Scala进阶之路-Spark底层通信小案例
Scala进阶之路-Spark底层通信小案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Spark Master和worker通信过程简介
1>.Worker会向master注册自己;
2>.Master收到worker的注册信息之后,会告诉你已经注册成功,并给worker发送启动执行器的消息;
3>.Worker收到master的注册消息之后,会定期向master汇报自己的状态;
4>.master收到worker的心跳信息后,定期的更新worker的状态,因为worker在发送心跳的时候会携带心跳发送的时间,master会监测master发送过来的心跳信时间和当前时间的差,如果大于5分钟,master会监测发送过来的心跳时间和当前时间的差,如果大于5分钟,则认为worker已死。然后master在分配任务的时候就不会给worker下发任务!
关于Master和Worker之间的通信机制,我们可以用以下一张图介绍:

二.编写源代码
1>.Maven依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>cn.org.yinzhengjie</groupId>
<artifactId>MyActor</artifactId>
<version>1.0-SNAPSHOT</version> <!-- 定义一下常量 -->
<properties>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.compat.version>2.11</scala.compat.version>
<akka.version>2.4.17</akka.version>
</properties> <dependencies>
<!-- 添加scala的依赖 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency> <!-- 添加akka的actor依赖 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_${scala.compat.version}</artifactId>
<version>${akka.version}</version>
</dependency> <!-- 多进程之间的Actor通信 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-remote_${scala.compat.version}</artifactId>
<version>${akka.version}</version>
</dependency>
</dependencies> <!-- 指定插件-->
<build>
<!-- 指定源码包和测试包的位置 -->
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
</build>
</project>
2>.MessageProtocol源代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.spark /**
* worker -> master ,即worker向master发送消息
*/
case class RegisterWorkerInfo(id: String, core: Int, ram: Int) // worker向master注册自己(信息)
case class HearBeat(id: String) // worker给master发送心跳信息 /**
* master -> worker,即master向worker发送消息
*/
case object RegisteredWorkerInfo // master向worker发送注册成功消息
case object SendHeartBeat // worker 发送发送给自己的消息,告诉自己说要开始周期性的向master发送心跳消息
case object CheckTimeOutWorker //master自己给自己发送一个检查超时worker的信息,并启动一个调度器,周期新检测删除超时worker
case object RemoveTimeOutWorker // master发送给自己的消息,删除超时的worker /**
* 定义存储worker信息的类
* @param id : 每个worker的id是不变的且唯一的!
* @param core : 机器的核数
* @param ram : 内存大小
*/
case class WorkerInfo(val id: String, core: Int, ram: Int) {
//定义最后一次的心跳时间,初始值为null。
var lastHeartBeatTime: Long = _
}
3>.SparkWorker源代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.spark import java.util.UUID import akka.actor.{Actor, ActorSelection, ActorSystem, Props}
import com.typesafe.config.ConfigFactory
import scala.concurrent.duration._ // 导入时间单位 /**
* 定义主构造器,用于指定master的地址
*/
class SparkWorker(masterUrl: String) extends Actor{
var masterProxy:ActorSelection = _ //定义master的引用对象(actorRef)
val workId:String = UUID.randomUUID().toString //定义worker的uuid,每个worker的id是不变的且唯一的!
/**
* 通过preStart方法拿到master的引用对象(actorRef),我们重写该方法就会在receive方法执行之前执行!也就是拿到master对象只需要拿一次。
*/
override def preStart(): Unit = {
masterProxy = context.actorSelection(masterUrl)
}
override def receive: Receive = {
case "started" => { // 自己已就绪
// 向master注册自己的信息,id, core, ram
masterProxy ! RegisterWorkerInfo(workId, 4, 32 * 1024) // 此时master会收到该条信息
} /**
* 处理master发送给自己的注册成功消息
*/
case RegisteredWorkerInfo => {
import context.dispatcher // 使用调度器时候必须导入dispatcher,因为该包涉及到隐式转换的东西。
/**
* worker通过"context.system.scheduler.schedule"启动一个定时器,定时向master 发送心跳信息,需要指定
* 四个参数:
* 第一个参数是需要指定延时时间,此处指定的间隔时间为0毫秒;
* 第二个参数是间隔时间,即指定定时器的周期性执行时间,我们这里指定为1秒;
* 第三个参数是发送消息给谁,我们这里指定发送消息给自己,使用变量self即可;
* 第四个参数是指发送消息的具体内容;
* 注意:由于我们将消息周期性的发送给自己,因此我们自己需要接受消息并处理,也就是需要定义下面的SendHeartBeat
*/
context.system.scheduler.schedule(0 millis, 1000 millis, self, SendHeartBeat)
}
case SendHeartBeat => {
// 开始向master发送心跳了
println(s"------- $workId 发送心跳 -------")
masterProxy ! HearBeat(workId) // 此时master将会收到心跳信息
}
}
} object SparkWorker {
def main(args: Array[String]): Unit = {
// 检验参数
if(args.length != 4) {
println(
"""
|请输入参数:<host> <port> <workName> <masterURL>
""".stripMargin)
sys.exit() // 退出程序
}
/**
* 定义参数,主机,端口号,worker名称以及master的URL。
*/
val host = args(0)
val port = args(1)
val workName = args(2)
val masterURL = args(3)
/**
* 我们使用ConfigFactory.parseString来创建读取参数配置的对象config
*/
val config = ConfigFactory.parseString(
s"""
|akka.actor.provider="akka.remote.RemoteActorRefProvider"
|akka.remote.netty.tcp.hostname=$host
|akka.remote.netty.tcp.port=$port
""".stripMargin)
val actorSystem = ActorSystem("sparkWorker", config)
/**
* 创建worker的actorRef
*/
val workerActorRef = actorSystem.actorOf(Props(new SparkWorker(masterURL)), workName)
workerActorRef ! "started" //给自己发送一个以启动的消息,表示自己已经就绪了
}
}
4>.SparkMaster源代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.spark import akka.actor.{Actor, ActorSystem, Props}
import com.typesafe.config.ConfigFactory
import scala.concurrent.duration._ class SparkMaster extends Actor{ // 定义存储worker的信息的saveWorkerInfo对象
val saveWorkerInfo = collection.mutable.HashMap[String, WorkerInfo]() // override def preStart(): Unit = {
// context.system.scheduler.schedule(0 millis, 6000 millis, self, RemoveTimeOutWorker)
// } override def receive: Receive = {
/**
* 处理收到worker注册过来的信息
*/
case RegisterWorkerInfo(wkId, core, ram) => {
/**
* 存储之前需要判断之前是否已经存储过了,如果没有存储就以wkId为key将worker的信息存储起来,存储到HashMap,
*/
if (!saveWorkerInfo.contains(wkId)) {
val workerInfo = new WorkerInfo(wkId, core, ram)
saveWorkerInfo += ((wkId, workerInfo))
/**
* master存储完worker注册的数据之后,要告诉worker说你已经注册成功
*/
sender() ! RegisteredWorkerInfo // 此时worker会收到注册成功消息
}
}
/**
* master收到worker的心跳消息之后,更新woker的上一次心跳时间
*/
case HearBeat(wkId) => {
val workerInfo = saveWorkerInfo(wkId)
val currentTime = System.currentTimeMillis()
workerInfo.lastHeartBeatTime = currentTime // 更改心跳时间
}
case CheckTimeOutWorker => {
import context.dispatcher // 使用调度器时候必须导入dispatcher,因为该包涉及到隐式转换的东西。
context.system.scheduler.schedule(0 millis, 5000 millis, self, RemoveTimeOutWorker)
}
case RemoveTimeOutWorker => {
/**
* 将hashMap中的所有的value都拿出来,然后查看当前时间和上一次心跳时间差是否超过三次心跳时间,
* 即三次没有发送心跳信息就认为超时,每次心跳时间默认为1000毫秒,三次则为3000毫秒
*/
val workerInfos = saveWorkerInfo.values
val currentTime = System.currentTimeMillis() workerInfos
.filter(workerInfo => currentTime - workerInfo.lastHeartBeatTime > 3000) //过滤超时的worker
.foreach(workerInfo => saveWorkerInfo.remove(workerInfo.id)) //将过滤超时的worker删除掉
println(s"====== 还剩 ${saveWorkerInfo.size} 存活的Worker ======")
}
}
} object SparkMaster {
private var name = ""
private val age = 100
def main(args: Array[String]): Unit = {
// 检验参数
if(args.length != 3) {
println(
"""
|请输入参数:<host> <port> <masterName>
""".stripMargin)
sys.exit() // 退出程序
}
/**
* 定义参数,主机,端口号,master名称
*/
val host = args(0)
val port = args(1)
val masterName = args(2)
/**
* 我们使用ConfigFactory.parseString来创建读取参数配置的对象config
*/
val config = ConfigFactory.parseString(
s"""
|akka.actor.provider="akka.remote.RemoteActorRefProvider"
|akka.remote.netty.tcp.hostname=$host
|akka.remote.netty.tcp.port=$port
""".stripMargin) val actorSystem = ActorSystem("sparkMaster", config)
val masterActorRef = actorSystem.actorOf(Props[SparkMaster], masterName)
/**
* 自己给自己发送一个消息,去启动一个调度器,定期的检测HashMap中超时的worker
*/
masterActorRef ! CheckTimeOutWorker
}
}
三.本机测试
1>.启动master端
配置参数如下:
127.0.0.1 8888 master

2>.启动woker端
两个worker的配置参数如下:
127.0.0.1 6665 worker akka.tcp://sparkMaster@127.0.0.1:8888//user/master
127.0.0.1 6666 worker akka.tcp://sparkMaster@127.0.0.1:8888//user/master

服务端输出如下:

四.master worker打包部署到linux多台服务测试
1>.打包SparkMaster
第一步:修改Maven配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.org.yinzhengjie</groupId>
<artifactId>MyActor</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 定义一下常量 -->
<properties>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.compat.version>2.11</scala.compat.version>
<akka.version>2.4.17</akka.version>
</properties>
<dependencies>
<!-- 添加scala的依赖 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- 添加akka的actor依赖 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_${scala.compat.version}</artifactId>
<version>${akka.version}</version>
</dependency>
<!-- 多进程之间的Actor通信 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-remote_${scala.compat.version}</artifactId>
<version>${akka.version}</version>
</dependency>
</dependencies>
<!-- 指定插件-->
<build>
<!-- 指定源码包和测试包的位置 -->
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<!-- maven打包的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
<!-- 指定main方法:cn.org.yinzhengjie.spark.SparkMaster -->
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.org.yinzhengjie.spark.SparkMaster</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
指定main方法:cn.org.yinzhengjie.spark.SparkMaster
第二步:点击package开始打包:
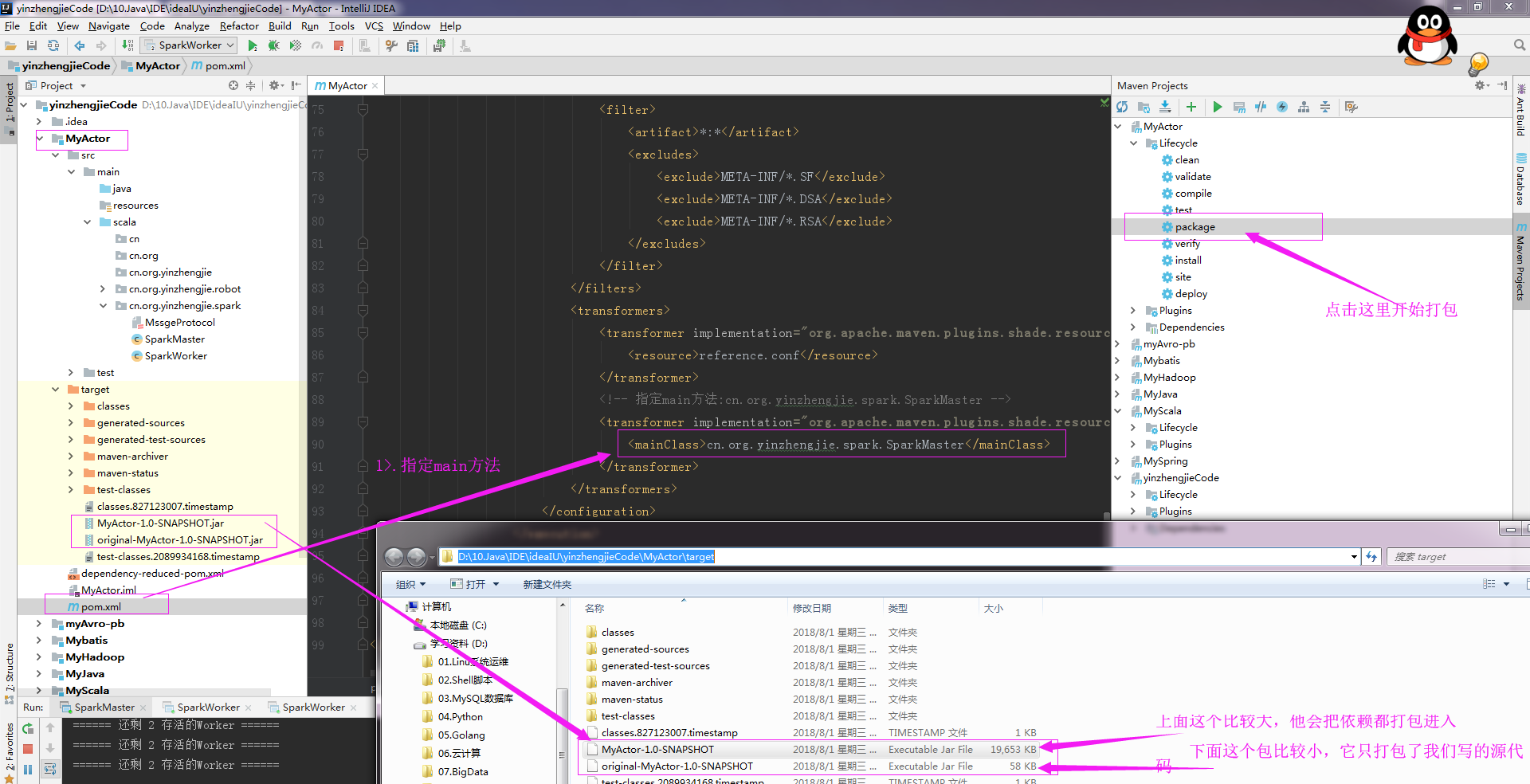
第三步:查看依赖包内部结构:

2>.打包SparkWorker
第一步:修改Maven配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.org.yinzhengjie</groupId>
<artifactId>MyActor</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 定义一下常量 -->
<properties>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.compat.version>2.11</scala.compat.version>
<akka.version>2.4.17</akka.version>
</properties>
<dependencies>
<!-- 添加scala的依赖 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- 添加akka的actor依赖 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_${scala.compat.version}</artifactId>
<version>${akka.version}</version>
</dependency>
<!-- 多进程之间的Actor通信 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-remote_${scala.compat.version}</artifactId>
<version>${akka.version}</version>
</dependency>
</dependencies>
<!-- 指定插件-->
<build>
<!-- 指定源码包和测试包的位置 -->
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<!-- maven打包的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
<!-- 指定main方法:cn.org.yinzhengjie.spark.SparkWorker -->
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.org.yinzhengjie.spark.SparkWorker</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
指定main方法:cn.org.yinzhengjie.spark.SparkWorker
接下来的两步还是和上面的步骤一直,将打包完成后的文件改名并查看主类信息如下:

3>.开启三台虚拟机并在master节点上传master.jar并运行
[yinzhengjie@s101 download]$ ll
total
-rw-r--r--. yinzhengjie yinzhengjie Jul : master.jar
-rw-r--r--. yinzhengjie yinzhengjie Jul : scala-2.11..tgz
-rw-r--r--. yinzhengjie yinzhengjie Jul : worker.jar
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$
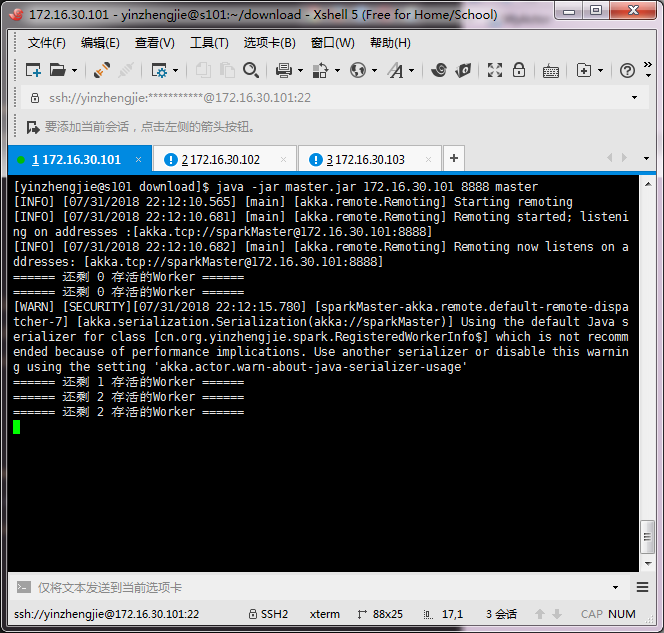
[yinzhengjie@s101 download]$ java -jar master.jar 172.16.30.101 master

4>.将worker.jar包上传到另外的两个节点并运行,如下:
172.16..102节点操作如下:
[yinzhengjie@s102 download]$ ll
total
-rw-r--r--. yinzhengjie yinzhengjie Jul : worker.jar
[yinzhengjie@s102 download]$
[yinzhengjie@s102 download]$ java -jar worker.jar 172.16.30.102 worker akka.tcp://sparkMaster@172.16.30.101:8888//user/master
[yinzhengjie@s102 download]$ 172.16..103节点操作如下:
[yinzhengjie@s103 download]$ ll
total
-rw-r--r--. yinzhengjie yinzhengjie Jul : worker.jar
[yinzhengjie@s103 download]$
[yinzhengjie@s103 download]$
[yinzhengjie@s103 download]$ java -jar worker.jar 172.16.30.103 worker akka.tcp://sparkMaster@172.16.30.101:8888//user/master
172.16.30.102节点操作如下:

172.16.30.103节点操作如下:

172.16.30.101输出信息如下:
Scala进阶之路-Spark底层通信小案例的更多相关文章
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
- Scala进阶之路-Spark本地模式搭建
Scala进阶之路-Spark本地模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark简介 1>.Spark的产生背景 传统式的Hadoop缺点主要有以下两 ...
- Scala进阶之路-idea下进行spark编程
Scala进阶之路-idea下进行spark编程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 1>.创建新模块并添加maven依赖 <?xml version=&qu ...
- Scala进阶之路-并发编程模型Akka入门篇
Scala进阶之路-并发编程模型Akka入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Akka Actor介绍 1>.Akka介绍 写并发程序很难.程序员不得不处 ...
- Scala进阶之路-高级数据类型之集合的使用
Scala进阶之路-高级数据类型之集合的使用 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Scala 的集合有三大类:序列 Seq.集 Set.映射 Map,所有的集合都扩展自 ...
- Scala进阶之路-Scala的基本语法
Scala进阶之路-Scala的基本语法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.函数式编程初体验Spark-Shell之WordCount var arr=Array( ...
- Scala进阶之路-为什么要学习Scala以及开发环境搭建
Scala进阶之路-为什么要学习Scala以及开发环境搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 最近人工智能和大数据那是相当的火呀,人工智能带动了Python的流行,区块 ...
- Scala进阶之路-Scala高级语法之隐式(implicit)详解
Scala进阶之路-Scala高级语法之隐式(implicit)详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们调用别人的框架,发现少了一些方法,需要添加,但是让别人为你一 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
随机推荐
- Android Studio下创建menu布局文件
一.问题: android studio项目中没有看到menu文件夹: 在android studio项目中想要添加menu布局文件,一开始我的做法是:直接在res文件夹右键选择xml文件来添加,如下 ...
- HTML 选择器
c56 div:nth-of-type(1) { margin-left: 12px; margin-top: 25px; } .c56 div:nth-of-type(2) { margin-top ...
- Maven -Maven配置tomcat插件 两种
Maven Tomcat插件现在主要有两个版本,tomcat-maven-plugin和tomcat7-maven-plugin,使用方式基本相同. tomcat-maven-plugin 插件官网: ...
- SQLServer:介质簇计数 缺失的介质簇序列号
https://shiyousan.com/post/635886596017415485 http://www.cnblogs.com/yc-755909659/p/3725940.html 错误描 ...
- 命令行方式(SSH or powershell )远程windows server
1. 使用ssh的方式远程登录window server 网上找到的方法大部分是freesshd 或者是Copsshd这样的工具 方式就是 下载安装文件,然后服务器端进行安装: 安装完成之后作为服务启 ...
- 转《js闭包与内存泄漏》
首先,能导致内存泄漏的一定是引用类型的变量,比如函数和其他自定义对象.而值类型的变量是不存在内存泄漏的,比如字符串.数字.布尔值等.因为值类型是靠复制来传递的,而引用类型是靠类似c语言中的指针来传递的 ...
- Spring学习14-源码下载地址
今天想下载一下Spring的源代码,登录到Spring官网,傻眼了,根本找不到下载的地方!费了九牛二虎之力在网上找到了一个下载地址,记下来,免得下次再次傻找. http://s3.amazonaws. ...
- jmeter 创建web测试计划
测试用例: 1 创建5个用户发送请求到2个web页面: 2 发送3次请求 总请求=5*2*3=30 创建这个测试计划需要用到以下元素:thread groups / http request / ht ...
- python之多线程举例
# 多线程举例 from threading import Thread from threading import current_thread class messager(Thread): de ...
- mysql 分页数据错乱
最近在使用mysql 分页查询数据的时候发现返回的数据与预期的不一样,显示数据重复错乱. 在官方文档 有这样一句话 If multiple rows have identical values in ...