Paper/ Overview | CNN(未完待续)
I. 基础知识
在对CNN进行概览之前,请先务必清楚以下问题:
机器学习基础知识:
- 什么是“全连接”?
- 前向传播和反向传播各自的作用是?为什么需要反向传播?
- 什么是感知机?其致命缺陷是什么?
- 常见的激活函数有哪些?“激活”了什么特性?(非线性,最直接解决了亦或问题)
深度学习基础知识:
- 常见的损失函数有哪些?最好能知道是怎么得到的(比如由最大似然推出)。
- 常见的优化方法有哪些?利弊如何?
- 抑制过拟合最简单的方法是什么?
- 什么是泛化能力?
- Dropout目的?如何实现?测试阶段需要用吗?
- 什么是梯度消失?有哪些解决方式?(RNN→LSTM,sigmoid、tanh→ReLU,Batch Normalization,GoogLeNet中的辅助损失函数等)
- Batch Normalization目的?如何实现?
- 什么是梯度爆炸?有哪些解决方式?
CNN基础知识:
- 离散卷积怎么实现?
- 假设有一个单通道28x28的图片,使用尺寸为5x5,步长为1的3个卷积核(滤波器),则卷积层尺寸为?(3x24x24)
- 相比于全连接网络,CNN的两大创新点是什么,使得它易于训练,又能学习到较高级的特征?(稀疏连接和参数共享)
- 什么是感受野?层数越大,该层单元的感受野会越大吗?
- 什么是转置卷积?(参见我的博客及其参考链接)
- 什么是池化?参数共享和最大池化,分别为CNN引入了什么特性?
(平移等变性和平移不变性。如果是分离参数的卷积输出的池化,那么会引入多种特征的不变性,比如旋转不变性)
以下内容的提纲,参考中科院PPT:《CNN近期进展与实用技巧》。
而具体内容,为笔者阅读论文后的学习总结。
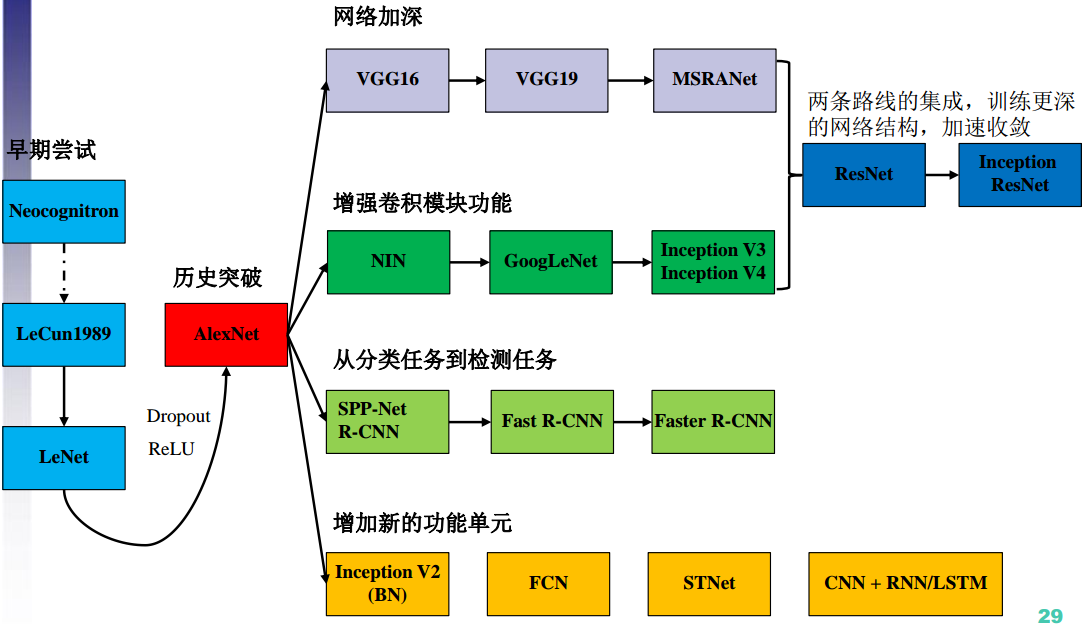
II. 早期尝试
CNN的演化脉络:
1. Neocognitron, 1980
1959年Hubel等人提了对视觉皮层的功能划分:
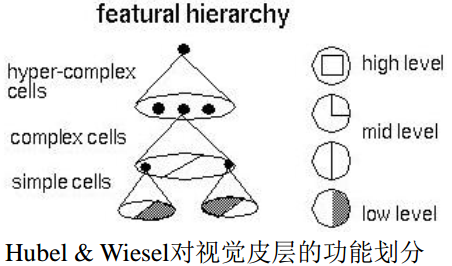
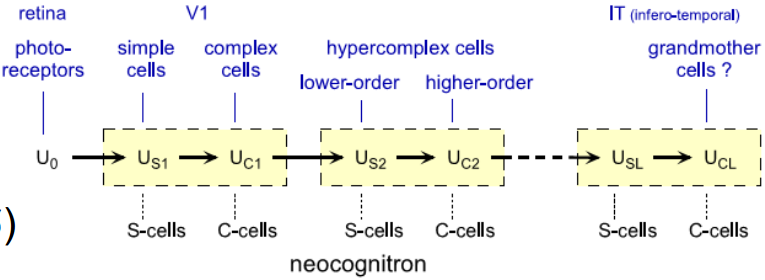
受此启发,1980年,Kunihiko Fukushima提出了Neocognitron,可用于手写数字识别等模式识别任务。
Paper: Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position
创新点:Neocognitron使用了两种细胞:simple cell和complex cell,并且让二者级联工作。
前者直接提取特征,后者处理特征的畸变,比如平移等,使Neocognitron具有平移不变性。
2. LeCun, 1989
A. 概况
Yann Le Cun是第一个在计算机视觉领域(手写邮政编码识别问题)使用CNN的人。
Paper: Backpropagation Applied to Handwritten Zip Code Recognition
我们知道,引入先验知识,也就是引入限制,可以增强网络的泛化能力。
那么,我们应该如何引入呢?
LeCun认为,引入先验最基本的原则(方法)是:在保证计算能力不变的情况下,尽可能减少冗余参数。
该原则的解释是:一可以减小 entropy ,二可以减小 VC 维数,因此可以增强泛化能力。
个人理解:对同一个问题,如果参数较多,要么是问题比较复杂,要么是先验知识不够,假设空间大。
如果在保证 computational power 不下降的情况下,尽可能减少参数,也就等同于引入了尽可能多的先验知识,缩小了假设空间。
现在的问题就是:如何实现这一点?
LeCun将要说明:我们可以通过构造特殊的 network architecture ,来实现这一点。
B. Feature maps & Weight sharing
与之前识别工作的最显著不同之处在于:
- 该网络是端到端的,即直接利用 low-level information ,而不是从 feature vectors 开始。
- 网络中所有的连接都是自适应的,而之前的工作中前几层的连接参数是手动选择的。
具体设计:
首先网络继承了特征提取的方式:
提取 local features ,整合在一起,然后再形成 higher order features 。
其优势在前人工作中已被证实。
一个目标的特征有很多而且各不相同,因此我们应该:
用 a set of feature detectors 来检测这些特征。
一个相同的特征可能出现在各个位置,因此:
我们可以采用 Rumelhart 等人在1986年提出的 weight sharing 方法,在较小的计算代价下,在各个位置上检测出该特征。
综合上述两点,第一个隐藏层应该是一个 feature maps ,每一个 plane 内部共享参数、表示一种特征。
由于某特征的具体位置信息不那么重要,因此该层可以比输入层小。
C. 网络设计
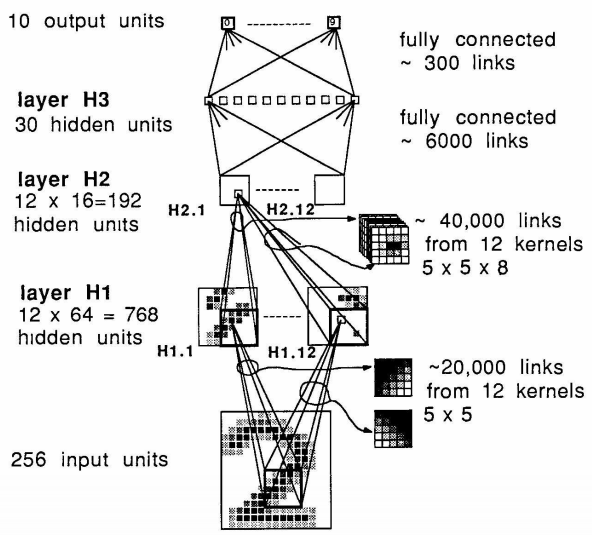
D. 实验
- 非线性激活单元采用 scaled hyperbolic tangent Symmetric functions ,收敛更快。但在函数输入值特别大或特别小时,学习也会很慢。
- 损失函数为MSE。
- 输出单元采用 sigmoid ,保证loss不会过大(梯度也会很大)。
- 目标输出要求在 sigmoid 的拟线性区,保证梯度不会产生于 sigmoid 的平坦区域。
- 在一个小范围内随机初始化,目的同上。
- 随机梯度下降,收敛更快。
- 拟牛顿法调节学习率,让下降更可靠。
最终效果:在数字识别领域当然是 state of the art ~
3. LeNet, 1998
这篇文章是引用过万的综述性文章,对当时手写数字识别的方法做了概述。
Paper: Gradient-based learning applied to document recognition
文章中提到了许多有意思的历史:
在过去,特征提取是重中之重,甚至会被整体手工设计。
原因是,过去分类器的分类任务比较简单,类别差距大,因此假设空间比较小。
因此,分类器的准确性很大程度上取决于该低维空间的拟合程度,特征提取就显得尤为关键。
但时过境迁,随着计算机性能提升、数据库日益扩大和越来越棒的深度学习技术的出现,设计者不再需要仔细设计特征提取器,而可以更依赖于真实数据,并且构造出足够复杂的假设。
该综述长达46页,我们重点说一下CNN的经典构架:LeNet-5。
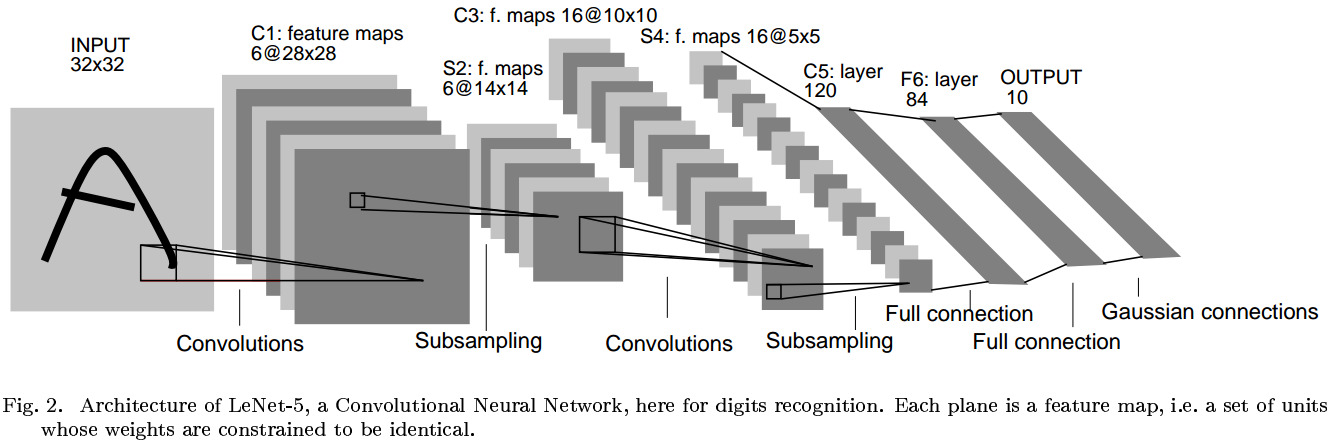
LeNet-5有7层:
- 输入层,尺寸大于任何一个字母,以保证每个字母都会出现在第七层单元的感受野的中心。
- 中间五层分别是:卷积层→降采样层→卷积层→降采样层→卷积层。
- 第一个卷积层使用了六种滤波器,因此具有六个通道的 feature maps 。
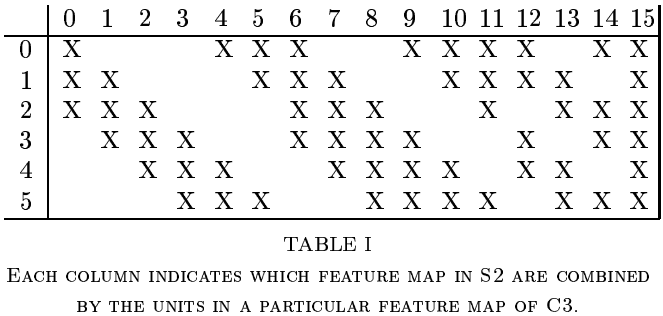
- 第二个卷积层上升到16个通道。每一个通道与前6个通道的关系都不一样,见上图,目的是破坏对称性,迫使每个通道学习不同的特征(理想情况是互补特征)。
- 在全连接层,特征进行内积和非线性激活。
- 最后是输出层,10种数字对应10个输出单元,分别计算输出向量和该分类参考向量的欧式距离。
参数要么是+1要么是-1,主要是因为输出向量的每一个元素都用sigmoid归一化,其值域就是[-1,+1]。
比如,[1 -1...-1]和[1 -1...-1]距离是0,[-1 1 -1...-1]和[1 -1...-1]距离是8。
在统计学上,如果真实概率模型是高斯分布,那么对于线性回归,最大化关于w的对数似然,和最小化MSE是等价的。
而输出层就是一个线性回归问题,并且我们可以假设简单先验为高斯分布。具体参见《DEEP LEARNING》。
那么为什么不用0-9这十个数字来分类呢?
一是上述理由阐述了 distributed codes 在衡量距离时的合理性;
二是实验证明,当类别较多时,这种 place code 效果非常差。因为只让大多数输出为0,只有1个输出非0是很困难的;
三是如果输入的不是字符,place code 更难拒绝判断。
III. 历史性突破:AlexNet, 2012
1. Historic
AlexNet competed in the ImageNet Large Scale Visual Recognition Challenge in 2012.
The network achieved a top-5 error of 15.3%, more than 10.8 percentage points lower than that of the runner up.
因此,AlexNet引爆了深度学习的热潮,我们称之为历史性突破。
Paper: ImageNet classification with deep convolutional neural networks
2. 困难之处
AlexNet解决的最直接问题,就是 ImageNet 图像分类问题,训练集高清图片容量达到120万,类别达1000种;神经网络参数达到6000万个,神经元达65万个,问题复杂度可想而知。
训练如此大规模的网络,显然是困难的。
本文在开头也说明了问题的复杂性:即便是 ImageNet 这样庞大的数据集,也无法 specify 这一复杂的问题。
也就是说,假设空间有很大的未知区域。
因此,我们需要许多先验知识,来补偿那些训练集中没有的数据。
3. 选择CNN
CNN 是理想的模型,因为它通常能为天然图片(测试图片)带来强大而正确的假设,即统计稳定性(平移不变性)和像素的位置依赖性(也就是二者兼顾的意思)。
最重要的是,它的计算成本相对较低。
4. 本文贡献
本文主要贡献有:
- 提出的网络结构,在图像分类比赛中达到了惊人的效果。
- 编写了高度优化的 GPU 2D 卷积实现,并已公开。但该实现偏硬件,新手建议从caffe入手。
- 采取了许多抑制过拟合的措施;虽然数据库很大,但是参数也很多,过拟合很严重。
- 该网络只包含5个卷积层,参数量只占了不到5%,但缺一不可(效果会变差);发现深度很重要。
- 当前的工作仅仅受到硬件水平的限制,还有很大的发展空间。
5. 网络设计

根据重要性依次排序,该网络有以下创新:
A. ReLU
之前使用的 tanh 和 sigmoid 激活函数都存在饱和区。
改用无饱和的 ReLU ,收敛速度可以达到数倍于 tanh !
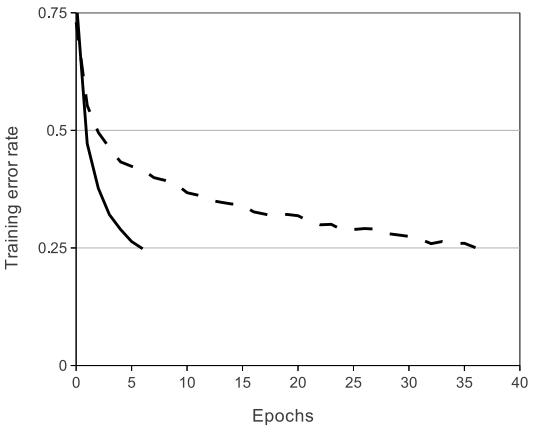
实验:同一个4层卷积网络,要求在 CIFAR-10 上达到25%准确率,分别测试 ReLU (实线)和 tanh (虚线),如图。
B. Training on Multiple GPUs
2个 GPU 协同,最直接的作用是加快了训练速度。
作者尝试将网络改为单GPU,同时保证参数数量不变,速度略逊于双 GPUs 。
其次,这两个 GPU 实际上是有交互的。与独立工作相比,交互将准确率提高了1.2%以上。
最后,当时的 GPU 性能不够强大,显存只有3GB。
这种协同的思想可以将大任务分解为多个小任务执行。
C. Local Response Normalization
在真实神经元中,存在一种侧边抑制效应 lateral inhibition 。
简单来说,就是在一个小区域内,如果有一个神经元被激活,那么其附近的神经元会相对受到抑制。
换句话说,这是一种促进神经元局部竞争的机制。但这一点其实有点牵强。
受此启发,AlexNet 在某些层的非线性激活以后采用 Local Response Normalization ,公式如图:
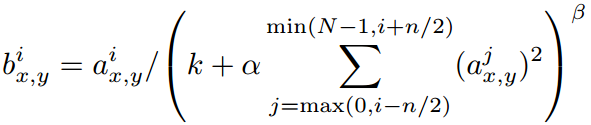
ReLU 的原始输出就是 \(\alpha_{x,y}^i\) ,位于第 \(i\) 个核的 \((x,y)\) 位置。
抑制是在不同核之间发生的,如图,在当前核的左右共 \(n\) 个通道上进行,核序号不要超过上限 \(N\) 和下限 \(0\) 。
显然,如果邻域内存在较大的 \(\alpha_{x,y}^j\) 而自身很小,那么除后将会小的可怜;如果反之,那么影响不大。
这样就拉开了“贫富差距”。
作者说明,该 trick 使得准确率提高了1.2%以上。
但据各路大神反馈,该 trick 基本无效。
D. Overlapping Pooling
实验证明,重叠池化可以更好地抑制过拟合,使准确率提高约0.4%和0.3%。
6. 抑制过拟合设计
A. Data Augmentation
最简单的抑制过拟合技术,就是 label-preserving transformations 。
简单来说,就是让图像进行各种不影响目标本质的变换,扩大数据量。
该网络采用的是简单的变换,不需要存储,并且用 CPU 即可实现,不影响正在计算上一个 batch 的 GPU 。
- 镜像对称变换;
- 图像光照强度和色彩变换。
第二点具体而言:
- 先提取 RGB 三通道分量;
- 对每一个通道分别进行主成分分析,提取出主成分;
- 然后再进行三通道的随机系数线性组合。
个人认为,先主成分分析可以减少数据量吧~
以上方案在抑制过拟合的同时,让准确率提升了至少1%。
B. Dropout
如果我们有多个不同的模型合作进行预测,那么泛化误差将会有效降低。
问题是,训练多个模型的计算成本很高昂。
Dropout 为我们提供了新思路:让这些模型分享相同的权重系数,但神经元的输出结果不尽相同。
这样,我们就相当于得到了许多模型。
具体而言,是让 hidden neuron 的输出有50%的概率被置零。
这样,每次反向传播时,参考的 loss 都是由不同模型计算得到的。
总的来说,Dropout 技术打破了神经元之间的依赖性,强迫网络学习更鲁棒的神经元连接。
我们只在全连接层使用,因为全连接层的连接非常多。
在测试阶段不采用 Dropout 。
Dropout 会延长收敛时间,但能有效抑制过拟合。
7. 讨论
作者发现,去掉网络中任意一个中间层,都会让整体表现下降2%左右。因此深度非常重要。
为了简化计算,作者并没有采用无监督的 pre-training 。
尽管 pre-training 可能可以在不提高数据量的同时,提升网络性能。
最后,深层次网络可以用于视频,以利用时间相关性。
IV. 网络加深
1. VGG Net, 2014
VGG 的深度是前所未有的,卷积层达到10个,全连接层有3个。
VGG 获得了 ImageNet2014 的分类赛冠军和定位赛亚军,并且泛化能力非常好。
Paper: Very deep convolutional networks for large-scale image recognition
重要贡献:探究了深度和滤波器尺寸的权衡问题,发现深度远比滤波器尺寸重要。
为了探究这一问题,滤波器尺寸固定为3x3,网络深度逐渐加深,同时进行实验。
为了保证客观,VGG Net 沿用了 AlexNet 的配置(ReLU等),但放弃了 LRN ,并且认为该 trick 不仅无效而且冗余。
下表是实验的几种配置,从左到右深度递增,对比效果:
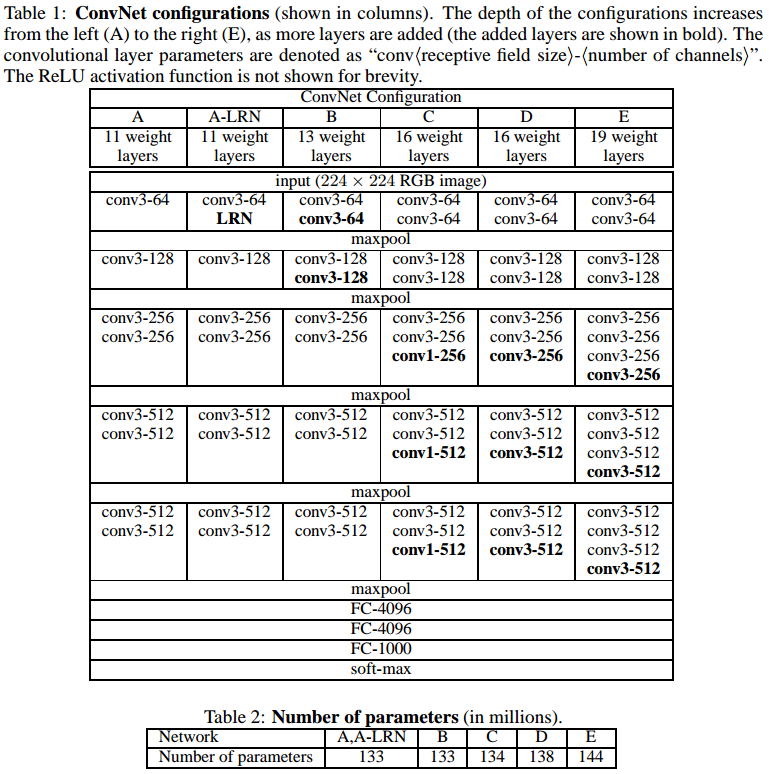
下表可以看到,不仅深度越深效果更好,而且多尺度训练的效果也更好:
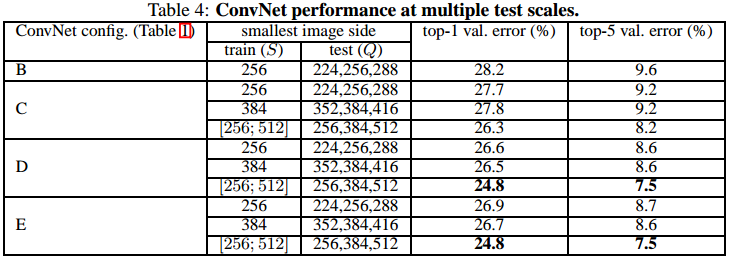
下表是当时各种网络的测试结果对比:
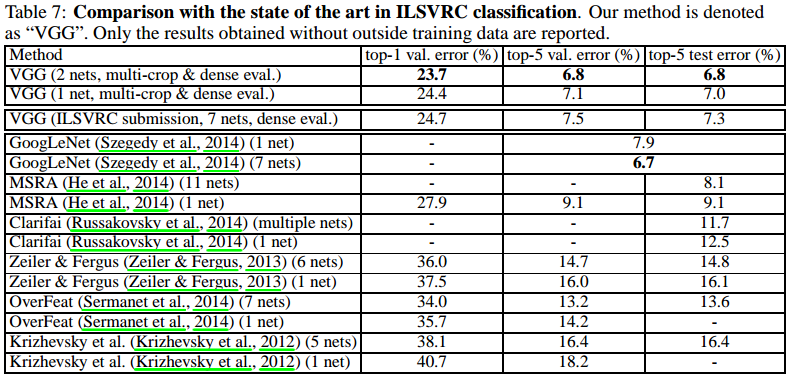
2. MSRA-Net, 2015
Paper: Convolutional neural networks at constrained time cost
A. 背景
时间成本控制很重要,特别是处理在线实时任务,多用户请求,移动终端处理等时。
这篇文章的重点就是时间成本控制。作者提到:
Most of the recent advanced CNNs are more timeconsuming than Krizhevsky et al.’s [14] original architecture in both training and testing.
The increased computational cost can be attributed to the increased width1 (numbers of filters) [21, 24, 1], depth (number of layers) [22, 23], smaller strides [21, 24, 22], and their combinations.
B. 实验方法
在实验中,时间成本是一个固定指标。时间成本用以下公式衡量:
\[
O(\sum_{l=1}^d n_{l-1} \cdot s_l^2 \cdot n_l \cdot m_l^2)
\]
四个参数分别代表:上一卷积层的滤波器个数,当前层滤波器尺寸,当前层滤波器个数和当前层 feature map 尺寸。
熟悉 CNN 的同学应该能理解这个公式:
- 输出 feature map 一共有 \(n_l\) 个通道,每一个通道有 \(m_l^2\) 个元素,因此输出一共有 \(n_l \cdot m_l^2\) 个元素;
- 每一个输出元素,和输入 feature map 的每一个卷积结果都有关;
- 而卷积发生在输入 feature map 的每一层,每一层卷积都只和同一个尺寸为 \(s_l\) 的滤波器有关。如果只考虑时间(大致是并行进行的),那么就是 \(n_{l-1} \cdot s_l^2\)。
在时间成本不变的条件下,我们调整滤波器尺寸、网络深度、滤波器个数( feature map 宽度)这三个关键参数,来判断哪个参数对网络性能更重要,从而在简化网络时着重保留。
与前人工作的不同之处主要有:
- 前人是固定总参数数目,这里是固定时间成本。
- 这里只研究卷积层。虽然全连接层和池化层参数占比最大,但是时间消耗通常只有 5-10% 。
- 通篇都是根据这个理论公式来计算权衡的,因为实际消耗时间和硬件等有关,不好限制,并且这个公式和实际情况也基本符合。
- 只研究 single-path 和 non-recursive 。
C. 实验设计
下表是实验中的网络配置情况和性能表现。
A是原始网络,采用的是最基本最普适的配置。
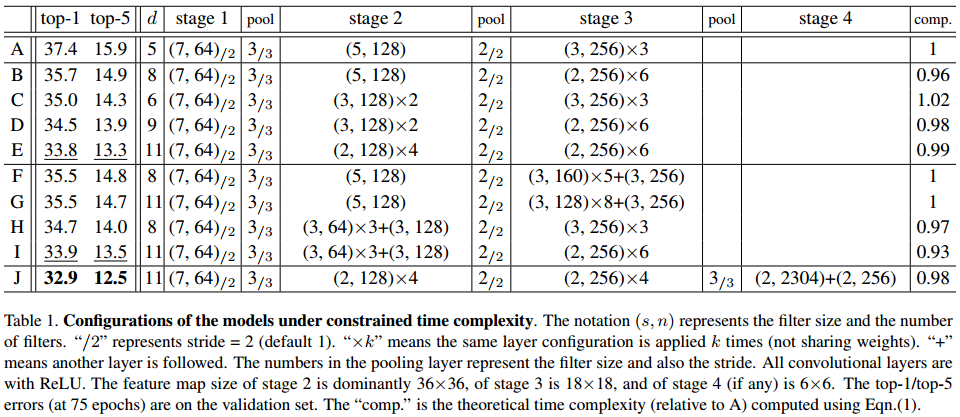
下面几张图片是图解:

通过理论公式计算,这些网络的时间复杂度都是一致的。
实验通过改变池化步长,来改变 feature map 的尺寸。
D. 实验结果
本文实验获得了以下几个重要结论:
- 网络深度是保证准确率的核心指标,比其余参数都重要,应该在 trade off 中倾斜考虑。
这个结论并非简单直接得到的,因为其他文章仅仅是堆叠更多层,但这篇文章是做了一个 trade off 来控制一定的时间成本。 - 当网络深度过度增加时,网络会存在退化现象,哪怕没有 trade off 也是如此。
经过分析,该现象并非是过拟合导致的,因为训练误差也特别大。
该现象为何凯明 ResNet 的创新埋下了伏笔。 - feature map 的宽度比尺寸重要。
- 我们通常在池化层就完成了降采样。实验发现,如果我们改为在卷积层中采用大步长,那么效果会更好。
最直接的效果是,作者仅用 AlexNet 40% 的复杂度,GPU 速度快20%,就实现了高4.2%的分类准确率。
Paper/ Overview | CNN(未完待续)的更多相关文章
- javascript有用小功能总结(未完待续)
1)javascript让页面标题滚动效果 代码如下: <title>您好,欢迎访问我的博客</title> <script type="text/javasc ...
- ASP.NET MVC 系列随笔汇总[未完待续……]
ASP.NET MVC 系列随笔汇总[未完待续……] 为了方便大家浏览所以整理一下,有的系列篇幅中不是很全面以后会慢慢的补全的. 学前篇之: ASP.NET MVC学前篇之扩展方法.链式编程 ASP. ...
- 关于DOM的一些总结(未完待续......)
DOM 实例1:购物车实例(数量,小计和总计的变化) 这里主要是如何获取页面元素的节点: document.getElementById("...") cocument.query ...
- 我的SQL总结---未完待续
我的SQL总结---未完待续 版权声明:本文为博主原创文章,未经博主允许不得转载. 总结: 主要的SQL 语句: 数据操作(select, insert, delete, update) 访问控制(g ...
- virtualbox搭建ubuntu server nginx+mysql+tomcat web服务器1 (未完待续)
virtualbox搭建ubuntu server nginx+mysql+tomcat web服务器1 (未完待续) 第一次接触到 linux,不知道linux的确很强大,然后用virtualbox ...
- MVC丶 (未完待续······)
希望你看了此小随 可以实现自己的MVC框架 也祝所有的程序员身体健康一切安好 ...
- 一篇文章让Oracle程序猿学会MySql【未完待续】
一篇文章让Oracle DB学会MySql[未完待续] 随笔前言: 本篇文章是针对已经能够熟练使用Oracle数据库的DB所写的快速学会MySql,为什么敢这么说,是因为本人认为Oracle在功能性方 ...
- [python]爬代理ip v2.0(未完待续)
爬代理ip 所有的代码都放到了我的github上面, HTTP代理常识 HTTP代理按匿名度可分为透明代理.匿名代理和高度匿名代理. 特别感谢:勤奋的小孩 在评论中指出我文章中的错误. REMOTE_ ...
- IOS之KVC和KVO(未完待续)
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- C++语言体系设计哲学的一些随想(未完待续)
对于静态类型语言,其本质目标在于恰当地操作数据,得到期望的值.具体而言,需要: (1)定义数据类型 你定义的数据是什么,是整形还是浮点还是字符.该类型的数据可以包含的值的范围是什么. (2)定义操作的 ...
随机推荐
- (转)SQLServer查询数据库各种历史记录
原文地址https://www.cnblogs.com/seusoftware/p/4826958.html 在SQL Server数据库中,从登陆开始,然后做了什么操作,以及数据库里发生了什么,大多 ...
- Avalon Master 外设
- Master公式计算递归时间复杂度
我们在算递归算法的时间复杂度时,Master定理为我们提供了很强大的便利! Master公式在我们的面试编程算法中除了BFPRT算法的复杂度计算不了之外,其他都可以准确计算! 这里用求数组最大值的递归 ...
- Linux的命令技巧
一.使用apt-get installl 方法安装的库或者程序一般的路径如下 1.下载的软件存放位置 /var/cache/apt/archives 2.安装后软件默认位置 /usr ...
- PHP运行出现Notice : Use of undefined constant 的解决办法
这些是 PHP 的提示而非报错,PHP 本身不需要事先声明变量即可直接使用,但是对未声明变量会有提示.一般作为正式的网站会把提示关掉的,甚至连错误信息也被关掉 关闭 PHP 提示的方法 搜索php.i ...
- Android倒计时实现
Android为我们封装好了一个抽象类CountDownTimer,可以实现计时器功能: /** * 倒数计时器 */ private CountDownTimer timer = new Count ...
- linux环境下载和安装scala
Linux下安装Scala和Windows下安装类似,步骤如下: 1.首先访问下载链接:http://www.scala-lang.org/download/默认这里下载的是Windows版本,这时点 ...
- ios怎么让状态栏颜色和导航栏背景图片颜色一样
ios7 图片作为导航的背景的话,如果想实现状态栏和导航栏一体化,那么图片高度需要增加22,也就是64,retina是128
- BASIC GIT WORKFLOW
BASIC GIT WORKFLOW Generalizations You have now been introduced to the fundamental Git workflow. You ...
- SSM商城项目(十)
1. 学习计划 1.使用freemarker实现网页静态化 a)Freemarker的使用方法 b)Freemarker模板的语法 c)Freemarker整合springmvc 2.Active ...