SQL 使用小记
0、SQL基础Note
wehre:行过滤
group by:分组
having:分组过滤
exists:相关子查询
where和having:针对行过滤 与 针对分组结果过滤的区别
where子查询和exists子查询:where包含子查询时先查得where后的子查询的结果再根据结果进行where前的主查询;exists先执行exists前的主查询得到结果再对每个结果进行子查询,可见后者在数据量大时会很耗时,慎用。
视图:视图通常用于查询而很少用于更新,并非所有的视图都可以进行更新操作,如视图中存在分组(group by)、联结、子查询、并(unoin)、聚合函数(sum/count等)、计算字段、DISTINCT等都不能对视图进行更新操作。
索引:单列索引、复合索引、唯一索引、主键索引 聚簇索引 等。
索引的设计:
where子句中的列可能最适合做为索引
不要尝试为性别或者有无这类字段等建立索引(因为类似性别的列,一般只含有“0”和“1”,无论搜索结果如何都会大约得出一半的数据)
如果创建复合索引,要遵守最左前缀法则。即查询从索引的最左前列开始,并且不跳过索引中的列
不要过度使用索引。每一次的更新,删除,插入都会维护该表的索引,更多的索引意味着占用更多的空间
使用InnoDB存储引擎时,记录(行)默认会按照一定的顺序存储,如果已定义主键,则按照主键顺序存储,由于普通索引都会保存主键的键值,因此主键应尽可能的选择较短的数据类型,以便节省存储空间
不要尝试在索引列上使用函数。
聚簇索引(clustered index)和非聚簇索引(nonclustered index):
区别:聚簇索引中index key和data一起存储在叶节点,因此索引项顺序和数据顺序一样;非聚簇索引中数据不在叶节点而是单独存储,叶节点存储index key和指向数据的指针,故两者顺序不一样。可见,聚簇索引和非聚簇索引分别相当于数据的一级索引和二级索引。
一张表最多只能有一个聚簇索引,因数据顺序只会有一种。
例子:按拼音查字典和按部首查字典分别是聚簇索引和非聚簇索引,前者拼音列表的顺序与字的组织顺序一样,后者部首的顺序与字的顺序不一样。
使用场景:由于聚簇索引索引项与数据的顺序一致,因此索引项改时要相应地调整数据位置,因此聚簇索引适合的场景有 更新少、范围查询多、数据有序(如自增id)、不同值不是很多等。如果数据无序,则插入新数据时索引项可能插入到中间从而导致需要移动已存储的数据保持一致顺序。
MySQL InnoDB存储引擎默认对主键用聚簇索引。
字符串类型字段不适合用聚簇索引,因为字符串值随机,插入后通常需要调整已由数据的位置。
使用场景的区别:
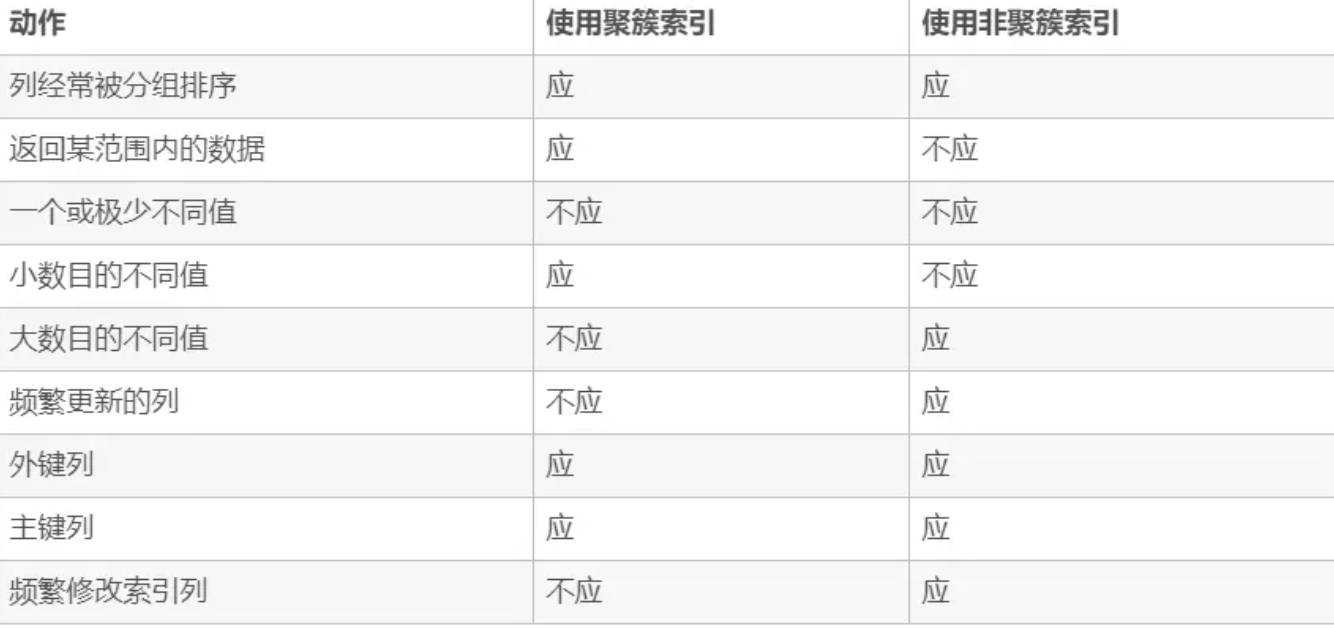
MySQL中若使用了聚簇索引,则普通列的索引项的value为primary key;若未使用聚簇索引,则上述value为指向数据的地址,因此存在聚簇索引时对于普通列查询比不存在聚簇索引时需要更多IO。示例图如下:
(1)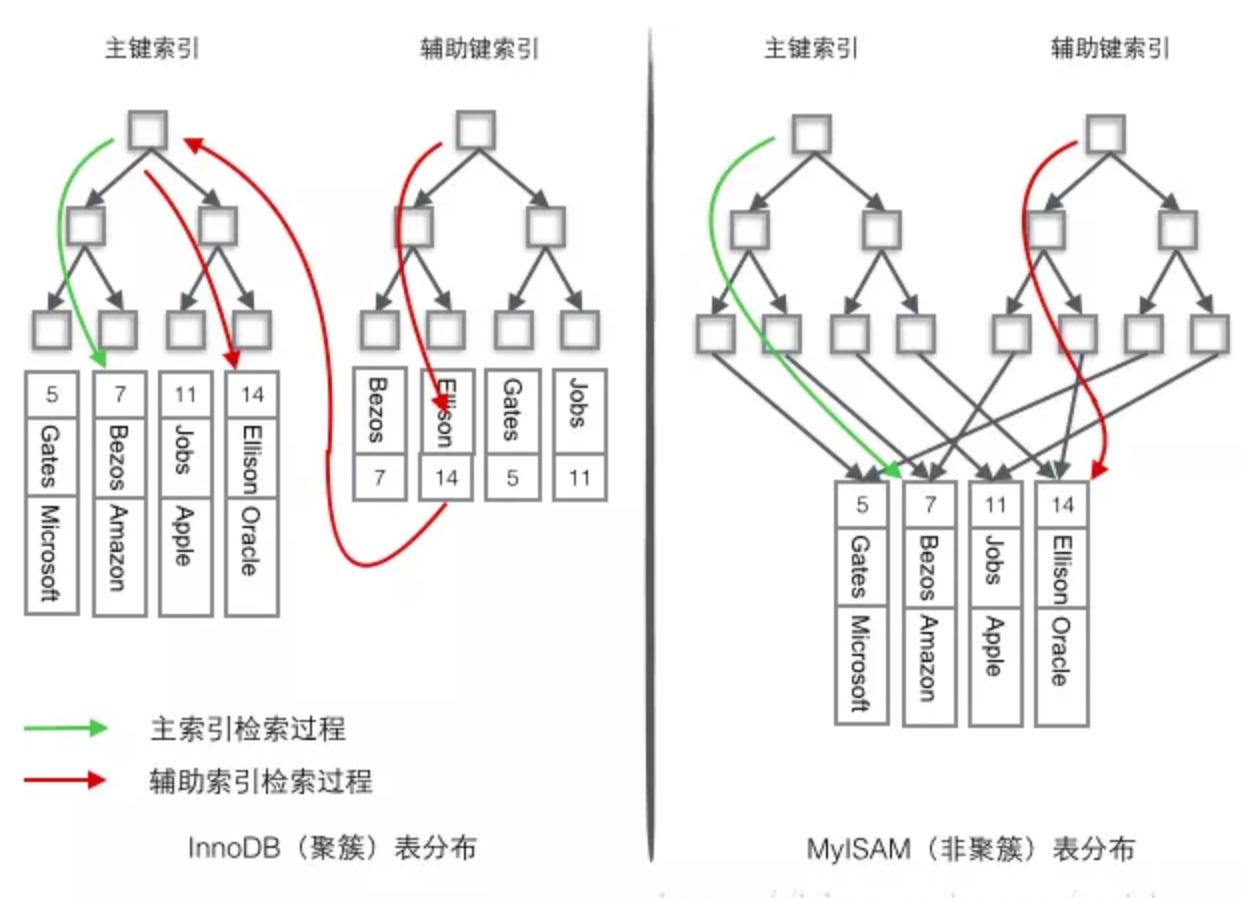 、(2)
、(2)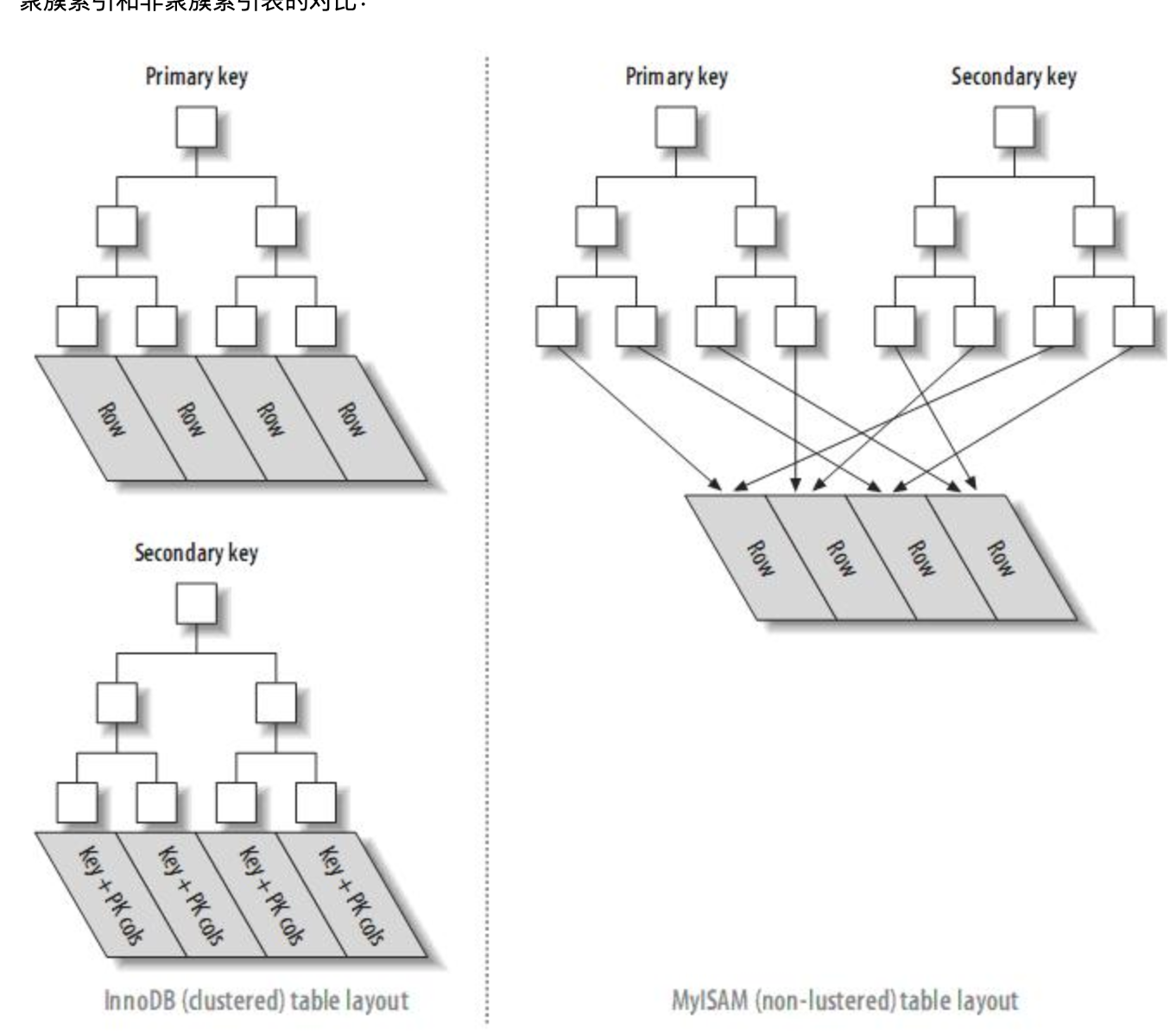
更多可参阅:https://www.cnblogs.com/z-sm/p/6005901.html
为什么索引字段要尽可能小(如用int比字符串好)?原因:
数据量固定时要使树高尽可能小 -> 每个节点中的索引项应尽可能多 ;而数据库中索引树(如B+树)节点占用空间大小(是OS页大小)是固定的,此时要使得索引项尽可能多,索引项的大小应该尽可能小。
另外,小的索引字段在磁盘、内存、CPU中占用空间更小,更容易处理
子查询与join查询:一般来说前者效率通常比后者低。
假设 用户订单表user_order有10w条数据,商品表goods有1000条数据,其间通过商品id关联,且g.type=1的goods有100条数据。前者子查询后需要100个子查询数据每个用户10w数据集进行查询、后者则不需要。
select uo.* from user_order uo where uo.gid in ( select g.id from goods g where g.type=1 ); select uo.* from user_order uo inner join goods g on uo.gid=g.id and g.type=1;
逗号分隔多表的多表查询其实就是inner join查询:from a, b where a.id=b.aid 与 from a inner join b on a.id=b.aid 等价
count(1)、count(*):不会忽略值为null的字段
count(列名):会忽略值为null的字段
20190825
联合主键(Composite Primary Key)的使用场景有两个:
- 从属关系的子表。如一个Experiment有多个ExperimentStep,则ExperimentStep中可以用experimentId、stepNum作为联合主键;
- 多对多关系的关联表:如Student、Course间的关系是多对多的,则其关联表Student_Course可以用studentId、courseId作为联合主键。
实际经验总结:如果业务中要求有软删除,则上述两种场景都不能设置联合主键不然可能会报主键冲突。相反,应该都额外加个id字段作为主键,并去掉联合主键。
修改表的字符集:
alter table course_export convert to character set utf8mb4 collate utf8mb4_unicode_ci;
1、 针对返回结果的case语句
示例
select
id,
name,
case user_role
when 0 then
"管理员"
when 1 then
"未注册用户"
when 2 then
"注册用户"
else
concat("未知值:", user_role)
end
“角色”
from
user
2、动态添加where条件
SELECT id, name, school_number AS schoolNumber, gender, grade FROM student where (?4 is NULL or name like %?4% or school_number like %?4%) and (?5 is NULL or gender= ?5) and (?6 is NULL or grade like %?6%)
该句应用背景为支持用户搜索返回模糊匹配结果,特点在于用户可以动态选择搜索条件的个数,?4、?5、?6 三个参数用户传不传均可。即不用因为用户传送参数个数的不同进行写多条SQL语句或在业务层面进行if判断,而只用一条SQL。
也可以使用if语句,示例:
update course c set c.is_enable= if (c.license_expire_time > now() , true, false), c.disable_time= if (c.is_enable =true, null, now());
3、SQL事件
可以让事件只发生一次或多次或周期性发生。
详见:https://www.yiibai.com/mysql/working-mysql-scheduled-event.html
示例:
-- '以下为course表中is_enable, disable_time自动更新的事件';
SET GLOBAL event_scheduler = ON;
drop event if exists `autoDisableCourse`;
create event `autoDisableCourse`
on schedule every 1 minute
DO
update course c set c.is_enable= if (c.license_expire_time > now() , true, false), c.disable_time= if (c.is_enable =true, null, now());
4、SQL触发器
示例:
-- '以下为course表中exp_num字段自动更新有关的两个触发器'; drop trigger if exists `updateExpNumInCourseTableAfterInsertExp` ;
DELIMITER ;;
CREATE trigger `updateExpNumInCourseTableAfterInsertExp`
after insert
on experiment for each row
begin
-- '插入一个实验时更新课程表中的实验数字段';
update course c set c.exp_num =(select count(e.id) from experiment e where e.course_id=NEW.course_id) where c.id = NEW.course_id;
end ;;
DELIMITER ; drop trigger if exists `updateExpNumInCourseTableAfterDeleteExp` ;
DELIMITER ;;
CREATE trigger `updateExpNumInCourseTableAfterDeleteExp`
after delete
on experiment for each row
begin
-- '删除一个实验时更新课程表中的实验数字段';
update course c set c.exp_num =(select count(e.id) from experiment e where e.course_id=OLD.course_id) where c.id = OLD.course_id;
end ;;
DELIMITER ;
5、关联表组织和命名
一对一、一对多关系通过外键来关联表,外键存储在主动关联的表即reference table(而非被管理表即referenced table)中;命名采用user、user_role
多对多关系通过主键来关联表,将reference table和referenced table的主键单独存在第三张表中来维护关联关系;命名采用user、region、user_region
可以看到,两者都会有下划线,此时不好快速区分到底 带下划线的表是 一张详细表(如user_role)还是一张 用来表示两张表关联关系的表(如user_region)。解决方法:一种是前者去掉 "user_" 前缀;另一种是后者统一加上 可区分的前缀如 "re_user_region" 。
7、字符串当做数字比较
如对于chapter="2"、"12",在sql中order by chapter asc得到的结果是字典序升序排序结果 "12"、"2"。若想使之与被当成数字时的升序排序结果一样,可以用语句order by chapter+0,得到的是"12"、"2"。
在native sql和JPQL中都可用此法。
可参阅:https://stackoverflow.com/questions/16242769/mysql-order-by-0-then-largest
8、查询时返回字段值的初始化
通过sql的 ifnull 函数,示例: select ifnull(t.courseNum, 0) as courseNun from course;
更好的方法是使用 COALESCE 函数,COALESCE(expression_1, expression_2, ...,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。
SQL 使用小记的更多相关文章
- WINDOWS Server2008上部署Oracle10g及oracle SQL语法小记
首先安装10G客户端 情况一:一般都会安装到一般报错.因为10G是32BIT客户端.而操作系统是64位的.但是不会影响配置监听程序.自主开发的应用程序依然可以运行. 情况二:报错但是配置完监听程序始终 ...
- sql server 小记——分区表(上)
我们知道很多事情都存在一个分治的思想,同样的道理我们也可以用到数据表上,当一个表很大很大的时候,我们就会想到将表拆 分成很多小表,查询的时候就到各个小表去查,最后进行汇总返回给调用方来加速我们的查询速 ...
- sql server 小记——分区表
我们知道很多事情都存在一个分治的思想,同样的道理我们也可以用到数据表上,当一个表很大很大的时候,我们就会想到将表拆 分成很多小表,查询的时候就到各个小表去查,最后进行汇总返回给调用方来加速我们的查询速 ...
- MS SQL 维护小记
--查看当前连接的会话信息(进程号1--50是SQL Server系统内部用的) SELECT * FROM sys.dm_exec_sessions WHERE session_id >=51 ...
- Impala SQL 使用小记
1. impala端创建的表,DROP. hive会自动同步到. 但是通过hive DROP时,数据还会在,只是表的元数据没有了. 所以完全DROP表,需要impala端的DROP 2. impal ...
- SQL函数小记
写一篇笔记,记录一下常见的sql函数,以备之后的查找需要. 算数函数 abs(num):绝对值函数 mod(被除数,除数):求余函数 round(num,保留小数的位数):四舍五入函数 字符串函数 c ...
- sql知识小记
1.在sql语句中,单引号嵌套时,使用单引号做转义
- 简单SQL注入试探、二
DVWA——简单SQL注入小记 今天我们来记录简单的盲注过程 简单的SQL injection(blind) Level:low 登陆后选择SQL Injection(Blind) 能看到这样的界面 ...
- 简单SQL注入试探、一
DVWA——简单SQL注入小记 前不久刚开始接触SQL注入,今天来记录一些最近的一些收获和一些SQL注入方面的知识. 主要是基于DVWA这个开源的平台来进行练习. 废话不多说开始解题. 从简单的SQL ...
随机推荐
- 怎样设置Word下次打开时跳转到上次阅读的位置
①我们启动Word2013,打开需要阅读的文档,当阅读完毕之后,在指定位置键入一个空格,然后按下Delete键删除,这样相当于是没有作任何更改. ②保存文档,单击文件--另存为,选择好路径,将文档保存 ...
- js函数声明
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- [转]Java_List元素的遍历和删除
原文地址:http://blog.csdn.net/insistgogo/article/details/19619645 1.创建一个ArrayList List<Integer> li ...
- iOS开发小技巧--实现毛玻璃效果的方法
一.美工出图 二.第三方框架 -- DRNRealTimeBlur,框架继承自UIView.使用方法:创建UIView直接继承自框架的View,就有了毛玻璃效果 三.CoreImage -- 图片加高 ...
- java eclipse打jar包和执行jar中的main函数
jar包使用eclipse打包步骤 右键需要打包的项目->选择Export 到这里有两种打包的方式 1.如果项目中没有使用其他第三方包等,则直接选择下图中的第一种即可(JAR file) 2.如 ...
- 【POJ 1182】食物链(并查集)
三种动物,A吃B,B吃C,C吃A.那么用并查集时,还要多一个x和根的关系,吃或者被吃或者同类.合并两个需要更新和祖先的关系.这个关系可以自己画一画. #include<cstdio> #d ...
- c# base64 编码解码
一. Base64的编码规则 Base64编码的思想是是采用64个基本的ASCII码字符对数据进行重新编 码.它将需要编码的数据拆分成字节数组.以3个字节为一组.按顺序排列24 位数据,再把这24位数 ...
- iOS9 支持http
在Info.plist中添加NSAppTransportSecurity类型Dictionary. 在NSAppTransportSecurity下添加NSAllowsArbitraryLoads类型 ...
- camerc文件播放
下载CamtasiaStudio 5中文版,打开CamtasiaStudio.exe在左边有生成选项,点左边工具框内添加/导入媒体,则选择下面的批量生成.弹出添加文件的菜单点添加文件,加入你要转换的c ...
- Linux 简介
转载:http://c.biancheng.net/cpp/html/2726.html Linux简介 严格的来讲,Linux 不算是一个操作系统,只是一个 Linux 系统中的内核,即计算机软件与 ...