Python 3 利用机器学习模型 进行手写体数字识别
0.引言
介绍了如何生成手写体数字的数据,提取特征,借助 sklearn 机器学习模型建模,进行识别手写体数字 1-9 模型的建立和测试。
用到的几种模型:
1. LR,Logistic Regression, (线性模型)中的逻辑斯特回归
2. Linear SVC,Support Vector Classification, (支持向量机)中的线性支持向量分类
3. MLPC,Multi-Layer Perceptron Classification, (神经网络)多层感知机分类
4. SGDC,Stochastic Gradient Descent Classification, (线性模型)随机梯度法求解
手写体的识别是一个 分类 问题,提取图像特征作为模型输入,输出到标记数字 1-9;
主要内容:
1. 生成手写体数字数据集;
2. 提取图像特征存入 CSV;
3. 利用机器学习建立和测试手写体数字识别模型;
(如果你想尝试生成自己的数据集可以参考我的另一篇博客:http://www.cnblogs.com/AdaminXie/p/8379749.html)
源码上传到了我的 GitHub: https://github.com/coneypo/ML_handwritten_number, 有问题可以留言或者联系我邮箱;
得到不同样本量训练下,几种机器学习模型精度随样本的变化关系曲线:
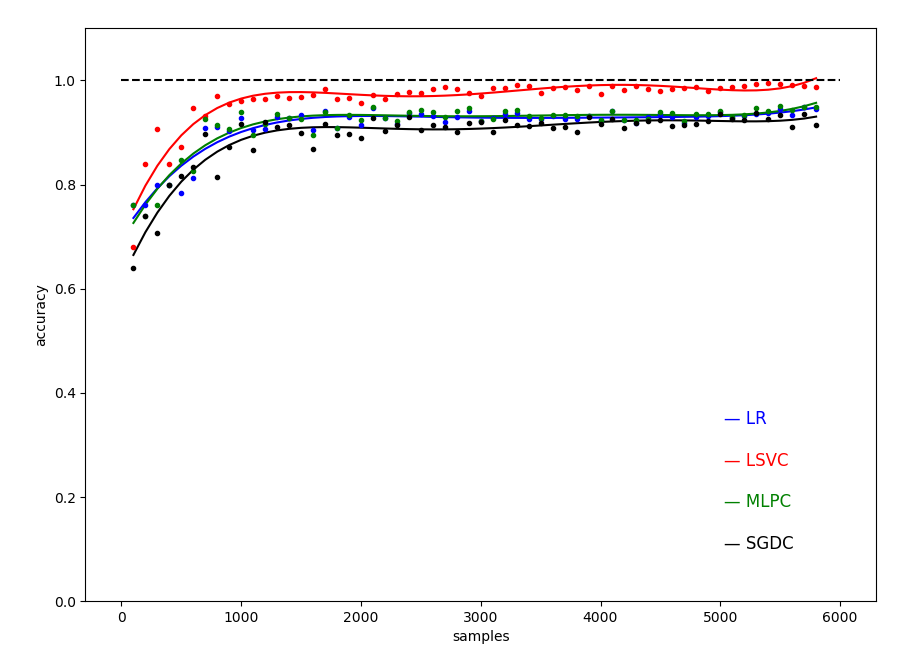
图 0 不同样本数目下的四种模型的测试精度( 数据集大小从 100 到 5800,间隔 100 )
1. 开发环境
python: 3.6.3
import PIL, cv2, pandas, numpy, os, csv, random
需要调用的 sklearn 库:
from sklearn.linear_model import LogisticRegression # 线性模型中的 Logistic 回归模型
from sklearn.linear_model import SGDClassifier # 线性模型中的随机梯度下降模型
from sklearn.svm import LinearSVC # SVM 模型中的线性 SVC 模型
from sklearn.neural_network import MLPClassifier # 神经网络模型中的多层网络模型
2.整体设计思路
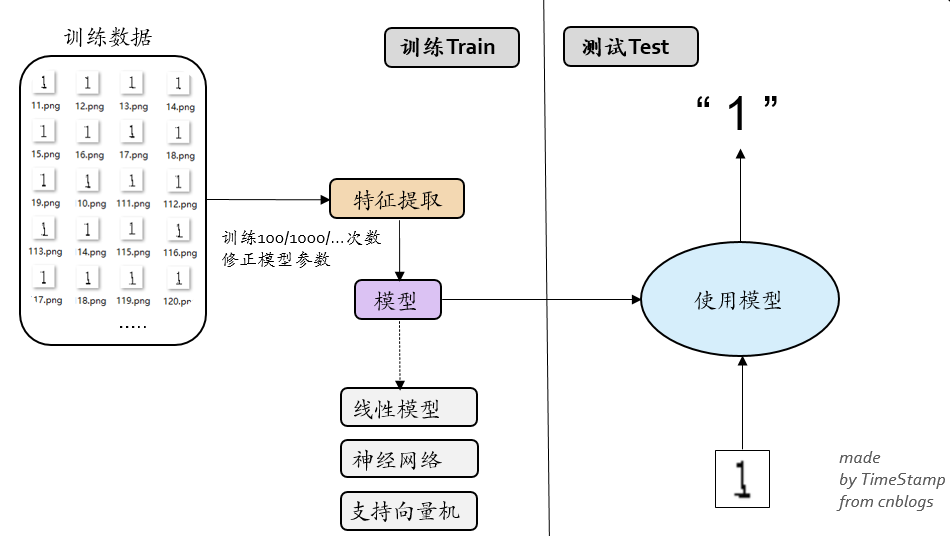
图 1 整体的框架设计
工程的目的,是想利用机器学习模型去训练识别生成的随机验证码图像(单个数字 1-9 ),通过以下三个步骤实现:
1. 生成手写体数据集
2. 提取特征向量写入 CSV
3. sklearn 模型训练和测试

图 2 整体的设计流程
3. 编程过程
3.1 生成多张单个验证码图像 ( generate_folders.py, generate_handwritten_numbers.py )
图 3 生成的多张单个验证码图像
手写体数据集的生成在我的另一篇博客详细介绍:( Link:http://www.cnblogs.com/AdaminXie/p/8379749.html )
思路就是 random 随机生成数字 1-9,然后利用PIL的画笔工具进行画图,对图像进行扭曲,然后根据随机数的真实标记 1-9,保存到对应文件夹内,用标记+序号命名。
1 draw = ImageDraw.Draw(im) # 画笔工具
3.2 提取特征向量写入 CSV ( get_features.py )
这一步是提取图像中的特征。生成的单个图像是 30*30 即 900 个像素点的;
为了降低维度,没有选择 900 个像素点每点的灰度作为输入,而是选取了 30 行每行的黑点数,和 30 列每列的黑点数作为输入,这样降到了 60 维。
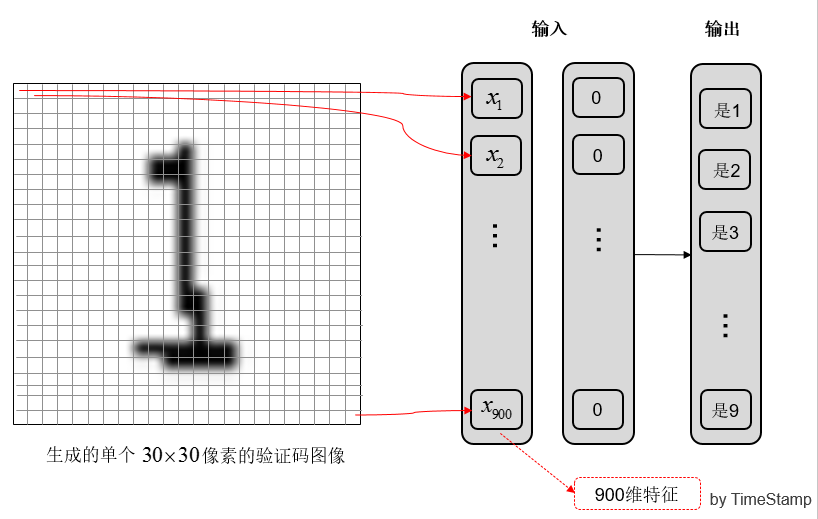
(a) 提取 900 维特征
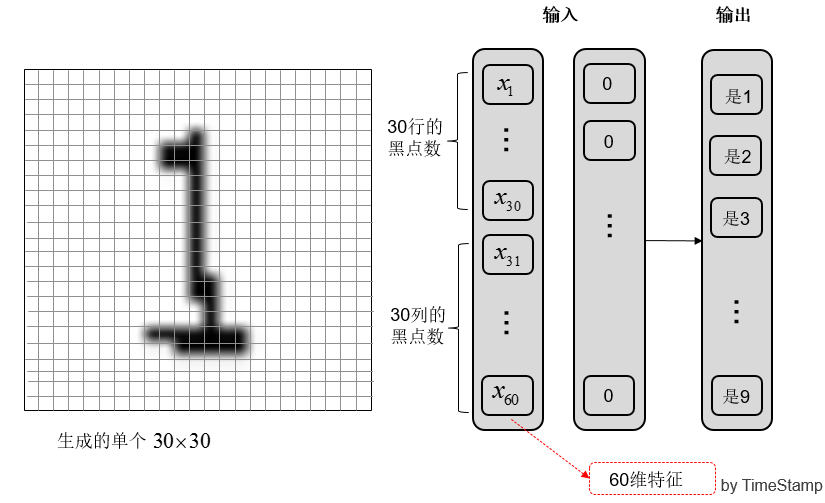
(b) 提取 60 维特征
图 4 提取图像特征
特征的提取也比较简单,逐行逐列计算然后计数求和:
def get_feature(img):
# 提取特征
# 30*30的图像, width, height = img.size global pixel_cnt_list
pixel_cnt_list=[] height = 30
for y in range(height):
pixel_cnt_x = 0
for x in range(width):
# print(img.getpixel((x,y)))
if img.getpixel((x, y)) == 0: # 黑点
pixel_cnt_x += 1 pixel_cnt_list.append(pixel_cnt_x) for x in range(width):
pixel_cnt_y = 0
for y in range(height):
if img.getpixel((x, y)) == 0: # 黑点
pixel_cnt_y += 1 pixel_cnt_list.append(pixel_cnt_y) return pixel_cnt_list
所以我们接下来需要做的工作是,遍历访问文件夹 num_1-9 中的所有图像文件,进行特征提取,然后写入 CSV 文件中:
with open(path_csv+"tmp.csv", "w", newline="") as csvfile:
writer = csv.writer(csvfile)
# 访问文件夹 1-9
for i in range(1, 10):
num_list = os.listdir(path_images + "num_" + str(i))
print(path_images + "num_" + str(i))
print("num_list:", num_list)
# 读到图像文件
if os.path.isdir(path_images + "num_" + str(i)):
print("样本个数:", len(num_list))
sum_images = sum_images + len(num_list) # Travsel every single image to generate the features
for j in range(0, (len(num_list))): # 处理读取单个图像文件提取特征
img = Image.open(path_images + "num_" + str(i)+"/" + num_list[j])
get_features_single(img)
pixel_cnt_list.append(num_list[j][0]) # 写入CSV
writer.writerow(pixel_cnt_list)
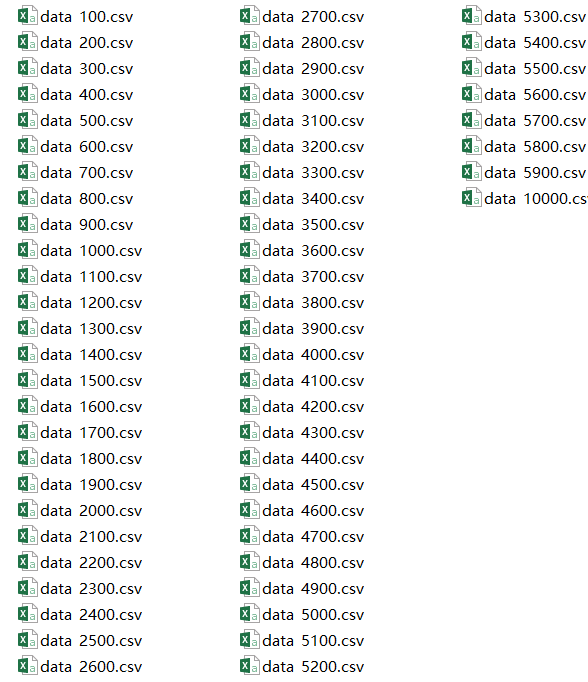
图 5 提取出来的 CSV 文件(前 60 列为输入特征,第 61 列为输出标记)
3.3 sklearn 模型训练和测试 ( ml_ana.py, test_single_images.py )
之前的准备工作都做完之后,我们生成了存放着 60 维输入特征和 1 维输出标记的 61 列的 CSV 文件;
然后就可以利用这些数据,交给 sklearn 的机器学习模型进行建模处理。
3.3.1 特征数据加工
第一步需要对 CSV 文件中的数据进行提取,利用 pd.read_csv 进行读取。写入 CSV 时,前 60 列为 60 维的特征向量,第 61 列为输出标记 1-9;
利用前面已经提取好的特征 CSV;
# 从 CSV 中读取数据
def pre_data():
# CSV61维表头名
column_names = [] for i in range(0, 60):
column_names.append("feature_" + str(i))
column_names.append("true_number") # 读取csv
path_csv = "../data/data_csvs/"
data = pd.read_csv(path_csv + "data_10000.csv", names=column_names) # 提取数据集
global X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = train_test_split(
data[column_names[0:60]],
data[column_names[60]],
test_size=0.25, # 75% for 训练,25% for 测试
random_state=33
)
利用sklearn库的 train_test_split 函数 将数据进行分割,
得到训练集数据:X_train, y_train
得到测试集数据:X_test, y_test
3.3.2 模型训练和测试
经过前面一系列的准备工作做完,这里正式开始使用 sklearn 的机器学习模型建模;
调用 sklearn 利用训练数据对模型进行训练,然后利用测试数据进行性能测试,并且保存模型到本地 ( "/data/data_models/model_xxx.m");
ml_ana.py:
# created at 2018-01-29
# updated at 2018-09-28 # Author: coneypo
# Blog: http://www.cnblogs.com/AdaminXie
# GitHub: https://github.com/coneypo/ML_handwritten_number from sklearn.model_selection import train_test_split
import pandas as pd from sklearn.preprocessing import StandardScaler # 标准化 # 调用模型
from sklearn.linear_model import LogisticRegression # 线性模型中的 Logistic 回归模型
from sklearn.svm import LinearSVC # SVM 模型中的线性 SVC 模型
from sklearn.neural_network import MLPClassifier # 神经网络模型中的多层网络模型
from sklearn.linear_model import SGDClassifier # 线性模型中的随机梯度下降模型 # 保存模型
from sklearn.externals import joblib # 从 CSV 中读取数据
def pre_data():
# CSV61维表头名
column_names = [] for i in range(0, 60):
column_names.append("feature_" + str(i))
column_names.append("true_number") # 读取csv
path_csv = "../data/data_csvs/"
data = pd.read_csv(path_csv + "data_10000.csv", names=column_names) # 提取数据集
global X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = train_test_split(
data[column_names[0:60]],
data[column_names[60]],
test_size=0.25, # 75% for 训练,25% for 测试
random_state=33
) path_saved_models = "../data/data_models/" # LR, logistic regression, 逻辑斯特回归分类(线性模型)
def way_LR():
X_train_LR = X_train
y_train_LR = y_train X_test_LR = X_test
y_test_LR = y_test # 数据预加工
# ss_LR = StandardScaler()
# X_train_LR = ss_LR.fit_transform(X_train_LR)
# X_test_LR = ss_LR.transform(X_test_LR) # 初始化LogisticRegression
LR = LogisticRegression() # 调用LogisticRegression中的fit()来训练模型参数
LR.fit(X_train_LR, y_train_LR) # 使用训练好的模型lr对X_test进行预测
# 结果储存在y_predict_LR中
global y_predict_LR
y_predict_LR = LR.predict(X_test_LR) # 评分函数
global score_LR
score_LR = LR.score(X_test_LR, y_test_LR)
print("The accurary of LR:", '\t', score_LR) # 保存模型
joblib.dump(LR, path_saved_models + "model_LR.m") return LR # 多层感知机分类(神经网络)
def way_MLPC():
X_train_MLPC = X_train
y_train_MLPC = y_train X_test_MLPC = X_test
y_test_MLPC = y_test # ss_MLPC = StandardScaler()
# X_train_MLPC = ss_MLPC.fit_transform(X_train_MLPC)
# X_test_MLPC = ss_MLPC.transform(X_test_MLPC) MLPC = MLPClassifier(hidden_layer_sizes=(13, 13, 13), max_iter=500)
MLPC.fit(X_train_MLPC, y_train_MLPC) global y_predict_MLPC
y_predict_MLPC = MLPC.predict(X_test_MLPC) global score_MLPC
score_MLPC = MLPC.score(X_test_MLPC, y_test_MLPC)
print("The accurary of MLPC:", '\t', score_MLPC) # 保存模型
joblib.dump(MLPC, path_saved_models + "model_MLPC.m") return MLPC # Linear SVC, Linear Supported Vector Classifier, 线性支持向量分类(SVM支持向量机)
def way_LSVC():
X_train_LSVC = X_train
y_train_LSVC = y_train X_test_LSVC = X_test
y_test_LSVC = y_test # Standard Scaler
# ss_LSVC = StandardScaler()
# X_train_LSVC = ss_LSVC.fit_transform(X_train_LSVC)
# X_test_LSVC = ss_LSVC.transform(X_test_LSVC) LSVC = LinearSVC()
LSVC.fit(X_train_LSVC, y_train_LSVC) global y_predict_LSVC
y_predict_LSVC = LSVC.predict(X_test_LSVC) global score_LSVC
score_LSVC = LSVC.score(X_test_LSVC, y_test_LSVC)
print("The accurary of LSVC:", '\t', score_LSVC) # 保存模型
joblib.dump(LSVC, path_saved_models + "model_LSVC.m") return LSVC # SGDC, stochastic gradient decent 随机梯度下降法求解(线性模型)
def way_SGDC():
X_train_SGDC = X_train
y_train_SGDC = y_train X_test_SGDC = X_test
y_test_SGDC = y_test # ss_SGDC = StandardScaler()
# X_train_SGDC = ss_SGDC.fit_transform(X_train_SGDC)
# X_test_SGDC = ss_SGDC.transform(X_test_SGDC) SGDC = SGDClassifier(max_iter=5) SGDC.fit(X_train_SGDC, y_train_SGDC) global y_predict_SGDC
y_predict_SGDC = SGDC.predict(X_test_SGDC) global score_SGDC
score_SGDC = SGDC.score(X_test_SGDC, y_test_SGDC)
print("The accurary of SGDC:", '\t', score_SGDC) # 保存模型
joblib.dump(SGDC, path_saved_models + "model_SGDC.m") return SGDC pre_data()
way_LR()
way_LSVC()
way_MLPC()
way_SGDC()
3.3.3 测试 ( test_single_images.py )
对于一张手写体数字,提取特征然后利用保存的模型进行预测;
# created at 2018-01-29
# updated at 2018-09-28 # Author: coneypo
# Blog: http://www.cnblogs.com/AdaminXie
# GitHub: https://github.com/coneypo/ML_handwritten_number # 利用保存到本地的训练好的模型,来检测单张 image 的标记 from sklearn.externals import joblib
from PIL import Image img = Image.open("../test/test_1.png") # Get features
from generate_datebase import get_features
features_test_png = get_features.get_features_single(img) path_saved_models = "../data/data_models/" # LR
LR = joblib.load(path_saved_models + "model_LR.m")
predict_LR = LR.predict([features_test_png])
print("LR:", predict_LR[0]) # LSVC
LSVC = joblib.load(path_saved_models + "model_LSVC.m")
predict_LSVC = LSVC.predict([features_test_png])
print("LSVC:", predict_LSVC[0]) # MLPC
MLPC = joblib.load(path_saved_models + "model_MLPC.m")
predict_MLPC = MLPC.predict([features_test_png])
print("MLPC:", predict_MLPC[0]) # SGDC
SGDC = joblib.load(path_saved_models + "model_SGDC.m")
predict_SGDC = SGDC.predict([features_test_png])
print("SGDC:", predict_SGDC[0])
3.3.4 绘制样本数-精度图像
可以绘图来更加直观的精度:
# 2018-01-29
# By TimeStamp
# cnblogs: http://www.cnblogs.com/AdaminXie/
# plot_from_csv.py
# 从存放样本数-精度的CSV中读取数据,绘制图形 import numpy as np
import matplotlib.pyplot as plt
import pandas as pd # CSV路径
path_csv = "F:/***/P_ML_handwritten_number/data/score_csv/" # 存储x轴坐标
x_array = [] # 存储精度
LR_score_arr = []
LSVC_score_arr = []
MLPC_score_arr = []
SGDC_score_arr = [] # 读取CSV数据
column_names = ["samples", "acc_LR", "acc_LSVC", "acc_MLPC", "acc_SGDC"]
rd_csv = pd.read_csv(path_csv + "score_100to5800.csv", names=column_names) print(rd_csv.shape) for i in range(len(rd_csv)):
x_array.append(float(rd_csv["samples"][i]))
LR_score_arr.append(float(rd_csv["acc_LR"][i]))
LSVC_score_arr.append(float(rd_csv["acc_LSVC"][i]))
MLPC_score_arr.append(float(rd_csv["acc_MLPC"][i]))
SGDC_score_arr.append(float(rd_csv["acc_SGDC"][i])) ################ 3次线性拟合 ################
xray = np.array(x_array)
y_LR = np.array(LR_score_arr)
y_LSVC = np.array(LSVC_score_arr)
y_MLPC = np.array(MLPC_score_arr)
y_SGDC = np.array(SGDC_score_arr) z1 = np.polyfit(xray, y_LR, 5)
z2 = np.polyfit(xray, y_LSVC, 5)
z3 = np.polyfit(xray, y_MLPC, 5)
z4 = np.polyfit(xray, y_SGDC, 5) p1 = np.poly1d(z1)
p2 = np.poly1d(z2)
p3 = np.poly1d(z3)
p4 = np.poly1d(z4) y_LR_vals = p1(xray)
y_LSVC_vals = p2(xray)
y_MLPC_vals = p3(xray)
y_SGDC_vals = p4(xray)
################################# # 标明线条说明
plt.annotate("— LR", xy=(5030, 0.34), color='b', size=12)
plt.annotate("— LSVC", xy=(5030, 0.26), color='r', size=12)
plt.annotate("— MLPC", xy=(5030, 0.18), color='g', size=12)
plt.annotate("— SGDC", xy=(5030, 0.10), color='black', size=12) # 画拟合曲线
plt.plot(xray, y_LR_vals, color='b')
plt.plot(xray, y_LSVC_vals, color='r')
plt.plot(xray, y_MLPC_vals, color='g')
plt.plot(xray, y_SGDC_vals, color='black') # 画离散点
plt.plot(xray, y_LR, color='b', linestyle='None', marker='.', label='y_test', linewidth=100)
plt.plot(xray, y_LSVC, color='r', linestyle='None', marker='.', label='y_test', linewidth=0.01)
plt.plot(xray, y_MLPC, color='g', linestyle='None', marker='.', label='y_test', linewidth=0.01)
plt.plot(xray, y_SGDC, color='black', linestyle='None', marker='.', label='y_test', linewidth=0.01) # 绘制y=1参考线
plt.plot([0, 6000], [1, 1], 'k--') # 设置y轴坐标范围
plt.ylim(0, 1.1) # 标明xy轴
plt.xlabel('samples')
plt.ylabel('accuracy') plt.show()
3.3.4 测试结果
在样本数 sample_num = 50 的情况下,训练 75% 数据,用 25% 的数据即 13 个样本进行测试;
几种模型的测试结果如 图 6 所示,可见除了 SVM 达到 84.7% 的精度之外,其他都在 60-70% 左右;
但是因为只有 50 个样本点,小样本的情况下测试精度的偶然性误差比较大。
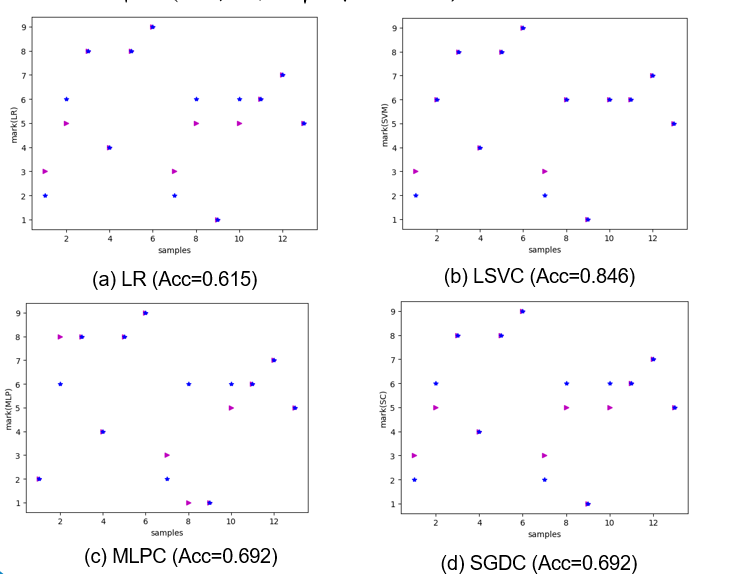
图 6 手写体识别的性能分析( 在样本数为 50 的情况下 )
增加样本数到 100,即生成了 100 张单个手写体图像,75 张用来训练,25 张用来测试;
25 张的测试结果 图 6 所示,几种模型的测试精度都达到了 90% 左右。
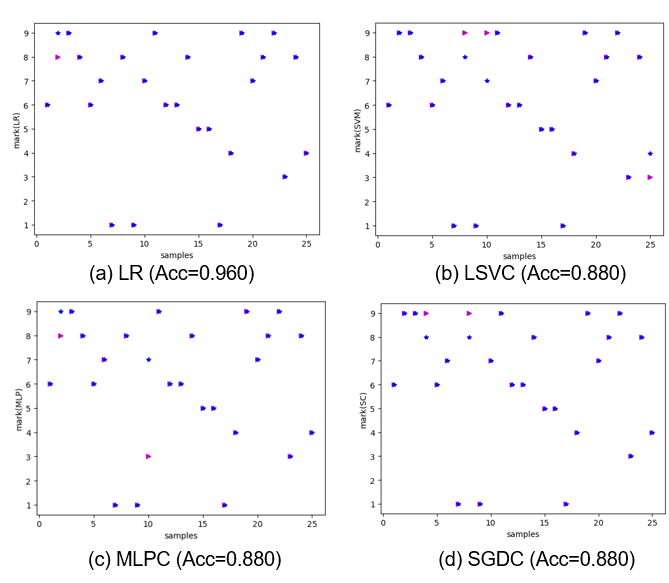
图 7 手写体识别的性能分析(在样本数为 100 的情况下)
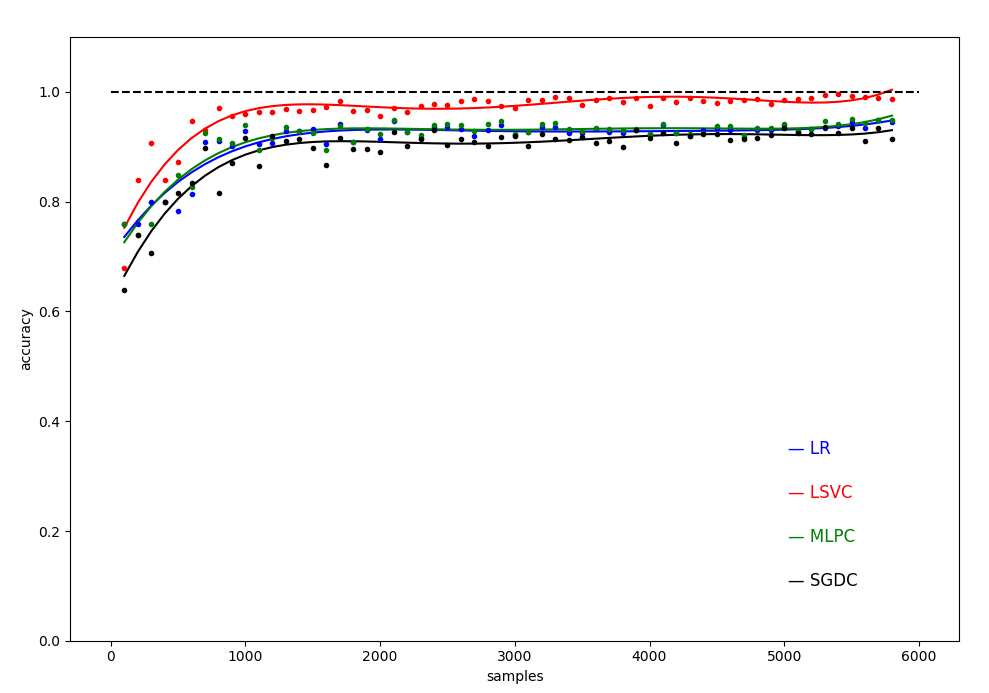
图 8 不同样本数目下的四种模型的测试精度( 5次拟合 )
# 如果对您有帮助,欢迎在 GitHub 上 Star 支持我: https://github.com/coneypo/ML_handwritten_number
# 请尊重他人劳动成果,转载或者使用源码请注明出处: http://www.cnblogs.com/AdaminXie
# 如有问题请联系邮箱 :coneypo@foxmail.com
Python 3 利用机器学习模型 进行手写体数字识别的更多相关文章
- Python 3 利用机器学习模型 进行手写体数字检测
0.引言 介绍了如何生成手写体数字的数据,提取特征,借助 sklearn 机器学习模型建模,进行识别手写体数字 1-9 模型的建立和测试. 用到的几种模型: 1. LR,Logistic Regres ...
- caffe-windows之手写体数字识别例程mnist
caffe-windows之手写体数字识别例程mnist 一.训练测试网络模型 1.准备数据 Caffe不是直接处理原始数据的,而是由预处理程序将原始数据变换存储为LMDB格式,这种方式可以保持较高的 ...
- 【转】机器学习教程 十四-利用tensorflow做手写数字识别
模式识别领域应用机器学习的场景非常多,手写识别就是其中一种,最简单的数字识别是一个多类分类问题,我们借这个多类分类问题来介绍一下google最新开源的tensorflow框架,后面深度学习的内容都会基 ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- [Python]基于CNN的MNIST手写数字识别
目录 一.背景介绍 1.1 卷积神经网络 1.2 深度学习框架 1.3 MNIST 数据集 二.方法和原理 2.1 部署网络模型 (1)权重初始化 (2)卷积和池化 (3)搭建卷积层1 (4)搭建卷积 ...
- Python 3 利用 Dlib 19.7 实现人脸识别和剪切
0.引言 利用python开发,借助Dlib库进行人脸识别,然后将检测到的人脸剪切下来,依次排序显示在新的图像上: 实现的效果如下图所示,将图1原图中的6张人脸检测出来,然后剪切下来,在图像窗口中依次 ...
- 【Keras篇】---利用keras改写VGG16经典模型在手写数字识别体中的应用
一.前述 VGG16是由16层神经网络构成的经典模型,包括多层卷积,多层全连接层,一般我们改写的时候卷积层基本不动,全连接层从后面几层依次向前改写,因为先改参数较小的. 二.具体 1.因为本文中代码需 ...
- 利用keras进行手写数字识别模型训练,并输出训练准确度
from keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.lo ...
- 吴裕雄--天生自然python Google深度学习框架:MNIST数字识别问题
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data INPUT_NODE = 784 ...
随机推荐
- redis 安装方式
1 参考网址 https://www.cnblogs.com/ahjx1628/p/6496529.html https://www.cnblogs.com/smail-bao/p/6164132.h ...
- python中顺序查找分析和实现
顺序查找算法是一种很基本的查找算法,该算法的复杂度一般是最大是O(n),假如加上顺序查找,算法的复杂度 还要降一倍,为O(n/2). Python的代码实现如下所示: def sequential_s ...
- XUL透明异形旋转窗体
200行不到的代码,实现透明异形旋转窗体. 下载(25MB): http://oltag.com:8080/yaolixing/18/11/00/OHUIv52.0.1_3_webTrans20180 ...
- hidden,display,visibility ,jQuery中的hide()区别
hidden是html中的属性,规定元素是否可见 display是css中的样式,规定元素是否显示 visible 是css中的样式,规定元素是否可见 display:none ---不为被隐藏的对象 ...
- @EnableAsync annotation metadata was not injected
[问题描述] @EnableAsync annotation metadata was not injected spring配置初始化时候报错 nested exception is java.la ...
- Python 的类的下划线命名有什么不同?
1. 以一个下划线开头的命名 ,如_getFile2. 以两个下划线开头的命名 ,如__filename3. 以两个下划线开头和结尾的命名,如 __init__()4. 其它 单下划线前缀的 ...
- Windows服务框架与服务的编写
从NT内核开始,服务程序已经变为一种非常重要的系统进程,一般的驻守进程和普通的程序必须在桌面登录的情况下才能运行,而许多系统的基础程序必须在用户登录桌面之前就要运行起来,而利用服务,可以很方便的实现这 ...
- 【转载】Linux下的IO监控与分析
近期要在公司内部做个Linux IO方面的培训, 整理下手头的资料给大家分享下 各种IO监视工具在Linux IO 体系结构中的位置 源自 Linux Performance and Tuning G ...
- div外观例子
title: div外观例子 date: 2018-1-15 14:00:00 tags: 前端 div css categories: 前端框架 --- 标题 我的标题 内容 Font Awesom ...
- Kotlin——从无到有系列教程(5): 你该知道的Kotlin可空类型、空安全(null)、类型转换等特性
在我们熟知的Java中,定义一个变量可以默认不赋值,因为Java的系统会给我们默认赋一个默认值,并且Java可定义一个赋值为null的变量,这样在使用这个变量的时候都会去显示判断该变量是否为null. ...