solr的安装及配置详细教程/solr入门教程
1 solr的下载
从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr最新版本,根据Solr的运行环境,Linux下需要下载solr-7.3.1.tgz,windows下需要下载solr-7.3.1.zip。
Solr使用指南可参考:https://wiki.apache.org/solr/FrontPage。
本教程中我使用的是solr-4.10.3.zip版本。新版本大体上都是一样的。注意solr-7.3.1需要的jdk的版本须在1.8及其以上。
2 solr的文件夹结构
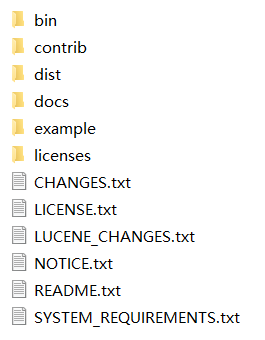
bin:solr的运行脚本 ,想要运行服务的服务的时候,可以双击运行里面的solr.cmd文件,不过使用的自带的jetty小服务器。
contrib:solr的一些贡献软件/插件,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档
example:solr工程的例子目录:
example/solr:
该目录是一个包含了默认配置信息的Solr的Core目录。
example/multicore:
该目录包含了在Solr的multicore中设置的多个Core目录。
example/webapps:
该目录中包括一个solr.war,该war可作为solr的运行实例工程。
licenses:solr相关的一些许可信息
system_requirements.txt : 系统需求信息【里面可以看到对应版本需要的jdk版本信息】
3 运行环境
solr 需要运行在一个Servlet容器中,Solr4.10.3要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器,环境如下:
Solr:Solr4.10.3
Jdk:jdk1.7.0_80
Tomcat:apache-tomcat-7.0.52
4 solr整合tomcat
因为我之前已经安装好了jdk,环境变量都已经配置好了。这里就不需要安装jdk和配置环境变量了。
1 创建目录
第一步:在D盘下面创建一个solr的文件夹
2 解压tomcat到创建的目录
第二步:解压tomcat的安装文件到solr目录下。
这一步建议使用新的安装文件解压,不要使用之前用过的tomcat
完成后的效果:
3 解压solr到创建的目录
第三步:解压solr-4.10.3.zip压缩文件到solr目录下
完成后的效果:
4 拷贝solr.war
第四步:拷贝solr-4.10.3里面的solr.war包到tomcat的的webapps里面去
1.solr.war在D:\solr\solr-4.10.3\example\webapps目录下

2.拷贝到D:\solr\apache-tomcat-7.0.52\webapps里面去
5 解压solr.war
第五步:使用解压工具解压solr.war包 或者 启动tomcat服务自动完成解压
如果启动tomcat服务自动解压的话,解压完成后记得停止tomcat服务,因为我们的配置工作还没有完成,
因此这里建议使用解压工具手动解压。
6 删除solr.war
第六步:删除tomcat下的webapps里面的solr.war包
7 拷贝jar包到工程中
第七步:把\solr-4.10.3\example\lib\ext目录下的所有的jar包添加到solr工程中
注意:对于一个tomcat有两个存放lib包的地方。
1.第一个地方是:你的项目下面的WEB-INF下面的lib目录里面
2.第二个地方是:tomcat安装目录下的lib目录里面

对于这两处地方,我们建议放到你的项目下面的WEB-INF下面的lib目录里面。

8 准备solrhome
第八步:配置solrHome 和 solrCore
1.在D:\solr目录下创建一个solrhome文件夹(存放solr所有配置文件的一个文件夹)
\solr-4.10.3\example\solr目录就是一个标准的solrhome。
2.复制\solr-4.10.3\example\solr文件夹里面的全部内容到刚刚创建的solrhome目录下面
为什么不使用\solr-4.10.3\example\solr这个标准的solrhome呢?
答:如果是单机版用这个还可以。如果搭建集群我们需要很多个solrhome,你就一个源代码包是不够用的。
补充:
在solrhome下有一个文件夹叫做collection1这就是一个solrcore。就是一个solr的实例。一个solrcore相当于mysql中一个数据库。Solrcore之间是相互隔离。
- 在solrcore中有一个文件夹叫做conf,包含了索引solr实例的配置信息。
- 在conf文件夹下有一个solrconfig.xml。配置实例的相关信息。如果使用默认配置可以不用做任何修改。
Xml的配置信息:
Lib:solr服务依赖的扩展包,默认的路径是collection1\lib文件夹,如果没有 就创建一个
dataDir:配置了索引库的存放路径。默认路径是collection1\data文件夹,如果没有data文件夹,会自动创建。
requestHandler:
9 配置solrhome到web.xml中
第九步:配置solrhome到我们的web.xml里面

其它瞎掰:weblogic服务器一般在我们的政府机构使用,电商一般使用的是tomcat.银行一般使用的IBM公司的websphere,银行使用的数据库一般是db2.
下面正式说一下怎么配置我们的solrhome:
打开web.xml,找到下面的内容

修改为:D:\solr\solrhome就是上面配置的solrhome所在的位置

注意:solr/home名称必须是固定的。
10 启动tomcat
第十步:进入tomcat的bin目录,双击startup.bat启动tomcat服务
11 访问
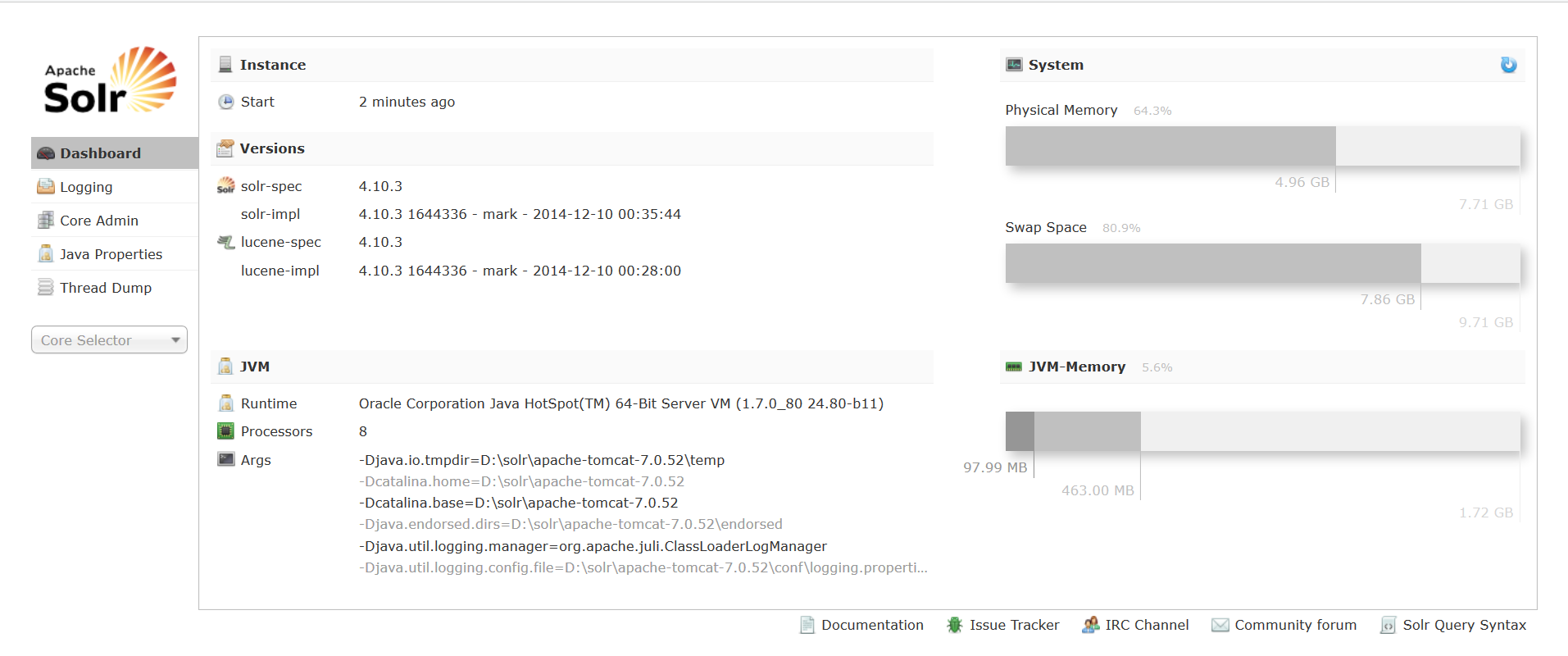
第十一步:浏览器访问localhost:8080/solr/出现下面的界面说明安装成功了
4 安装中文分词器
第一步:把IKAnalyzer2012FF_u1.jar添加到solr/WEB-INF/lib目录下。

第二步:在solr/WEB-INF/下面创建classes目录

第三步:复制IKAnalyzer的配置文件和自定义词典和停用词典到solr的classpath下。即是复制到上一步创建的classes目录下。
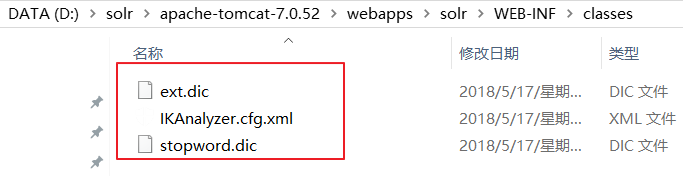
注意:eclipse的文本编辑是以UTF-8 无BOM格式编码的,如果使用文本编辑器编辑推荐使用notepad++编辑,
选择一样的编码格式【以UTF-8 无BOM格式编码】,这样可以避免,你修改ext.dic或者stopword.dic文档之后就不好使了。
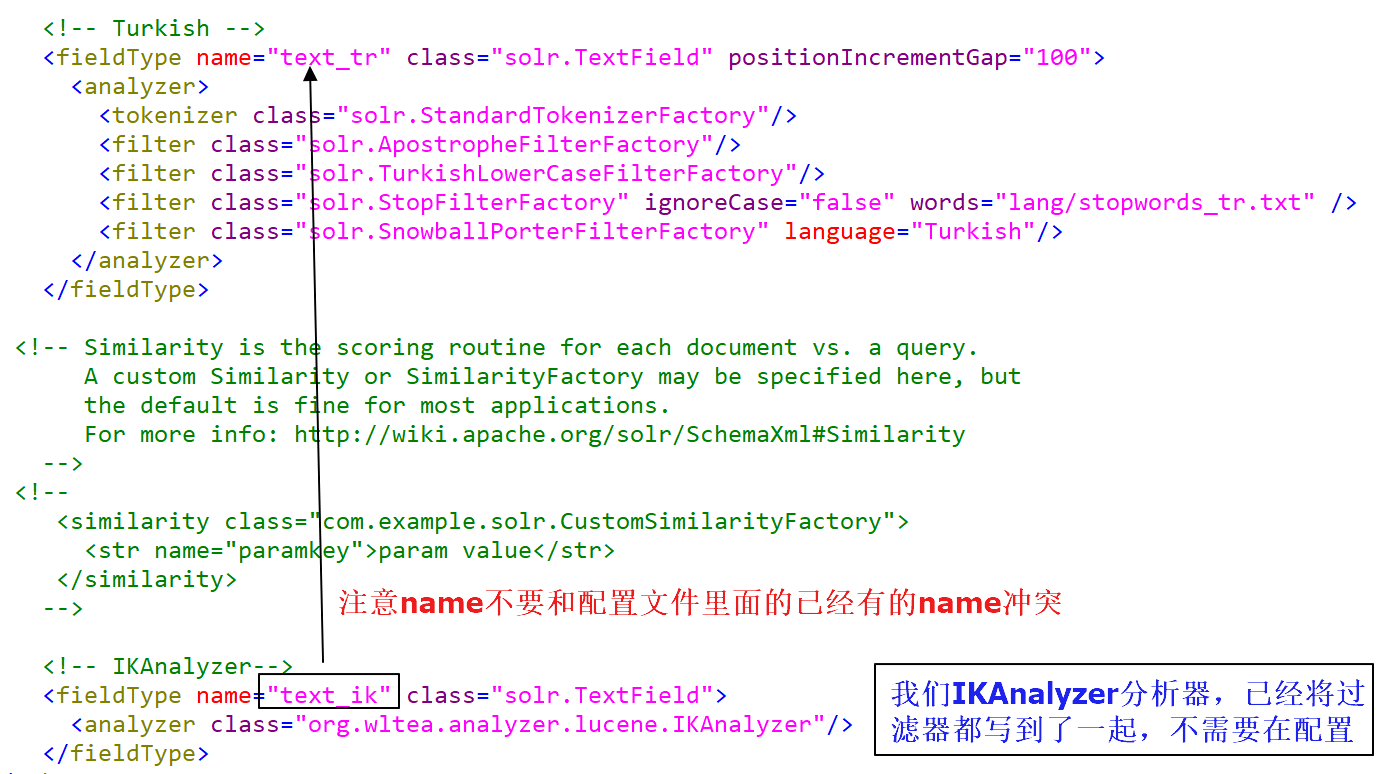
第四步:在D:\solr\solrhome\collection1\conf下的schema.xml文件中添加一个自定义的fieldType,使用中文分析器。
直接添加下面的代码到配置文件里面就可以了:
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
第五步:定义一个field,指定field的Type属性为text_ik.
复制下面的代码添加到schema.xml配置文件就可以了。
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
四五两步配置后的效果:

第六步:重启tomcat,配置生效
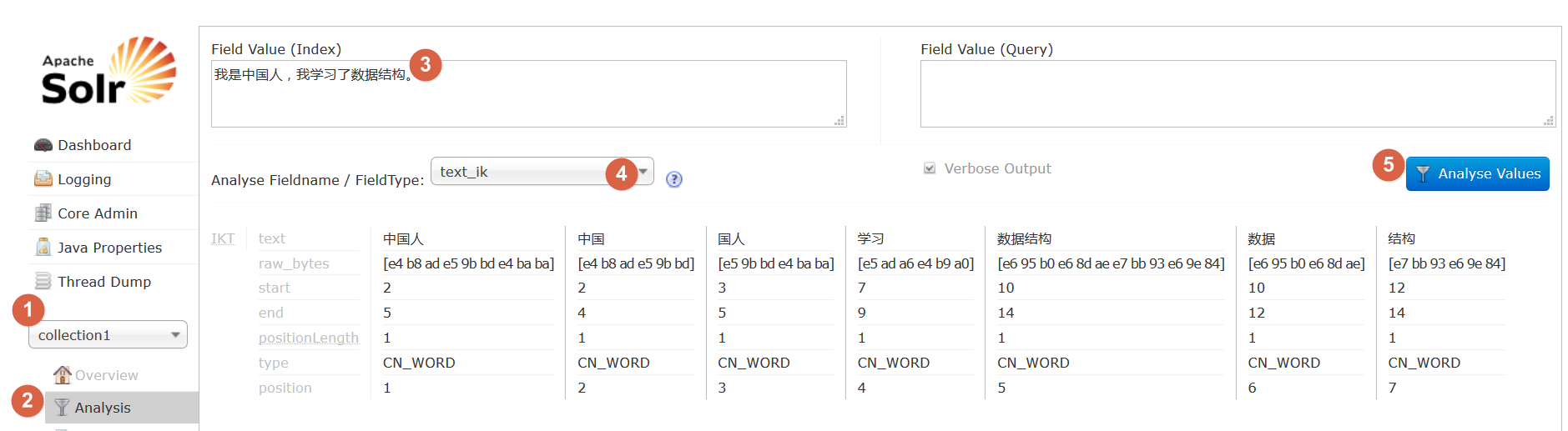
第七步:测试
5 批量导入数据
使用dataimport插件批量导入数据。
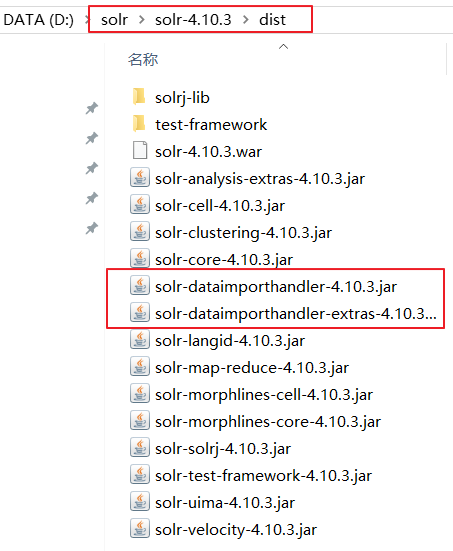
第一步:把dataimport插件的依赖的jar包添加到solrcore(collection1\lib)中去。
1.jar包所在位置
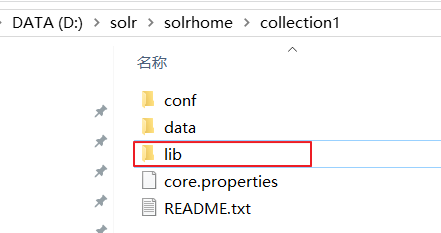
2.D:\solr\solrhome\collection1下面没有lib文件夹,创建一个
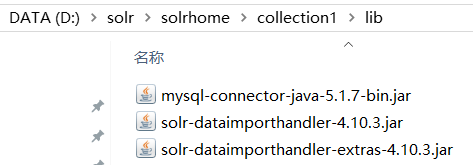
3.将jar包拷贝进去

第二步:导入数据库的驱动包到solrcore(collection1\lib)中去。
这里需要的数据库的驱动包需要你自己准备

完成后的效果:
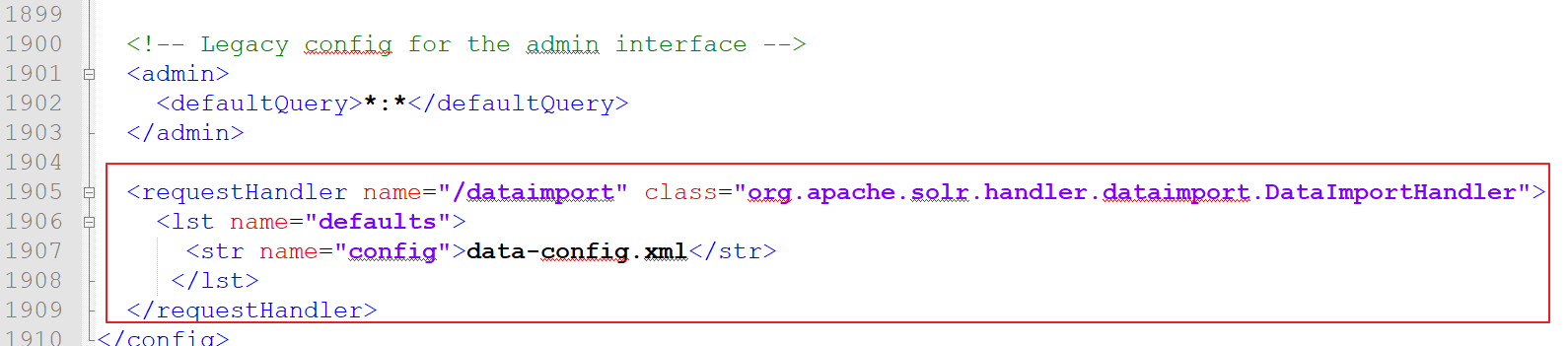
第三步:修改D:\solr\solrhome\collection1\conf下的solrconfig.xml文件,添加一个requestHandler。
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
效果:
第四步:创建一个data-config.xml,保存到D:\solr\solrhome\collection1\conf目录下
1.创建data-config.xml文件。
2.复制下面的代码到data-config.xml文件中
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://39.105.94.154:3306/lucene"
user="tom"
password="tom"/>
<document>
<entity name="product" query="SELECT pid,name,catalog_name,price,description,picture FROM products ">
<field column="pid" name="id"/>
<field column="name" name="product_name"/>
<field column="catalog_name" name="product_catalog_name"/>
<field column="price" name="product_price"/>
<field column="description" name="product_description"/>
<field column="picture" name="product_picture"/>
</entity>
</document>
</dataConfig>
dataSource和entity里面的内容根据自己的实际情况修改.
对于没有的域需要自己配置。
<!--product-->
<field name="product_name" type="text_ik" indexed="true" stored="true"/>
<field name="product_price" type="float" indexed="true" stored="true"/>
<field name="product_description" type="text_ik" indexed="true" stored="false" />
<field name="product_picture" type="string" indexed="false" stored="true" />
<field name="product_catalog_name" type="string" indexed="true" stored="true" /> <field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="product_name" dest="product_keywords"/>
<copyField source="product_description" dest="product_keywords"/>
在schema.xml中加入上面的代码,效果如下

第五步:重启tomcat,让配置生效。
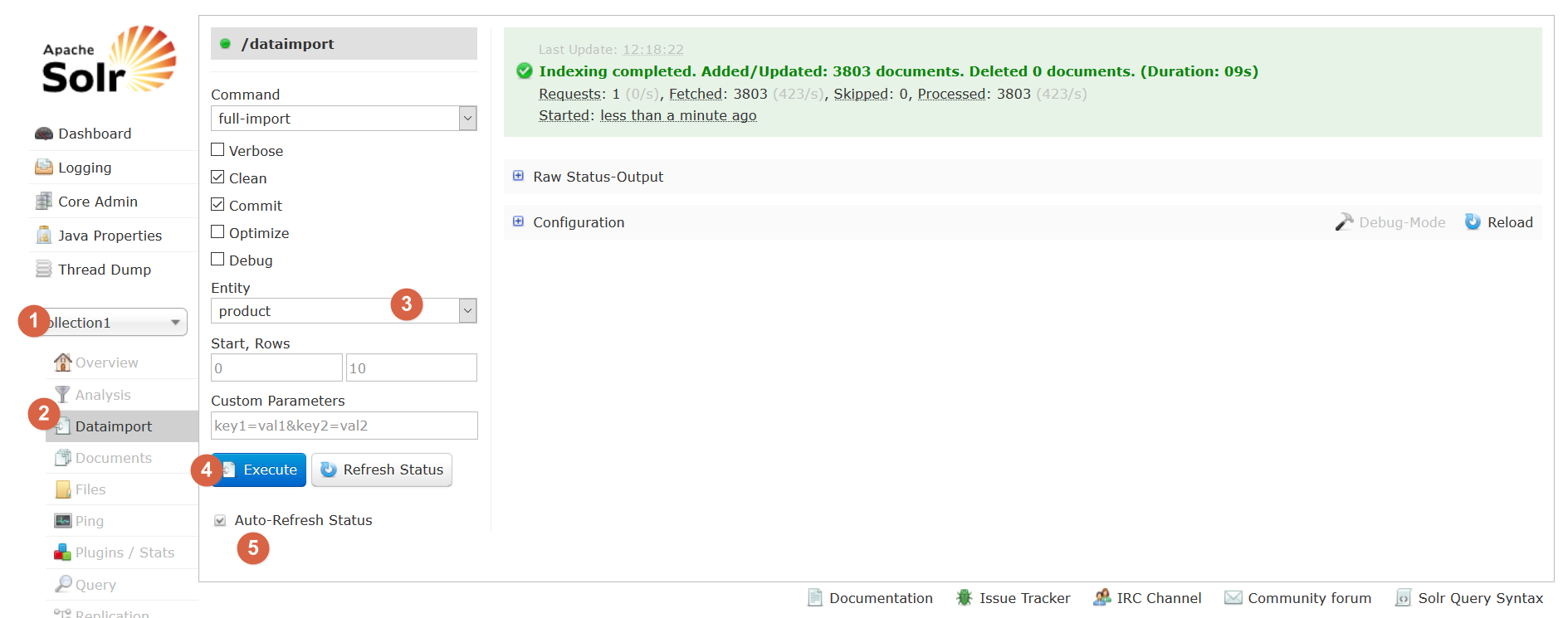
第六步:点击Execute按钮导入数据。
勾选Auto-Refresh Status 可以自动刷新,看到导入的状态
导入数据前会先清空索引库,然后再导入。
6 Solr后台管理界面维护索引
1 添加/修改文档
id相同的话,会先删除原来的,然后保存新的。

2 删除文档
1 删除指定id的索引
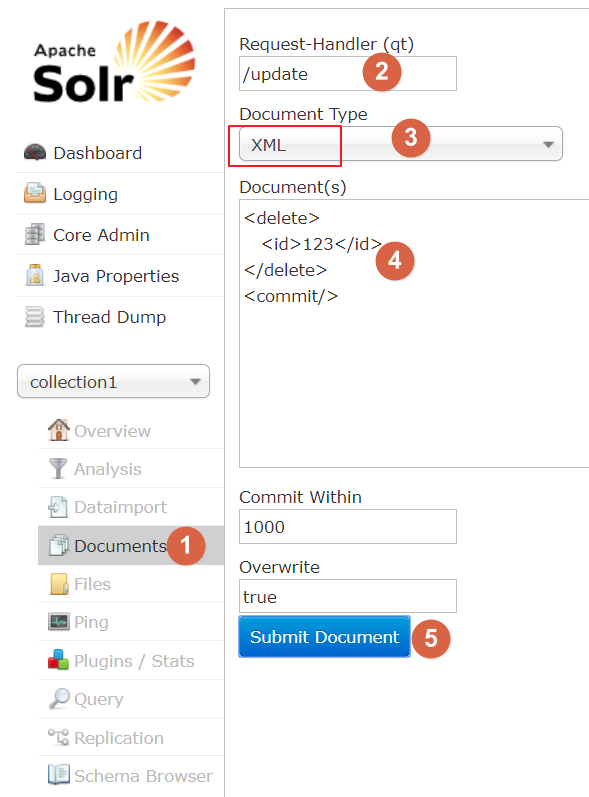
2 删除查询到的索引数据
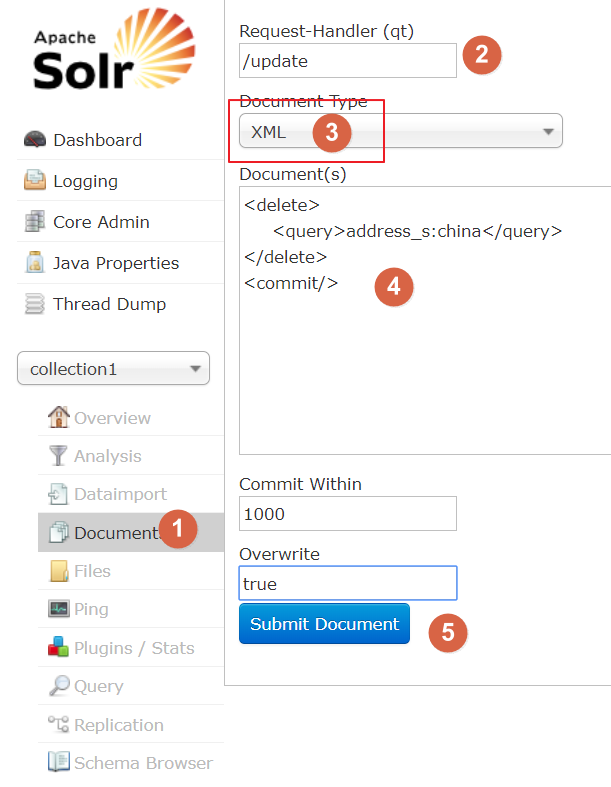
3 删除所有的索引数据
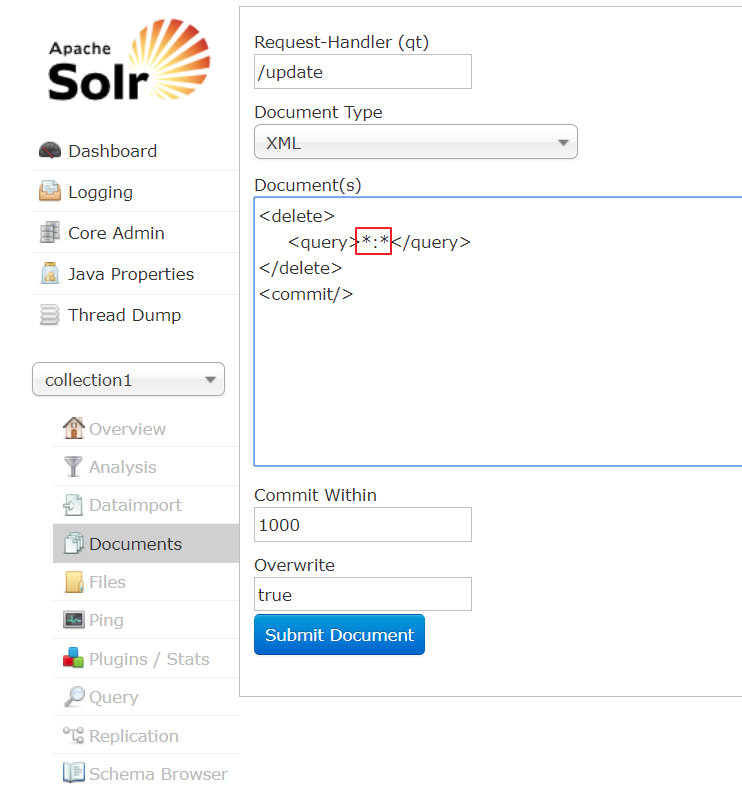
7 solr后台管理界面查询索引
通过/select 搜索索引,Solr 制定一些参数完成不同需求的搜索
1 q query
1 q - 查询字符串,必须的,如果查询所有使用*:*。

2 fq filter query

3 sort

4 start&rows

5 fl

6 df
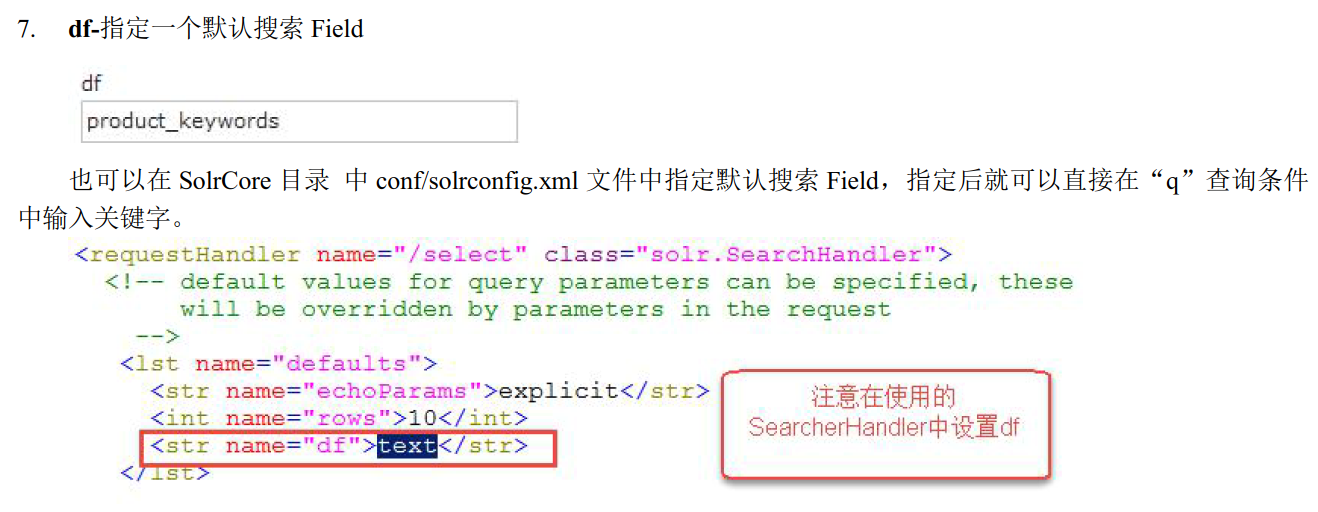
7 wt

9 hl

8 Solr 4.10.1 使用 SolrJ 管理索引库
1 什么是SolrJ
solrj 是访问 Solr 服务的 java 客户端,提供索引和搜索的请求方法,SolrJ 通常在嵌入在业务系统中,通过 SolrJ
的 API 接口操作 Solr 服务.如下图:

2 依赖的jar包
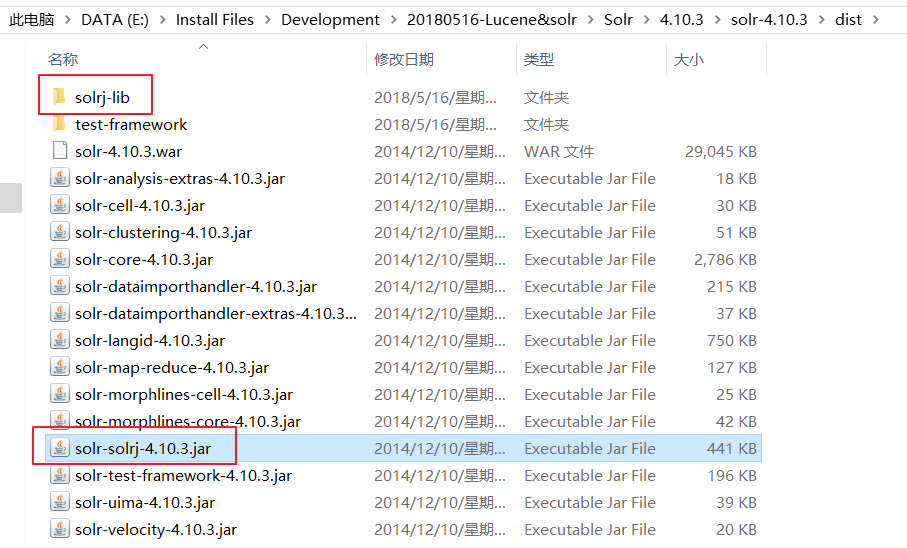

3 使用SolrJ添加文档
实现步骤:
第一步:创建一个 java 工程。
第二步:导入 jar 包。
maven工程添加下面的依赖
<!-- solr客户端 -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>4.10.3</version>
</dependency>
第三步:和 Solr 服务器建立连接。HttpSolrServer 对象建立连接。
第四步:创建一个 SolrInputDocument 对象,然后添加域。
第五步:将 SolrInputDocument 添加到索引库。
第六步:提交。
//向索引库中添加索引
@Test
public void addDocument() throws Exception {
//和solr 服务器创建连接
//参数:solr 服务器的地址,默认找的collection1,如不不是需要指明。
SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr");
//创建一个文档对象
SolrInputDocument document = new SolrInputDocument();
//向文档中添加域
//第一个参数:域的名称,域的名称必须是在 schema.xml 中定义的
//第二个参数:域的值
document.addField("id", "c0001");
document.addField("title_ik", "使用 solrJ 添加的文档");
document.addField("content_ik", "文档的内容");
document.addField("product_name", "商品名称");
//把 document 对象添加到索引库中
solrServer.add(document);
//提交修改
solrServer.commit();
}
4 根据 id 删除文档
//删除文档,根据 id 删除
@Test
public void deleteDocumentByid() throws Exception {
//创建连接
SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr");
//根据 id 删除文档
solrServer.deleteById("c0001");
//提交修改
solrServer.commit();
}
5 根据查询删除文档
查询语法完全支持 Lucene 的查询语法。
//根据查询条件删除文档
@Test
public void deleteDocumentByQuery() throws Exception {
//创建连接
SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr");
//根据查询条件删除文档,*:*刪除所有
solrServer.deleteByQuery("*:*");
//提交修改
solrServer.commit();
}
6 修改文档
在 solrJ 中修改没有对应的 update 方法,只有 add 方法,只需要添加一条新的文档,和被修改的文档 id 一致就,可以
修改了。本质上就是先删除后添加。
7 简单查询
//查询索引
@Test
public void queryIndex() throws Exception {
//创建连接
SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr");
//创建一个 query 对象
SolrQuery query = new SolrQuery();
//设置查询条件
query.setQuery("*:*");
//也可以这样写:query.set("q","*:*");
//执行查询
QueryResponse queryResponse = solrServer.query(query);
//取查询结果
SolrDocumentList solrDocumentList = queryResponse.getResults();
//共查询到商品数量
System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound());
//遍历查询的结果
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
System.out.println(solrDocument.get("product_name"));
System.out.println(solrDocument.get("product_price"));
System.out.println(solrDocument.get("product_catalog_name"));
System.out.println(solrDocument.get("product_picture"));
}
}
8 复杂查询
其中包含查询、过滤、分页、排序、高亮显示等处理。
// 复杂查询索引
@Test
public void queryIndex2() throws Exception {
// 创建连接
SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr");
// 创建一个 query 对象
SolrQuery query = new SolrQuery();
// 设置查询条件
query.setQuery("钻石");
// 也可以这样写:query.set("q","钻石");
// 也可以这样写:query.set("q", "id:1");
// 也可以这样写:query.set("q", "*:*"); // 过滤条件
query.setFilterQueries("product_catalog_name:幽默杂货");
// 也可以这样写:query.set("fq","product_catalog_name:幽默杂货");
// 也可以这样写: query.set("fq","product_price:[* TO 10]"); // 排序条件
query.setSort("product_price", ORDER.asc);
// 也可以这样写:query.addSort("product_price asc");
// 也可以这样写:query.addSort("product_price",ORDER.asc);
// 也可以这样写:query.set("sort", "product_price asc"); // 分页处理
query.setStart(0);
query.setRows(10);
// 也可以这样写:query.set("start", 0);
// 也可以这样写:query.set("rows", 10);
// 结果中域的列表
query.setFields("id", "product_name", "product_price", "product_catalog_name", "product_picture");
// 也可以写成下面这样:query.set("fl", "product_name","product_price"); // 设置默认搜索域
query.set("df", "product_keywords"); // 打开高亮显示
query.setHighlight(true);
// 高亮显示的域
query.addHighlightField("product_name");
// 高亮显示的前缀
query.setHighlightSimplePre("<span style='color:red;'>");
// 高亮显示的后缀
query.setHighlightSimplePost("</span>"); // 执行查询
QueryResponse queryResponse = solrServer.query(query);
// 取查询结果
SolrDocumentList solrDocumentList = queryResponse.getResults();
// 共查询到商品数量
System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound());
// 取高亮显示部分的内容
// Map k id V Map
// Map k 域名 V List
// List list.get(0);
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting(); // 遍历查询的结果
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
//看高亮显示部分是否有此 id 的内容,有取出。没有返回 null.
Map<String, List<String>> map = highlighting.get(solrDocument.get("id"));
// 判断一下,防止出现空指针异常
List<String> list = null;
if (map != null) {
list = map.get("product_name");
}
// 判断是否有高亮内容
String productName = "";
if (null != list) {
productName = list.get(0);
} else {
productName = (String) solrDocument.get("product_name");
}
System.out.println(productName);
System.out.println(solrDocument.get("product_price"));
System.out.println(solrDocument.get("product_catalog_name"));
System.out.println(solrDocument.get("product_picture"));
}
}
query.setQuery("钻石"); 如果不指定默认搜索域,默认配置文件里面走的是text域。

可以看到默认的所搜域是text , 默认的条数是10条。
solr的安装及配置详细教程/solr入门教程的更多相关文章
- 安装、配置Jupyter Notebook快速入门教程
What? Why? How? ---安装 ---启动 ---关闭 ---保存 Markdown语法 Magic关键词 转换notebook--toHTML 创建幻灯片 运行代码 What? 文字化编 ...
- JAVAEE——Solr:安装及配置、后台管理索引库、 使用SolrJ管理索引库、仿京东的电商搜索案例实现
1 学习回顾 1. Lucene 是Apache开源的全文检索的工具包 创建索引 查询索引 2. 遇到问题? 文件名 及文件内容 顺序扫描法 全文检索 3. 什么是全文检索? 这种先创建索引 再 ...
- solr与.net系列课程(一)solr的安装与配置
不久之前开发了一个项目,需要用到solr,因为所以在开始再网上查找资料,但是发现大部分的资料都是很片面的,要么就是只讲解solr如何安装的,要么就是只讲解solr的某一个部分的,而且很多都是资料都是一 ...
- solr的安装与配置
solr的安装与配置 不久之前开发了一个项目,需要用到solr,因为所以在开始再网上查找资料,但是发现大部分的资料都是很片面的,要么就是只讲解solr如何安装的,要么就是只讲解solr的某一个部分的, ...
- Solr学习总结(二)Solr的安装与配置
接着前一篇,这里总结下Solr的安装与配置 1.准备 1.安装Java8 和 Tomcat9 ,java和tomcat 的安装这里不再重复.需要注意的是这两个的版本兼容问题.貌似java8 不支持,t ...
- MySQL5.7免安装版配置详细教程
MySQL5.7免安装版配置详细教程 一. 软件下载 Mysql是一个比较流行且很好用的一款数据库软件,如下记录了我学习总结的mysql免安装版的配置经验,要安装的朋友可以当做参考哦 mysql5.7 ...
- Solr学习总结 Solr的安装与配置
接着前一篇,这里总结下Solr的安装与配置 1.准备 1.安装Java8 和 Tomcat9 ,java和tomcat 的安装这里不再重复.需要注意的是这两个的版本兼容问题.貌似java8 不支持,t ...
- Tableau Server注册安装及配置详细教程
Tableau Server注册安装及配置详细教程 本文讲解的是 Tableau Server 10.0 版本的安装及配置 这里分享的 TableauServer 安装版本为64位的10.0版本Ser ...
- ubuntu下安装和配置最新版JDK8傻瓜教程
ubuntu下安装和配置最新版JDK8傻瓜教程 听语音 | 浏览:18940 | 更新:2014-07-14 22:13 | 标签:ubuntu 1 2 3 4 5 6 分步阅读 ubuntu系统通常 ...
随机推荐
- Tomcat之Web站点部署
上线代码有两种方式,第一种方式是直接将程序目录放在webapps目录下面,这种方式大家已经明白了,就不多说了.第二种方式是使用开发工具将程序打包成war包,然后上传到webapps目录下面.下面让我们 ...
- 终端工具putty访问vmware centos系统
当我们安装好后,可以通过shell来输入命令行来操作centos,当我们一般为了方便可以用终端进行远程连接虚拟机. 软件下载:http://www.chiark.greenend.org.uk/~sg ...
- linux vi vim文本编辑器
vim是vi的加强版,建议使用vim. vim拥有三种模式: 命令模式(常规模式) vim启动后,默认进入命令模式,任何模式都可以通过esc键来回到命令模式.命令模式可以通过键入不同的命令来完成选择, ...
- 提高SQL Server数据库效率常用方法
1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 5.网络速度慢 6.查询出的数据量过大 ...
- .net core i上 K8S(三)Yaml文件运行.netcore程序
上一章我们通过kubectl run简单运行了一个.netcore网站,但实际的开发中,我们都是通过yaml来实现的. 1.编写yaml文件 关于yaml文件的格式在此就不多描述了,不熟悉的可以去网上 ...
- Ocelot Consul
1首先创建一个json的配置文件,文件名随便取,我取Ocelot.json 这个配置文件有两种配置方式,第一种,手动填写 服务所在的ip和端口:第二种,用Consul进行服务发现 第一种如下: { & ...
- Tiled结合Unity实现瓦片地图——Tiled2Unity篇
本系列文章由Aimar_Johnny编写,欢迎转载,转载请标明出处,谢谢. http://blog.csdn.net/lzhq1982/article/details/75356478 前段时间应公司 ...
- Mysql表操作《一》表的增删改查
一.表介绍 表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段 id,name,qq,age称为字段,其余的,一行内容称为一条记录 二.创建表 语法 ...
- maven+eclipse+ssm 环境搭建和启动
该类工程环境搭建和启动方法 ------------------------------------------------------------------------------- 配置 jdk ...
- jquery源码解析:jQuery原型方法init的详解
先来了解几个jQuery方法: <li></li> <li></li> <li></li> $("li") ...