机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/
通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测。
学习问题一般可以分为:
- 监督学习(supervised learning)
- 分类(classification)
- 回归(regression)
- 非监督学习(unsupervised learning)
- 聚类(clustering)
监督学习和非监督学习的区别就是,监督学习中,样本数据会包含要预测的标签(label),例如给定一组猫和狗的图片并对不同的照片给定对应的标签(猫或狗),而非监督学习只会给定一组图片,并不会给出标签。
分类和回归的区别是,分类的样本数据中的标签有大于等于2种,对于预测数据只需要判断属于其中哪个类即可,而回归则是期望输出由一个或多个连续的变量组成,例如根据鱼的年龄和重量推断鱼的长度。
对于一个已知问题,如何判断需要使用那种方法,scikit-learn给出了一个图,可以根据这个图来确定,链接:
http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html

接下来的内容包括:
- 样本数据的获取和生成
- 分类器训练和预测
- 持久化分类器
- 简单交叉验证
- 例子
① 样本数据获取和生成
scikit-learn中包含了很多供初学者学习的样本数据,这些数据包含在sklearn.datasets包中,比较典型的数据是iris,这个数据集给出了iris花的花瓣和萼片的长度和宽度及对应花的种类:

读取这个数据集的方法很简单:
from sklearn import datasets # 读取iris数据集
iris = datasets.load_iris()
# 获取数据集中的属性值(花瓣和萼片长度宽度)
iris_X = iris.data
# 获取数据集中的标签,分别是哪种花
iris_y = iris.target print(iris_X[::50])
print(iris_y[::50])
因为数据集是有序的并且长度为150(每种花50个),所以打印的时候步长设置为50,我们可以看到结果如下所示:

下面的这个数组就是对应的分类,这里简化为数字123了。
在学习中,也可以手动的创造自己想要的数据集,比如生成一组回归数据:
X, y = datasets.make_regression(n_samples=200, n_features=1, n_targets=1, noise=10)
得到的数据集如图所示:

构造的方法参考API文档即可:http://scikit-learn.org/stable/modules/classes.html#samples-generator
② 训练分类器和进行预测
接着我们将iris数据集分为两部分,一部分用来训练分类器,另一部分则是用来进行测试,看看预测的正确率如何。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier # 读取iris数据集
iris = datasets.load_iris()
# 获取数据集中的属性值(花瓣和萼片长度宽度)
iris_X = iris.data
# 获取数据集中的标签,分别是哪种花
iris_y = iris.target # 将数据分别训练数据和测试数据,测试数据为20%
train_X, test_X, train_y, test_y = train_test_split(iris_X, iris_y, test_size=0.2) # 创建K邻近分类器
knn = KNeighborsClassifier()
# 输入训练数据
knn.fit(train_X, train_y)
# 得到预测标签
predicts = knn.predict(test_X) # 对比结果
print(predicts)
print(test_y) # 计算准确率
print(knn.score(test_X, test_y))
这里首先将数据分成训练和测试数据,接着创建了一个K临近分类器,通过fit方法传入训练数据,predict方法对测试数据进行测试。
得到的结果如图:

这里的准确率可能会不同,因为使用train_test_split方法分离数据会打乱数据集顺序并且随机选择。
这里的K临近分类器,是一个比较简单的分类器,对于每个测试样本,分类器会选取K个(默认是5个)附近的点进行比较,判断哪个分类的点多,则判断为对应的类。因为每个样本有四个属性,所以样本属性需要一个四维空间坐标系表示,但是距离计算公式是类似二维空间的。
当然,scikit-learn还有其他的分类器,可以参考API文档和例子:
http://scikit-learn.org/stable/supervised_learning.html#supervised-learning
③ 持久化
对于一个训练好的模型,可以进行持久化,也就是每次需要使用模型的时候,不需要重新训练。
持久化的方法有多种,可以利用python提供的pickle,但是scikit-learn提供了效率更高的joblib:
from sklearn.externals import joblib
# 持久化knn分类器
joblib.dump(knn, 'save/knn.pk')
# 读取knn分类器
knn2 = joblib.load('save/knn.pk')
print(knn2.score(test_X, test_y))
④ 交叉验证
交叉验证就是对训练数据和测试数据进行多次分组测试模型的准确率,再计算平均值来表示当前模型的优劣。
一个模型中的不同参数,会不同程度的影响模型的准确率,如果模型架构配置不恰当,还会出现过度拟合(overfitting)或者拟合不足(underfitting):
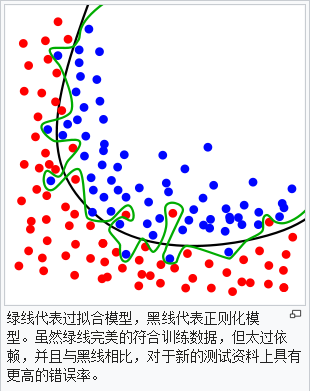
交叉验证,可以通过cross_val_score方法来计算认证的每个分组的分数:
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier iris = datasets.load_iris()
X = iris.data
y = iris.target knn = KNeighborsClassifier() # 交叉验证分数,分为5组
scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy')
# 输出分组平均值
print(scores.mean()) # 让K邻近分类器的k从1到30取值并计算认证分数
k_range = range(1, 31)
k_scores = []
for r in k_range:
# 设置k,也就是n_neighbors参数
kn = KNeighborsClassifier(n_neighbors=r)
# 求平均值并加入k_scores中
k_scores.append(cross_val_score(kn, X, y, cv=10, scoring='accuracy').mean()) print(k_scores)
打印得到的结果:

使用print打印结果虽然能显示,但是不直观,这里可以通过matplotlib这个库来生成图表,更加直观的看出来对于每个k,哪个的分数更高:
import matplotlib.pyplot as plt
# 以k_range为x,k_scores为y,拟点并连线
plt.plot(k_range, k_scores)
# 设置x和y的标签
plt.xlabel('n_neighbors')
plt.ylabel('score')
# 展示图表
plt.show()
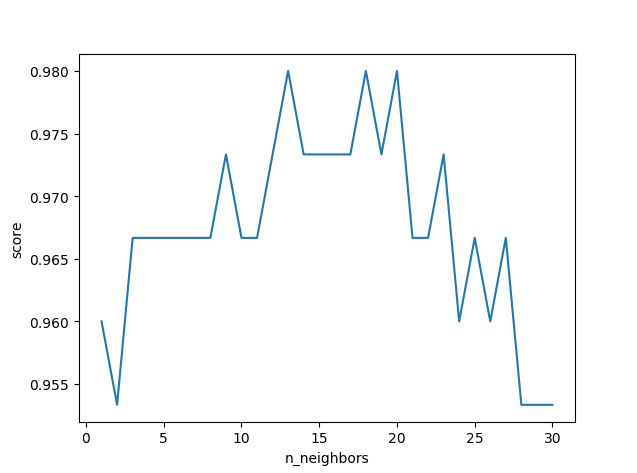
可以看到,k并非越大越好,我们得到这个图表,就可以选择一个得分高对应的k,例如上图的13作为模型的n_neighbors参数。
⑤ 例子
这个例子也是datasets中包含的,手写体数字分类。这里使用官方的一个例子:
http://scikit-learn.org/stable/auto_examples/classification/plot_digits_classification.html#sphx-glr-auto-examples-classification-plot-digits-classification-py
训练完了之后,持久化模型,接着可以尝试预测一下我们自己设计的数字(8*8像素灰度图片,放大模糊了):

测试代码:
from PIL import Image
import numpy as np
from sklearn.externals import joblib # 使用pil获取每个像素点的颜色信息(灰度图为二维数组)
img = Image.open('four.jpg')
img = np.array(img)
for i in range(8):
for j in range(8):
# 根据datasets中的数据修改图片数据信息
img[i][j] //= 16
img[i][j] = 15 - img[i][j] clf = joblib.load('save/digit')
print('推断图片中的数字为:', clf.predict(img.reshape((1, -1))))
结果:
最后,关于回归和聚类的demo,可以参考官方的Examples:
http://scikit-learn.org/stable/auto_examples/index.html
有误,请指出,万分感谢
机器学习-scikit learn学习笔记的更多相关文章
- (转载)林轩田机器学习基石课程学习笔记1 — The Learning Problem
(转载)林轩田机器学习基石课程学习笔记1 - The Learning Problem When Can Machine Learn? Why Can Machine Learn? How Can M ...
- Learning How to Learn学习笔记(转)
add by zhj: 工作中提高自己水平的最重要的一点是——快速的学习能力.这篇文章就是探讨这个问题的,掌握了快速学习能力的规律,你自然就有了快速学习能力了. 原文:Learning How to ...
- 《机器学习实战》学习笔记第十四章 —— 利用SVD简化数据
相关博客: 吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA) <机器学习实战>学习笔记第十三章 —— 利用PCA来简化数据 奇异值分解(SVD)原理与在降维中的应用 机器学习( ...
- 《机器学习实战》学习笔记第九章 —— 决策树之CART算法
相关博文: <机器学习实战>学习笔记第三章 —— 决策树 主要内容: 一.CART算法简介 二.分类树 三.回归树 四.构建回归树 五.回归树的剪枝 六.模型树 七.树回归与标准回归的比较 ...
- Coursera台大机器学习基础课程学习笔记1 -- 机器学习定义及PLA算法
最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一机器学习是什么? 感觉和 Tom M. Mitchell的定义几乎一致, A computer program ...
- [转]Python3《机器学习实战》学习笔记(一):k-近邻算法(史诗级干货长文)
转自http://blog.csdn.net/c406495762/article/details/75172850 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 一 简 ...
- MNIST机器学习入门【学习笔记】
平台信息:PC:ubuntu18.04.i5.anaconda2.cuda9.0.cudnn7.0.5.tensorflow1.10.GTX1060 作者:庄泽彬(欢迎转载,请注明作者) 说明:本文是 ...
- Andrew N.G的机器学习公开课学习笔记(一):机器学习的动机与应用
机器学习由对于人工智能的研究而来,是一个综合性和应用性学科,可以用来解决计算机视觉/生物学/机器人和日常语言等各个领域的问题,机器学习的目的是让计算机具有像人类的学习能力,这样做是因为我们发现,计算机 ...
- Coursera台大机器学习基础课程学习笔记2 -- 机器学习的分类
总体思路: 各种类型的机器学习分类 按照输出空间类型分Y 按照数据标记类型分yn 按照不同目标函数类型分f 按照不同的输入空间类型分X 按照输出空间类型Y,可以分为二元分类,多元分类,回归分析以及结构 ...
随机推荐
- ABP Zero 多租户管理
ABPZero - 多租户管理 启用多租户 ASP.NET Boilerplate和module-zero可以运行多租户或单租户模式.多租户默认为禁用.我们可以在我们的模块PreInitialize方 ...
- hudson入门
持续集成hudson入门博客分类: Java 单元测试配置管理maven项目管理Tomcat 极限编程中一项建议实践便是持续集成,持续集成是指在开发阶段,对项目进行持续性自动化编译.测 ...
- redux-form的学习笔记
redux是一种常用的与react框架搭配的一种数据流架构,而伴随着redux的出现,也出现了许多基于redux开源的第三方库,而redux-form就是其中之一的开源组件库,到今天我写下这篇笔记为止 ...
- UISearchController 搜索
UISearchController实现搜索 通过 UISearchController 实现 UISearchResultsUpdating 这个委托实现上面的效果: 视图中中需要声明UISearc ...
- 九度OJ题目1076:N的阶乘 (java)运用BigInteger的例子。
题目描述: 输入一个正整数N,输出N的阶乘. 输入: 正整数N(0<=N<=1000) 输出: 输入可能包括多组数据,对于每一组输入数据,输出N的阶乘 样例输入: 4 5 15 样例输出: ...
- [设计模式] Iterator - 迭代器模式:由一份奥利奥早餐联想到的设计模式
Iterator - 迭代器模式 目录 前言 回顾 UML 类图 代码分析 抽象的 UML 类图 思考 前言 这是一包奥利奥(数组),里面藏了很多块奥利奥饼干(数组中的元素),我将它们放在一个碟子上慢 ...
- 从Visual Studio看微软20年技术变迁
前言 这个世界从来都不缺变革,从工业革命到晶体管和集成电路,从生活电器到物联网,从简陋人机到精致体验,我们在享受技术带来的便捷的同时,也在为复杂设计而带来的挑战和生产力下降而痛并快乐着.而迫切期盼的, ...
- 使用sudo提示用户不在sudoers文件中的解决方法
切换到root用户 [linux@localhost ~]$ su root 密码: [root@localhost ~]# 2 查看/etc/sudoers文件权限,如果只读权限,修改为可写权限 [ ...
- 移植python笔记
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 编译环境:ubuntu-14.04.1 编译器:gcc.arm-hisiv200-linux-gnueabi P ...
- iOS开发之通过代码自定义一个控件
关于控件的继承关系(面试重点): (1)所有的控件都继承自UIView. (2)能监听事件的都是先继承自UIControl,UIControl再继承自UIView.比如UIButton. (3)能整体 ...