JS 中的广度与深度优先遍历
现在有一种类似树的数据结构,但是不存在共同的根节点 root,每一个节点的结构为 {key: 'one', value: '1', children: [...]},都包含 key 和 value,如果存在 children 则内部会存在 n 个和此结构相同的节点,现模拟数据如下图:

已知一个 value 如 3-2-1,需要取出该路径上的所有 key,即期望得到 ['three', 'three-two', 'three-two-one']。
1.广度优先遍历
广度优先的算法如下图:
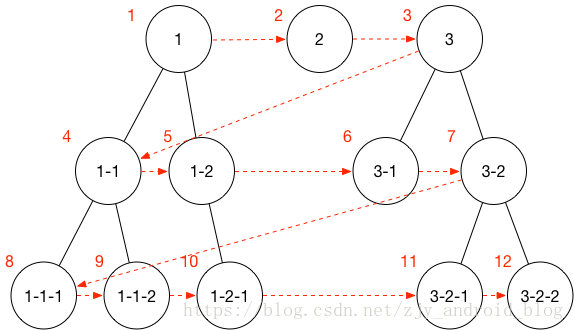
从上图可以轻易看出广度优先即是按照数据结构的层次一层层遍历搜索。
首先需要把外层的数据结构放入一个待搜索的队列(Queue)中,进而对这个队列进行遍历,当正在遍历的节点存在子节点(children)时则把此子节点下所有节点放入待搜索队列的末端。
因为本需求需要记录路径,因此还需要对这些数据做一些特殊处理,此处采用了为这些节点增加 parent 即来源的方法。
对此队列依次搜索直至找到目标节点时,可通过深度遍历此节点的 parent 从而获得到整个目标路径。具体代码如下:
- // 广度优先遍历
- function findPathBFS(source, goal) {
- // 深拷贝原始数据
- var dataSource = JSON.parse(JSON.stringify(source))
- var res = []
- // 每一层的数据都 push 进 res
- res.push(...dataSource)
- // res 动态增加长度
- for (var i = 0; i < res.length; i++) {
- var curData = res[i]
- // 匹配成功
- if (curData.value === goal) {
- var result = []
- // 返回当前对象及其父节点所组成的结果
- return (function findParent(data) {
- result.unshift(data.key)
- if (data.parent) return findParent(data.parent)
- return result
- })(curData)
- }
- // 如果有 children 则 push 进 res 中待搜索
- if (curData.children) {
- res.push(...curData.children.map(d => {
- // 在每一个数据中增加 parent,为了记录路径使用
- d.parent = curData
- return d
- }))
- }
- }
- // 没有搜索到结果,默认返回空数组
- return []
- }
2.深度优先遍历
深度优先的算法如下图:
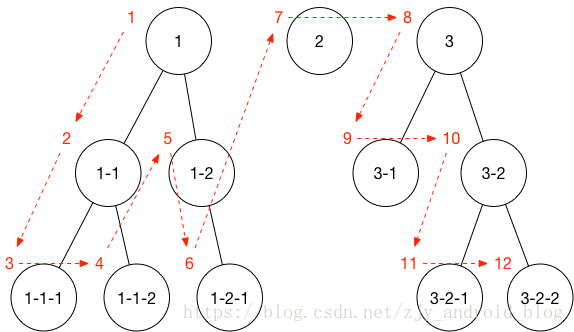
深度优先即是取得要遍历的节点时如果发现有子节点(children) 时,则不断的深度遍历,并把这些节点放入一个待搜索的栈(Stack)中,直到最后一个没有子节点的节点时,开始对栈进行搜索。后进先出(下列代码中使用了 push 方法入栈,因此需使用 pop 方法出栈),如果没有匹配到,则删掉此节点,同时删掉父节点中的自身,不断重复遍历直到匹配为止。注意,常规的深度优先并不会破坏原始数据结构,而是采用 isVisited 或者颜色标记法进行表示,原理相同,此处简单粗暴做了删除处理。代码如下:
- // 深度优先遍历
- function findPathDFS(source, goal) {
- // 把所有资源放到一个树的节点下,因为会改变原数据,因此做深拷贝处理
- var dataSource = [{children: JSON.parse(JSON.stringify(source))}]
- var res = []
- return (function dfs(data) {
- if (!data.length) return res
- res.push(data[0])
- // 深度搜索一条数据,存取在数组 res 中
- if (data[0].children) return dfs(data[0].children)
- // 匹配成功
- if (res[res.length - 1].value === goal) {
- // 删除自己添加树的根节点
- res.shift()
- return res.map(r => r.key)
- }
- // 匹配失败则删掉当前比对的节点
- res.pop()
- // 没有匹配到任何值则 return
- if (!res.length) return res
- // 取得最后一个节点,待做再次匹配
- var lastNode = res[res.length - 1]
- // 删除已经匹配失败的节点(即为上面 res.pop() 的内容)
- lastNode.children.shift()
- // 没有 children 时
- if (!lastNode.children.length) {
- // 删除空 children,且此时需要深度搜索的为 res 的最后一个值
- delete lastNode.children
- return dfs([res.pop()])
- }
- return dfs(lastNode.children)
- })(dataSource)
- }
该方法在思考时,添加了根节点以把数据转换成树,并在做深度遍历时传入了子节点数组 children 作为参数,其实多有不便,于是优化后的代码如下:
- // 优化后的深度搜索
- function findPathDFS(source, goal) {
- // 因为会改变原数据,因此做深拷贝处理
- var dataSource = JSON.parse(JSON.stringify(source))
- var res = []
- return (function dfs(data) {
- res.push(data)
- // 深度搜索一条数据,存取在数组 res 中
- if (data.children) return dfs(data.children[0])
- // 匹配成功
- if (res[res.length - 1].value === goal) {
- return res.map(r => r.key)
- }
- // 匹配失败则删掉当前比对的节点
- res.pop()
- // 没有匹配到任何值则 return,如果源数据有值则再次深度搜索
- if (!res.length) return !!dataSource.length ? dfs(dataSource.shift()) : res
- // 取得最后一个节点,待做再次匹配
- var lastNode = res[res.length - 1]
- // 删除已经匹配失败的节点(即为上面 res.pop() 的内容)
- lastNode.children.shift()
- // 没有 children 时
- if (!lastNode.children.length) {
- // 删除空 children,且此时需要深度搜索的为 res 的最后一个值
- delete lastNode.children
- return dfs(res.pop())
- }
- return dfs(lastNode.children[0])
- })(dataSource.shift())
- }
改进后的方法只关心传入的节点,如果存在子节点则内部自行处理,而非预先传入所有子节点数组进行处理,此方法更易理解一些。
结语
以上便是广度与深度遍历在 JS 中的应用,代码可在 codepen 中查看。
JS 中的广度与深度优先遍历的更多相关文章
- [PHP] 算法-邻接矩阵图的广度和深度优先遍历的PHP实现
1.图的深度优先遍历类似前序遍历,图的广度优先类似树的层序遍历 2.将图进行变形,根据顶点和边的关系进行层次划分,使用队列来进行遍历 3.广度优先遍历的关键点是使用一个队列来把当前结点的所有下一级关联 ...
- 在js中使用for和forEach遍历数组
数组的遍历 for var arr = [1, 2, 3, 4]; for (var i = 0; i < arr.length; i++){ arr[i]; } forEach var arr ...
- js中数组的循环与遍历forEach,map
对于前端的循环遍历我们知道有 针对js数组的forEach().map().filter().reduce()方法 针对js对象的for/in语句(for/in也能遍历数组,但不推荐) 针对jq数组/ ...
- JavaScript基础&实战(5)js中的数组、forEach遍历、Date对象、Math、String对象
文章目录 1.工厂方法创建对象 1.1 代码块 1.2.测试结果 2.原型对象 2.1 代码 2.2 测试结果 3.toString 3.1 代码 3.2 测试结果 4.数组 4.1 代码 5.字面量 ...
- 图的广度、深度优先遍历 C语言
以下是老师作为数据结构课的作业的要求,没有什么实际用处和可以探讨和总结的的地方,所以简单代码直接展示. 宽度优先遍历: #include<cstdio> #include<iostr ...
- 关于js中的for(var in)遍历属性报错问题
之前遇到过这个问题,但是没找到问题的所在,将for(var i in array){} 改成了for(var i ;i<array.length;i++)循环,但是今天又遇到了,mark一下错 ...
- JS中数组与对象的遍历方法实例小结
一.数组的遍历: 首先定义一个数组 1 arr=['snow','bran','king','nightking']; 1.for循环,需要知道数组的长度; 2.foreach,没有返回值,可以不知道 ...
- JS中数组实现(倒序遍历数组,数组连接字符串)
// =================== 求最大值===================================== <script> var arr = [10,35,765 ...
- js中数字的4种遍历方式
<!DOCTYPE html> <html> <head> <meta charset="utf-8"/> <title> ...
随机推荐
- Painter's Problem (高斯消元)
There is a square wall which is made of n*n small square bricks. Some bricks are white while some br ...
- DataGridView 访问任意行不崩溃
int index= this.dataGridView1.rows.Add(); 先执行这行代码,然后访问任意行,不崩溃, 赋值不存在的行,只是不显示,或者无值. 什么原理呢? 一些其他 priva ...
- C++ 打印机设置
我在网上已不断看到一些网友关于自定义纸张打印的问题,基本上还没有较完美的解决方案,我在这里提供一个WindowsNT/2000/XP下的解决办法,供广大同仁参考.Windows9x/Me下也有解决办法 ...
- ltp-ddt inverted_return小trick
./runtest/ddt/i2c_readwrite # @name I2C write read test on slave device# @desc I2C write read test o ...
- PHP 订单延时处理:延迟队列(未鉴定)
PHP 订单延时处理:延迟队列: https://github.com/chenlinzhong/php-delayqueue
- 剑指offer(42)和为S的字符串
题目描述 输入一个递增排序的数组和一个数字S,在数组中查找两个数,是的他们的和正好是S,如果有多对数字的和等于S,输出两个数的乘积最小的. 输出描述: 对应每个测试案例,输出两个数,小的先输出. 题目 ...
- 使用JS调用手机本地摄像头或者相册图片识别二维码/条形码
接着昨天的需求,不过这次不依赖微信,使用纯js唤醒手机本地摄像头或者选择手机相册图片,识别其中的二维码或者是条形码.昨天,我使用微信扫一扫识别,效果超棒的.不过如果依赖微信的话,又怎么实现呢,这里介绍 ...
- Query the tables and index which will caus rebuild index fail
On MSSQL server database, while rebuild index failed, we can use the follow sql statement to see if ...
- CookieHelper
using System.Web: /// <summary> /// CookieHelper /// </summary> public static class Cook ...
- react-native android/ios 根据配置文件编译时自动修改版本号
开发react-native时大都有过这个操作,当版本迭代时候要修改app版本号时,一般都这样做 Android: 的要修改build.gradle文件的versionName ios: 打开xcod ...