基于Redis的BloomFilter算法去重
BloomFilter算法及其适用场景
BloomFilter是利用类似位图或者位集合数据结构来存储数据,利用位数组来简洁的表示一个集合,并且能够快速的判断一个元素是不是已经存在于这个集合。因为基于Hash来计算数据所在位置,所以BloomFilter的添加和查询操作都是O(1)的。因为存储简洁,这种数据结构能够利用较少的内存来存储海量的数据。那么,还有这种时间和空间两全其美的算法?当然不是,BloomFilter正是它的高效(使用Hash)带来了它的判断不一定是正确的,也就是说准确率不是100%。因为再好的Hash都是存在冲突的,这样的话同一个位置可能被多次置1。这样再判断的时候,有可能一个不存在的数据就会误判成存在。但是判断存在的数据一定是存在的。这里需要注意的是这里的Hash和HashMap不同,HashMap可以使用开放定址发、链地址法来解决冲突,因为HashMap是有Key-Value结构的,是可逆的,可以定位。但是Hash是不可逆的,所以不能够解决冲突。虽然BloomFilter不是100%准确,但是可以通过调节参数,使用Hash函数的个数,位数组的大小来降低失误率。这样调节完全可以把失误率降低到接近于0。可以满足大部分场景了。
关于BloomFilter的理论请参考:
http://blog.csdn.net/jiaomeng/article/details/1495500
https://en.wikipedia.org/wiki/Bloom_filter
适用场景:BloomFilter一般适用于大数据量的对精确度要求不是100%的去重场景。
爬虫链接的去重:大的爬虫系统有成千上万的链接需要去爬,而且需要保证爬虫链接不能循环。这样就需要链接列表的去重。把链接Hash后存放在BitSet中,然后在爬取之前判断是否存在。
网站UV统计:一般同一个用户的多次访问是要过滤掉的,一般大型网站的UV是巨大的,这样使用BloomFilter就能较高效的实现。
结合Redis
前面说的BloomFilter算法是单机的,可以使用JDK自带的BitSet来实现。但是拥有大数据量的系统绝不是一台服务器,所以需要多台服务器共享。结合Redis的BitMap就能够完美的实现这一需求。利用redis的高性能以及通过pipeline将多条bit操作命令批量提交,实现了多机BloomFilter的bit数据共享。唯一需要注意的是redis的bitmap只支持2^32大小,对应到内存也就是512MB,数组的下标最大只能是2^32-1。不过这个限制我们可以通过构建多个redis的bitmap通过hash取模的方式分散一下即可。万分之一的误判率,512MB可以放下2亿条数据。
实践
使用了Github上两个开源的实现测试了一下,是基于JDK BitSet实现的。
开源代码:https://github.com/MagnusS/Java-BloomFilter
https://github.com/Baqend/Orestes-Bloomfilter
测试结果(在本地测试,耗时是每条数据的耗时):
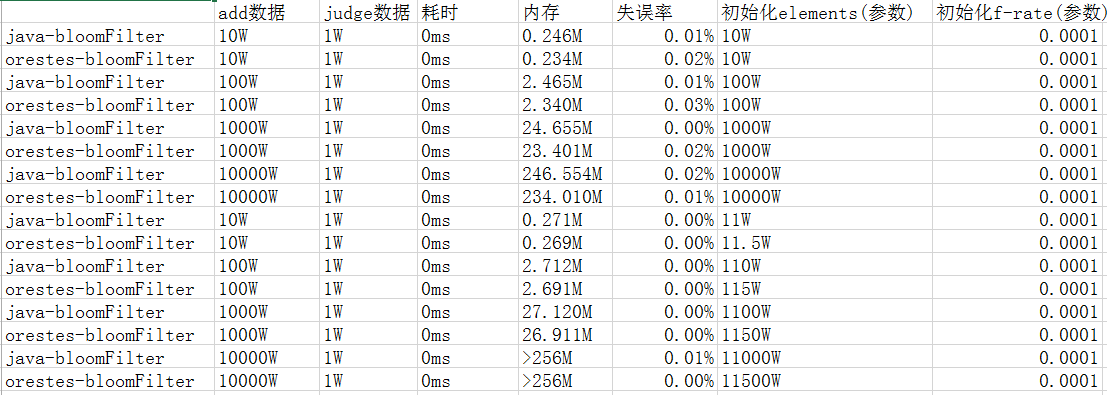
然后在java-bloomFilter的基础上修改了源代码,在有5个节点的Redis集群上做了一下测试。
测试结果:
初始化:173070
插入数据:173070
查询数据:173070
耗时:350261ns
内存:326KB
失误率:0.00%
可以看到结合Redis的BloomFilter算法的性能还是比较好的。
Redis+BloomFilter测试源代码:https://github.com/wxisme/redis-bloomFilter
基于Redis的BloomFilter算法去重的更多相关文章
- [转载]基于Redis的Bloomfilter去重(附Python代码)
前言: “去重”是日常工作中会经常用到的一项技能,在爬虫领域更是常用,并且规模一般都比较大.去重需要考虑两个点:去重的数据量.去重速度.为了保持较快的去重速度,一般选择在内存中进行去重. 数据量不大时 ...
- 基于Redis的Bloomfilter去重(转载)
转载:http://blog.csdn.net/bone_ace/article/details/53107018 前言 “去重”是日常工作中会经常用到的一项技能,在爬虫领域更是常用,并且规模一般都比 ...
- 基于Redis的分布式锁和Redlock算法
1 前言 前面写了4篇Redis底层实现和工程架构相关文章,感兴趣的读者可以回顾一下: Redis面试热点之底层实现篇-1 Redis面试热点之底层实现篇-2 Redis面试热点之工程架构篇-1 Re ...
- 身为一枚优秀的程序员必备的基于Redis的分布式锁和Redlock算法
1 前言 今天开始来和大家一起学习一下Redis实际应用篇,会写几个Redis的常见应用. 在我看来Redis最为典型的应用就是作为分布式缓存系统,其他的一些应用本质上并不是杀手锏功能,是基于Redi ...
- 基于redis分布式缓存实现
Redis的复制功能是完全建立在之前我们讨论过的基 于内存快照的持久化策略基础上的,也就是说无论你的持久化策略选择的是什么,只要用到了Redis的复制功能,就一定会有内存快照发生,那么首先要注意你 的 ...
- 基于redis实现可靠的分布式锁
什么是锁 今天要谈的是如何在分布式环境下实现一个全局锁,在开始之前先说说非分布式下的锁: 单机 – 单进程程序使用互斥锁mutex,解决多个线程之间的同步问题 单机 – 多进程程序使用信号量sem,解 ...
- 基于redis排行榜的实战总结
前言: 之前写过排行榜的设计和实现, 不同需求其背后的架构和设计模型也不一样. 平台差异, 有的立足于游戏平台, 为多个应用提供服务, 有的仅限于单个游戏.排名范围差异, 有的面向全局排名, 有的只做 ...
- 基于Redis的分布式锁真的安全吗?
说明: 我前段时间写了一篇用consul实现分布式锁,感觉理解的也不是很好,直到我看到了这2篇写分布式锁的讨论,真的是很佩服作者严谨的态度, 把这种分布式锁研究的这么透彻,作者这种技术态度真的值得我好 ...
- 基于redis的分布式锁(转)
基于redis的分布式锁 1 介绍 这篇博文讲介绍如何一步步构建一个基于Redis的分布式锁.会从最原始的版本开始,然后根据问题进行调整,最后完成一个较为合理的分布式锁. 本篇文章会将分布式锁的实现分 ...
随机推荐
- windows下clang的安装与使用
我本意是想在windows下学习下C++11,而结果是我的Visual Studio 2012不完全支持,而我又懒得去安装2013/2015,太大了.公司运维也不允许我去下载- -,然后就想能不能在w ...
- Nginx + FastCgi + Spawn-fcgi + c 的架构
参考: nginx+c/c++ fastcgi:http://www.yis.me/web/2011/11/01/66.htm cgi探索之路:http://github.tiankonguse.co ...
- C++ Data Member内存布局
如果一个类只定义了类名,没定义任何方法和字段,如class A{};那么class A的每个实例占用1个字节的内存,编译器会会在这个其实例中安插一个char,以保证每个A实例在内存中有唯一的地址,如A ...
- 关于ios中得路径详细讲解
利用create groups for any added folders 这样的方式表示的是将所有的资源都放在资源包得路径下,没有层次的概念利用create folder references fo ...
- webpack处理Img标签路径的几种情况
在使用webpack过程中遇到这个问题,各种搜索遇到此问题的还真不少,但都没有一个完整的说明. 后来研究下,图片除了路径替换还是就是图片做优化主是小于一定大小的通过转 base64 inline方式减 ...
- 用Java实现约瑟夫环
约瑟夫环是一个数学的应用问题:已知n个人(以编号1,2,3...n分别表示)围坐在一张圆桌周围.从编号为k的人开始报数,数到m的那个人出列;他的下一个人又从1开始报数,数到m的那个人又出列;依此规律重 ...
- WPF 定时写入文本
public static void Start() { ThreadStart start = new ThreadStart(ThreadAction); Thread th = new Thre ...
- C语言程序代写
MTRX1702 - C ProgrammingAssignment 1This assignment requires you to design and build a program to co ...
- Android杂谈--HTC等手机接收不到UDP广播报文的解决方案
最近遇到个问题,在android手机上发送UDP报文的时候,HTC等机型(测试用HTC new one)接收不到广播报文,而其他的samsung, huawei, xiaomi, nexus等等均没有 ...
- 教你在Excel里做GA的水平百分比图的详细步骤(图文教程)-成为excel大师(1)
GA报表除了默认的表格方式显示数据外,还支持饼图,水平百分比图,数据透视图等展现方式,其中水平百分比图在可视化看流量时最为方便,就像这样: 那么当我们要在Excel里做类似的效果应该怎么做呢?尤其是数 ...