Apache Flume 1.7.0 源码编译 导入Eclipse
前言
最近看了看Apache Flume,在虚拟机里跑了一下flume + kafka + storm + mysql架构的demo,功能很简单,主要是用flume收集数据源(http上报信息),放入到kafka队列里,然后用storm消费kafka里的资源,计算结果并存入到mysql中;
在这期间遇到了很多问题,也学到了一些知识,打算做个笔记吧,帮助自己也帮助别人;
先从Flume源码的编译开始;
下载
下载源码很简单,去官网或者去github下载,Apache Flume 1.7.0的github源码地址如下:
https://github.com/apache/flume/tree/release-1.7.0
Maven编译安装
在mvn install之前,最好先设置下maven的国内镜像地址,加快依赖的下载速度,时间还是很宝贵的,别浪费在无聊的等待上,
打开maven的setting.xml配置文件,添加如下镜像即可:
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
--> <mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror> </mirrors>
在控制台输入如下命令,后面的参数表示跳过单元测试
mvn install -Dmaven.test.skip=true
很快就开始下载依赖了,骚等片刻:
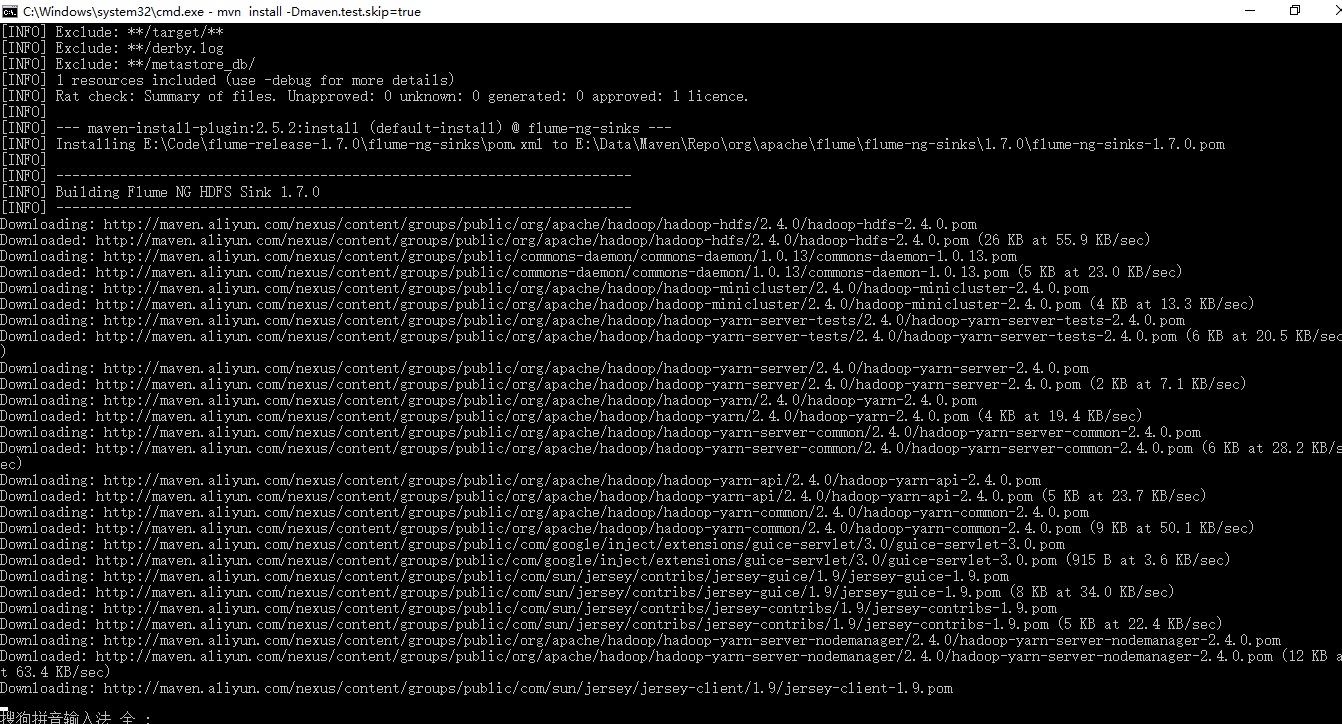
遗憾的是报错了,坑爹,又是国外的网络不能访问,ping下maven.twttr.com,果真不行,哎,,,
[ERROR] Failed to execute goal on project flume-ng-morphline-solr-sink: Could not resolve dependencies for project org.apache.flume.flume-ng-sinks:flume-ng-morphline-solr-sink:jar:1.7.0: Failed to collect dependencies at org.kitesdk:kite-morphlines-all:pom:1.0.0 -> org.kitesdk:kite-morphlines-useragent:jar:1.0.0 -> ua_parser:ua-parser:jar:1.3.0: Failed to read artifact descriptor for ua_parser:ua-parser:jar:1.3.0: Could not transfer artifact ua_parser:ua-parser:pom:1.3.0 from/to maven-twttr (http://maven.twttr.com): maven.twttr.com: Unknown host maven.twttr.com -> [Help 1]
网上找了半天解决方案,搞什么代理啊 VPN什么的,有点麻烦,好在找到了一个ip,添加到hosts里即可,如下:
199.16.156.89 maven.twttr.com
添加完host后,继续执行mvn install -Dmaven.test.skip=true,耐心等待...
结果等了半天,还是不行,卡在这,又是坑爹的天朝网络,速度真的太慢了,没办法。。。。。conjars.org的访问速度真心太慢...
Downloading: http://conjars.org/repo/eigenbase/eigenbase-properties/1.1.4/eigenbase-properties-1.1.4.pom
多试几次吧,反正我是试了好几次,最后终于成功了,也可以尝试在父pom.xml加个repository,如下,实在不行,真的只能代理了,或者把别人已经下好的依赖拷贝到自己的maven本地仓库。
<repositories>
<repository>
<id>nexus.axiomalaska.com</id>
<url>http://nexus.axiomalaska.com/nexus/content/repositories/public</url>
</repository>
</repositories>

导入Eclipse
这个没啥好说的,直接导入maven工程即可,遗憾的是flume-ng-core工程还是报错,如下:
TransferStateFileMeta cannot be resolved to a type
仔细看看源码,发现确实没有定义TransferStateFileMeta 这个类,这就尴尬了,在检查下,发现pom.xml有错误,需要安装,execution元素那边报错了,鼠标放上去,提示需要安装相应插件,那就安装吧,骚等片刻,终于安装好了,update下maven工程,pom.xml也没报错了。。。
坑爹的是发现还是报那个错误
TransferStateFileMeta cannot be resolved to a type
不过发现问题还是出在pom.xml里的build-helper-maven-plugin这个插件的配置上,好像原因是DurablePositionTracker引用的TransferStateFileMeta这个类是自动生成的,查看target目录,确实找到了这个类,但是为什么还是报错,仔细观察,原来是source没配对,因为TransferStateFileMeta类是在generated-sources的avro目录下的,那就增加个目录呗,在sources节点增加<source>target/generated-sources/avro</source>,如下所示。。
<executions>
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>target/generated-sources/java</source>
<source>target/generated-sources/avro</source>
</sources>
</configuration>
</execution>
</executions>
update下工程,终于Ok了,没报任何错误。。。(如果还有错的话,试着先执行mvn eclipse:eclipse命令后再导入)
Apache Flume 1.7.0 源码编译 导入Eclipse的更多相关文章
- 使用Maven将Hadoop2.2.0源码编译成Eclipse项目
编译环境: OS:RHEL 6.3 x64 Maven:3.2.1 Eclipse:Juno SR2 Linux x64 libprotoc:2.5.0 JDK:1.7.0_51 x64 步骤: 1. ...
- hadoop-2.6.0源码编译问题汇总
在上一篇文章中,介绍了hadoop-2.6.0源码编译的一般流程,因个人计算机环境的不同, 编译过程中难免会出现一些错误,下面是我编译过程中遇到的错误. 列举出来并附上我解决此错误的方法,希望对大家有 ...
- ambari 2.5.0源码编译安装
参考:https://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/index.html Ambari 是什么 Ambar ...
- hadoop-1.2.0源码编译
以下为在CentOS-6.4下hadoop-1.2.0源码编译步骤. 1. 安装并且配置ant 下载ant,将ant目录下的bin文件夹加入到PATH变量中. 2. 安装git,安装autoconf, ...
- Spark1.0.0 源码编译和部署包生成
问题导读:1.如何对Spark1.0.0源码编译?2.如何生成Spark1.0的部署包?3.如何获取包资源? Spark1.0.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对 ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- Tomcat8.0源码编译
最近打算开始研究一下Tomcat的工作原理,拜读一下源码.所以先从编译源码开始了.尽管网上有那么多的资料,但是总是觉得,自己研究一遍,写一遍,在动手做一遍能够让我们更加深入的了解.现在整个社会都流行着 ...
- hadoop-2.0.0-mr1-cdh4.2.0源码编译总结
准备编译hadoop-2.0.0-mr1-cdh4.2.0的同学们要谨慎了.首先看一下这篇文章: Hadoop作业提交多种方案 http://www.blogjava.net/dragonHadoop ...
- Ubantu16.04进行Android 8.0源码编译
参考这篇博客 经过测试,8.0源码下载及编译之后,占用100多G的硬盘空间,尽量给ubantu系统多留一些硬盘空间,如果后续需要在编译好的源码上进行开发,需要预留更多的控件,为了防止后续出现文件权限问 ...
随机推荐
- 符合Chrome58的证书制作
Chrome 58开始取消了对通用名检查的支持, 但网上大多数OpenSSL使用教程没有提及这一点, 制作出的证书总是提示ERR_CERT_COMMON_NAME_INVALID 错误, 所以分享出解 ...
- 杨其菊201771010134《面向对象程序设计(java)》第一周学习总结
第一部分:课程准备部分 填写课程学习 平台注册账号, 平台名称 注册账号 博客园:www.cnblogs.com 安迪儿 程序设计评测:https://pintia.cn/ 迷路的麋鹿回不来家了 代码 ...
- centos7通过yum安装JDK1.8
安装之前先检查一下系统有没有自带open-jdk 命令: rpm -qa |grep java rpm -qa |grep jdk rpm -qa |grep gcj 如果没有输入信息表示没有安装. ...
- JavaScript 方法
对象的定义 var xiaoming = { name: '小明', birth: 1990 }; 是,如果我们给xiaoming绑定一个函数,就可以做更多的事情.比如,写个age()方法,返回xia ...
- java30
1.类的组合关系 当一个类中的字段是一个类时,就称类依赖于字段这个类,也称这两个类为组合关系 2.快捷键:ctrl+shift+c,多行的// ctrl+shift+/,多行的/-----/ 3.类的 ...
- springMVC学习 十二 拦截器
一 拦截器概述 拦截器技术比较像java web技术中的过滤器技术,都是发送 请求时被拦截器拦截,在控制器的前后添加额外功能.但是和Spring中的Aop技术是由区别的.AOP 在特定方法前后扩充(一 ...
- innodb_flush_method理解
http://blog.csdn.net/gua___gua/article/details/44916207 innodb_flush_method这个参数控制着innodb数据文件及redo lo ...
- spring web参数传递
spring boot 参数相关 ****************************************** @RequestParam 这个注解用来绑定单个请求数据,既可以是url中的 ...
- nginx简单权限配置
一.指定ip段 location / { allow 172.17.0.1/24; deny all; } 二.指定认证账户 location / { auth_basic "please ...
- LOJ-10105(欧拉回路模板,套圈法,递归)
题目链接:传送门 思路: (1)用邻接表存储有向图和无向图,有向图和无向图的每条边均站两个单元,无向图有正向边和反向边的区分. (2)有向图有欧拉回路:所有点的入度=出度: 无向图有欧拉回路:所有点的 ...