LevelDB源码剖析
LevelDB的公共部件并不复杂,但为了更好的理解其各个核心模块的实现,此处挑几个关键的部件先行备忘。
Arena(内存领地)
Arena类用于内存管理,其存在的价值在于:
- 提高程序性能,减少Heap调用次数,由Arena统一分配后返回到应用层。
- 分配后无需执行dealloc,当Arena对象释放时,统一释放由其创建的所有内存。
- 便于内存统计,如Arena分配的整体内存大小等信息。
class Arena {
public:
Arena();
~Arena(); // Return a pointer to a newly allocated memory block of "bytes" bytes.
char* Allocate(size_t bytes); // Allocate memory with the normal alignment guarantees provided by malloc
char* AllocateAligned(size_t bytes); // Returns an estimate of the total memory usage of data allocated
// by the arena (including space allocated but not yet used for user
// allocations).
size_t MemoryUsage() const {
return blocks_memory_ + blocks_.capacity() * sizeof(char*);
} private:
char* AllocateFallback(size_t bytes);
char* AllocateNewBlock(size_t block_bytes); // Allocation state
char* alloc_ptr_; //当前block当前位置指针
size_t alloc_bytes_remaining_; //当前block可用内存大小 // Array of new[] allocated memory blocks
std::vector<char*> blocks_; //创建的全部内存块 // Bytes of memory in blocks allocated so far
size_t blocks_memory_; //目前为止分配的内存总量 // No copying allowed
Arena(const Arena&);
void operator=(const Arena&);
};Slice(数据块)
Slice的含义和其名称一致,代表了一个数据块,data_为数据地址,size_为数据长度。
Slice一般和Arena配合使用,其仅保持了数据信息,并未拥有数据的所有权。而数据在Arena对象的整个声明周期内有效。
Slice在LevelDB中一般用于传递Key、Value或编解码处理后的数据块。
和string相比,Slice具有的明显好处包括:避免不必要的拷贝动作、具有比string更丰富的语义(可包含任意内容)。
class Slice {
public:
......
private:
const char* data_;
size_t size_;
};LevelDB源码之一SkipList
SkipList称之为跳表,可实现Log(n)级别的插入、删除。跳表是平衡树的一种替代方案,和平衡树不同的是,跳表并不保证严格的“平衡性”,而是采用更为随性的方法:随机平衡算法。
关于SkipList的完整介绍请参见跳表(SkipList),这里借用几幅图做简要说明:

图1.1 跳表

图1.2 查找、插入

图1.3 查找、删除
- 图1.1中红色部分为初始化状态,即head各个level中next节点均为NULL。
- 跳表是分层的,由下往上分别为1、2、3...,因此需要分层算法。
- 跳表中每一层的数据都是按顺序存储的,因此需要Compactor。
- 查找动作由最上层开始依序查找,直到找到数据或查找失败。
- 插入动作仅影响插入位置前后节点,对其他节点无影响。
- 删除动作仅影响插入位置前后节点,对其他节点无影响。
分层算法
分层算法决定了数据插入的Level,SkipList的平衡性如何全权由分层算法决定。极端情况下,假设SkipList只有Level-0层,SkipList将弱化成自排序List。此时查找、插入、删除的时间复杂度均为O(n),而非O(Log(n))。
LevelDB中的分层算法实现如下(leveldb::skiplist::RandomHeight())
// enum { kMaxHeight = 12 };
template<typename Key, class Comparator>
int SkipList<Key, Comparator>::RandomHeight()
{
// Increase height with probability 1 in kBranching
static const unsigned int kBranching = ;
int height = ;
while (height < kMaxHeight && ((rnd_.Next() % kBranching) == )) {
height++;
}
assert(height > );
assert(height <= kMaxHeight);
return height;
}
代码1.1 RandomHeight
kMaxHeight 代表Skiplist的最大高度,即最多允许存在多少层,为关键参数,与性能直接相关。修改kMaxHeight ,在数值变小时,性能上有明显下降,但当数值增大时,甚至增大到10000时,和默认的kMaxHeight =12相比仍旧无明显差异,内存使用上也是如此。
为何如此?关键在于while循环中的判定条件:height < kMaxHeight && ((rnd_.Next() % kBranching) == 0)。除了kMaxHeight 判定外,(rnd_.Next() % kBranching) == 0)判定使得上层节点的数量约为下层的1/4。那么,当设定MaxHeight=12时,根节点为1时,约可均匀容纳Key的数量为4^11=4194304(约为400W)。因此,当单独增大MaxHeight时,并不会使得SkipList的层级提升。MaxHeight=12为经验值,在百万数据规模时,尤为适用。
Compactor
如同二叉树,Skiplist也是有序的,键值比较需由比较器(Compactor)完成。
SkipList对Compactor的要求只有一点:()操作符重载,格式如下:
//a<b返回值小于0,a>b返回值大于0,a==b返回值为0
int operator()(const Key& a, const Key& b) const;
Key与Compactor均为模板参数,因而Compactor亦由使用者实现。LevelDB中,存在一个Compactor抽象类,但该抽象类并没有重载()操作符,至于Compacotr如何使用及Compactor抽象类和此处的Compactor的关系如何请参见MemTable一节。
查找、插入、删除
LevelDB中实现的SkipList并无删除行为,这由其业务特性决定,故此处不提。
查找、插入亦即读、写行为。由图1.2可知,插入首先需完成一次查找动作,随后在指定位置上完成一次插入行为。
LevelDB中的查找、插入行为几乎做到了“无锁”并发,这一点是非常可取的。关于这一点,是本次备忘的重点。先来看查找:
template<typename Key, class Comparator>
typename SkipList<Key, Comparator>::Node*
SkipList<Key, Comparator>::FindGreaterOrEqual(const Key& key, Node** prev) const
{
Node* x = head_;
int level = GetMaxHeight() - ;
while (true) {
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) {
// Keep searching in this list
x = next;
}
else {
if (prev != NULL) prev[level] = x;
if (level == ) {
return next;
}
else {
// Switch to next list
level--;
}
}
}
}
代码1.2 FindGreaterOrEqual
实现并无特别之处:由最上层开始查找,一直查找到Level-0。找到大于等于指定Key值的数据,如不存在返回NULL。来看SkipList的Node结构:
template<typename Key, class Comparator>
struct SkipList<Key, Comparator>::Node {
explicit Node(const Key& k) : key(k) { } Key const key; // Accessors/mutators for links. Wrapped in methods so we can
// add the appropriate barriers as necessary.
Node* Next(int n) {
assert(n >= );
// Use an 'acquire load' so that we observe a fully initialized
// version of the returned Node.
return reinterpret_cast<Node*>(next_[n].Acquire_Load());
}
void SetNext(int n, Node* x) {
assert(n >= );
// Use a 'release store' so that anybody who reads through this
// pointer observes a fully initialized version of the inserted node.
next_[n].Release_Store(x);
} // No-barrier variants that can be safely used in a few locations.
Node* NoBarrier_Next(int n) {
assert(n >= );
return reinterpret_cast<Node*>(next_[n].NoBarrier_Load());
}
void NoBarrier_SetNext(int n, Node* x) {
assert(n >= );
next_[n].NoBarrier_Store(x);
} private:
// Array of length equal to the node height. next_[0] is lowest level link.
port::AtomicPointer next_[]; //看NewNode代码,实际大小为node height
};
代码1.3 Node
Node有两个成员变量,Key及next_数组。Key当然是节点数据,next_数组(注意其类型为AtomicPointer )则指向了其所在层及之下各个层中的下一个节点(参见图1.1)。Next_数组的实际大小和该节点的height一致,来看Node的工厂方法NewNode:
template<typename Key, class Comparator>
typename SkipList<Key, Comparator>::Node*
SkipList<Key, Comparator>::NewNode(const Key& key, int height)
{
char* mem = arena_->AllocateAligned( sizeof(Node) +
sizeof(port::AtomicPointer) * (height - ));
return new (mem) Node(key); //显示调用构造函数,并不常见。
}
代码1.4 NewNode
再来看Node的两组方法:SetNext/Next、NoBarrier_SetNext/NoBarrier_Next。这两组方法用于读写指定层的下一节点指针,前者并发安全、后者非并发安全。来看插入操作实现:
template<typename Key, class Comparator>
void SkipList<Key, Comparator>::Insert(const Key& key)
{
// TODO(opt): We can use a barrier-free variant of FindGreaterOrEqual()
// here since Insert() is externally synchronized.
Node* prev[kMaxHeight];
Node* x = FindGreaterOrEqual(key, prev); // Our data structure does not allow duplicate insertion
assert(x == NULL || !Equal(key, x->key)); int height = RandomHeight();
if (height > GetMaxHeight())
{
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
//fprintf(stderr, "Change height from %d to %d\n", max_height_, height); // It is ok to mutate max_height_ without any synchronization
// with concurrent readers. A concurrent reader that observes
// the new value of max_height_ will see either the old value of
// new level pointers from head_ (NULL), or a new value set in
// the loop below. In the former case the reader will
// immediately drop to the next level since NULL sorts after all
// keys. In the latter case the reader will use the new node.
max_height_.NoBarrier_Store(reinterpret_cast<void*>(height));
} x = NewNode(key, height);
for (int i = ; i < height; i++) {
// NoBarrier_SetNext() suffices since we will add a barrier when
// we publish a pointer to "x" in prev[i].
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}
代码1.5 Insert
插入行为主要修改两类数据:max_height_及所有level中前一节点的next指针。
max_height_没有任何并发保护,关于此处作者注释讲的很清楚:读线程在读到新的max_height_同时,对应的层级指针(new level pointer from head_)可能是原有的NULL,也有可能是部分更新的层级指针。如果是前者将直接跳到下一level继续查找,如果是后者,新插入的节点将被启用。
随后节点插入方是将无锁并发变为现实:
- 首先更新插入节点的next指针,此处无并发问题。
- 修改插入位置前一节点的next指针,此处采用SetNext处理并发。
- 由最下层向上插入可以保证当前层一旦插入后,其下层已更新完毕并可用。
当然,多个写之间的并发SkipList时非线程安全的,在LevelDB的MemTable中采用了另外的技巧来处理写并发问题。
LevelDB源码之二MemTable
MemTable是内存表,在LevelDB中最新插入的数据存储于内存表中,内存表大小为可配置项(默认为4M)。当MemTable中数据大小超限时,将创建新的内存表并将原有的内存表Compact(压缩)到SSTable(磁盘)中。
MemTable* mem_; //新的内存表
MemTable* imm_; //待压缩的内存表
MemTable内部使用了前面介绍的SkipList做为数据存储,其自身封装的主要目的如下:
- 以一种业务形态出现,即业务抽象。
- LevelDB是Key-Value存储系统,而SkipList为单值存储,需执行用户数据到SkipList数据的编解码处理。
- LevelDB支持插入、删除动作,而MemTable中删除动作将转换为一次类型为Deletion的添加动作。
业务形态
MemTable做为内存表可用于存储Key-Value形式的数据、根据Key值返回Value数据,同时需支持表遍历等功能。
class MemTable {
public:
......
// Returns an estimate of the number of bytes of data in use by this
// data structure.
//
// REQUIRES: external synchronization to prevent simultaneous
// operations on the same MemTable.
size_t ApproximateMemoryUsage(); //目前内存表大小
// Return an iterator that yields the contents of the memtable.
//
// The caller must ensure that the underlying MemTable remains live
// while the returned iterator is live. The keys returned by this
// iterator are internal keys encoded by AppendInternalKey in the
// db/format.{h,cc} module.
Iterator* NewIterator(); // 内存表迭代器
// Add an entry into memtable that maps key to value at the
// specified sequence number and with the specified type.
// Typically value will be empty if type==kTypeDeletion.
void Add(SequenceNumber seq, ValueType type, const Slice& key, const Slice& value);
// If memtable contains a value for key, store it in *value and return true.
// If memtable contains a deletion for key, store a NotFound() error
// in *status and return true.
// Else, return false.
//根据key值返回正确的数据
bool Get(const LookupKey& key, std::string* value, Status* s);
private:
~MemTable(); // Private since only Unref() should be used to delete it
......
};
这即所谓的业务形态:以一种全新的,SkipList不可见的形式出现,代表了LevelDB中的一个业务模块。
KV转储
LevelDB是键值存储系统,MemTable也被封装为KV形式的接口,而SkipList是单值存储结构,因此在插入、读取数据时需完成一次编解码工作。
如何编码?来看Add方法:
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key, const Slice& value)
{
// Format of an entry is concatenation of:
// key_size : varint32 of internal_key.size()
// key bytes : char[internal_key.size()]
// value_size : varint32 of value.size()
// value bytes : char[value.size()]
size_t key_size = key.size();
size_t val_size = value.size();
size_t internal_key_size = key_size + ;
//总长度
const size_t encoded_len =
VarintLength(internal_key_size) + internal_key_size +
VarintLength(val_size) + val_size;
char* buf = arena_.Allocate(encoded_len);
//Internal Key Size
char* p = EncodeVarint32(buf, internal_key_size);
//User Key
memcpy(p, key.data(), key_size);
p += key_size;
//Seq Number + Value Type
EncodeFixed64(p, (s << ) | type);
p += ;
//User Value Size
p = EncodeVarint32(p, val_size);
//User Value
memcpy(p, value.data(), val_size); assert((p + val_size) - buf == encoded_len); table_.Insert(buf);
}
参数传入的key、value是需要记录的键值对,本文称之为User Key,User Value。
而最终插入到SkipList的数据为buf,buf数据和User Key、User Value的转换关系如下:
|
Part 1 |
Part 2 |
Part 3 |
Part 4 |
Part 5 |
|
User Key Size + 8 |
User Key |
Seq Number << 8 | Value Type |
User Value Size |
User Value |
表1 User Key/User Value -> SkipList Data Item
如何解码?来看Get:
bool MemTable::Get(const LookupKey& key, std::string* value, Status* s)
{
Slice memkey = key.memtable_key(); Table::Iterator iter(&table_);
iter.Seek(memkey.data()); if (iter.Valid()) {
// entry format is:
// klength varint32
// userkey char[klength - 8]
// tag uint64
// vlength varint32
// value char[vlength]
// Check that it belongs to same user key. We do not check the
// sequence number since the Seek() call above should have skipped
// all entries with overly large sequence numbers.
const char* entry = iter.key();
uint32_t key_length;
const char* key_ptr = GetVarint32Ptr(entry, entry + , &key_length);
if (comparator_.comparator.user_comparator()->Compare(
Slice(key_ptr, key_length - ), key.user_key()) == )
{
// Correct user key
const uint64_t tag = DecodeFixed64(key_ptr + key_length - );
switch (static_cast<ValueType>(tag & 0xff)) {
case kTypeValue: {
Slice v = GetLengthPrefixedSlice(key_ptr + key_length);
value->assign(v.data(), v.size());
return true;
}
case kTypeDeletion:
*s = Status::NotFound(Slice());
return true;
}
}
}
return false;
}
根据memtable_key,通过Table::Iterator的Seek接口找到指定的数据,随后以编码的逆序提前User Value并返回。这里有一个新的概念叫memtable_key,即memtable_key中的键值,它实际上是由表1中的Part1-Part3组成。
更直观一些,我们顺着Table的typedef看过来:
typedef SkipList<const char*, KeyComparator> Table;
---->
struct KeyComparator
{
const InternalKeyComparator comparator;
explicit KeyComparator(const InternalKeyComparator& c) : comparator(c) { }
int operator()(const char* a, const char* b) const;
};
SkipList通过()操作符完成键值比较:
int MemTable::KeyComparator::operator()(const char* aptr, const char* bptr)const {
// Internal keys are encoded as length-prefixed strings.
Slice a = GetLengthPrefixedSlice(aptr);
Slice b = GetLengthPrefixedSlice(bptr);
return comparator.Compare(a, b); //InternalKeyComparator comparator
}
此处提前的a、b键值即SkipList中使用的key,为表1中part1-part3部分。真正的比较由InternalKeyComparator完成:
int InternalKeyComparator::Compare(const Slice& akey, const Slice& bkey) const
{
// Order by:
// increasing user key (according to user-supplied comparator)
// decreasing sequence number
// decreasing type (though sequence# should be enough to disambiguate)
int r = user_comparator_->Compare(ExtractUserKey(akey), ExtractUserKey(bkey));
if (r == ) {
const uint64_t anum = DecodeFixed64(akey.data() + akey.size() - );
const uint64_t bnum = DecodeFixed64(bkey.data() + bkey.size() - );
if (anum > bnum) {
r = -;
}
else if (anum < bnum) {
r = +;
}
}
return r;
}
核心的比较分为两部分:User Key比较、Seq Number及Value Type比较。
User Key比较由User Compactor完成,如果用户未指定比较器,系统将使用默认的按位比较器(BytewiseComparatorImpl)完成键值比较。
Seq Number即版本号,每一次数据更新将递增该序号。当用户希望查看指定版本号的数据时,希望查看的是指定版本或之前的数据,故此处采用降序比较。
Value Type分为kTypeDeletion、kTypeValue两种,实际上由于任意操作序号的唯一性,类型比较时非必须的。这里同时进行了类型比较也是出于性能的考虑(减少了从中分离序号、类型的工作)。
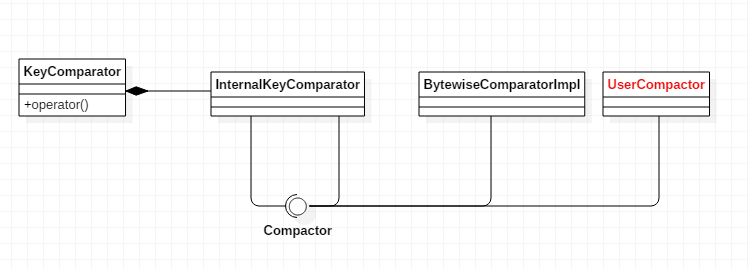
图2.1 Compactor
注:
- Add/Get接口对的接口参数形式不一致,属于不良接口封装。Add中采用Slice Key而Get中则使用了LookupKey Key做为键值,此处应统一。
- 在Add方法中,部分地方使用了变长数据EncodeVarint32、而部分又采用了定长数据EncodeFixed64。此处尚未摸清作者的使用规律,或者和极致的性能优化有关,又或者存在部分随性的因素在。
删除记录
客户端的删除动作将被转换为一次ValueType为Deletion的添加动作,Compact动作将执行真正的删除:
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key, const Slice& value)
--->
// Value types encoded as the last component of internal keys.
// DO NOT CHANGE THESE ENUM VALUES: they are embedded in the on-disk
// data structures.
enum ValueType {
kTypeDeletion = 0x0, //Deletion必须小于Value,查找时按顺序排列
kTypeValue = 0x1
};
Get时如查找到符合条件的数据为一条删除记录,查找失败:
bool MemTable::Get(const LookupKey& key, std::string* value, Status* s)
{
Slice memkey = key.memtable_key(); Table::Iterator iter(&table_);
iter.Seek(memkey.data()); if (iter.Valid()) {
const char* entry = iter.key();
uint32_t key_length;
const char* key_ptr = GetVarint32Ptr(entry, entry + , &key_length);
if (comparator_.comparator.user_comparator()->Compare(
Slice(key_ptr, key_length - ), key.user_key()) == )
{
// Correct user key
const uint64_t tag = DecodeFixed64(key_ptr + key_length - );
switch (static_cast<ValueType>(tag & 0xff)) {
case kTypeValue: {
Slice v = GetLengthPrefixedSlice(key_ptr + key_length);
value->assign(v.data(), v.size());
return true;
}
case kTypeDeletion:
*s = Status::NotFound(Slice());
return true;
}
}
}
return false;
}
LevelDB源码之三SSTable
上一节提到的MemTable是内存表,当内存表增长到一定程度时(memtable.size> Options::write_buffer_size),Compact动作会将当前的MemTable数据持久化,持久化的文件(sst文件)称之为SSTable。LevelDB中的SSTable分为不同的层级,这也是LevelDB称之为Level DB的原因,当前版本的最大层级为7(0-6),level-0的数据最新,level-6的数据最旧。除此之外,Compact动作会将多个SSTable合并成少量的几个SSTable,以剔除无效数据,保证数据访问效率并降低磁盘占用。
SSTable物理布局
在存储设备上,一个SSTable被划分为多个Block数据块。每个Block中存储的可能是用户数据、索引数据或任何其他数据。SSTable除Block外,每个Block尾部还带了额外信息,布局如下:
|
Block(数据块) |
Compression Type(是否压缩) |
CRC(数字签名) |
|
Block(数据块) |
Compression Type(是否压缩) |
CRC(数字签名) |
表 3.1 SSTable内部单元
Compression Type标识Block中的数据是否被压缩,采用了何种压缩算法,CRC则是Block的数字签名,用于校验数据的有效性。
Block是SSTable物理布局的关键。来看Block结构:

图3.1 Block的物理布局
Block由以下两部分组成:
l 数据记录:每一个Record代表了一条用户记录(Key-Value对)。严格上讲,并不是完整的用户记录,在Key上Block做了优化。
l 重启点信息:亦即索引信息,用于Record快速定位。如Restart[0]永远指向block的相对偏移0,Restart[1]指向重启点Record4的相对偏移。作者在Key存储上做了优化,每个重启点指向的第一条Record记录了完整的Key值,而本重启点之内的其他key仅包含和前一条的差异项。
让我们通过Block的构建过程了解上述结构:
void BlockBuilder::Add(const Slice& key, const Slice& value) {
Slice last_key_piece(last_key_);
assert(!finished_);
assert(counter_ <= options_->block_restart_interval);
assert(buffer_.empty() || options_->comparator->Compare(key, last_key_piece) > );
//1. 构建Restart Point
size_t shared = ;
if (counter_ < options_->block_restart_interval)//配置参数,默认为16
{ //尚未达到重启点间隔,沿用当前的重启点
// See how much sharing to do with previous string
const size_t min_length = std::min(last_key_piece.size(), key.size());
while ((shared < min_length) && (last_key_piece[shared] == key[shared]))
{
shared++;
}
}
else //触发并创建新的重启点
{
//此时,shared = 0; 重启点中将保存完整key
// Restart compression
restarts_.push_back(buffer_.size());//buffer_.size()为当前数据块偏移
counter_ = ;
}
const size_t non_shared = key.size() - shared;
//2. 记录数据
// shared size | no shared size | value size | no shared key data | value data
// Add "<shared><non_shared><value_size>" to buffer_
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
// Add string delta to buffer_ followed by value
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());
// Update state
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
assert(Slice(last_key_) == key);
counter_++;
}
代码3.1 BlockBuilder::Add
Buffer_代表当前数据块,restart_中则包含了重启点信息。当向block中新增一条记录时,首先设置重启点信息,包括:是否创建新的重启点,当前key和last key中公共部分大小。重启点信息整理完毕后,插入Record信息,Record信息的结构如下:
Record: shared size | no shared size | value size | no shared key data | value data
表3.2 Record结构
再来看Block构建完成时调用的Finish方法:
Slice BlockBuilder::Finish() {
// Append restart array
for (size_t i = ; i < restarts_.size(); i++) {
PutFixed32(&buffer_, restarts_[i]);
}
PutFixed32(&buffer_, restarts_.size());
finished_ = true;
return Slice(buffer_);
}
代码3.2 BlockBuilder::Finish
此处和图3.1一致,在所有Record之后记录重启点信息,包括每条重启点信息(block中相对偏移)及重启点数量。
重启点机制主要有两点好处:
- 索引信息:用于快速定位,读取时通过重启点的二分查找先获取查找数据所属的重启点,随后在重启点内部遍历,时间复杂度为Log(n)。
- 空间压缩:有序key值使得相邻记录的key值的重叠度极高,通过上述方式可以有效降低持久化设备占用。
至此,SSTable的物理布局已然清晰,由上到下依次为:表3.1->图3.1->表3.2。
SSTable逻辑布局
刚刚看过Block的结构,紧接着来看SSTable的逻辑布局,这次我们先从实现说起:
void TableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->num_entries > ) {
assert(r->options.comparator->Compare(key, Slice(r->last_key)) > );
}
//1. 构建Index
if (r->pending_index_entry) {
assert(r->data_block.empty());
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
//2. 记录数据
r->last_key.assign(key.data(), key.size());
r->num_entries++;
r->data_block.Add(key, value);
//3. 数据块大小已达上限,写入文件
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
if (estimated_block_size >= r->options.block_size) {
Flush();
}
}
代码3.3 TableBuilder::Add
这段代码和代码3.1类似,先构建索引,随后插入数据,此处额外增加了数据块处理逻辑:数据块大小达到了指定上限,写入文件。您可能已经注意到,Block中采用了重启点机制实现索引功能,在保证性能的同时又降低了磁盘占用。那么此处为何没有采用类似的机制呢?
实际上,此处索引键值的存储也做了优化,具体实现在FindShortestSeparator中,其目的在于获取最短的可以做为索引的“key”值。举例来说,“helloworld”和”hellozoomer”之间最短的key值可以是”hellox”。除此之外,另一个FindShortSuccessor方法则更极端,用于找到比指定key值大的最小key,如传入“helloworld”,返回的key值可能是“i”而已。作者专门为此抽象了两个接口,放置于Compactor中,可见其对编码也是是有“洁癖”的(*_*)。
// A Comparator object provides a total order across slices that are
// used as keys in an sstable or a database. A Comparator implementation
// must be thread-safe since leveldb may invoke its methods concurrently
// from multiple threads.
class Comparator {
public:
......
// Advanced functions: these are used to reduce the space requirements
// for internal data structures like index blocks. // If *start < limit, changes *start to a short string in [start,limit).
// Simple comparator implementations may return with *start unchanged,
// i.e., an implementation of this method that does nothing is correct.
virtual void FindShortestSeparator(std::string* start, const Slice& limit) const = ; // Changes *key to a short string >= *key.
// Simple comparator implementations may return with *key unchanged,
// i.e., an implementation of this method that does nothing is correct.
virtual void FindShortSuccessor(std::string* key) const = ;
};
代码3.4 索引键值优化接口
再来看Table构建完成时调用的Finish方法:
Status TableBuilder::Finish() {
//1. Data Block
Rep* r = rep_;
Flush();
assert(!r->closed);
r->closed = true;
//2. Meta Block
BlockHandle metaindex_block_handle;
BlockHandle index_block_handle;
if (ok())
{
BlockBuilder meta_index_block(&r->options);
// TODO(postrelease): Add stats and other meta blocks
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
//3. Index Block
if (ok()) {
if (r->pending_index_entry) {
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
WriteBlock(&r->index_block, &index_block_handle);
}
//4. Footer
if (ok())
{
Footer footer;
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
r->status = r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset += footer_encoding.size();
}
}
return r->status;
}
代码3.5 TableBuilder::Finish
通过Finish方法,我们可以一窥SSTable的全貌:

图3.2 SSTable逻辑布局
l Data Block:数据块,用户数据存放于此。
l Meta Block:元数据块,暂未使用,占位而已。
l Index Block:索引块,用于用户数据快速定位。
l Footer:见图3.3,“metaindex_handle指出了metaindex block的起始位置和大小;inex_handle指出了index Block的起始地址和大小;这两个字段可以理解为索引的索引,是为了正确读出索引值而设立的,后面跟着一个填充区和魔数。”(引自数据分析与处理之二(Leveldb 实现原理))。

图3.3 Footer
- 重启点机制问题:SSTable一旦创建后,将只存在查询行为,在键值查找或SSTable遍历时,必定从重启点开始查找,因此除重启点位置的Record为完整key外,其他均为差异项亦可快速定位。
- Table、Block一旦创建后无法修改,TableBuilder负责Table创建,BlockBuilder负责。Table、Block最重要的接口为Iterator* NewIterator(...) const,用于查找、遍历数据。LevelDB中的Iterator稍显复杂,后面会统一备忘。
- Table、Block各自采用了类似的索引机制,并形成了Table到Block的多级索引。重启点、Table的索引机制在保证性能的同时又降低了存储空间。
- 表3.1、图3.2中一直强调SSTable中存储的是Block,这种描述并不十分准确。表3.1中讲到,SSTable中存储了“Compression Type(是否压缩)”,如果数据被压缩,SSTable中存储的并不是Block数据本身,而是压缩后的数据,使用时则需先对Block解压。
Version、Current File、Manifest等暂未备忘,待后续补充。
LevelDB源码剖析的更多相关文章
- [Leveldb源码剖析疑问]-block_builder.cc之Add函数
Add函数是给一个Data block中添加对应的key和value,函数源码如下,其中有一处不理解: L30~L34是更新last_key_的,不理解这里干嘛不直接last_key_ = key.T ...
- jQuery之Deferred源码剖析
一.前言 大约在夏季,我们谈过ES6的Promise(详见here),其实在ES6前jQuery早就有了Promise,也就是我们所知道的Deferred对象,宗旨当然也和ES6的Promise一样, ...
- Nodejs事件引擎libuv源码剖析之:高效线程池(threadpool)的实现
声明:本文为原创博文,转载请注明出处. Nodejs编程是全异步的,这就意味着我们不必每次都阻塞等待该次操作的结果,而事件完成(就绪)时会主动回调通知我们.在网络编程中,一般都是基于Reactor线程 ...
- Apache Spark源码剖析
Apache Spark源码剖析(全面系统介绍Spark源码,提供分析源码的实用技巧和合理的阅读顺序,充分了解Spark的设计思想和运行机理) 许鹏 著 ISBN 978-7-121-25420- ...
- 基于mybatis-generator-core 1.3.5项目的修订版以及源码剖析
项目简单说明 mybatis-generator,是根据数据库表.字段反向生成实体类等代码文件.我在国庆时候,没事剖析了mybatis-generator-core源码,写了相当详细的中文注释,可以去 ...
- STL"源码"剖析-重点知识总结
STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点略多 :) 1.STL概述 STL提供六大组件,彼此可以组合 ...
- SpringMVC源码剖析(四)- DispatcherServlet请求转发的实现
SpringMVC完成初始化流程之后,就进入Servlet标准生命周期的第二个阶段,即“service”阶段.在“service”阶段中,每一次Http请求到来,容器都会启动一个请求线程,通过serv ...
- 自己实现多线程的socket,socketserver源码剖析
1,IO多路复用 三种多路复用的机制:select.poll.epoll 用的多的两个:select和epoll 简单的说就是:1,select和poll所有平台都支持,epoll只有linux支持2 ...
- Java多线程9:ThreadLocal源码剖析
ThreadLocal源码剖析 ThreadLocal其实比较简单,因为类里就三个public方法:set(T value).get().remove().先剖析源码清楚地知道ThreadLocal是 ...
随机推荐
- wait(0)
public final synchronized void join(long millis) throws InterruptedException { long base = System.cu ...
- Innosetup中将bat文件压缩到压缩包中
有时候在安装的过程中需要调用某些文件(bat或者exe等文件),但是只需要使用一次,然后就可以删掉该文件, 在Innosetup中应该这样操作: 1.在.iss脚本的[Files]章节写下: So ...
- CentOS 6.5 安装 Nginx 1.7.8 教程
http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=29791971&id=4702007 Nginx是一款轻量级的Web ...
- iOS 中关闭键盘方法
在 iOS 程序中当想要在文本框中输入数据,轻触文本框会打开键盘.对于 iPad 程序,其键盘有一个按钮可以用来关闭键盘,但是 iPhone 程序中的键盘却没有这样的按钮,不过我们可以采取一些方法关闭 ...
- 用android:clipChildren来实现红心变大特效
最近在看别人技术博客(http://www.cnblogs.com/over140/p/3508335.html)的时候,发现一个属性:android:clipChildren属性. 翻文档找到下面介 ...
- Redis应用
一.什么是Redis? Redis是一个高性能的key-value内存数据库. 二.为什么使用Redis? Redis是NoSQL数据库,相比传统关系型数据库,内存数据库读写更快. 三.Redis怎么 ...
- Windows 2008 IIS7.0安装FTP教程 IIS7.5 配置多用户FTP
一. 安装IIS.右键[我的电脑],选择[管理]打开. 选择[角色],选择[添加角色]打开. 二. 配置DOS.输入: CACLS "%Syste ...
- Unity3D 新人学习的一点感想
想到那里写到那里吧 1.Unity3D的优点大家都知道:组件化.c#语言.可见即所得. 当初刚开始学习的是cocos2dx,c++的货,觉得还是写的不错的,也是国人开发的,真的代码很容易懂,直接看引擎 ...
- [转]Markdown 语法手册
Markdown 是一种轻量级标记语言,能将文本换成有效的XHTML(或者HTML)文档,它的目标是实现易读易写,成为一种适用于网络的书写语言. Markdown 语法简洁明了,易于掌握,所以用它来写 ...
- Select的深入应用(1)
在子句中使用列的位置: 使用select语句创建新表: 在子句中使用列的别名: 注意,你的 ANSI SQL 不允许你在一个WHERE子句中引用一个别名.这是因为在WHERE代码被执行时,列值还可能没 ...