微信公众号批量爬取java版
最近需要爬取微信公众号的文章信息。在网上找了找发现微信公众号爬取的难点在于公众号文章链接在pc端是打不开的,要用微信的自带浏览器(拿到微信客户端补充的参数,才可以在其它平台打开),这就给爬虫程序造成很大困扰。后来在知乎上看到了一位大牛用php写的微信公众号爬取程序,就直接按大佬的思路整了整搞成java的了。改造途中遇到蛮多细节问题,拿出来分享一下。
附上大牛文章链接:https://zhuanlan.zhihu.com/c_65943221 写php的或者只需要爬取思路的可以直接看这个,思路写的非常详细。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
系统的基本思路是在安卓模拟器上运行微信,模拟器设置代理,通过代理服务器拦截微信数据,将得到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs,anyproxy代理,安卓模拟器
nodejs下载地址:http://nodejs.cn/download/,我下载的是windows版的,下好直接安装就行。安装好后,直接运行C:\Program Files\nodejs\npm.cmd 会自动配置好环境。
anyproxy安装:按上一步安装好nodejs之后,直接在cmd运行 npm install -g anyproxy 就会安装了
安卓模拟器随便在网上下一个就好了,一大堆。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
首先为代理服务器安装证书,anyproxy默认不解析https链接,安装证书后就可以解析了,在cmd执行anyproxy --root 就会安装证书,之后还得在模拟器也下载这个证书。
然后输入anyproxy -i 命令 打开代理服务。(记得加上参数!)

记住这个ip和端口,之后安卓模拟器的代理就用这个。现在用浏览器打开网页:http://localhost:8002/ 这是anyproxy的网页界面,用于显示http传输数据。
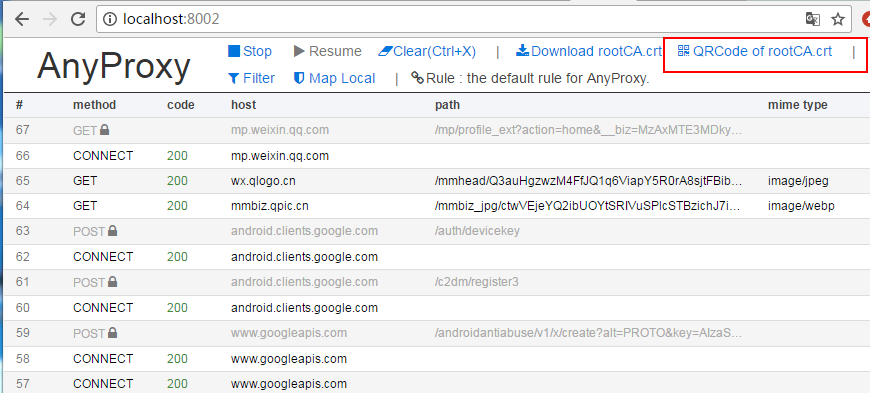
点击上面红框框里面的菜单,会出一个二维码,用安卓模拟器扫码识别,模拟器(手机)就会下载证书了,安装上就好了。
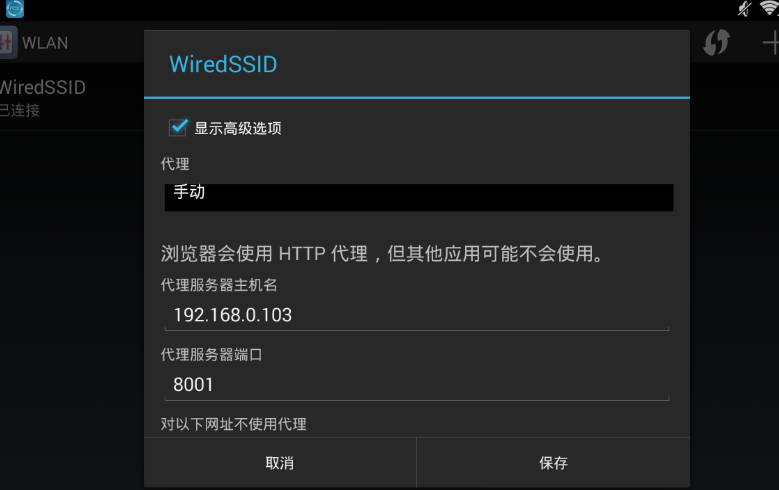
现在准备为模拟器设置代理,代理方式设置为手动,代理ip为运行anyproxy机器的ip,端口是8001
到这里准备工作基本完成,在模拟器上打开微信随便打开一个公众号的文章,就能从你刚打开的web界面中看到anyproxy抓取到的数据:
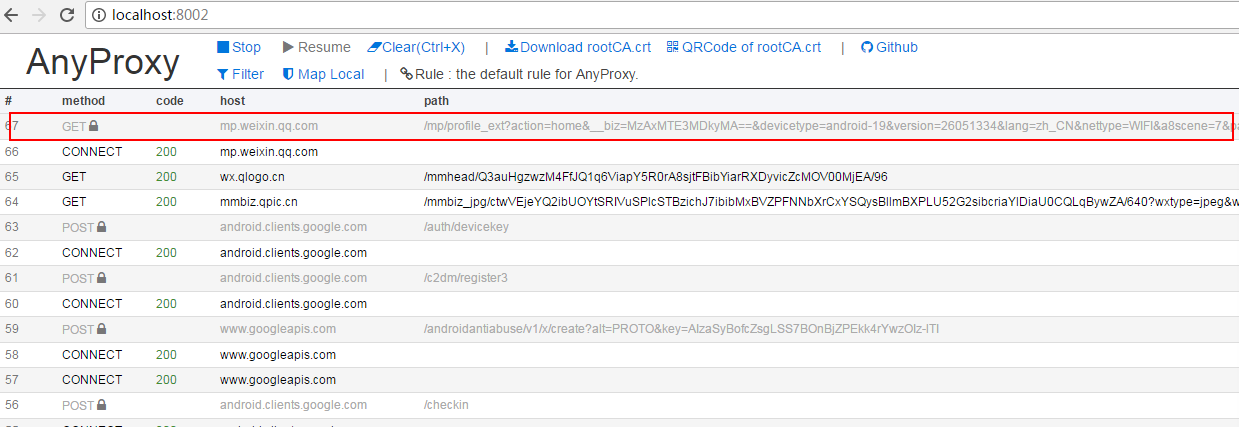
上面红框内就是微信文章的链接,点击进去可以看到具体的数据。如果response body里面什么都没有可能证书安装有问题。
如果上面都走通了,就可以接着往下走了。
这里我们靠代理服务抓微信数据,但总不能抓取一条数据就自己操作一下微信,那样还不如直接人工复制。所以我们需要微信客户端自己跳转页面。这时就可以使用anyproxy拦截微信服务器返回的数据,往里面注入页面跳转代码,再把加工的数据返回给模拟器实现微信客户端自动跳转。
打开anyproxy中的一个叫rule_default.js的js文件,windows下该文件在:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
在文件里面有个叫replaceServerResDataAsync: function(req,res,serverResData,callback)的方法,这个方法就是负责对anyproxy拿到的数据进行各种操作。一开始应该只有callback(serverResData);这条语句的意思是直接返回服务器响应数据给客户端。直接删掉这条语句,替换成大牛写的如下代码。这里的代码我并没有做什么改动,里面的注释也解释的给非常清楚,直接按逻辑看懂就行,问题不大。
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
//console.log("开始第一种页面爬取");
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
//console.log("开始第一种页面爬取向下翻形式");
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
//console.log("开始第一种页面爬取 结束");
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
//console.log(e);
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
//callback(serverResData);
},
这里简单解释一下,微信公众号的历史消息页链接有两种形式:一种以 mp.weixin.qq.com/mp/getmasssendmsg 开头,另一种是 mp.weixin.qq.com/mp/profile_ext 开头。历史页是可以向下翻的,如果向下翻将触发js事件发送请求得到json数据(下一页内容)。还有公众号文章链接,以及文章的阅读量和点赞量的链接(返回的是json数据),这几种链接的形式是固定的可以通过逻辑判断来区分。这里有个问题就是历史页如果需要全部爬取到该怎么做到。我的思路是通过js去模拟鼠标向下滑动,从而触发提交加载下一部分列表的请求。或者直接利用anyproxy分析下滑加载的请求,直接向微信服务器发生这个请求。但都有一个问题就是如何判断已经没有余下数据了。我是爬取最新数据,暂时没这个需求,可能以后要。如果有需求的可以尝试一下。
下图是上文中的HttpPost方法内容。
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
console.log("开始执行转发操作");
try{
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
data = require('querystring').stringify(data);
var options = {
method: "POST",
host: "xxx",//注意没有http://,这是服务器的域名。
port: xxx,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": data.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(data);
req.end();
}catch(e){
console.log("错误信息:"+e);
}
console.log("转发操作结束");
}
做完以上工作,接下来就是按自己业务来完成服务端代码了,我们的服务用于接收代理服务器发过来的数据进行处理,进行持久化操作,同时向代理服务器发送需要注入到微信的js代码。针对代理服务器拦截到的几种不同链接发来的数据,我们就需要设计相应的方法来处理这些数据。从anyproxy处理微信数据的js方法replaceServerResDataAsync: function(req,res,serverResData,callback)中,我们可以知道至少需要对公众号历史页数据、公众号文章页数据、公众号文章点赞量和阅读量数据设计三种方法来处理。同时我们还需要设计一个方法来生成爬取任务,完成公众号的轮寻爬取。如果需要爬取更多数据,可以从anyproxy抓取到的链接中分析出更多需要的数据,然后往replaceServerResDataAsync: function(req,res,serverResData,callback)中添加判定,拦截到需要的数据发送到自己的服务器,相应的在服务端添加方法处理该类数据就行了。
我是用java写的服务端代码。
处理公众号历史页数据方法:
public void getMsgJson(String str ,String url) throws UnsupportedEncodingException {
// TODO Auto-generated method stub
String biz = "";
Map<String,String> queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
}
/**
* 从数据库中查询biz是否已经存在,如果不存在则插入,
* 这代表着我们新添加了一个采集目标公众号。
*/
List<WeiXin> results = weiXinMapper.selectByBiz(biz);
if(results == null || results.size() == 0){
WeiXin weiXin = new WeiXin();
weiXin.setBiz(biz);
weiXin.setCollect(System.currentTimeMillis());
weiXinMapper.insert(weiXin);
}
//System.out.println(str);
//解析str变量
List<Object> lists = JsonPath.read(str, "['list']");
for(Object list : lists){
Object json = list;
int type = JsonPath.read(json, "['comm_msg_info']['type']");
if(type == 49){//type=49表示是图文消息
String content_url = JsonPath.read(json, "$.app_msg_ext_info.content_url");
content_url = content_url.replace("\\", "").replaceAll("amp;", "");//获得图文消息的链接地址
int is_multi = JsonPath.read(json, "$.app_msg_ext_info.is_multi");//是否是多图文消息
Integer datetime = JsonPath.read(json, "$.comm_msg_info.datetime");//图文消息发送时间
/**
* 在这里将图文消息链接地址插入到采集队列库tmplist中
* (队列库将在后文介绍,主要目的是建立一个批量采集队列,
* 另一个程序将根据队列安排下一个采集的公众号或者文章内容)
*/
try{
if(content_url != null && !"".equals(content_url)){
TmpList tmpList = new TmpList();
tmpList.setContentUrl(content_url);
tmpListMapper.insertSelective(tmpList);
}
}catch(Exception e){
System.out.println("队列已存在,不插入!");
}
/**
* 在这里根据$content_url从数据库post中判断一下是否重复
*/
List<Post> postList = postMapper.selectByContentUrl(content_url);
boolean contentUrlExist = false;
if(postList != null && postList.size() != 0){
contentUrlExist = true;
}
if(!contentUrlExist){//'数据库post中不存在相同的$content_url'
Integer fileid = JsonPath.read(json, "$.app_msg_ext_info.fileid");//一个微信给的id
String title = JsonPath.read(json, "$.app_msg_ext_info.title");//文章标题
String title_encode = URLEncoder.encode(title, "utf-8");
String digest = JsonPath.read(json, "$.app_msg_ext_info.digest");//文章摘要
String source_url = JsonPath.read(json, "$.app_msg_ext_info.source_url");//阅读原文的链接
source_url = source_url.replace("\\", "");
String cover = JsonPath.read(json, "$.app_msg_ext_info.cover");//封面图片
cover = cover.replace("\\", "");
/**
* 存入数据库
*/
// System.out.println("头条标题:"+title);
// System.out.println("微信ID:"+fileid);
// System.out.println("文章摘要:"+digest);
// System.out.println("阅读原文链接:"+source_url);
// System.out.println("封面图片地址:"+cover);
Post post = new Post();
post.setBiz(biz);
post.setTitle(title);
post.setTitleEncode(title_encode);
post.setFieldId(fileid);
post.setDigest(digest);
post.setSourceUrl(source_url);
post.setCover(cover);
post.setIsTop(1);//标记一下是头条内容
post.setIsMulti(is_multi);
post.setDatetime(datetime);
post.setContentUrl(content_url);
postMapper.insert(post);
}
if(is_multi == 1){//如果是多图文消息
List<Object> multiLists = JsonPath.read(json, "['app_msg_ext_info']['multi_app_msg_item_list']");
for(Object multiList : multiLists){
Object multiJson = multiList;
content_url = JsonPath.read(multiJson, "['content_url']").toString().replace("\\", "").replaceAll("amp;", "");//图文消息链接地址
/**
* 这里再次根据$content_url判断一下数据库中是否重复以免出错
*/
contentUrlExist = false;
List<Post> posts = postMapper.selectByContentUrl(content_url);
if(posts != null && posts.size() != 0){
contentUrlExist = true;
}
if(!contentUrlExist){//'数据库中不存在相同的$content_url'
/**
* 在这里将图文消息链接地址插入到采集队列库中
* (队列库将在后文介绍,主要目的是建立一个批量采集队列,
* 另一个程序将根据队列安排下一个采集的公众号或者文章内容)
*/
if(content_url != null && !"".equals(content_url)){
TmpList tmpListT = new TmpList();
tmpListT.setContentUrl(content_url);
tmpListMapper.insertSelective(tmpListT);
}
String title = JsonPath.read(multiJson, "$.title");
String title_encode = URLEncoder.encode(title, "utf-8");
Integer fileid = JsonPath.read(multiJson, "$.fileid");
String digest = JsonPath.read(multiJson, "$.digest");
String source_url = JsonPath.read(multiJson, "$.source_url");
source_url = source_url.replace("\\", "");
String cover = JsonPath.read(multiJson, "$.cover");
cover = cover.replace("\\", "");
// System.out.println("标题:"+title);
// System.out.println("微信ID:"+fileid);
// System.out.println("文章摘要:"+digest);
// System.out.println("阅读原文链接:"+source_url);
// System.out.println("封面图片地址:"+cover);
Post post = new Post();
post.setBiz(biz);
post.setTitle(title);
post.setTitleEncode(title_encode);
post.setFieldId(fileid);
post.setDigest(digest);
post.setSourceUrl(source_url);
post.setCover(cover);
post.setIsTop(0);//标记一下不是头条内容
post.setIsMulti(is_multi);
post.setDatetime(datetime);
post.setContentUrl(content_url);
postMapper.insert(post);
}
}
}
}
}
}
处理公众号文章页的方法:
public String getWxPost() {
// TODO Auto-generated method stub
/**
* 当前页面为公众号文章页面时,读取这个程序
* 首先删除采集队列表中load=1的行
* 然后从队列表中按照“order by id asc”选择多行(注意这一行和上面的程序不一样)
*/
tmpListMapper.deleteByLoad(1);
List<TmpList> queues = tmpListMapper.selectMany(5);
String url = "";
if(queues != null && queues.size() != 0 && queues.size() > 1){
TmpList queue = queues.get(0);
url = queue.getContentUrl();
queue.setIsload(1);
int result = tmpListMapper.updateByPrimaryKey(queue);
System.out.println("update result:"+result);
}else{
System.out.println("getpost queues is null?"+queues==null?null:queues.size());
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
if((Math.random()>0.5?1:0) == 1){
url = "http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=" + biz +
"#wechat_webview_type=1&wechat_redirect";//拼接公众号历史消息url地址(第一种页面形式)
}else{
url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
}
url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getPost weiXin updateResult:"+result);
}
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "<script>setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");</script>";
return jsCode;
}
处理公众号点赞量和阅读量的方法:
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map<String,String> queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根据biz和sn找到对应的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json数据:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//阅读量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//点赞量
}catch(Exception e){
read_num = 123;//阅读量
like_num = 321;//点赞量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
* $sql = "delete from `队列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后将阅读量和点赞量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}
处理跳转向微信注入js的方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 当前页面为公众号历史消息时,读取这个程序
* 在采集队列表中有一个load字段,当值等于1时代表正在被读取
* 首先删除采集队列表中load=1的行
* 然后从队列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//队列表为空
/**
* 队列表如果空了,就从存储公众号biz的表中取得一个biz,
* 这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,
* 就得到时间戳最小的一个公众号记录,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得当前这一行的content_url字段
url = queue.getContentUrl();
//将load字段update为1
tmpListMapper.updateByContentUrl(url);
}
//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
//echo "<script>setTimeout(function(){window.location.href='".$url."';},2000);</script>";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "<script>setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");</script>";
return jsCode;
}
以上就是对处理代理服务器拦截到的数据进行处理的程序。这里有一个需要注意的问题,程序会对数据库中的每个收录的公众号进行轮循访问,甚至是已经存储的文章也会再次访问,目的是为了一直更新文章的阅读数和点赞数。如果需要抓取大量的公众号建议对添加任务队列的代码进行修改,添加条件限制,否则公众号一多 轮循抓取重复数据将十分影响效率。
至此就将微信公众号的文章链接全部爬取到,而且这个链接是永久有效而且可以在浏览器打开的链接,接下来就是写爬虫程序从数据库中拿链接爬取文章内容等信息了。
我是用webmagic写的爬虫,轻量好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List<Post> posts;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和谐文章 此处做判定如果有直接删除记录或设置表示位表示文章被和谐
if(content == null){
System.out.println("文章已和谐!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//纯文本内容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章发布时间
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公众号名称
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("发布时间:"+pubTime);
// System.out.println("公众号名称:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章标题
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章点赞数
int readNum = post.getReadnum();//文章阅读数
String contentUrl = post.getContentUrl();//文章链接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//纯文本内容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站点名称 公众号名称
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公众号");//来源媒体类型
WechatStorage.saveWechatInfo(wechatBean);
//标示文章已经被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List<Post> inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取时间" + ((endTime - startTime) / 1000) + "秒--");
}
}
其它的一些无关逻辑的存储数据代码就不贴了,这里我把代理服务器抓取到的数据存在了mysql,把自己的爬虫程序爬到的数据存储在了mongodb。
下面是自己爬取到的公众号号的信息:
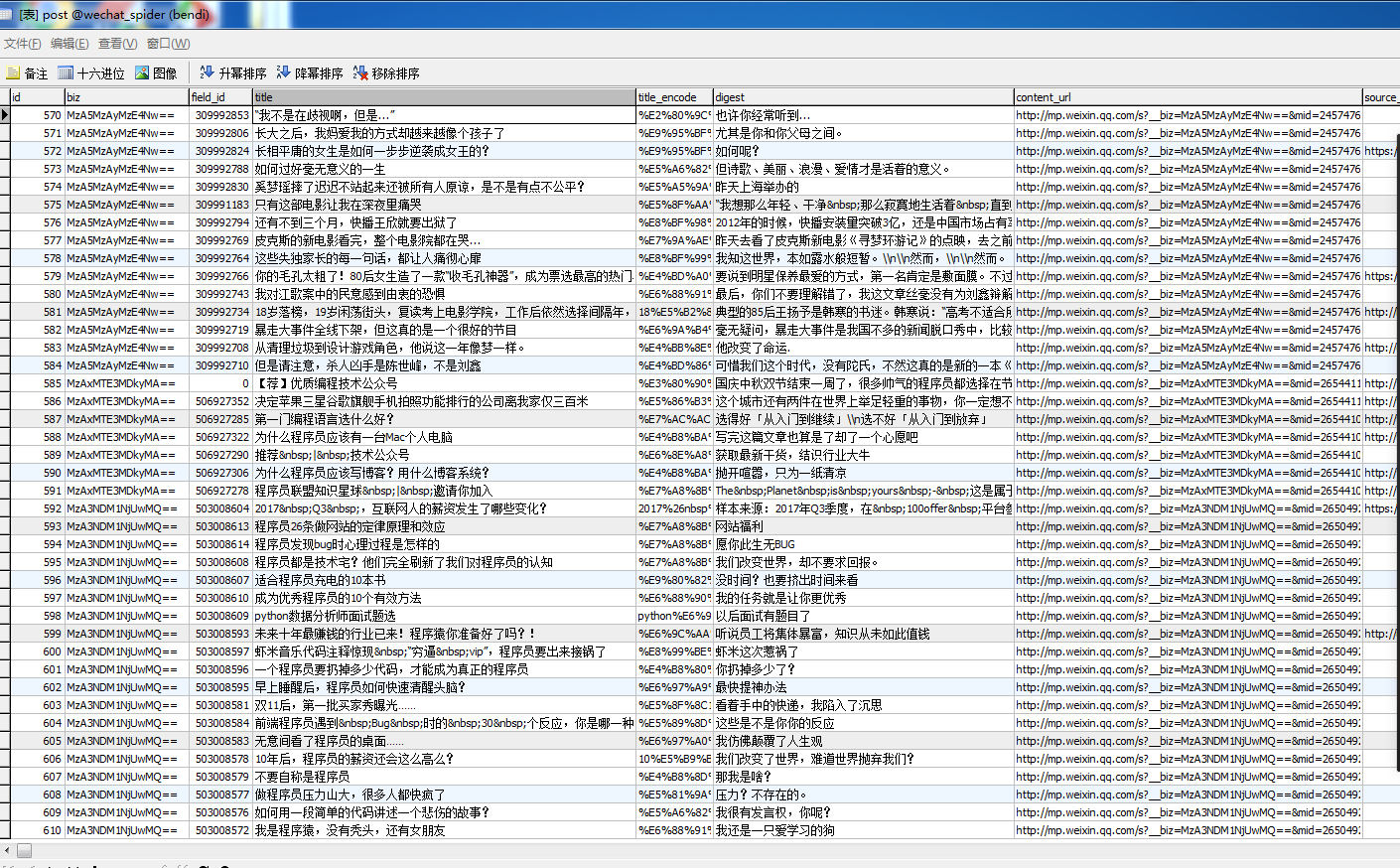
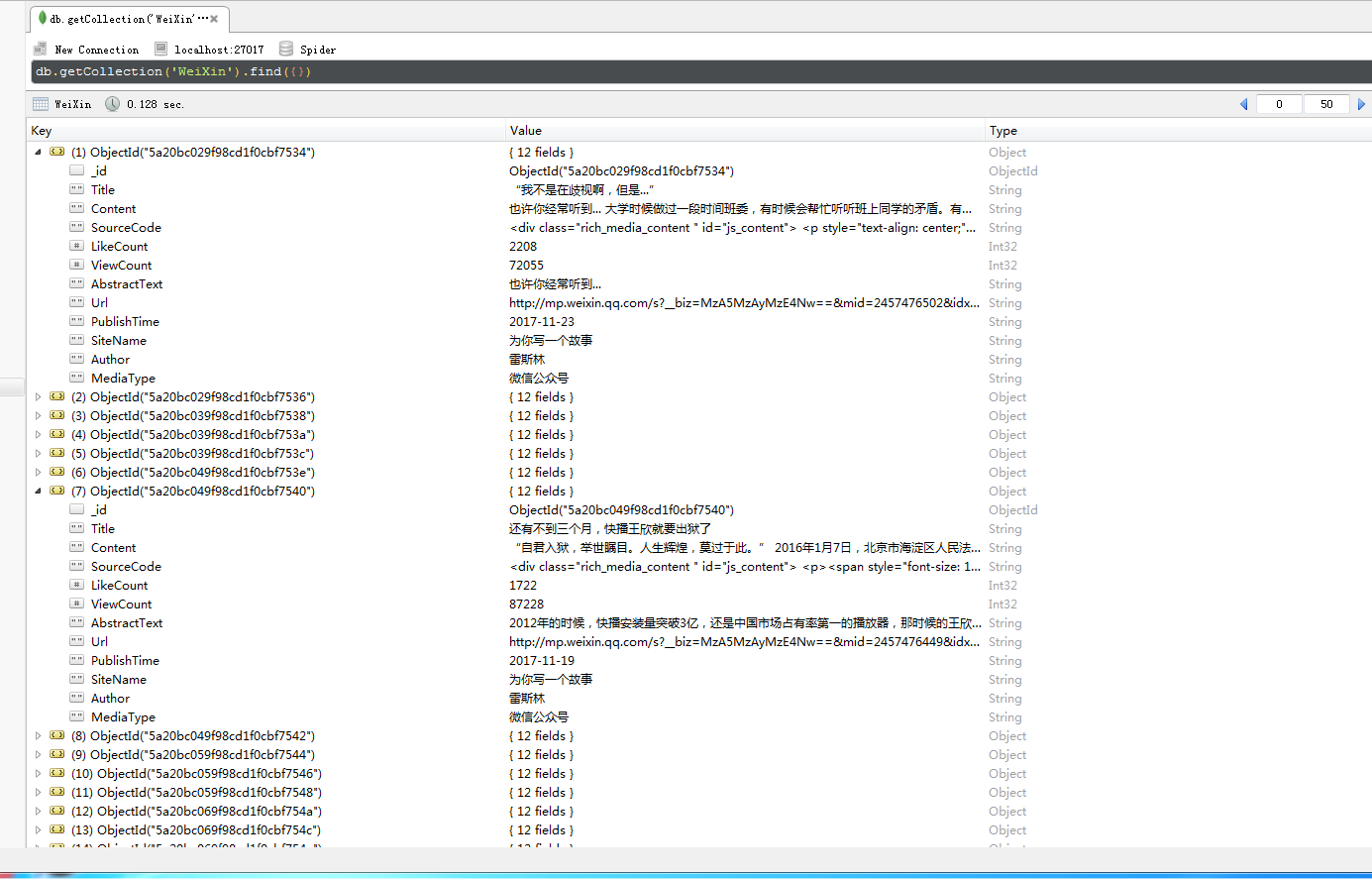
___________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________18.4.23更新
微信已经修改点赞量和阅读量请求链接,链接中已不包含参数biz和sn,故而我们拿到阅读量和点赞量后无法找到属于哪篇文章了。
但是可以从请求头中的referer 获取到,看下图
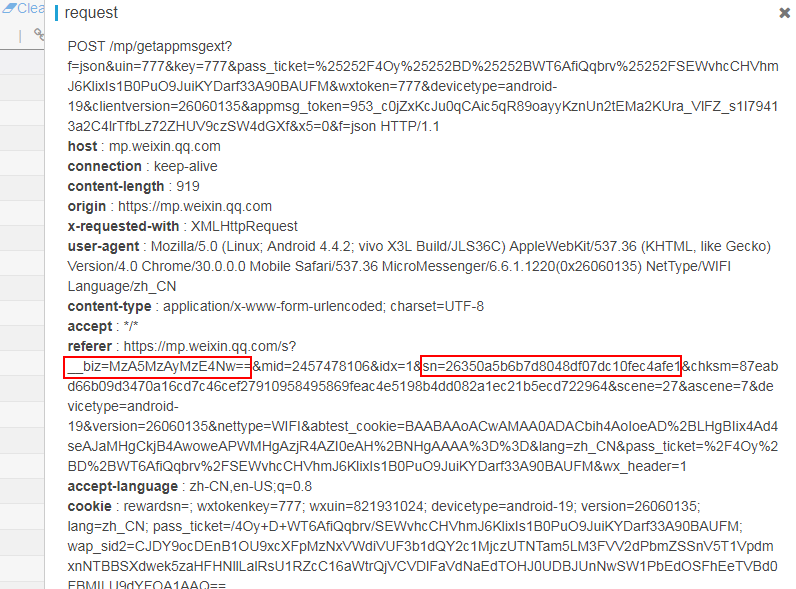
然后我们小小修改一下rule_default.js文件,把请求头数据获取到,丢给服务器,后台再解析数据拿到referer 提取出里面的sn和biz就ok了
nodejs获取请求头的方法:req.headers 拿到后记得做下转换JSON.stringify(xxx) 然后丢给后台就行了 修改十行不到的代码就不贴出来了
最后提醒下要控制采集频率,别放在那儿一直采,会被警告恶意刷公众号文章流量,我已经被封了一个小号!!!共勉
爱好技术的可以一起交流交流 我微信号:zazymA
微信公众号批量爬取java版的更多相关文章
- 破解微信防盗链&微信公众号文章爬取方案
破解微信图文防盗链:https://www.cnblogs.com/xsxshmily/p/8000043.html 图片解除防盗链:https://blog.csdn.net/show_ljw/ar ...
- Python 微信公众号文章爬取
一.思路 我们通过网页版的微信公众平台的图文消息中的超链接获取到我们需要的接口 从接口中我们可以得到对应的微信公众号和对应的所有微信公众号文章. 二.接口分析 获取微信公众号的接口: https:// ...
- 微信公众号支付开发全过程 --JAVA
按照惯例,开头总得写点感想 ------------------------------------------------------------------ 业务流程 这个微信官网说的还是很详细的 ...
- 到处是坑的微信公众号支付开发(java)
之前公司项目开发中支付是用阿里的支付做的,那叫一个简单,随意:悲催的是,现在公司开发了微信公众号,所以我步入了全是坑的微信支付开发中... ------------------------------ ...
- 利用微信公众平台实现自动回复消息—java版
最近公司需要拿微信公众平台做个东西,所以就开始了最基本学习,网上很多是php版的,对于我这个只会java,不会php的就只能在网上找点只言片语来一点一点学习了.不费话了直接贴图看效果(很简单的). 不 ...
- 微信公众号网页授权登录--JAVA
网上搜资料时,网友都说官方文档太垃圾了不易看懂,如何如何的.现在个人整理了一个通俗易懂易上手的,希望可以帮助到刚接触微信接口的你. 请看流程图!看懂图,就懂了一半了: 其实整体流程大体只需三步:用户点 ...
- 微信公众号发送消息模板(java)
这段时间接触公众号开发,写下向用户发送消息模板的接口调用 先上接口代码 public static JSONObject sendModelMessage(ServletContext context ...
- [5] 微信公众号开发 - 微信支付功能开发(网页JSAPI调用)
1.微信支付的流程 如下三张手机截图,我们在微信网页端看到的支付,表面上看到的是 "点击支付按钮 - 弹出支付框 - 支付成功后出现提示页面",实际上的核心处理过程是: 点击支付按 ...
- 微信公众号开发 [05] 微信支付功能开发(网页JSAPI调用)
1.微信支付的流程 如下三张手机截图,我们在微信网页端看到的支付,表面上看到的是 "点击支付按钮 - 弹出支付框 - 支付成功后出现提示页面",实际上的核心处理过程是: 点击支付按 ...
随机推荐
- 【NOIP2015提高组】Day2 T1 跳石头
题目描述 这项比赛将在一条笔直的河道中进行,河道中分布着一些巨大岩石.组委会已经选择好了两块岩石作为比赛起点和终点.在起点和终点之间,有 N 块岩石(不含起点和终 点的岩石).在比赛过程中,选手们将从 ...
- 【NOIP2015提高组】 Day1 T3 斗地主
[题目描述] 牛牛最近迷上了一种叫斗地主的扑克游戏.斗地主是一种使用黑桃.红心.梅花.方片的A到K加上大小王的共54张牌来进行的扑克牌游戏.在斗地主中,牌的大小关系根据牌的数码表示如下:3<4& ...
- C 指针的几个注意点
1.静态指针在初始化时必须使用编译时可以确定地址表达式完成赋值,如 static int a; static int* pa = &a;//初始化时必须使用可以确定地址的表达式 int b; ...
- 解析 .Net Core 注入 (3) 创建对象
回顾 通过前两节的学习,我们知道 IServiceCollection 以元数据(ServiceDescriptor)的形式存放着用户注册的服务,它的 IServiceCollection 的拓展方法 ...
- PHPExcel-1.8导出
//PHPExcel-1.8导出excel<?phpheader("Content-type: text/html; charset=utf-8");mysql_query( ...
- C++中引用的底层实现
为了研究一下C++中引用的底层实现,写了一个小代码验证其中的基本原理. 引用是一个变量的别名,到底会不会为引用申请内存空间?如果申请空间,空间存放的是什么,下面的代码就主要解决这个疑问. 代码如下,详 ...
- Leetcode题解(21)
62. Unique Paths 题目 分析: 机器人一共要走m+n-2步,现在举个例子类比,有一个m+n-2位的二进制数,现在要在其中的m位填0,其余各位填1,一共有C(m+n-2,m-1)种可能, ...
- Ubuntu下通过makefile生成静态库和动态库简单实例
本文转自http://blog.csdn.net/fengbingchun/article/details/17994489 Ubuntu环境:14.04 首先创建一个test_makefile_gc ...
- 磁盘管理之 raid 文件系统 分区
第1章 RAID 磁盘阵列 1.1 使用raid的目的 1)获得更大的容量 2)让数据更安全 3)读写速度更快 1.2 raid0.raid1.raid5.raid10对比 磁头 0磁道 1扇区 前4 ...
- two.js之实现动画效果
一.什么是two.js? Two.js 是面向现代 Web 浏览器的一个二维绘图 API.Two.js 可以用于多个场合:SVG,Canvas 和 WebGL,旨在使平面形状和动画的创建更方便,更简洁 ...