Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
无论是是Kafka集群,还是producer和consumer都依赖于Zookeeper集群保存一些mate信息,来保证系统可用性!这个特点会产生一个现象,即会产生大量的网络IO,所以说在企业生产环境中会单独开3到5台集群,这三台集群什么都不干,只开Zookeeper集群。所以说Zookeeper开放的节点一定要开网络监控告警,这是一个大数据运维的基本功!
一.Zookeeper简介
1>.什么是zookeeper
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
2>.从设计模式角度来理解Zookeeper
zookeeper是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出反应,从而实现集群中类似与hadoop高可用中的active/standby管理模式。
3>.Zookeeper工作机制剖析
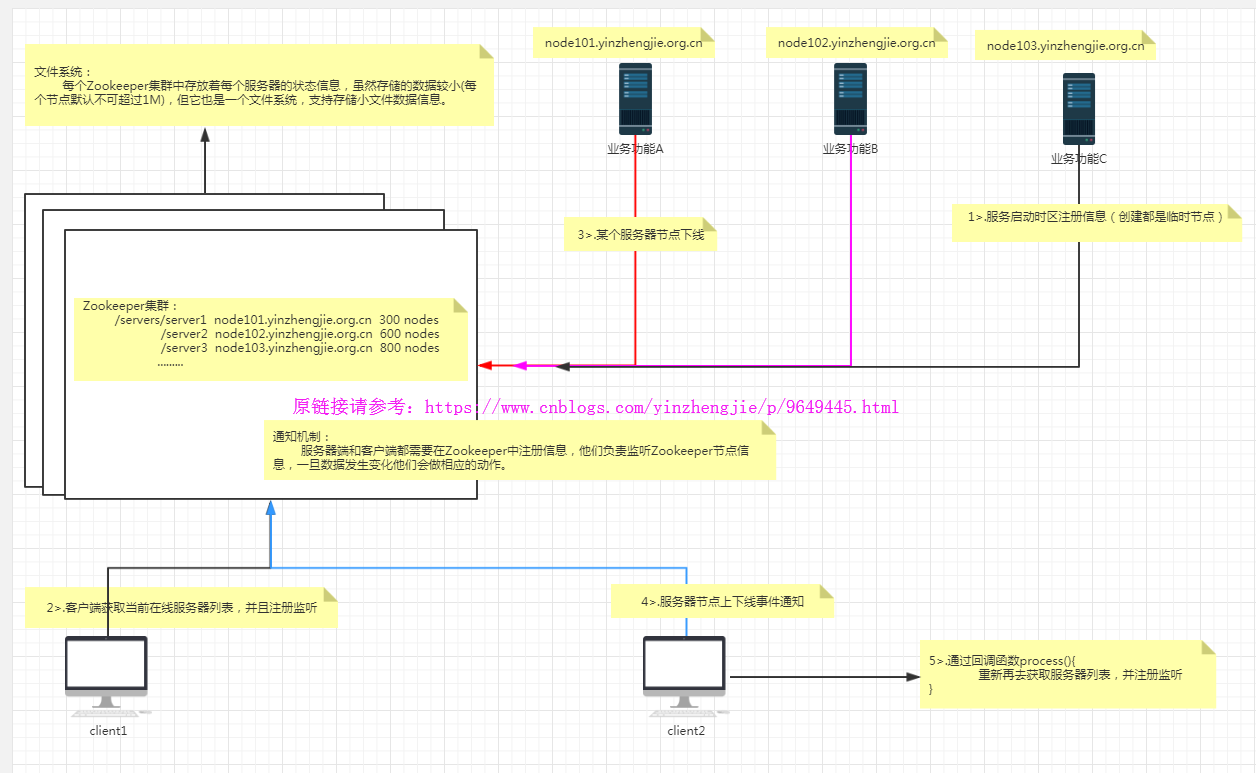
结合上图所述,我们可以说:Zookeeper = 文件系统 + 通知机制 文件系统:
每个Zookeeper集群中存放着每个服务器的状态信息,虽然存储的数据较小(每个节点默认不可超过1M),但它也是一个文件系统,支持存储小文件数据信息。 通知机制:
服务器端和客户端都需要在Zookeeper中注册信息,他们负责监听Zookeeper节点信息,一旦数据发生变化他们会做相应的动作。 Zookeeper的特点:
>.Zookeeper:一个领导者(leader),多个跟随者(follower)组成的集群。
>.Leader负责进行投票的发起和决议,更新系统状态。
>.Follower用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票。
>.集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。
>.全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的。
>.更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行。
>.数据更新原子性,一次数据更新要么成功,要么失败。
>.实时性,在一定时间范围内,client能读到最新数据。 Zookeeper的数据结构
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
二.Zookeeper的应用场景
Zookeeper提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
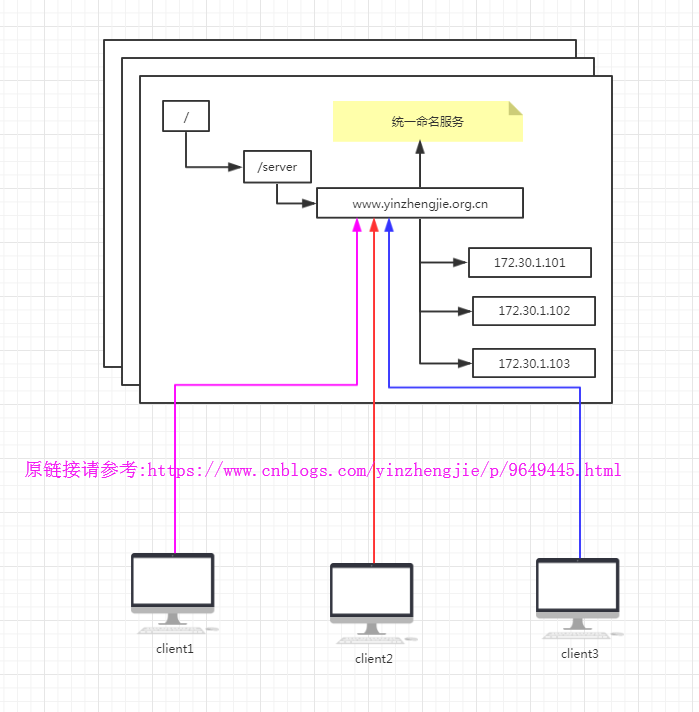
1>.统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别不同服务。类似于域名与IP之间对应关系,IP不容易记住,而域名容易记住。通过域名来火气资源或服务的地址,提供者等信息。
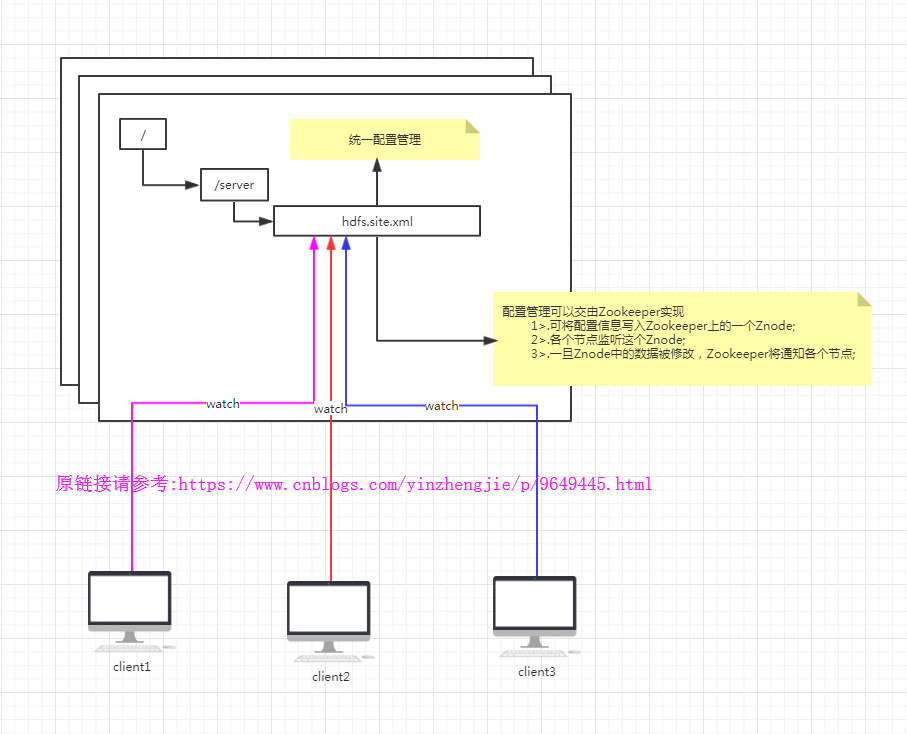
2>.统一配置管理
分布式环境下,配置文件管理和同步是一个常见问题。一个集群中,所有节点的配置信息是一致的,比如hadoop集群。对配置文件修改后,希望能够快速同步到各个节点上。
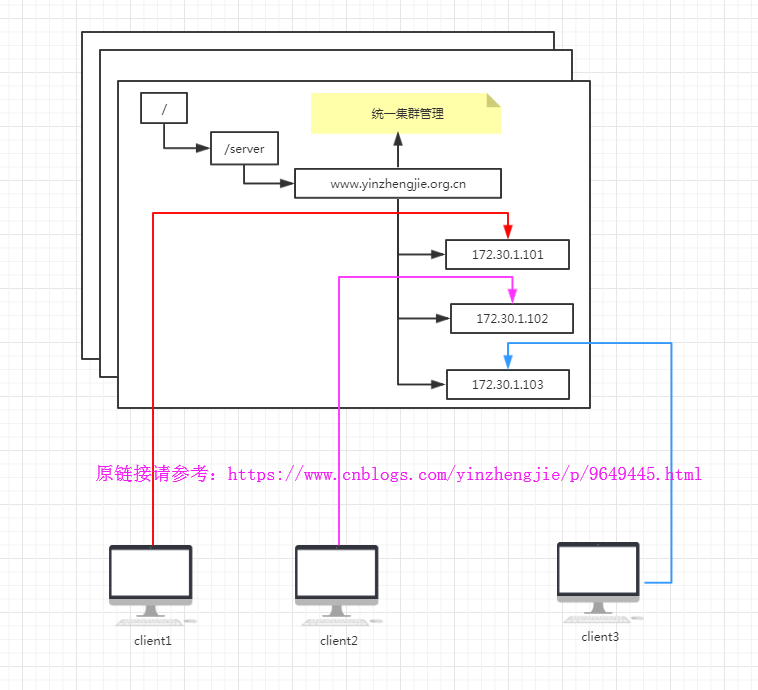
3>.统一集群管理
分布式环境中,实时掌握每个节点的状态是必要的。可以根据节点实时状态做出一些调整。可将节点信息写入Zookeeper上的一个Znode,监听这个Znode可获得他的实时状态变化。典型应用为HBase的Master状态监控和选举。
4>.服务器节点动态上下线
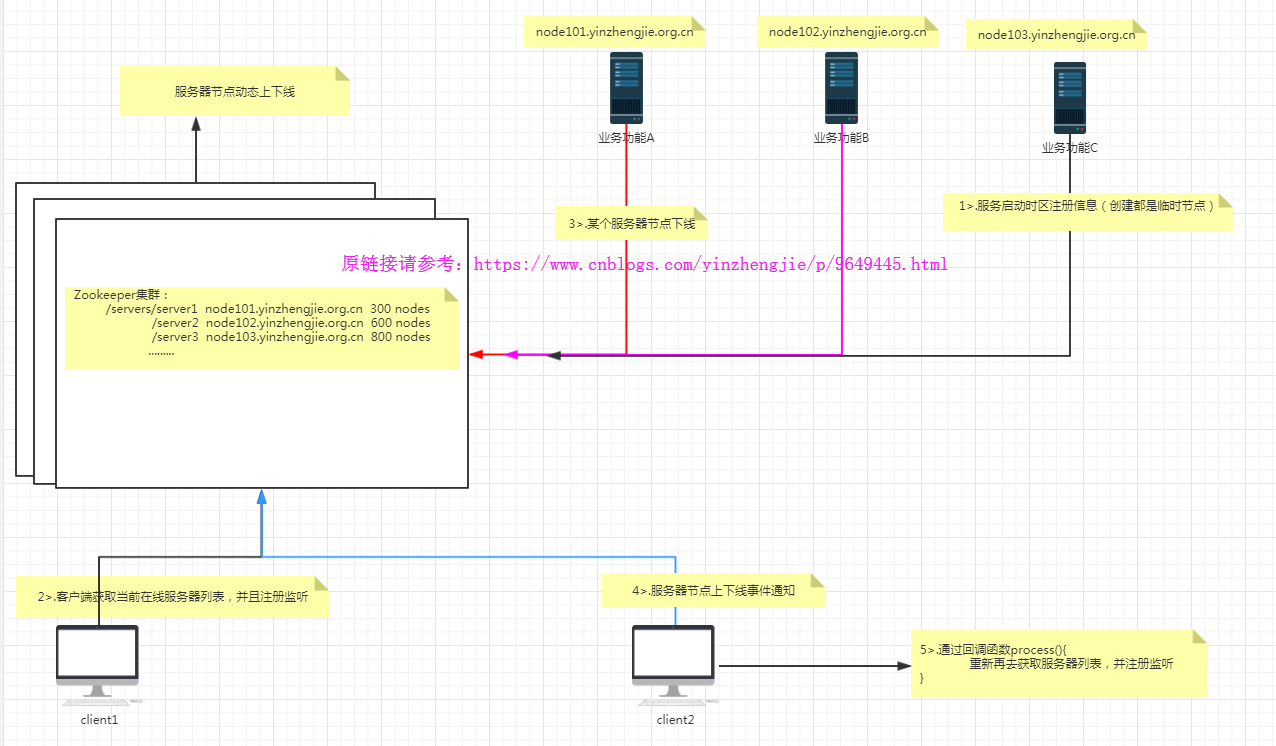
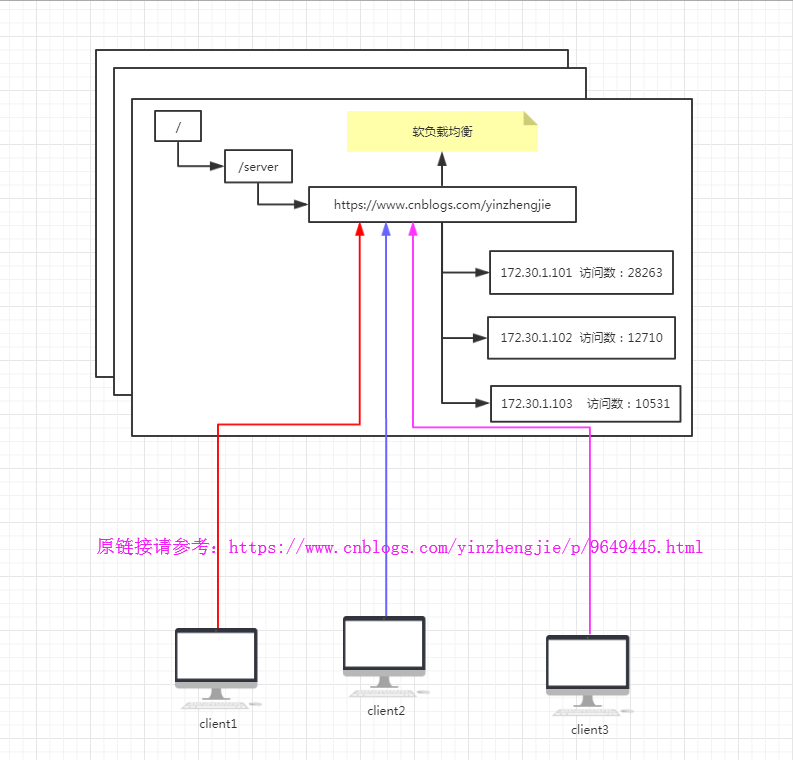
5>.软负载均衡
三.Zookeeper内部原理
1>.选举机制
在选举leader节点时,首先会比较事务id,其次比较myid,如果集群中已经有一半机器参加选举,那么次leader就是整个集群中的leader。
为了方便理解,我画了两幅图,便于理解上面的一句话,当事物id一致时推选leader如下:
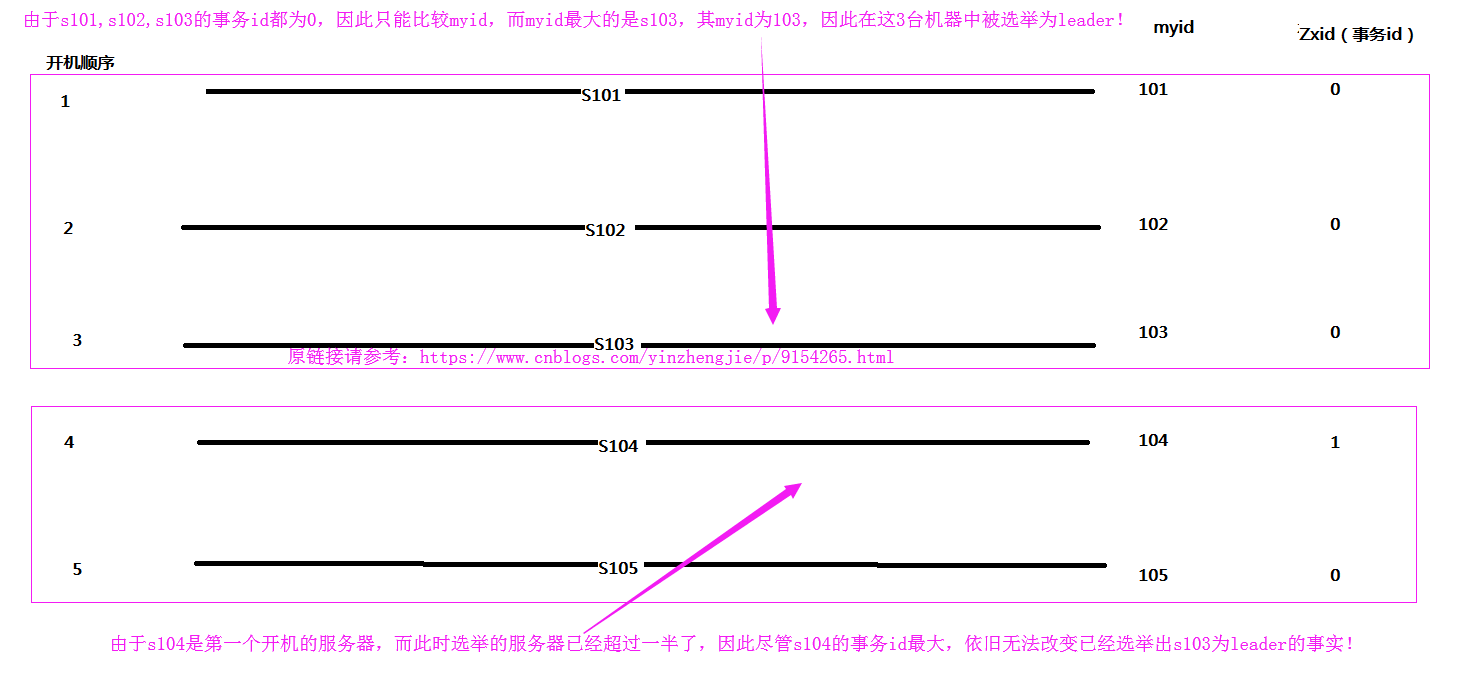
当事物id不一致时推选leader如下:

2>.Zookeeper概念知识扫描整理
一.Znode有两种类型:
>.短暂(ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
>.持久(persistent):客户端和服务器端断开连接后,创建的节点不删除 二.Znode有四种形式的目录节点(默认是persistent )
>.持久化目录节点(PERSISTENT)
客户端与zookeeper断开连接后,该节点依旧存在。
>.持久化顺序编号目录节点(PERSISTENT_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号。
>.临时目录节点(EPHEMERAL)
客户端与zookeeper断开连接后,该节点被删除。
>.临时顺序编号目录节点(EPHEMERAL_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号。 三.创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护 四.在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序 五.stat结构体
>.czxid- 引起这个znode创建的zxid,创建节点的事务的zxid
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生
>.ctime - znode被创建的毫秒数(从1970年开始)
>.mzxid - znode最后更新的zxid
>.mtime - znode最后修改的毫秒数(从1970年开始)
>.pZxid-znode最后更新的子节点zxid
>.cversion - znode子节点变化号,znode子节点修改次数
>.dataversion - znode数据变化号
>.aclVersion - znode访问控制列表的变化号
>.ephemeralOwner- 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0
>.dataLength- znode的数据长度
>.numChildren - znode子节点数量
3>.监听器原理

如上图所示,Zookeeper监听器原理详解:
>.首先由一个main()线程;
>.在main线程中创建Zookeeper客户端,这时就会创建两个线程,一个负责网络链接通信(connet),一个负责监听(linster);
>.通过connect线程将注册的监听事件发送给Zookeeper;
>.在Zookeeper的注册监听器中将注册的监听事件添加到列表中;
>.Zookeeper监听到有数据或路径变化,就会将这个消息发送给listener线程;
>.listener线程内部调用了process()方法; 常见的监听:
>.监听节点数据的变化 get path [watch]
>.监听子节点增减的变化 ls path [watch]
4>.写数据流程
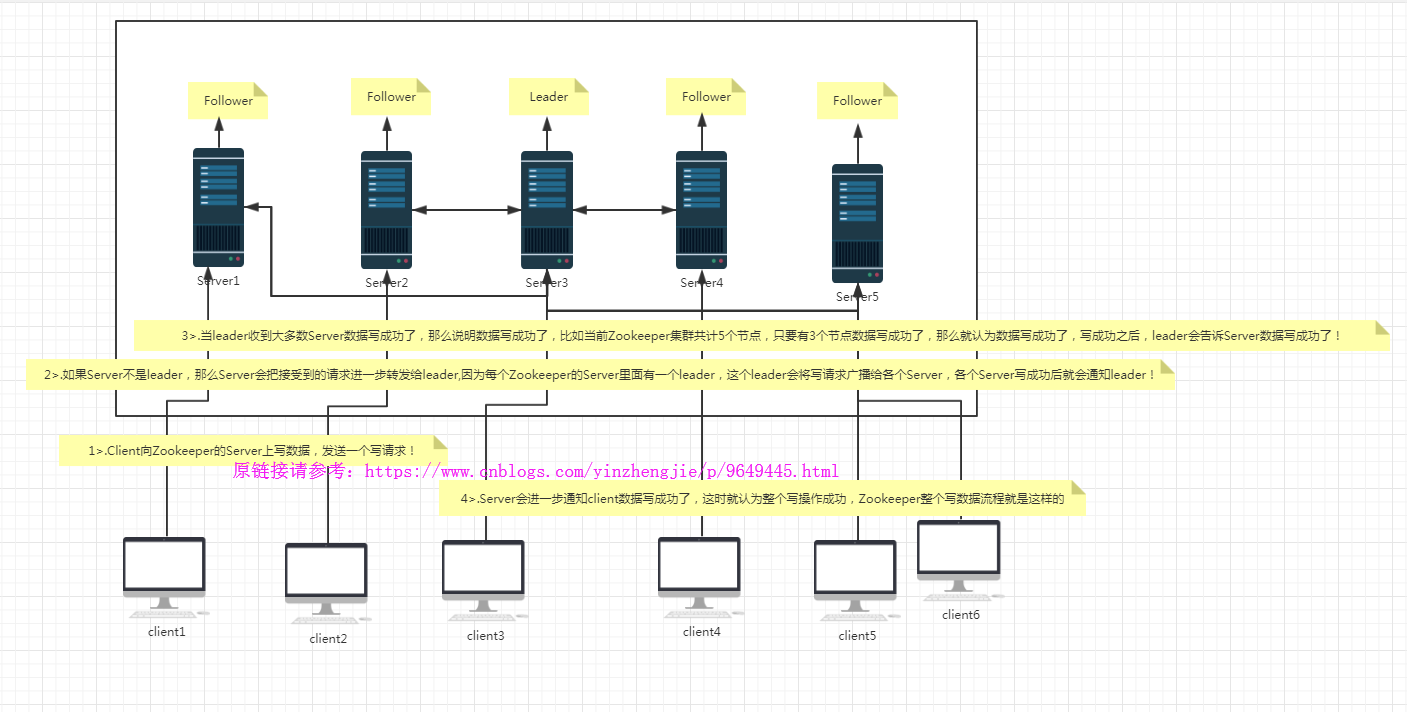
四.部署Zookeeper
1>.zookeeper本地搭建
详情请参考:https://www.cnblogs.com/yinzhengjie/p/9103008.html
2>.zookeeper完全分布式部署
详情请参考:https://www.cnblogs.com/yinzhengjie/p/9154265.html
3>.zookeeper的API用法详解
详情请参考:https://www.cnblogs.com/yinzhengjie/p/9154283.html
Hadoop生态圈-Zookeeper的工作原理分析的更多相关文章
- Hadoop生态圈-zookeeper完全分布式部署
Hadoop生态圈-zookeeper完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客部署是建立在Hadoop高可用基础之上的,关于Hadoop高可用部署请参 ...
- ZooKeeper的工作原理
ZooKeeper是一个分布式的应用程序协调服务. 2 ZooKeeper的工作原理 Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步.实现这个机制的协议叫做Zab ...
- SPI协议及工作原理分析
说明.文章摘自:SPI协议及其工作原理分析 http://blog.csdn.net/skyflying2012/article/details/11710801 一.概述. SPI, Serial ...
- Security:蠕虫的行为特征描述和工作原理分析
________________________ 参考: 百度文库---蠕虫的行为特征描述和工作原理分析 http://wenku.baidu.com/link?url=ygP1SaVE4t4-5fi ...
- Azure WAF防火墙工作原理分析和配置向导
Azure WAF工作原理分析和配置向导 本文博客地址为:http://www.cnblogs.com/taosha/p/6716434.html ,转载请保留出处,多谢! 本地数据中心往云端迁移的的 ...
- Hadoop生态圈-zookeeper本地搭建以及常用命令介绍
Hadoop生态圈-zookeeper本地搭建以及常用命令介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载zookeeper软件 下载地址:https://www.ap ...
- Hadoop生态圈-zookeeper的API用法详解
Hadoop生态圈-zookeeper的API用法详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.测试前准备 1>.开启集群 [yinzhengjie@s101 ~] ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
随机推荐
- 关于五子棋游戏java版
一 题目简介:关于五子棋游戏 二 源码的github链接 https://github.com/marry1234/test/blob/master/五子棋游戏 三.所设计的模块测试用例.测试结果 ...
- JSONObject使用方法详解
1.JSONObject介绍 JSONObject-lib包是一个beans,collections,maps,java arrays和xml和JSON互相转换的包. 2.下载jar包 http:// ...
- [转] Linux有问必答:如何修复“sshd error: could not load host key”
编译自:http://ask.xmodulo.com/sshd-error-could-not-load-host-key.html作者: GOLinux 本文地址:https://linux.cn/ ...
- 第五届蓝桥杯C++B组 地宫取宝
代码: #include <bits/stdc++.h> using namespace std; #define ll long long const ll mod = 1e9 + 7; ...
- GlusterFS卷的优化
GlusterFS可以通过配置选项来优化卷 配置选项 用途 默认值 合法值 network.ping-timeout 客户端等待检查服务器是否响应的持续时间,节点挂了数据不能写入 42 0-42 ...
- Test Scenarios for sending emails
(test cases for composing or validating emails are not included)(make sure to use dummy email addres ...
- HTML DOM 節點
節點: 整個html文檔是文檔節點: 注釋為注釋節點: 文本為文本節點: html元素為元素節點: html包含的內容為html節點. 節點間的關係: 父節點,子節點和同胞節點. html節點為根節點 ...
- React 组件库框架搭建
前言 公司业务积累了一定程度,需要搭建自己的组件库,有了组件库,整个团队开发效率会提高恨多. 做组件库需要提供开发调试环境,和组件文档的展示,调研了几个比较主流的方案,如下: docz 配置简单,功能 ...
- Omni(USDT)钱包安装(ubuntu)
一.下载Omni Layer钱包 wget https://bintray.com/artifact/download/omni/OmniBinaries/omnicore-0.3.0-x86_64- ...
- BZOJ3786星系探索——非旋转treap(平衡树动态维护dfs序)
题目描述 物理学家小C的研究正遇到某个瓶颈. 他正在研究的是一个星系,这个星系中有n个星球,其中有一个主星球(方便起见我们默认其为1号星球),其余的所有星球均有且仅有一个依赖星球.主星球没有依赖星球. ...