kafka副本机制之数据可靠性
一、概述
为了提升集群的HA,Kafka从0.8版本开始引入了副本(Replica)机制,增加副本机制后,每个副本可以有多个副本,针对每个分区,都会从副本集(Assigned Replica,AR)中,选取一个副本作为Leader副本,所有读写请求都由Leader副本处理,其余的副本被称为Follwer副本,其会从Leader副本拉取消息更新到本地。因此,Follower更像是Leader的热备。
一般情况下,同一个分区的多个副本会被均匀的分配到集群中的不同Broker上,当leader副本所在机器出现故障后会重新选举出新的leader实现故障转移。(针对副本如何分配以避免单台机器上leader过多导致集群负载均衡不均及多副本在同一机器上等问题,不再本文的讨论范围内,感兴趣的小伙伴,可以参考下kafka-reassign-partitions脚本)。
二、关键术语
- 副本:kafka对消息的冗余存储以提升容灾能力,以分区为单位。
- Leader副本:每个分区都有多个副本,针对每个分区,都有一个唯一的一个Leader副本,负责该分区的读写请求处理。
- Follower副本:从Leader副本拉取数据,作为Leader副本的热备。
- AR:(Assigned Replica)副本集合(Leader+Follower的总和)
- ISR:(In-Sync Replica)同步副本集合,与leader副本消息镜像“相差”不多的副本集合,又称为“核心副本集”,与kafka 发送端的ACK的几种语义有关,后面会详聊(注意这个集合是动态的,是会剔除和新增的)。
- HW:(High Watermark)是一个特殊的标记,与ISR有关,用以标记该分区中哪些消息被“commit”了,自然的对于消费者来说,它只能看到被commit了的消息,也就是HW之前的消息,当ISR集合中的副本都从Leader拉取了HW之后的某些消息后,Leader才会递增HW,因此HW的概念仅存在与Leader副本中,Follower不存在这个概念。
- 有的小伙伴可能会问了,那为何要有这个标记呢,这个标记是为了从语义的角度保证即使Leader副本所在的机器宕机了,也不会出现消息丢失,后面会详细介绍。
- LEO:(Log End Offset)每个分区都会有的一个标记,标示当前分区的最后一条消息(针对Leader就是Leader上的最后一条消息,针对某个Follower,就是当前该Follower的最后一条消息)
三、图解AR、ISR、HW、LEO
这里我们假设每个副本有三个分区,副本被剔除和加入ISR的临界条件为落后leader 三条消息,kafka判断是否符合ISR的条件有两个:
- Follower落后leader多少条消息,落后超过配置值后将踢出ISR
- Follwer多久没从leader同步消息,超过配置时间没拉取数据将从ISR踢出(kafka0.9后删除了该判断,a为唯一判断标准)。
下面我们用图来表达下上面的概念的关系:
- 时刻t1该分区的情况如下,此时ISR与AR一致(Leader,follower1,follower2),follower2 和 leader的消息一致,LEO都为4,follower1的LEO为2,因此leader的HW为2.

- .时刻t2 follower full gc.

- 时刻t3,leader接受producer发送来的2条消息5、6,此时发现Follower1已经落后了自己4条消息,将follower1踢出ISR集合
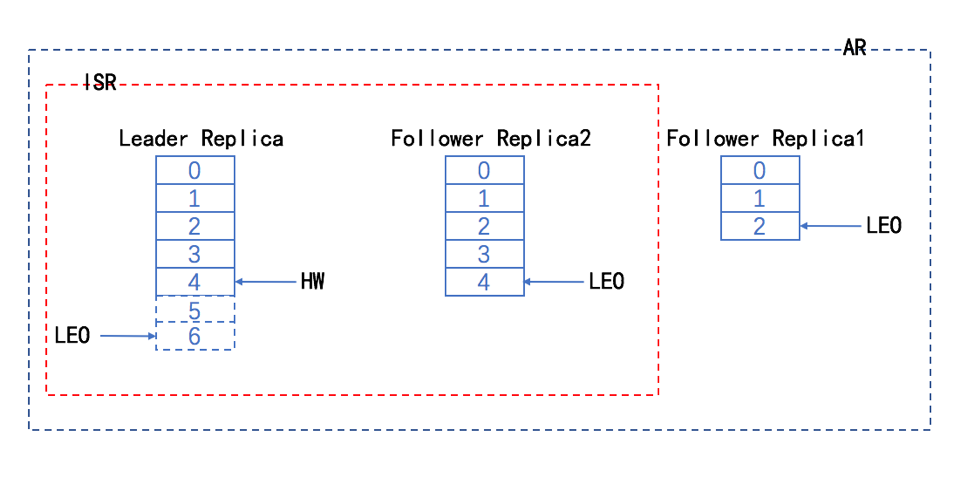
- 时刻t4,follower2 从leader拉取到5这条消息,更新HW值。
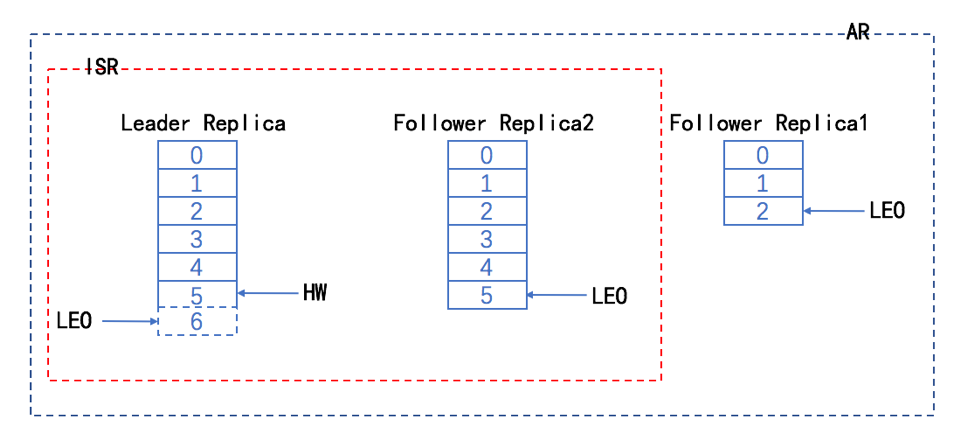
- 时刻t5,follower1 full gc完成后,发现自己已经落后了很多消息,开始从leader追消息,待消息不落后leader太多时,申请加入ISR中。

经过上面的图解分析后,我们来看下几个需要注意的点
- ISR是AR的一个自己,并且是不断伸缩的,变化的条件为“是否落后太多的消息”
- HW之前的消息代表被集群“commit”的消息,只有commit的消息才对client端(consumer以及request.required.acks为-1时的producer),在前面我们说过,这样能够使kafka在语义上支持不丢消息。我们从producer和consumer两个维度来分析:
在这之前,我们先说下request.required.acks的取值范围(1、0、-1)
1:leader成功就返回
0:无需等待leader响应
-1:ISR都成功才返回
- 从producer的角度:当producer将request.required.acks设置为-1时候,保证了消息已经在多个副本中存在了,此时即便leader挂了,这个消息还是存在的(leader选举会从ISR中选举出新的leader),那么假如ISR迟迟同步不成功怎么办呢?
- 从consumer的角度:如果没有HW,consumer拉取到最新的消息后,而此时leader宕机,很有可能新的leader中并没有此消息。
当然不能保证消息永远不会丢,极端的情况下,如ISR中只有leader的时候(当然可以配置集群可用的最小核心副本集个数,但会极大的损失可用性),或者所有副本都宕机了(这个。。。没办法。),消息还是会丢的。
kafka副本机制之数据可靠性的更多相关文章
- 深入理解 Kafka 副本机制
一.Kafka集群 二.副本机制 2.1 分区和副本 2.2 ISR机制 2.3 不完全的首领选举 2.4 最少同步副本 ...
- Kafka 学习之路(五)—— 深入理解Kafka副本机制
一.Kafka集群 Kafka使用Zookeeper来维护集群成员(brokers)的信息.每个broker都有一个唯一标识broker.id,用于标识自己在集群中的身份,可以在配置文件server. ...
- Kafka 系列(五)—— 深入理解 Kafka 副本机制
一.Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息.每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文 ...
- kafka 副本机制和容错处理 -2
文章来源于本人的印象笔记,如出现格式问题可访问该链接查看原文 原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 副本机制 Kafka的副本机 ...
- 深入了解Kafka【三】数据可靠性分析
1.多副本数据同步策略 为了保障Prosucer发送的消息能可靠的发送到指定的Topic,Topic的每个Partition收到消息后,要向Producer发送ACK,如果Produser收到ACK, ...
- Kafka 入门(二)--数据日志、副本机制和消费策略
一.Kafka 数据日志 1.主题 Topic Topic 是逻辑概念. 主题类似于分类,也可以理解为一个消息的集合.每一条发送到 Kafka 的消息都会带上一个主题信息,表明属于哪个主题. Kafk ...
- Kafka——副本(Replica)机制
副本定义 Kafka 是有主题概念的,而每个主题又进一步划分成若干个分区.副本的概念实际上是在分区层级下定义的,每个分区配置有若干个副本. 所谓副本(Replica),本质就是一个只能追加写消息的提交 ...
- 入门大数据---Kafka深入理解分区副本机制
一.Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息.每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文 ...
- kafka 日常使用和数据副本模型的理解
kafka 日常使用和数据副本模型的理解 在使用Kafka过程中,有时经常需要查看一些消费者的情况.Kafka健康状况.临时查看.同步一些数据,又由于Kafka只是用来做流式存储,又没有像Mysql或 ...
随机推荐
- 【JDK1.8】JDK1.8集合源码阅读——TreeMap(二)
一.前言 在前一篇博客中,我们对TreeMap的继承关系进行了分析,在这一篇里,我们将分析TreeMap的数据结构,深入理解它的排序能力是如何实现的.这一节要有一定的数据结构基础,在阅读下面的之前,推 ...
- Android自定义指示器时间轴
指示器时间轴在外卖.购物类的APP里会经常用到,效果大概就像下面这样,看了网上很多文章,大都是自己绘制,太麻烦,其实通过ListView就可以实现. 在Activity关联的布局文件activit ...
- Apache服务器配置
之前做代码一直按照传统化的方法部署别人的网站,但是一直不成功,尝试了很多次最后才发现时虚拟主机的问题 使用apache默认为127.0.0.1和网站的配置发生冲突. 因此在apache的conf文件夹 ...
- linux 常用命令详解
常见Linux目录名称:/ 虚拟目录的根目录.通常不会在这里存储文件/bin 二进制目录,存放许多用户级的GNU工具/boot 启动目录,存放启动文件/dev 设备目录,Linux在这里创建设备节点/ ...
- 企业级分布式监控系统-Zabbix基础
1.基础分部 1.1Zabbix简介 Zabbix 是一个企业级的分布式开源监控方案. 1.2监控系统架构 C/S架构 客户端/服务器端,这种架构适合规模较小,处于同一地域的环境 C/P/S 客户端/ ...
- Nginx 搭建rtmp直播服务器
1.到nginx源码目录新建个rtmp目录 ,进入 git clone https://github.com/arut/nginx-rtmp-module.git 2.重编译nginx 代码如下 ...
- google guava cache缓存基本使用讲解
代码地址:https://github.com/vikde/demo-guava-cache 一.简介 guava cache是google guava中的一个内存缓存模块,用于将数据缓存到JVM内存 ...
- 出现JSONvalue failed .error is Illegal start of token
出现JSONvalue failed .error is Illegal start of token了? 别着急,抽根烟,喝杯水.开工: 1:判断是请求前报的错还是请求后报的错!!这个很重要,我就是 ...
- Java 封装 HDFS API 操作
代码下载地址:点击下载 一:环境介绍 hadoop:2.6 Ubuntu:15.10 eclipse:3.8.1 二:操作包含 推断某个目录是否存在 isExist(fold ...
- 有关怎样入门ACM
想给大家看看 所以就弄了原创了,造成作者困扰请联系在下. 来源: 吴垠的日志 一些题外话 首先就是我为什么要写这么一篇日志.原因非常easy,就是由于前几天有个想起步做ACM人非常诚恳的问我该怎样 ...