json and pickle 序列化
前言
文件只能存储字符串、二进制,若把内存的数据对象存到硬盘 从硬盘里读取数据,里面不止是字符串的类型,因此用到了json and pickle 序列化
json序列化
作用:用于不同语言进行的数据交互,json默认只能处理简单化的数据类型:字典、列表、字符串。为何只能处理简单的数据类型?因为java里的类和pyhton的类完全不一样,定义、特性等
文件只能存储字符串、二进制,例如将数据字典的数据类型写入文件,报错
按之前学过的知识对文件序列化
info = {
"name":"Mike",
"age":16
}
f = open("json1","w",encoding = "utf-8")
f.write(info)
f.close()
结果:
Traceback (most recent call last):
File "E:/python_3.5/second/json模块/json1.py", line 6, in <module>
f.write(info)
TypeError: write() argument must be str, not dict
数据类型为字符串已存入文件
info = {
"name":"Mike",
"age":16
}
f = open("json1","w",encoding = "utf-8")
f.write(str(info))
f.close()
写入的json1文件
{'age': 16, 'name': 'Mike'}
用json.dumps()序列化
import json
info = {
"name":"Mike",
"age":16
}
f = open("json1","w",encoding = "utf-8")
#print(json.dumps(info)) #结果{"age": 16, "name": "Mike"}
f.write(json.dumps(info)) 写入文件
{"age": 16, "name": "Mike"}
json.dump()序列化
不用写f.write() 将文件句柄传入
import json
info = {
"name":"Mike",
"age":16,
#"fun":sayhi
} f = open("json1","w",encoding = "utf-8”)
json.dump(info,f) 写入文件:
{"age": 16, "name": "Mike"}
json.loads()反序列化
按之前学过的知识对文件反序列化
f = open("json1","r",encoding = "utf-8")
data = eval(f.read())
print(data)
print(data["age"])
结果:
{'age': 16, 'name': 'Mike'}
16
用json反序列化读取文件
import json
f = open("json1","r",encoding = "utf-8")
data = json.loads(f.read())
print(data["age"])
结果
16
json.load()反序列化
import json
f = open("json1","r")
# data = pickle.loads(f.read())
print(json.load(f)) 结果:
{'age': 16, 'name': 'Mike'}
pickle.dumps() 序列化
pickle只有在Python本语言里使用,java不认识pickle数据类型,只认识json数据类型
pickle可以序列化python里的所有数据类型
import pickle
def sayhi():
print("hello")
info = {
"name":"Mike",
"age":16,
"fun":sayhi
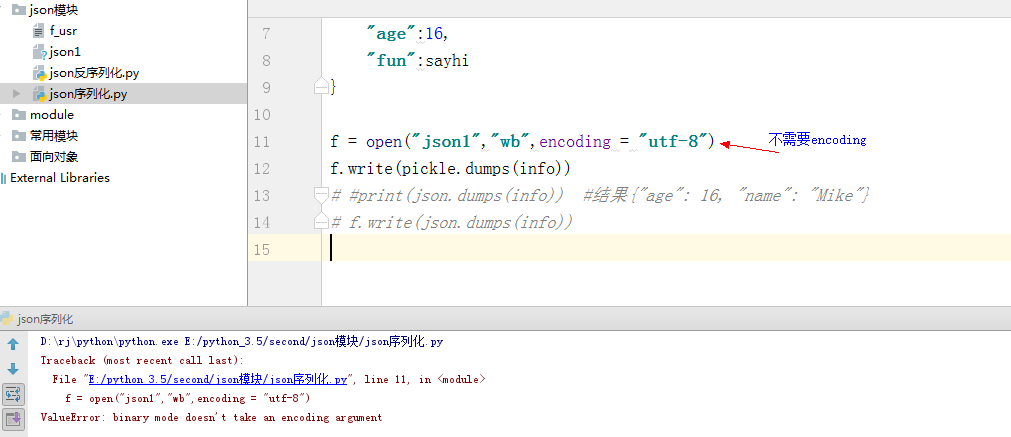
} f = open("json1","wb")
f.write(pickle.dumps(info))
写入的文件

注意:
pickle.loads() 反序列化
import pickle
def sayhi():
print("hello") #为何这里要再写一遍,在序列化时程序结束函数的内存地址已经被释放了 已找不到 f = open("json1","rb")
data = pickle.loads(f.read())
print(data["age"])
print(data)
结果:
16
{'name': 'Mike', 'fun': <function sayhi at 0x005D2FA8>, 'age': 16}
json and pickle 序列化的更多相关文章
- (转)python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
阅读目录 1.1.1导入模块 1.1.2__name__ 1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代 ...
- python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文 ...
- Python的json and pickle序列化
json序列化和json反序列化 #!/usr/bin/env python3 # -*- coding: utf-8 -*- __author__ = '人生入戏' import json a = ...
- (1)json和pickle序列化模块
json 和pickle 模块 json和pickle模块下都有4个功能 dumps <---> loads (序列化 <--->反序列化) dump <---> ...
- Python3 json、pickle序列化与反序列化
注意:可以dumps多次,loads只能一次,一般我们只dumps一次,loads一次,多个版本就写入多个文件 一.json序列化与反序列化: 支持各种语言数据交互,但只能处理字典,列表,集合等简单的 ...
- json和pickle序列化模块
一.json序列化模块 1.序列化:将内存数据转成字符串加以保存. 2.反序列化:将字符串转成内存数据加以读取. data = { '北京':{ '五道口':{ 'sohu':'引擎', } } } ...
- python 跨语言数据交互、json、pickle(序列化)、urllib、requests(爬虫模块)、XML。
Python中用于序列化的两个模块 json 用于[字符串]和 [python基本数据类型] 间进行转换 pickle 用于[python特有的类型] 和 [python基本数据类型]间进 ...
- json and pickle 序列化和反序列化
类似vmware虚拟机里的虚拟主机挂起操作,把当前内存拷贝成文件保存. 上面的这种操作就叫内存序列化:如下图: 有序列化就有反序列化,要把文件里的东西再恢复成字典:eval把字符串变成字典. 但是上面 ...
- python学习之day5,装饰器,生成器,迭代器,json,pickle
1.装饰器 import os import time def auth(type): def timeer(func): def inner(*args,**kwargs): start = tim ...
随机推荐
- Python全栈之路----Python基础元素
1.变量定义规则 声明变量 name = " Alex Li" 其中,name是变量名(标识符),"Alex Li" ...
- spring jpa + mybatis快速开始:
springmvc开始搭建 源码地址 https://gitee.com/flydb/spingjpamy pom: <packaging>war</packaging> &l ...
- angular 使用window事件
1. 使用host 2. 使用HostListener 推荐使用第二种方式. 不推荐下面的方法,虽然也能进行window事件的绑定,但组件销毁后,window事件任然保留,即使手动在组件的ngOn ...
- IIS 集成模式 导致 AjaxPro 无法正常运行
web.config 配置如下: system.web/httphandlers <httpHandlers> <add verb="POST,GET" path ...
- JVM的基本结构及其各部分详解(一)
1 java虚拟机的基本结构如图: 1)类加载子系统负责从文件系统或者网络中加载Class信息,加载的类信息存放于一块称为方法区的内存空间.除了类的信息外,方法区中可能还会存放运行时常量池信息,包括字 ...
- DevExpress GridView 整理(转)
DevExpress GridView 那些事儿 1:去除 GridView 头上的 "Drag a column header here to group by that column&q ...
- Ubuntu更新时提示错误 E: Sub-process /usr/bin/dpkg returned an error code (1)
$ sudo su //root权限 $ sudo mv /var/lib/dpkg/info /var/lib/dpkg/info_old //现将info文件夹更名 $ sudo mkdir /v ...
- 【python】numpy中的shape用法
转自 https://blog.csdn.net/u010758410/article/details/71554224# shape函数是numpy.core.fromnumeric中的函数,它的功 ...
- 斐讯自动下单抢购V1.3.4【自动验证码识别】
20180530 更新 V1.3.41.增加有货下单:替代定时下单 20180519 更新 V1.3.31.增加订单满减优惠:支付宝每单立减5元2.修改商城域名及下单速度 功能介绍1.斐讯商城抢购专用 ...
- Promise事件比timeout优先
Promise, setTimeout 和 Event Loop 下面的代码段,为什么输出结果是1,2,3,5,4而非1,2,3,4,5?(function test() { setTimeout(f ...