深入理解 JVM(上)
菜鸟拙见,望请纠正(首先:推荐一本书【链接:https://pan.baidu.com/s/15I062n5LPYtRmueAAUFuFA 密码:kyo1】)
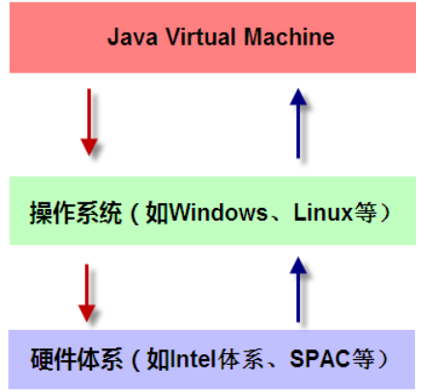
一:JVM体系概述
1:JVM是运行在操作系统之上的,他与硬件没有直接的交互。
二:JVM内存结构
Java虚拟机在运行时,会把内存空间分为若干个区域。Java虚拟机所管理的内存区域分为如下部分:方法区、堆内存、虚拟机栈、本地方法栈、程序计数器。
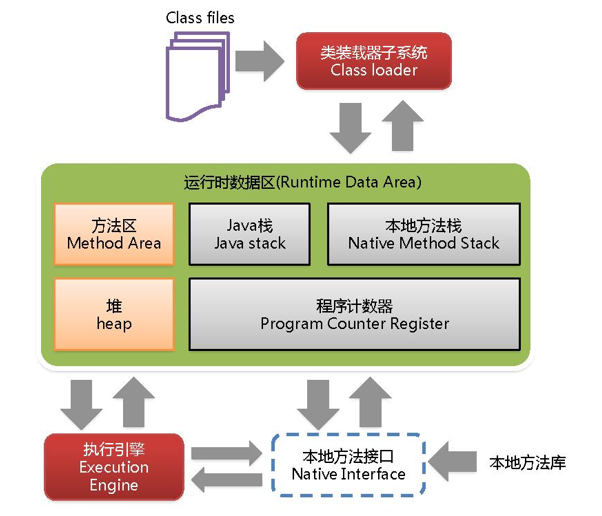
1、类装载器ClassLoader
负责加载class文件,class文件在文件开头有特定的文件标识,并且ClassLoader只负责class文件的加载,至于它是否可以运行,则是由执行引擎(Execution Engine)决定。
虚拟机自带的加载器:
启动类加载器(Bootstrap):由C++编写,不是前端框架Bootstrap。
扩展类加载器(Extension):由Java语言编写
应用程序类加载器(App):由Java语言编写,也叫系统类加载器,加载当前应用的classpath的所有类。
用户自定义加载器
Java.lang.ClassLoader的之类,用户可以定制的加载方式。
类加载器的双亲委派机制
某个特定的类加载器在加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成该加载任务时,才自己去加载。
沙箱机制(防止恶意代码对java本身的破坏)
当用户命名了和Java一样的类时,Java会首先加载自带的类。
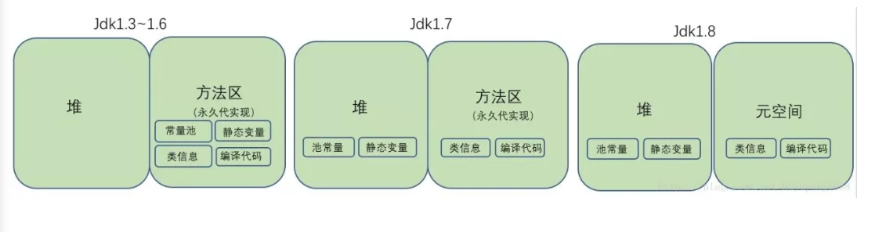
2、方法区
方法区是线程共享的,通常用来保存装载的类的元结构信息。主要用于存储虚拟机加载的类信息、常量、静态变量,以及编译器编译后的代码等数据。
在jdk1.7及其之前,方法区是堆的一个“逻辑部分”(一片连续的堆空间)。也有人用“永久代”表示方法区。
在jdk1.8中,方法区已经不存在,原方法区中存储的类信息、编译后的代码数据等已经移动到了元空间(MetaSpace)中,元空间并没有处于堆内存上,而是直接占用的本地内存(NativeMemory)。
3:堆内存
一个JVM实例只存在一个堆内存,堆内存的大小是可以调节的。类加载器读取了类文件后,需要把类,方法,穿变量放到堆内存中去,
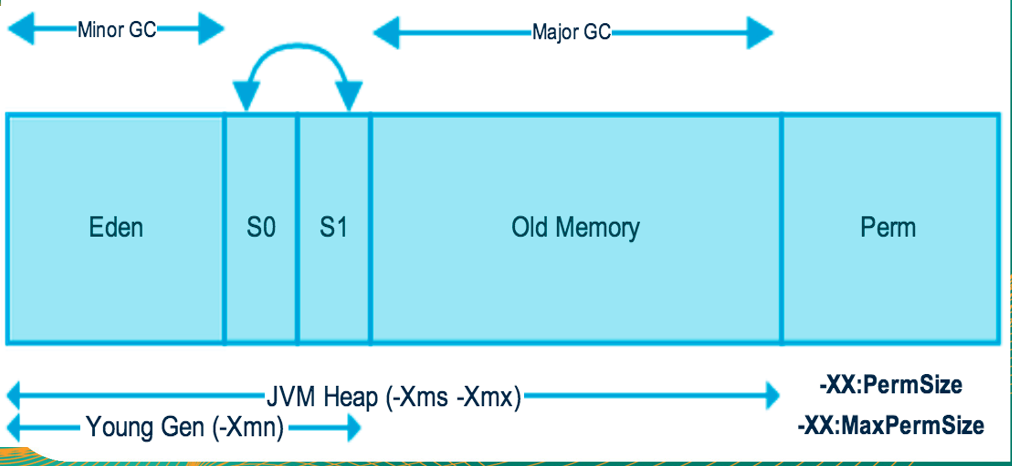
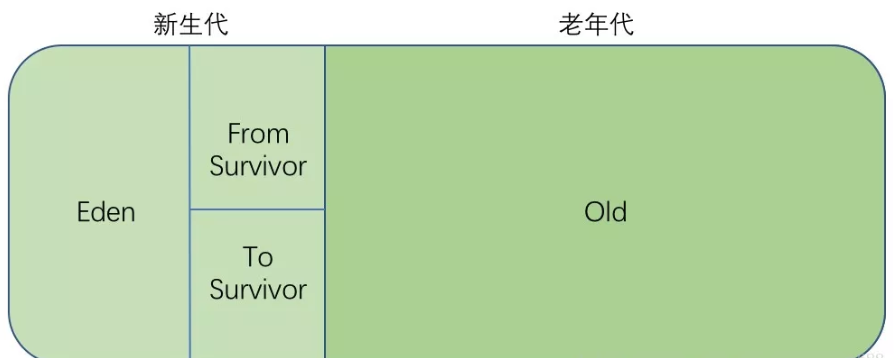
它是JVM管理的内存中最大的一块区域,堆内存和方法区都被所有线程共享,在虚拟机启动时创建。在垃圾收集的层面上来看,由于现在收集器基本上都采用分代收集算法,因此堆还可以分为新生代(YoungGeneration)和老年代(OldGeneration),新生代还可以分为Eden、From Survivor、To Survivor。
JAVA1.7如下图,但在Java1.8中,其他基本没变,只是将Perm变成了元空间
4:程序计数器
程序计数器是一块非常小的内存空间,可以看做是当前线程执行字节码的行号指示器,每个线程都有一个独立的程序计数器,因此程序计数器是线程私有的一块空间,此外,程序计数器是Java虚拟机规定的唯一不会发生内存溢出的区域。
5:虚拟机栈
虚拟机栈也是每个线程私有的一块内存空间,它描述的是方法的内存模型。
虚拟机会为每个线程分配一个虚拟机栈,每个虚拟机栈中都有若干个栈帧,每个栈帧中存储了局部变量表、操作数栈、动态链接、返回地址等。一个栈帧就对应Java代码中的一个方法,当线程执行到一个方法时,就代表这个方法对应的栈帧已经进入虚拟机栈并且处于栈顶的位置,每一个Java方法从被调用到执行结束,就对应了一个栈帧从入栈到出栈的过程。
6、本地方法栈
虚拟机栈执行的是Java方法,本地方法栈执行的是本地方法(Native Method),其他基本上一致
7:元空间
上面说到,jdk1.8中,已经不存在永久代(方法区),替代它的一块空间叫做“元空间”,和永久代类似,都是JVM规范对方法区的实现,但是元空间并不在虚拟机中,而是使用本地内存,元空间的大小仅受本地内存限制,但可以通过-XX:MetaspaceSize和-XX:MaxMetaspaceSize来指定元空间的大小。
三:垃圾回收机制
垃圾回收,就是通过垃圾收集器把内存中没用的对象清理掉。垃圾回收涉及到的内容有:1、判断对象是否已死;2、选择垃圾收集算法;3、选择垃圾收集的时间;4、选择适当的垃圾收集器清理垃圾(已死的对象)。
1:判断对象是否以死
判断对象是否已死就是找出哪些对象是已经死掉的,以后不会再用到的,就像地上有废纸、饮料瓶和百元大钞,扫地前要先判断出地上废纸和饮料瓶是垃圾,百元大钞不是垃圾。判断对象是否已死有引用计数算法和可达性分析算法。
(1)引用计数算法
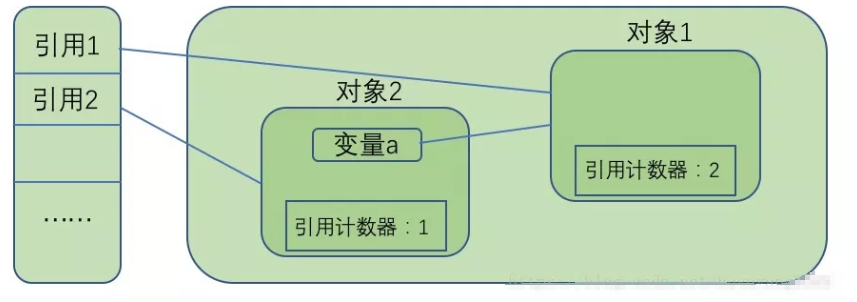
给每一个对象添加一个引用计数器,每当有一个地方引用它时,计数器值加1;每当有一个地方不再引用它时,计数器值减1,这样只要计数器的值不为0,就说明还有地方引用它,它就不是无用的对象。如下图,对象2有1个引用,它的引用计数器值为1,对象1有两个地方引用,它的引用计数器值为2 。
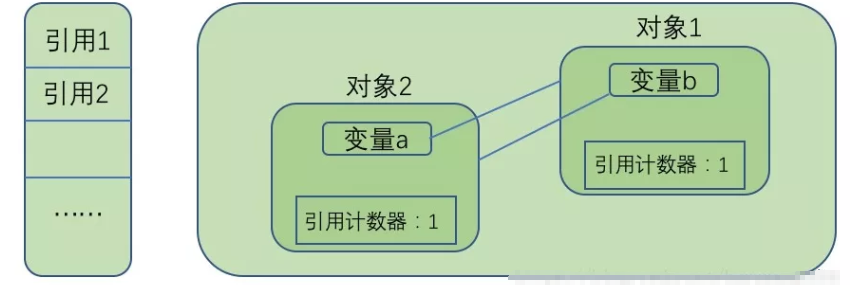
这种方法看起来非常简单,但目前许多主流的虚拟机都没有选用这种算法来管理内存,原因就是当某些对象之间互相引用时,无法判断出这些对象是否已死,如下图,对象1和对象2都没有被堆外的变量引用,而是被对方互相引用,这时他们虽然没有用处了,但是引用计数器的值仍然是1,无法判断他们是死对象,垃圾回收器也就无法回收。
(2)可达性分析算法
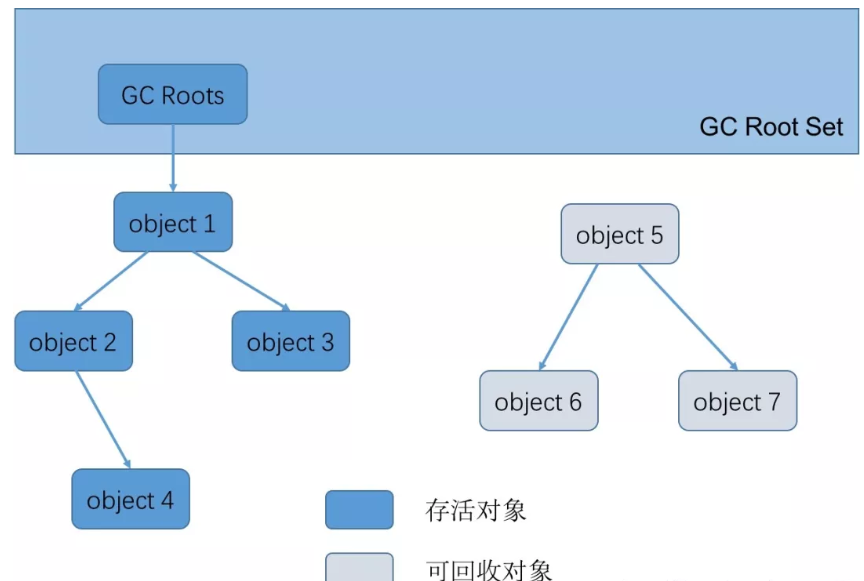
了解可达性分析算法之前先了解一个概念——GC Roots,垃圾收集的起点,可以作为GC Roots的有虚拟机栈中本地变量表中引用的对象、方法区中静态属性引用的对象、方法区中常量引用的对象、本地方法栈中JNI(Native方法)引用的对象。
当一个对象到GC Roots没有任何引用链相连(GC Roots到这个对象不可达)时,就说明此对象是不可用的,是死对象。如下图:object1、object2、object3、object4和GC Roots之间有可达路径,这些对象不会被回收,但object5、object6、object7到GC Roots之间没有可达路径,这些对象就被判了死刑。
(3)方法区回收
上面说的都是对堆内存中对象的判断,方法区中主要回收的是废弃的常量和无用的类。
判断常量是否废弃可以判断是否有地方引用这个常量,如果没有引用则为废弃的常量。
判断类是否废弃需要同时满足如下条件:
- 该类所有的实例已经被回收(堆中不存在任何该类的实例)
- 加载该类的ClassLoader已经被回收
- 该类对应的java.lang.Class对象在任何地方没有被引用(无法通过反射访问该类的方法)
2、常用垃圾回收算法
(1)标记-清除算法:分为标记和清除两个阶段,首先标记出所有需要回收的对象,标记完成后统一回收所有被标记的对象,如下图。
缺点:标记和清除两个过程效率都不高;标记清除之后会产生大量不连续的内存碎片。
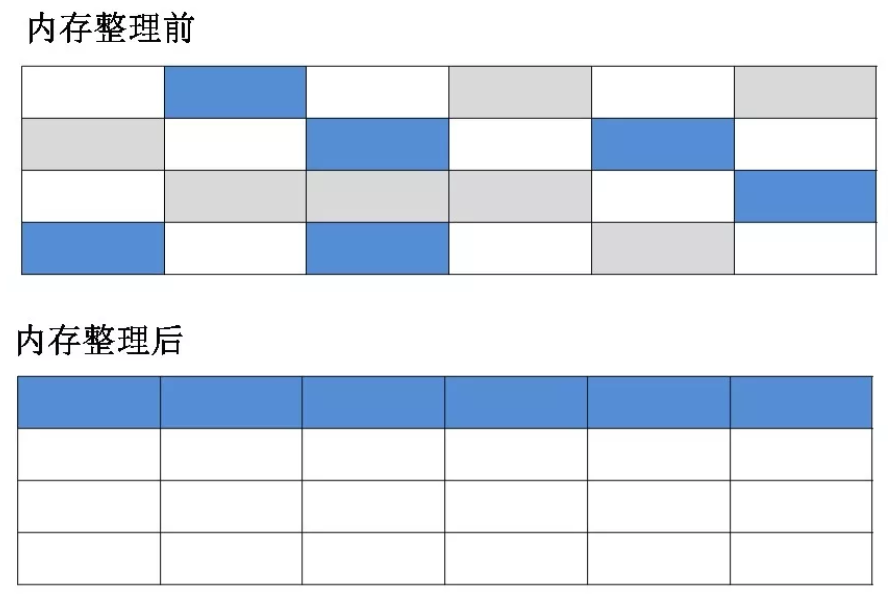
(2)复制算法:把内存分为大小相等的两块,每次存储只用其中一块,当这一块用完了,就把存活的对象全部复制到另一块上,同时把使用过的这块内存空间全部清理掉,往复循环,如下图。
缺点:实际可使用的内存空间缩小为原来的一半,比较适合。
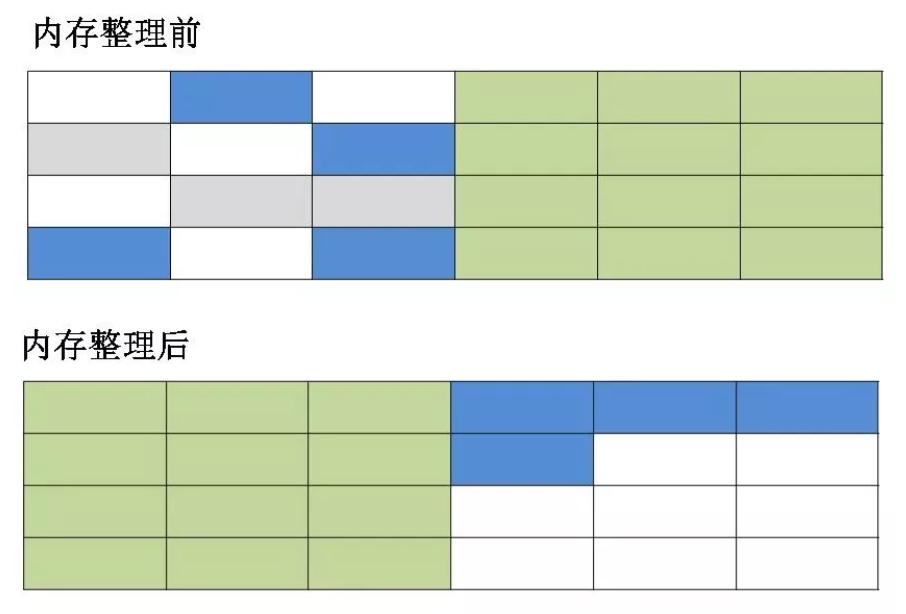
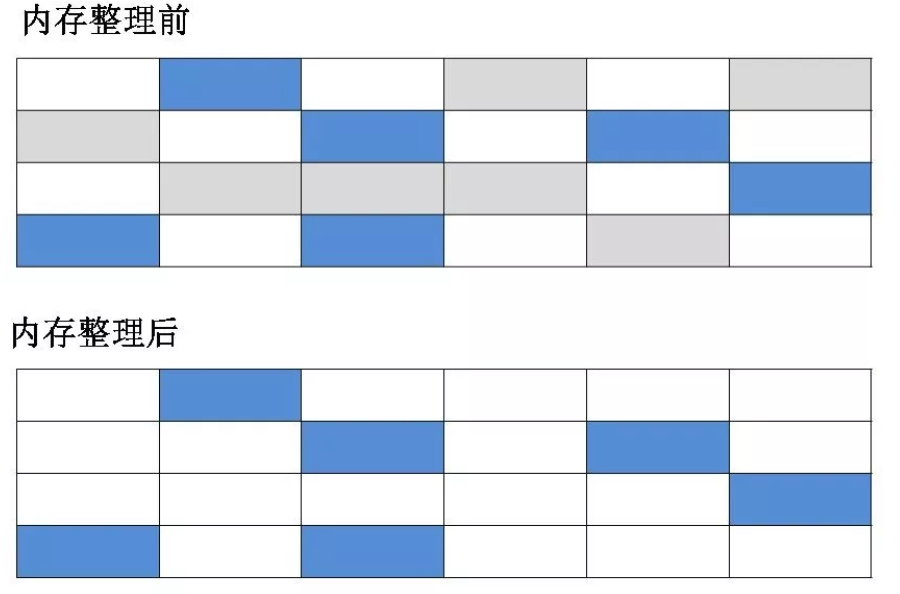
(3)标记-整理算法:先对可用的对象进行标记,然后所有被标记的对象向一段移动,最后清除可用对象边界以外的内存,如下图。
(4)分代收集算法:把堆内存分为新生代和老年代,新生代又分为Eden区、From Survivor和To Survivor。一般新生代中的对象基本上都是朝生夕灭的,每次只有少量对象存活,因此采用复制算法,只需要复制那些少量存活的对象就可以完成垃圾收集;老年代中的对象存活率较高,就采用标记-清除和标记-整理算法来进行回收。
3、选择垃圾收集的时间
当程序运行时,各种数据、对象、线程、内存等都时刻在发生变化,当下达垃圾收集命令后就立刻进行收集吗?肯定不是,他们要在保证线程安全的前提下进行垃圾回收
安全点:从线程角度看,安全点可以理解为是在代码执行过程中的一些特殊位置,当线程执行到安全点的时候,说明虚拟机当前的状态是安全的,如果有需要,可以在这里暂停用户线程。当垃圾收集时,如果需要暂停当前的用户线程,但用户线程当时没在安全点上,则应该等待这些线程执行到安全点再暂停。理论上,解释器的每条字节码的边界上都可以放一个安全点,实际上,安全点基本上以“是否具有让程序长时间执行的特征”为标准进行选定。
安全区:安全点是相对于运行中的线程来说的,对于如sleep或blocked等状态的线程,收集器不会等待这些线程被分配CPU时间,这时候只要线程处于安全区中,就可以算是安全的。安全区就是在一段代码片段中,引用关系不会发生变化,可以看作是被扩展、拉长了的安全点。
4、常见垃圾收集器
新生代收集器:Serial、ParNew、Parallel Scavenge
老年代收集器:Serial Old、CMS、Parallel Old
堆内存垃圾收集器:G1
这些垃圾收集器同样很重要,可以自行百度了解其原理。
深入理解 JVM(上)的更多相关文章
- 深入理解JVM内幕(转)
转自:http://blog.csdn.net/zhoudaxia/article/details/26454421/ 每个Java开发者都知道Java字节码是执行在JRE((Java Runtime ...
- 深入理解JVM内幕:从基本结构到Java 7新特性
转自:http://www.importnew.com/1486.html 每个Java开发者都知道Java字节码是执行在JRE((Java Runtime Environment Java运行时环境 ...
- 深入理解JVM—字节码执行引擎
原文地址:http://yhjhappy234.blog.163.com/blog/static/3163283220122204355694/ 前面我们不止一次的提到,Java是一种跨平台的语言,为 ...
- [译]深入理解JVM
深入理解JVM 原文链接:http://www.cubrid.org/blog/dev-platform/understanding-jvm-internals 每个使用Java的开发者都知道Java ...
- 深入理解JVM垃圾收集机制(JDK1.8)
垃圾收集算法 标记-清除算法 最基础的收集算法是"标记-清除"(Mark-Sweep)算法,分两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象. 不足: ...
- JVM上的响应式流 — Reactor简介
强烈建议先阅读下JVM平台上的响应式流(Reactive Streams)规范,如果没读过的话. 官方文档:https://projectreactor.io/. 响应式编程 作为响应式编程方向上的第 ...
- 深入理解JVM(一)编译openJDK
此文总结的很不错:https://www.cnblogs.com/ACFLOOD/p/5528035.html 准备openJDK源码和环境 1.在linux和macOS上编译openJDK更加友好, ...
- 走进JVM【二】理解JVM内存区域
引言 对于C++程序员,内存分配与回收的处理一直是令人头疼的问题.Java由于自身的自动内存管理机制,使得管理内存变得非常轻松,不容易出现内存泄漏,溢出的问题. 不容易不代表不会出现问题,一旦内存泄漏 ...
- 《深入理解JVM虚拟机》读书笔记
前言:<深入理解JVM虚拟机>是JAVA的经典著作之一,因为内容更偏向底层,所以之前一直没有好好的阅读过.最近因为刚好有空,又有了新目标.所以打算和<构架师的12项修炼>一起看 ...
随机推荐
- 微信小程序 thirdScriptError sdk uncaught third Error regeneratorRuntime is not defined ReferenceError: regeneratorRuntime is not defined
thirdScriptError sdk uncaught third Error regeneratorRuntime is not defined ReferenceError: regenera ...
- vue和webpack打包 项目相对路径修改
一般vue使用webpack打包是整个工程的根目录,但是很多情况下都是把vue打包后的文件在某子目录下. 修改: 1,打开index.js assetsPublicPath:'/' 改为: asset ...
- 网络基础 http 会话(session)详解
http 会话(session)详解 by:授客 QQ:1033553122 会话(session)是一种持久网络协议,在用户(或用户代理)端和服务器端之间创建关联,从而起到交换数据包的作用机制 一. ...
- js,H5本地存储
//存储本地存储----setItem(存储名称,数据名称) var c={name:"man",sex:"woman"}; localStorage.setI ...
- Flutter 依赖的那些事儿
Flutter 里面有2种库一样的东西, Package -creating a pure Dart component. like a new Widget. 这种是纯Dart,相当于你自己写的组件 ...
- Android 系统工具类
系统工具类 public class systemUtil { //隐藏ipad底部虚拟按键栏 @RequiresApi(api = Build.VERSION_CODES.KITKAT) publi ...
- Element隐藏组件:scrollbar
scrollbar是用来替代浏览器原生滚动条的组件,element的文档中并没有对scrollbar的描述. 使用方法:以<el-scrollbar/>包裹要滚动的元素,并设置固定高度.在 ...
- python第十五天-原来还差一份作业
作业 1: 员工信息表程序,实现增删改查操作 可进行模糊查询,语法至少支持下面3种: select name,age from staff_table where age > 22 select ...
- oracle 日期格式化 TO_CHAR (datetime) 修饰语和后缀
Datetime Format Element Suffixes Suffix Meaning Example Element Example Value TH Ordinal Number DDTH ...
- Linux 小知识翻译 - 「Unix」和「兼容Unix的OS」
经常有人会问「Linux和Unix有什么区别?」,「Linux就是Unix吗?」. 回答一般都是「Linux是仿照Unix而开发的OS」,「Linux和Unix相似但不是一种OS」之类的. 关于「Li ...