option java_generate_equals_and_hash = true;
option optimize_for = SPEED; message BytesBytesPair {
required bytes first = 1;
required bytes second = 2;
} message FileInfoProto {
repeated BytesBytesPair map_entry = 1;
}
编译: protoc FileInfo.proto --java_out=.
编写测试类:
....
FileTrailerProto hfileProtos = FileTrailerProto.PARSER.parseDelimitedFrom(new ByteArrayInputStream(trailerBytes, 8,trailerBytes.length - 4));
long loadOnOpenLength = length - trailerSize - hfileProtos.getLoadOnOpenDataOffset();
MyHFileBlockIterator inter = new MyHFileBlockIterator(input,hfileProtos.getLoadOnOpenDataOffset(), (int) loadOnOpenLength);
//解析出来root data index
MyHFileBlock dataIndex = inter.nextBlock();
int dataIndexLevels = hfileProtos.getNumDataIndexLevels();
int dataIndexEntries = hfileProtos.getDataIndexCount();
//创建root data index reader
MyHFileBlock.BlockIndexReader rootDataReader = dataIndex.createBlockIndexReader().parseMultiLevel(dataIndexEntries,"IDXROOT2", dataIndexLevels);
//解析出来root meta index
MyHFileBlock metaIndex = inter.nextBlock();
.....
//获取file info
MyHFileBlock fileInfo = inter.nextBlock();
//解析读取FileInfo内容
ByteArrayInputStream in = new ByteArrayInputStream(fileInfo.getBlockBuf().array());
int pblen = ProtobufUtil.lengthOfPBMagic();
byte[] pbuf = new byte[pblen];
if (in.markSupported())
in.mark(pblen);
int read = in.read(pbuf);
FileInfoProtos.FileInfoProto fileInfoProto = FileInfoProtos.FileInfoProto.parseDelimitedFrom(in); List<BytesBytesPair> entries = fileInfoProto.getMapEntryList(); for (BytesBytesPair entry : entries) {
System.out.println(entry.getFirst().toStringUtf8() + ":"+ entry.getSecond().toStringUtf8());
}
//剩下的BloomFileter metadata block.
while (inter.hasNext()) {
MyHFileBlock block = inter.nextBlock();
System.out.println(block.getHeader());
}
以上就是解析HFile Load-on-open-section部分的各个fileblock内容,完整代码请下载附带的地址。
Scanned block section: 关于bloomfilter先不分析了。
Non-scanned block section:
这部分内容就是真正的数据块,从图1看出,这部分数据是分datablock存储的,默认地,每个datablock占64K,如果是多层的index的话,部分index block也会存放在这里,由于我的测试数据,是single-level的,所以只针对单级的index分析。
的single-level情况下,内存的rootDataIndex记录了每个datablock的偏移量,大小及startKey信息,主要是为了快速地定位到KeyValue的位置,在HFile中查找或者seek到某个KeyValue时,首先会在内存中,对rootDataIndex进行二分查找,单级的index可以直接定位DataBlock,然后通过迭代datablock定位到KeyValue所在的位置,而2-3层时,上面也略有提及,大家有时间的话,可以做多点研究这部分。
弱弱提句:在HStore中,会有cache将这些datablock缓存起来,使用LRU算法,这样会提高不少性能。
每个DataBlock同样也是一个HFileBlock,也包括header,data,checksum信息,可以用我们之前写的BlockIterator就可以搞定。下面使用代码,去遍历一个datablock看看。
实验3:
编写KeyValue遍历器
public class KeyValueIterator {
public static final int KEY_LENGTH_SIZE = 4;
public static final int VALUE_LENGTH_SIZE = 4;
private byte [] data ;
private int currentOffset ;
public KeyValueIterator(byte [] data) {
this.data = data;
currentOffset = 0;
}
public KeyValue nextKeyValue(){
KeyValue kv = null;
int keyLen = Bytes.toInt(data,currentOffset,4);
incrementOffset(KEY_LENGTH_SIZE);
int valueLen = Bytes.toInt(data,currentOffset,4);
incrementOffset(VALUE_LENGTH_SIZE);
//1 is memTS
incrementOffset(keyLen,valueLen,1);
int kvSize = KEY_LENGTH_SIZE + VALUE_LENGTH_SIZE + keyLen + valueLen ;
kv = new KeyValue(data , currentOffset - kvSize - 1, kvSize);
return kv;
}
public void incrementOffset(int ... lengths) {
for(int length : lengths)
currentOffset = currentOffset + length;
}
public boolean hasNext() {
return currentOffset < data.length;
}
}
编写测试代码:
//从rootDataReader中获取第一块的offset及数据大小
long offset = rootDataReader.getBlockOffsets()[0];
int size = rootDataReader.getBlockDataSizes()[0]; byte[] dataBlockArray = new byte[size];
input.seek(offset);
input.read(dataBlockArray);
//图方便,直接用iterator来解析出来FileBlock
MyHFileBlockIterator dataBlockIter = new MyHFileBlockIterator(dataBlockArray);
MyHFileBlock dataBlock1 = dataBlockIter.nextBlock();
//将data内容给一个keyvalue迭代器
KeyValueIterator kvIter = new KeyValueIterator(dataBlock1.getBlockBuf().array());
while (kvIter.hasNext()) {
KeyValue kv = kvIter.nextKeyValue();
//do some with keyvalue. like print the kv.
System.out.println(kv);
}
OK,基本上是这些内容了。有点抱歉一开篇讲得有点大了,其实没有方方面面都讲得很详细。meta,bloomfilter部分没有详细分析,大家有时间可以研究后,分享一下。
源码我将我测试的Hfile也附带上传了,压缩后有3M多,完整代码请下载:下载源码
HBase之HFile解析的更多相关文章
- HBase – 探索HFile索引机制
本文由 网易云发布. 作者: 范欣欣 本篇文章仅限内部分享,如需转载,请联系网易获取授权. 01 HFile索引结构解析 HFile中索引结构根据索引层级的不同分为两种:single-level和m ...
- HFile解析 基于0.96
什么是HFile HBase.BigTable以及其他分布式存储.查询系统的底层存储都采用SStable的思想,HBase的底层存储是HFile,他要解决的问题就是如果将内容存储到磁盘,以及如何高效的 ...
- Hadoop生态圈-HBase的HFile创建方式
Hadoop生态圈-HBase的HFile创建方式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 废话不多说,直接上代码,想说的话都在代码的注释里面. 一.环境准备 list cr ...
- HBase 高级架构解析
整体框架 使用 ZooKeeper 框架协助 RegionServer(类似于HDFS的nodemanager)用户请求从 Client 到 Zookeeper 进行判断数据属于哪一个 Region ...
- hbase 查看hfile文件
emp表数据结构 hbase(main):098:0> scan 'emp' ROW COLUMN+CELL row1 column=mycf:depart, timestamp=1555846 ...
- HBase – 存储文件HFile结构解析
本文由 网易云发布. 作者:范欣欣 本篇文章仅限内部分享,如需转载,请联系网易获取授权. HFile是HBase存储数据的文件组织形式,参考BigTable的SSTable和Hadoop的TFile ...
- HBase架构深度解析
原文出处: DLevin(@雪地脚印_) 前记 公司内部使用的是MapR版本的Hadoop生态系统,因而从MapR的官网看到了这篇文文章:An In-Depth Look at the HBase A ...
- HBase工具:如何查看HBase的HFile
root@root:~/Desktop/sourceCodes/hbase-2.1.1/bin# ./hbase Usage: hbase [<options>] <command& ...
- HBase轻松入门之HBase架构图解析
2018-12-13 2018-12-20 本篇文章旨在针对初学者以我本人现阶段所掌握的知识就HBase的架构图中各模块作一个概念科普.不对文章内容的“绝对.完全正确性”负责. 1.开胃小菜 关于HB ...
随机推荐
- Node.js aitaotu图片批量下载Node.js爬虫1.00版
即使是https网页,解析的方式也不是一致的,需要多试试. 代码: //====================================================== // aitaot ...
- Solidworks如何等比例缩小放大模型
比如初始化的模型,笔记本长度只有120mm,实际上应该是3倍左右 右击特征,勾选模具工具,然后可以发现多出来一个页面 点击比例缩放,选中要缩放的特征,设置比例,然后打钩 可以发现已经缩放到 ...
- 算法笔记_060:蓝桥杯练习 出现次数最多的整数(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 编写一个程序,读入一组整数,这组整数是按照从小到大的顺序排列的,它们的个数N也是由用户输入的,最多不会超过20.然后程序将对这个数组进行统 ...
- js 数组去重方法汇总
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8&quo ...
- javascript Date日期类
四.Date日期类 迁移时间:2017年5月27日18:43:02 Author:Marydon (一)对日期进行格式化(日期转字符串) 自定义Date日期类的format()格式化方法 方式一: ...
- Backbone.js 1.0.0源码架构分析(二)——Event
(function(){ //省略前面代码 var Events = Backbone.Events = { // 根据name订阅事件,push到this._events[name] on: fun ...
- 【Shiro】Apache Shiro架构之权限认证(Authorization)
Shiro系列文章: [Shiro]Apache Shiro架构之身份认证(Authentication) [Shiro]Apache Shiro架构之集成web [Shiro]Apache Shir ...
- Ooui:在浏览器中运行.NET应用 Ooui.Wasm:浏览器中的.NET
在过去数年中,桌面应用开发人员一直处境艰难,因为人们的主要关注点聚焦于Web和移动应用.由于Microsoft未来Windows平台的计划未定,并且UWP应用也没有突破性进展,因此技术落伍的责任也不应 ...
- android http post 请求与 json字符串
一.目标 android客户端发送一个json格式的http的请求,期望得到服务端的一个json反馈. 1. 客户端发送的json格式为: {"data" : "valu ...
- Xcode中利用git源代码版本号控制
git是一个版本号控制系统,能够通过命令行来调用,也有专门的桌面软件.这里主要介绍在Xcode中怎样利用git来进行版本号的控制. 一.创建git源 从Xcode5開始引入了使用git的一些新特性.将 ...