程序或-内存区域分配& ELF分析 ***
一.在学习之前我们先看看ELF文件。
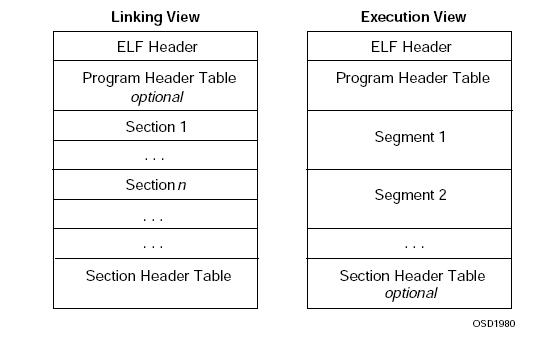
ELF分为三种类型:
1. .o 可重定位文件(relocalble file)
2. 可执行文件
3. 共享库(shared library)
三种格式基本上从结构上是一样的,只是具体到每一个结构不同。下面我们就从整体上看看这3种格式从文件内容上存储的方式,spec上有张图是比较经典的:如上图:
其实从文件存储的格式来说,上面的两种view实际上是一样的,Segment实际上就是由section组成的,将相应的一些section映射到一起就叫segment了,就是说segment是由0个或多个section组成的,实际上本质都是section。在这里我们首先来仔细了解一下section和segment的概念:section就是相同或者相似信息的集合,比如我们比较熟悉的.text .data .bss section,.text是可执行指令的集合,.data是初始化后数据的集合,.bss是未初始化数据的集合。实际上我们也可以将一个程序的所有内容都放在一起,就像dos一样,但是将可执行程序分成多个section是很有好处的,比如说我们可以将.text section放在memory的只读空间内,将可变的.data section放在memory的可写空间内。
从可执行文件的角度来讲,如果一个数据未被初始化那就不需要为其分配空间,所以.data和.bss一个重要的区别就是.bss并不占用可执行文件的大小,它只是记载需要多少空间来存储这些未初始化数据,而不分配实际的空间。
可以通过命令 $ readelf -l a.out 查看文件的格式和组成。
但一般查看ELF文件使用:
readelf -S -W xxx.out
编译使用:
gcc xxx.c -g -O0 -o xxx.out
注意“-O0”为编译器不优化。
二. 站在汇编语言的角度,一个程序分为:
数据段 -- DS
堆栈段 -- SS
代码段 -- CS
扩展段 -- ES
站在高级语言的角度,根据APUE,一个程序分为如下段:
text
data (initialized)
bss
stack
heap
1.一般情况下,一个可执行二进制程序(更确切的说,在Linux操作系统下为一个进程单元,在UC/OSII中被称为任务)在存储(没有调入到内存运行)时拥有3个部分,分别是代码段(text)、数据段(data)和BSS段。这3个部分一起组成了该可执行程序的文件。
★★可执行二进制程序 = 代码段(text)+数据段(data)+BSS段★★
2.而当程序被加载到内存单元时,则需要另外两个域:堆域和栈域。图1-1所示为可执行代码存储态和运行态的结构对照图。一个正在运行的C程序占用的内存区域分为代码段、初始化数据段、未初始化数据段(BSS)、堆、栈5个部分。
★★正在运行的C程序 = 代码段+初始化数据段(data)+未初始化数据段(BSS)+堆+栈★★
3.在将应用程序加载到内存空间执行时,操作系统负责代码段、数据段和BSS段的加载,并将在内存中为这些段分配空间。栈亦由操作系统分配和管理,而不需要程序员显示地管理;堆段由程序员自己管理,即显示地申请和释放空间。
4.动态分配与静态分配,二者最大的区别在于:1. 直到Run-Time的时候,执行动态分配,而在compile-time的时候,就已经决定好了分配多少Text+Data+BSS+Stack。2.通过malloc()动态分配的内存,需要程序员手工调用free()释放内存,否则容易导致内存泄露,而静态分配的内存则在进程执行结束后系统释放(Text, Data), 但Stack段中的数据很短暂,函数退出立即被销毁。
图1-1(从可执行文件a.out的角度来讲,如果一个数据未被初始化那就不需要为其分配空间,所以.data和.bss一个重要的区别就是.bss并不占用可执行文件的大小,它只是记载需要多少空间来存储这些未初始化数据,而不分配实际的空间)
三.
代码段 --text(code segment/text segment)
text段在内存中被映射为只读,但.data和.bss是可写的。
text段是程序代码段,在AT91库中是表示程序段的大小,它是由编译器在编译连接时自动计算的,当你在链接定位文件中将该符号放置在代码段后,那么该符号表示的值就是代码段大小,编译连接时,该符号所代表的值会自动代入到源程序中。
数据段 -- data
data包含静态初始化的数据,所以有初值的全局变量和static变量在data区。段的起始位置也是由连接定位文件所确定,大小在编译连接时自动分配,它和你的程序大小没有关系,但和程序使用到的全局变量,常量数量相关。数据段属于静态内存分配。
bss段--bss
bss是英文Block Started by Symbol的简称,通常是指用来存放程序中未初始化的全局变量的一块内存区域,在程序载入时由内核清0。BSS段属于静态内存分配。它的初始值也是由用户自己定义的连接定位文件所确定,用户应该将它定义在可读写的RAM区内,源程序中使用malloc分配的内存就是这一块,它不是根据data大小确定,主要由程序中同时分配内存最大值所确定,不过如果超出了范围,也就是分配失败,可以等空间释放之后再分配。BSS段属于静态内存分配。
stack:
栈(stack)保存函数的局部变量(但不包括static声明的变量, static 意味着 在数据段中 存放变量),参数以及返回值。是一种“后进先出”(Last In First Out,LIFO)的数据结构,这意味着最后放到栈上的数据,将会是第一个从栈上移走的数据。对于哪些暂时存贮的信息,和不需要长时间保存的信息来说,LIFO这种数据结构非常理想。在调用函数或过程后,系统通常会清除栈上保存的局部变量、函数调用信息及其它的信息。栈另外一个重要的特征是,它的地址空间“向下减少”,即当栈上保存的数据越多,栈的地址就越低。栈(stack)的顶部在可读写的RAM区的最后。
heap:
堆(heap)保存函数内部动态分配内存,是另外一种用来保存程序信息的数据结构,更准确的说是保存程序的动态变量。堆是“先进先出”(First In first Out,FIFO)数据结构。它只允许在堆的一端插入数据,在另一端移走数据。堆的地址空间“向上增加”,即当堆上保存的数据越多,堆的地址就越高。

下图是APUE中的一个典型C内存空间分布图:
所以可以知道传入的参数,局部变量,都是在栈顶分布,随着子函数的增多而向下增长.
函数的调用地址(函数运行代码),全局变量,静态变量都是在分配内存的低部存在,而malloc分配的堆则存在于这些内存之上,并向上生长.
举例1:
- #include <stdio h="">
- const int g_A = 10; //代码段
- int g_B = 20; //数据段
- static int g_C = 30; //数据段
- static int g_D; //BSS段
- int g_E; //BSS段
- char *p1; //BSS段
- void main( )
- {
- int local_A; //栈
- int local_B; //栈
- static int local_C = 0; //数据段
- static int local_D; //数据段
- char *p3 = "123456"; //123456在代码段,p3在栈上
- p1 = (char *)malloc( 10 ); //堆,分配得来得10字节的区域在堆区
- strcpy( p1, "123456" ); //123456{post.content}放在常量区,编译器可能会将它与p3所指向 的"123456"优化成一块
- printf("hight address\n");
- printf("-------------栈--------------\n");
- printf( "栈, 局部变量, local_A, addr:0x%08x\n", &local_A );
- printf( "栈, 局部变量,(后进栈地址相对local_A低) local_B, addr:0x%08x\n", &local_B );
- printf("-------------堆--------------\n");
- printf( "堆, malloc分配内存, p1, addr:0x%08x\n", p1 );
- printf("------------BSS段------------\n");
- printf( "BSS段, 全局变量, 未初始化 g_E, addr:0x%08x\n", &g_E, g_E );
- printf( "BSS段, 静态全局变量, 未初始化, g_D, addr:0x%08x\n", &g_D );
- printf( "BSS段, 静态局部变量, 初始化, local_C, addr:0x%08x\n", &local_C);
- printf( "BSS段, 静态局部变量, 未初始化, local_D, addr:0x%08x\n", &local_D);
- printf("-----------数据段------------\n");
- printf( "数据段,全局变量, 初始化 g_B, addr:0x%08x\n", &g_B);
- printf( "数据段,静态全局变量, 初始化, g_C, addr:0x%08x\n", &g_C);
- printf("-----------代码段------------\n");
- printf( "代码段,全局初始化变量, 只读const, g_A, addr:0x%08x\n\n", &g_A);
- printf("low address\n");
- return;
- }
- </stdio>
运行结果:
- hight address
- -------------栈--------------
- 栈, 局部变量, local_A, addr:0xffa70c1c
- 栈, 局部变量,(后进栈地址相对local_A低) local_B, addr:0xffa70c18
- -------------堆--------------
- 堆, malloc分配内存, p1, addr:0x087fe008
- ------------BSS段------------
- BSS段, 全局变量, 未初始化 g_E, addr:0x08049a64
- BSS段, 静态全局变量, 未初始化, g_D, addr:0x08049a5c
- BSS段, 静态局部变量, 初始化, local_C, addr:0x08049a58
- BSS段, 静态局部变量, 未初始化, local_D, addr:0x08049a54
- -----------数据段------------
- 数据段,全局变量, 初始化 g_B, addr:0x08049a44
- 数据段,静态全局变量, 初始化, g_C, addr:0x08049a48
- -----------代码段------------
- 代码段,全局初始化变量, 只读const, g_A, addr:0x08048620
- low address
注意:
编译时需要-g选项,这样才可以看elf信息;
readelf -a a.out
查看这个执行文件的elf信息,摘录部分如下:重点注意其中data段,text段还要有bss段的地址,然后比较这个地址和上面的运行结果,是否是在elf文件的各个段的地址之内。
- Section Headers:
- [Nr] Name Type Addr Off Size ES Flg Lk Inf Al
- [ 0] NULL 00000000 000000 000000 00 0 0 0
- [ 1] .interp PROGBITS 08048114 000114 000013 00 A 0 0 1
- [ 2] .note.ABI-tag NOTE 08048128 000128 000020 00 A 0 0 4
- [ 3] .gnu.hash GNU_HASH 08048148 000148 000020 04 A 4 0 4
- [ 4] .dynsym DYNSYM 08048168 000168 000070 10 A 5 1 4
- [ 5] .dynstr STRTAB 080481d8 0001d8 000058 00 A 0 0 1
- [ 6] .gnu.version VERSYM 08048230 000230 00000e 02 A 4 0 2
- [ 7] .gnu.version_r VERNEED 08048240 000240 000020 00 A 5 1 4
- [ 8] .rel.dyn REL 08048260 000260 000008 08 A 4 0 4
- [ 9] .rel.plt REL 08048268 000268 000028 08 A 4 11 4
- [10] .init PROGBITS 08048290 000290 000017 00 AX 0 0 4
- [11] .plt PROGBITS 080482a8 0002a8 000060 04 AX 0 0 4
- [12] .text PROGBITS 08048310 000310 0002e8 00 AX 0 0 16
- [13] .fini PROGBITS 080485f8 0005f8 00001c 00 AX 0 0 4
- [14] .rodata PROGBITS 08048614 000614 000326 00 A 0 0 4
- [15] .eh_frame PROGBITS 0804893c 00093c 000004 00 A 0 0 4
- [16] .ctors PROGBITS 08049940 000940 000008 00 WA 0 0 4
- [17] .dtors PROGBITS 08049948 000948 000008 00 WA 0 0 4
- [18] .jcr PROGBITS 08049950 000950 000004 00 WA 0 0 4
- [19] .dynamic DYNAMIC 08049954 000954 0000c8 08 WA 5 0 4
- [20] .got PROGBITS 08049a1c 000a1c 000004 04 WA 0 0 4
- [21] .got.plt PROGBITS 08049a20 000a20 000020 04 WA 0 0 4
- [22] .data PROGBITS 08049a40 000a40 00000c 00 WA 0 0 4
- [23] .bss NOBITS 08049a4c 000a4c 00001c 00 WA 0 0 4
- [24] .comment PROGBITS 00000000 000a4c 000114 00 0 0 1
- [25] .debug_aranges PROGBITS 00000000 000b60 000020 00 0 0 1
- [26] .debug_pubnames PROGBITS 00000000 000b80 00003a 00 0 0 1
- [27] .debug_info PROGBITS 00000000 000bba 0001f4 00 0 0 1
- [28] .debug_abbrev PROGBITS 00000000 000dae 00006f 00 0 0 1
- [29] .debug_line PROGBITS 00000000 000e1d 000058 00 0 0 1
- [30] .debug_frame PROGBITS 00000000 000e78 00003c 00 0 0 4
- [31] .debug_str PROGBITS 00000000 000eb4 00000d 00 0 0 1
- [32] .debug_loc PROGBITS 00000000 000ec1 000043 00 0 0 1
- [33] .shstrtab STRTAB 00000000 000f04 000143 00 0 0 1
- [34] .symtab SYMTAB 00000000 0015e8 000560 10 35 60 4
- [35] .strtab STRTAB 00000000 001b48 0002ad 00 0 0 1
- Key to Flags:
- W (write), A (alloc), X (execute), M (merge), S (strings)
- I (info), L (link order), G (group), x (unknown)
- O (extra OS processing required) o (OS specific), p (processor specific)
★★★★注意静态变量初始化为零和全局静态变量初始化为零的情况,都是存储在bss段★★★★
从上面的elf文件可以看出,
[23] .bss NOBITS 08049a4c 000a4c 00001c 00 WA 0 0 4
[22] .data PROGBITS 08049a40000a40 00000c 00 WA 0 0 4
[12] .text PROGBITS 08048310000310 0002e8 00 AX 0 0 16
但是在结果中显示: BSS段, 静态局部变量, 初始化, local_C, addr:0x08049a58
(0x08049a58 大于0x08049a4c 属于bss段)是初始化的静态局部变量但是却属于bss段,为什么?
原因是:local_C是局部静态变量但是却初始化为零。这和没有初始化,默认是零的情况一样,都存储在bss段,如果初始化为其他的值,那么local_C这个变量就会存储在data段。
四
可执行文件大小由什么决定?
可执行文件在存储时分为代码段、数据段和BSS段三个部分。
【例一】
//程序1:
int ar[];
void main()
{
......
}
//程序2:
int ar[] = {, , , , , };
void main()
{
......
}
发现程序2编译之后所得的.exe文件比程序1的要大得多。当下甚为不解,于是手工编译了一下,并使用了/FAs编译选项来查看了一下其各自的.asm,发现在程序1.asm中ar的定义如下:
_BSS SEGMENT
?ar@@3PAHA DD 0493e0H DUP (?) ; ar
_BSS ENDS
而在程序2.asm中,ar被定义为:
_DATA SEGMENT
?ar@@3PAHA DD 01H ; ar
DD 02H
DD 03H
ORG $+1199988
_DATA ENDS
区别很明显,一个位于.bss段,而另一个位于.data段,两者的区别在于:全局的未初始化变量存在于.bss段中,具体体现为一个占位符;全局的已初始化变量存于.data段中;而函数内的自动变量都在栈上分配空间。
.bss是不占用.exe文件空间的,其内容由操作系统初始化(清零);而.data却需要占用,其内容由程序初始化,因此造成了上述情况。
以上仅仅做为学习只用!!
程序或-内存区域分配& ELF分析 ***的更多相关文章
- [转]C程序内存区域分配(5个段作用)
[转]C程序内存区域分配(5个段作用) 2012-08-10 14:45:32| 分类: C++基础|字号 订阅 参考:http://www.360doc.com/content/11/03 ...
- 1 - JVM随笔分类(java虚拟机的内存区域分配(一个不断记录和推翻以及再记录的一个过程))
java虚拟机的内存区域分配 在JVM运行时,类加载器ClassLoader在加载到类的字节码后,交由jvm的执行引擎处理, 执行过程中需要空间来存储数据(类似于Cpu及主存),此时的这段空间的分 ...
- 深入C语言内存区域分配(进程的各个段)详解(转)
原文地址:http://www.jb51.net/article/39696.htm 一般情况下,一个可执行二进制程序(更确切的说,在Linux操作系统下为一个进程单元,在UC/OSII中被称为任务) ...
- C 语言内存区域分配(进程的各个段)详解
C语言可执行代码结构 名称 内容 代码段 可执行代码.字符串常量 数据段 已初始化全局变量.已初始化全局静态变量.局部静态变量.常量数据 BSS段 未初始化全局变量,未初始化全局静态变量 栈 ...
- [转]深入C语言内存区域分配(进程的各个段)详解
一般情况下,一个可执行二进制程序(更确切的说,在Linux操作系统下为一个进程单元,在UC/OSII中被称为任务)在存储(没有调入到内存运行)时拥有3个部分,分别是代码段(text).数据段(data ...
- 面试之四:JVM内存区域分配
1.程序计数器(线程私有)[不会OOM] 记录线程执行的代码位置,每个线程各自独有. 2.栈:虚拟机栈和本地方法栈(线程私有)[会OOM和StackOverflow] 虚拟机栈 每个JAVA方法在执行 ...
- Java内存区域分配基恩内存溢出异常
- JVM内存区域异常分析
在Java虚拟机规范描述中,除程序计数器外,其他几个运行时区域都有可能发生OutOfMemoryError异常.接下来将对各区域分别进行分析介绍,内容包括触发各区域OutOfMemoryError异常 ...
- java\c程序的内存分配
JAVA 文件编译执行与虚拟机(JVM)介绍 Java 虚拟机(JVM)是可运行Java代码的假想计算机.只要根据JVM规格描述将解释器移植到特定的计算机上,就能保证经过编译的任何Java代码能够在该 ...
随机推荐
- org.apache.log4j.Logger用法
在应用程序中添加日志记录总的来说基于三个目的 :监视代码中变量的变化情况,周期性的记录到文件中供其他应用进行统计分析工作:跟踪代码运行时轨迹,作为日后审计的依据:担当集成开发环境中的调试器的作用,向文 ...
- scala学习手记31 - Trait
不知道大家对java的接口是如何理解的.在我刚接触到接口这个概念的时候,我将接口理解为一系列规则的集合,认为接口是对类的行为的规范.现在想来,将接口理解为是对类的规范多少有些偏颇,更恰当些的观点应该是 ...
- java socket - 半关闭
通常,使用关闭输出流来表示输出已经结束.但在进行网络通信时则不能这样做.因为我们关闭输出流时,该输出流对应的Socket也将随之关闭,这样程序将无法再从该socket中读取数据. 为了应付这种情况,s ...
- 关于JDK1.8 HashMap扩容部分源码分析
今天回顾hashmap源码的时候发现一个很有意思的地方,那就是jdk1.8在hashmap扩容上面的优化. 首先大家可能都知道,1.8比1.7多出了一个红黑树化的操作,当然在扩容的时候也要对红黑树进行 ...
- 新东方雅思词汇---7.4、cap
新东方雅思词汇---7.4.cap 一.总结 一句话总结: 抓住 capable 英 ['keɪpəb(ə)l] 美 ['kepəbl] adj. 能干的,能胜任的:有才华的 词组短语 capab ...
- DP问题如何确定状态
DP问题如何确定状态 一.dp实质 动态规划的实质就是通过小规模的同类型的问题来解决题目的问题. 所以有一个dp数组来储存所有小规模问题的解. 所以确定状态也就是缩小问题规模. 我们求解问题的一般规律 ...
- 初试Orchard Core CMS
关于Orchard Core CMS,这是一套内容管理系统(Content Management System),看一下来自官方文档的解释,什么是Orchard CMS. Orchard is a f ...
- poj1469
题解: 二分图匹配 然后判断最大匹配是否是m 代码: #include<cstdio> #include<cmath> #include<algorithm> #i ...
- ZOJ 3204 Connect them(最小生成树+最小字典序)
Connect them Time Limit: 1 Second Memory Limit: 32768 KB You have n computers numbered from 1 t ...
- 几种常见排序算法的C++描述
基本的排序算法有如下特点: 1.几种容易的算法都是以O(N2)排序的 2.Shell排序编程简单,其也是以O(N2)排序的,在实践中用的很多 3.复杂的排序算法往往都是按照O(NlogN)尽心排序的 ...