Scrapy爬取静态页面
Scrapy爬取静态页面
安装Scrapy框架:
Scrapy是python下一个非常有用的一个爬虫框架
Pycharm下:
搜索Scrapy库添加进项目即可
终端下:
#python2
sudo pip install scrapy
#python3
sudo pip3 install scrapy
#安装完成测试一下
scrapy version
爬取赶集网租房信息
们通过Chrome查看源代码可以发现所有的内容都是静态的,这种是比较容易爬取的。
Chrome下可以安装插件XPath。
终端下
scrapy shellhttp://bj.ganji.com/fang1/ 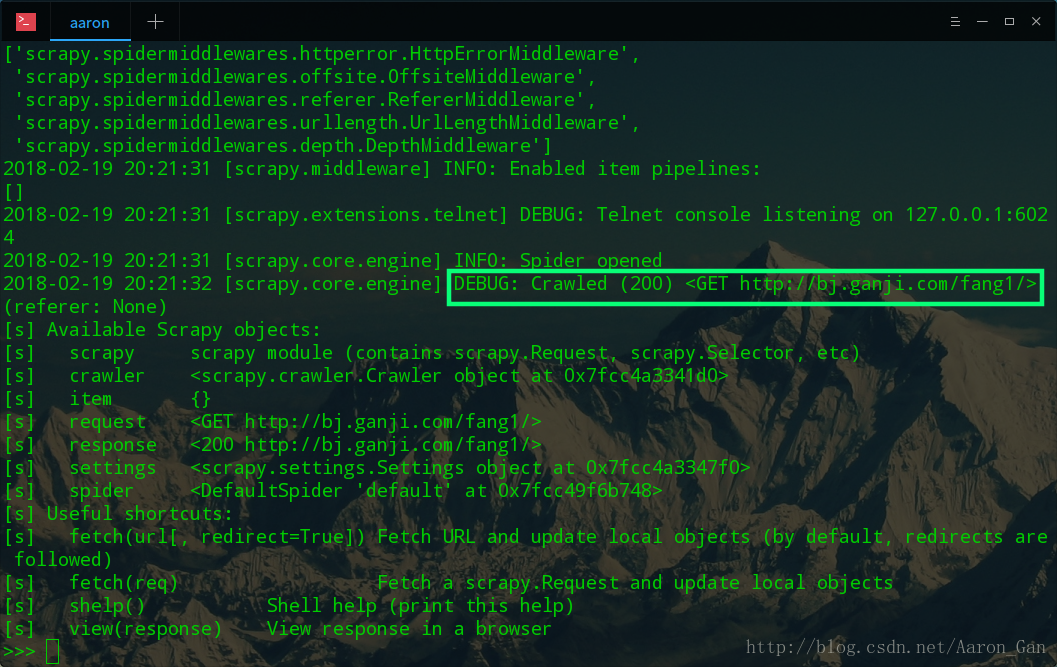
返回200即表示获取成功
#调用默认的浏览器打开缓存的页面
view(response)f12控制台下找到对应元素的xpath,可以在XPath插件下检查是不是对应的元素,复制这个对应的xpath
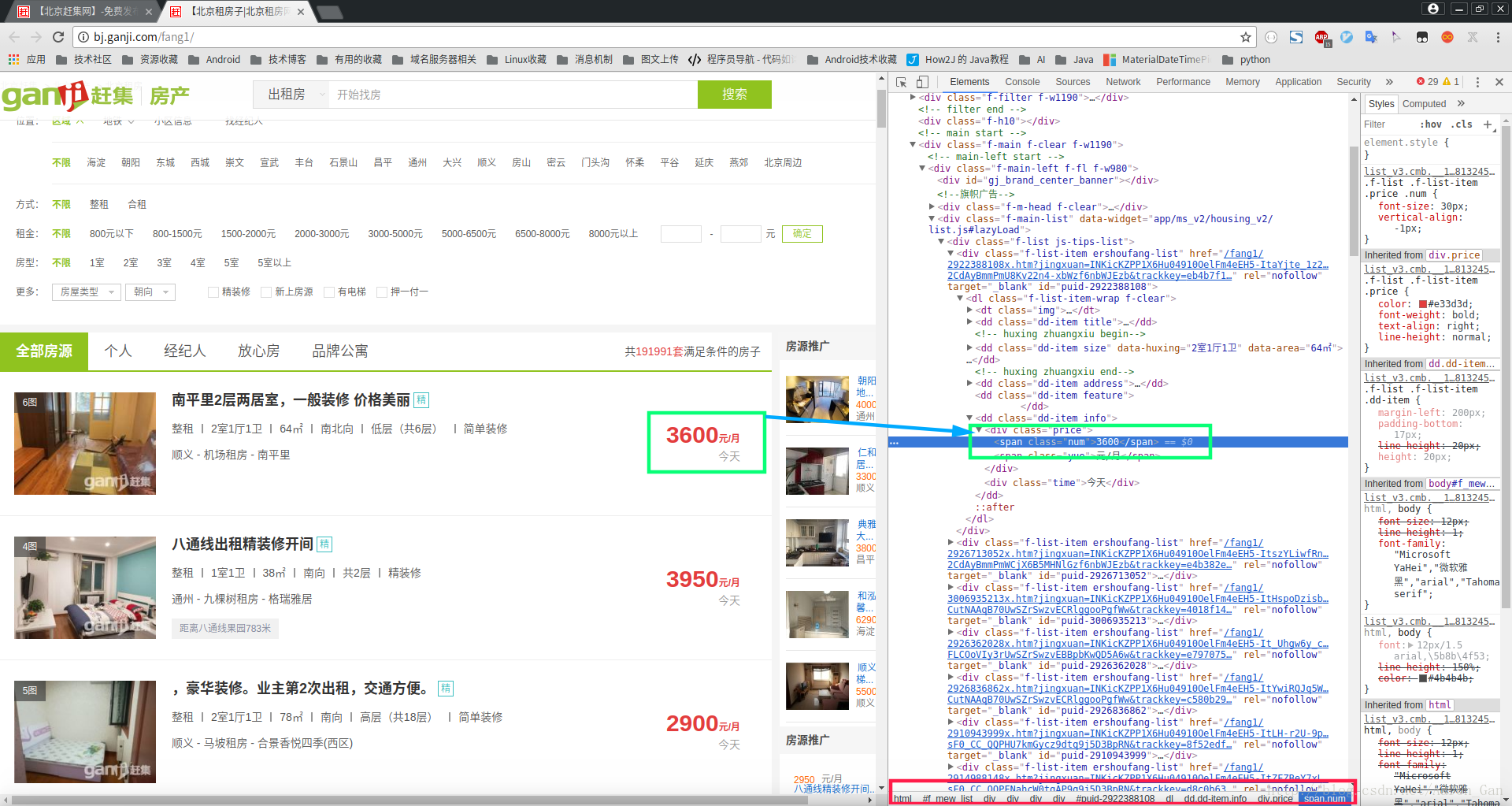
终端下
response.xpath('//*[@id="puid-2922388108"]/dl/dd[5]/div[1]/span[1]').extract()
response.xpath('//*[@id="puid-2922388108"]/dl/dd[5]/div[1]/span[1]/text()').extract()
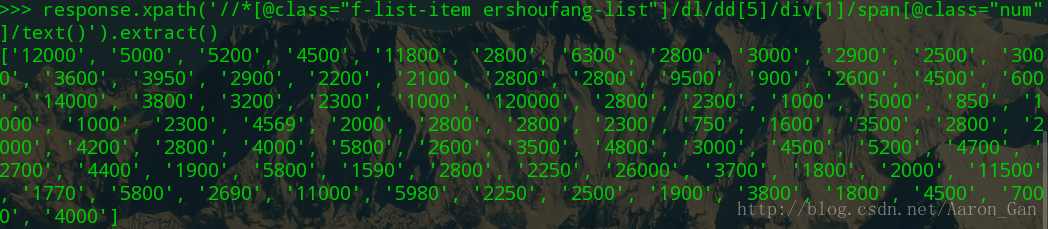
批量价格获取,这里做一个选择,原来是用id来标记价格,而这个id是一个item唯一的,所以我们要找到所有items的共性,这里借助类选择器来实现,因为所有的item的css类都是f-list-item ershoufang-list,这样获取到的就是一个价格列表,在span里面再用类选择器区分一下价格和单位。总之就是找共性,一步一步将元素从复杂的页面中剥离出来。
response.xpath('//*[@class="f-list-item ershoufang-list"]/dl/dd[5]/div[1]/span[@class="num"]/text()').extract()
爬取知乎日报首页
值得注意的直接脚本爬取知乎日报的首页会返回500错误,需要对项目进行一些设置,让爬虫模拟浏览来访问页面
终端下新建Scrapy项目
scrapy startproject spiderZhihuDaily
修改settings.py,添加
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'USER-AGENT': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36',
}找到页面中要获取的对应元素
这里是:图片,标题,链接
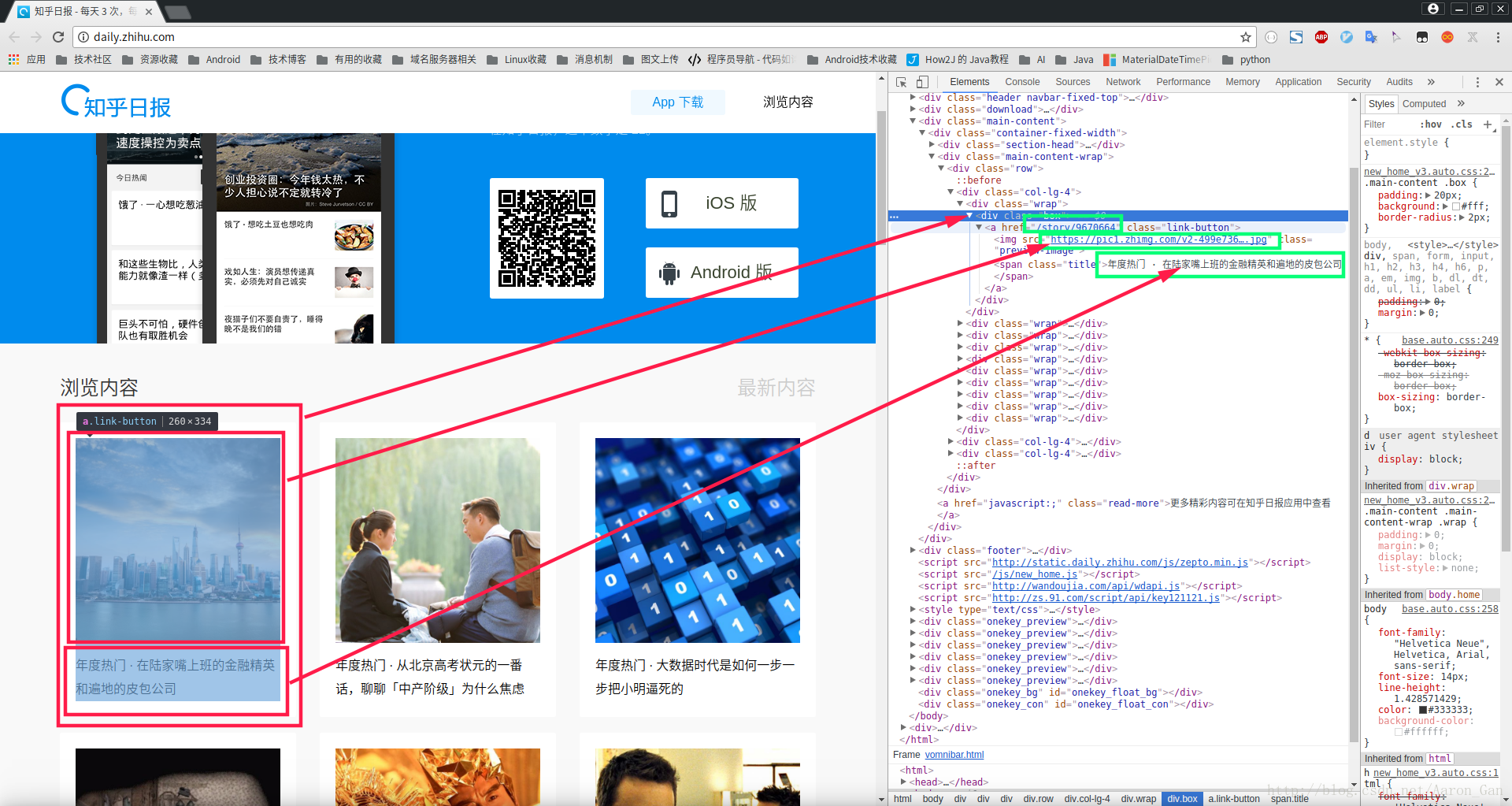
f12控制台下检查元素,找到xpath,将这个Xpath复制下来,在代码中会用到
注
#我们获取的xpath是单个元素的,这里以title为例
/html/body/div[3]/div/div[2]/div/div[1]/div[1]/div/a/span
#如果需要批量获取元素,需要借助类选择器来辅助,这里做一个选择
#注意观察网页代码中的规律,每一个item的类选择器都是class="box"
#所以通过这个来实现批量title的获取
/html/body/div[3]/div/div[2]/div/div[1]/div[@class="box"]/div/a/span/text()代码
import scrapy
class ZhihuDailySpider(scrapy.Spider):
name = 'zhihuDaily'
start_urls = ['http://daily.zhihu.com/']
def parse(self, response):
titles = response.xpath('/html/body/div[3]/div/div[2]/div/div[@class="col-lg-4"]/div[@class="wrap"]/div[@class="box"]/a/span/text()').extract()
imgSrcs= response.xpath('/html/body/div[3]/div/div[2]/div/div[@class="col-lg-4"]/div[@class="wrap"]/div[@class="box"]/a/img/@src').extract()
links = response.xpath('/html/body/div[3]/div/div[2]/div/div[@class="col-lg-4"]/div[@class="wrap"]/div[@class="box"]/a/@href').extract()
for title,img,link in zip(titles,imgSrcs,links):
print(title+"---"+img+"---"+link)运行
终端下进入爬虫脚本所在文件夹
#执行爬虫命令
scrapy crawl zhihuDaily
Scrapy爬取静态页面的更多相关文章
- node js 爬虫爬取静态页面,
先打一个简单的通用框子 //根据爬取网页的协议 引入对应的协议, http||https var http = require('https'); //引入cheerio 简单点讲就是node中的jq ...
- scrapy爬取相似页面及回调爬取问题(以慕课网为例)
以爬取慕课网数据为例 慕课网的数据很简单,就是通过get方式获取的 连接地址为https://www.imooc.com/course/list?page=2 根据page参数来分页
- Scrapy 爬取动态页面
目前绝大多数的网站的页面都是冬天页面,动态页面中的部分内容是浏览器运行页面中的JavaScript 脚本动态生成的,爬取相对比较困难 先来看一个很简单的动态页面的例子,在浏览器中打开 http://q ...
- C# HtmlAgilityPack爬取静态页面
最近对爬虫很感兴趣,稍微研究了一下,利用HtmlAgilityPack制作了一个十分简单的爬虫,这个简易爬虫只能获取静态页面的Html HtmlAgilityPack简介 HtmlAgilityPac ...
- scrapy(四): 爬取二级页面的内容
scrapy爬取二级页面的内容 1.定义数据结构item.py文件 # -*- coding: utf-8 -*- ''' field: item.py ''' # Define here the m ...
- 以豌豆荚为例,用 Scrapy 爬取分类多级页面
本文转载自以下网站:以豌豆荚为例,用 Scrapy 爬取分类多级页面 https://www.makcyun.top/web_scraping_withpython17.html 需要学习的地方: 1 ...
- scrapy模拟浏览器爬取验证码页面
使用selenium模块爬取验证码页面,selenium模块需要另外安装这里不讲环境的配置,我有一篇博客有专门讲ubuntn下安装和配置模拟浏览器的开发 spider的代码 # -*- coding: ...
- Scrapy爬取自己的博客内容
python中常用的写爬虫的库有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
随机推荐
- vmvare安装vmtools菜单灰色
光驱和各种驱动器改为自动检测 将vmvaretools.gz文件解压 tar xvf vm...gz 然后进程解压目录运行 sudo ./vmware-install.pl 然后重启 reboot 这 ...
- java Timer 定时每天凌晨0点执行任务
import java.util.TimerTask; /** * 执行内容 * @author admin_Hzw * */ public class Task extends TimerTask ...
- 把ArrayList集合中的字符串内容写到文本文件中
list列表数据导出到指定路径文本文档中 public String getSDCardPath() { String sdCard = Environment.getExternalStorage ...
- thymeleaf 添加语法提示
thymeleaf 添加语法提示: xmlns:th="http://www.thymeleaf.org"
- Python数据分析Numpy库方法简介(四)
Numpy的相关概念2 副本和视图 副本:复制 三种情况属于浅copy 赋值运算 切片 视图:链接,操作数组是,返回的不是副本就是视图 c =a.view().创建a的视图/影子和切片一样都是浅cop ...
- jQuery 字符串拼接
jQuery 字符串拼接 // 字符串加变量拼接 $('#id 标签名[属性名="' + 变量 + '"]')
- @Transacitonal注解不生效之spring中expose-proxy的作用与原理
几年前记得整理过,@Transacitonal注解的方法被另外一个方法调用的时候,事务是不生效的. 如果大量代码已经这么写了,这个时候抽取出去不现实,怎么办呢? 答案就是在<aop:aspect ...
- mysql的并发控制
并发即指在同一时刻,多个操作并行执行.MySQL对并发的处理主要应用了两种机制——是"锁"和"多版本控制". 1.并发控制 MySQL提供两个级别的并发控制:服 ...
- poj1985和poj1849(树的直径)
题目传送门:poj1985 树是连通无环图,树上任意两点之间的路径是唯一的.定义树上任 意两点u, v的距离为u到v路径上边权的和.树的直径MN为树上最长路 径,即点M和N是树上距离最远的两个点. 题 ...
- Python作业
1使用while 循环输入1,2,3,4,5,6,,8,9,10 count = 0 while count<10: count+=1 if count ==7: continue print( ...