Hadoop下面WordCount运行详解
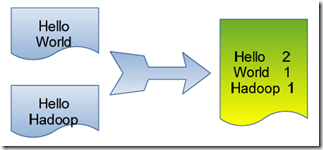
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版"Hello World",该程序的完整代码可以在Hadoop安装包的"src/examples"目录下找到。单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数,如下图所示。
现在我们以"hadoop"用户登录"Master.Hadoop"服务器。
1. 创建本地的示例数据文件:
依次进入【Home】-【hadoop】-【hadoop-1.2.1】创建一个文件夹file用来存储本地原始数据。
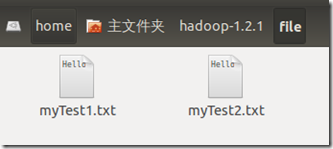
并在这个目录下创建2个文件分别命名为【myTest1.txt】和【myTest2.txt】或者你想要的任何文件名。
分别在这2个文件中输入下列示例语句:
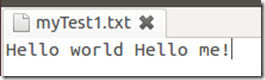

2. 在HDFS上创建输入文件夹
呼出终端,输入下面指令:
bin/hadoop fs -mkdir hdfsInput
执行这个命令时可能会提示类似安全的问题,如果提示了,请使用
bin/hadoop dfsadmin -safemode leave
来退出安全模式。
当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结 束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入 安全模式。
意思是在HDFS远程创建一个输入目录,我们以后的文件需要上载到这个目录里面才能执行。
3. 上传本地file中文件到集群的hdfsInput目录下
在终端依次输入下面指令:
cd hadoop-1.2.1
bin/hadoop fs -put file/myTest*.txt hdfsInput

4. 运行例子:
在终端输入下面指令:
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount hdfsInput hdfsOutput
注意,这里的示例程序是1.2.1版本的,可能每个机器有所不一致,那么请用*通配符代替版本号
bin/hadoop jar hadoop-examples-*.jar wordcount hdfsInput hdfsOutput
应该出现下面结果:
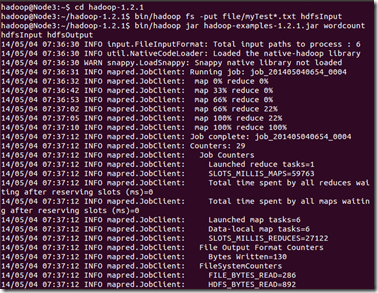
Hadoop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。以上就是Hadoop Job的运行记录,从这里可以看到,这个Job被赋予了一个ID号:job_201202292213_0002,而且得知输入文件有两个(Total input paths to process : 2),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输出记录。
查看HDFS上hdfsOutput目录内容:
在终端输入下面指令:
bin/hadoop fs -ls hdfsOutput

从上图中知道生成了三个文件,我们的结果在"part-r-00000"中。
使用下面指令查看结果输出文件内容
bin/hadoop fs -cat output/part-r-00000

(注意:请忽视截图指令中的3)
输出目录日志以及输入目录中的文件是永久存在的,如果不删除的话,如果出现结果不一致,请参考这个因素。
Hadoop下面WordCount运行详解的更多相关文章
- Hadoop集群WordCount运行详解(转)
原文链接:Hadoop集群(第6期)_WordCount运行详解 1.MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对 ...
- WordCount运行详解
1.MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然 ...
- [转]Hadoop集群_WordCount运行详解--MapReduce编程模型
Hadoop集群_WordCount运行详解--MapReduce编程模型 下面这篇文章写得非常好,有利于初学mapreduce的入门 http://www.nosqldb.cn/1369099810 ...
- hadoop应用开发技术详解
<大 数据技术丛书:Hadoop应用开发技术详解>共12章.第1-2章详细地介绍了Hadoop的生态系统.关键技术以及安装和配置:第3章是 MapReduce的使用入门,让读者了解整个开发 ...
- 《Hadoop应用开发技术详解》
<Hadoop应用开发技术详解> 基本信息 作者: 刘刚 丛书名: 大数据技术丛书 出版社:机械工业出版社 ISBN:9787111452447 上架时间:2014-1-10 出版日期:2 ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- Hadoop生态圈-Kafka配置文件详解
Hadoop生态圈-Kafka配置文件详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.默认kafka配置文件内容([yinzhengjie@s101 ~]$ more /s ...
- Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例)
Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编辑配置文件(pml.xml)(我 ...
- Java程序在内存中运行详解
目录 Java程序在内存中运行详解 一.JVM的内存分布 二.程序执行的过程 三.只有一个对象时的内存图 四.两个对象使用同一个方法的内存图 五.两个引用指向同一个对象的内存图 六.使用对象类型作为方 ...
随机推荐
- ThinkBox DOC
插件源码下载 @github https://github.com/Aoiujz/ThinkBox.git 插件使用方法 引入文件 //使用ThinkBox弹出框必须引入以上三个文件. //jQuer ...
- javascript提升复习
https://www.baidu.com/s?wd=JavaScript+%E9%A2%84%E8%A7%A3%E6%9E%90 http://www.cnblogs.com/HPNiuYear/a ...
- MySQL的慢查询分析
慢查询分析日最初是用来捕获比较“慢”的查询,在mysql5.1 + 版本中,慢查询的功能被加强,可以通过设置long_query_time为0来捕获所有的查询,而且查询的响应时间已经可以做到微妙级别. ...
- jQuery之Deferred对象详解
deferred对象是jQuery对Promises接口的实现.它是非同步操作的通用接口,可以被看作是一个等待完成的任务,开发者通过一些通过的接口对其进行设置.事实上,它扮演代理人(proxy)的角色 ...
- Nodejs开源项目推荐
当我们学习一门新语言,不要用以前语言的习惯去使用新的语言,这样可能会导致走一些弯路.最好的办法就是去看一些写的比较好的开源项目,所以这里我推荐几个NodeJs的开源项目,花点时间去研究一下他们的实现, ...
- LCLFramework框架之IOC
我们都知道,在采用面向对象方法设计的软件系统中,它的底层实现都是由N个对象组成的,所有的对象通过彼此的合作,最终实现系统的业务逻辑. 借助于"第三方"实现具有依赖关系的对象之间的解 ...
- 卖萌的极致!脸部捕捉软件FaceRig让你化身萌宠
FaceRig是一款以摄像头为跟踪设备捕捉用户脸部动作并转化为数据套用在其他动画模型上的一款软件,能够应用于一些日常的视频社交软件或网站,比如视频通话软件Skype和直播网站Twitch.FaceRi ...
- Linux64位服务器编译安装MySQL5.6(CentOS6.4)
首先到MySQL官网下载MySQL最新版(目前是mysql-5.6.12)上传到服务器上,下面说一下详细的安装过程. 安装依赖包,可以在线更新也可以配置本地源(CentOS本地源配置)yum -y i ...
- 同步与异步&阻塞与非阻塞
摘要 一直为同步异步,阻塞非阻塞概念所困扰,特定总结了下,原来是这么个意思 一直为同步异步,阻塞非阻塞概念所困扰,特定总结了下 一.同步与异步的区别 1.概念介绍 同步:所谓同步是一个服务的完成需要依 ...
- [转]一个小试验验证对象的指针计数置为nil的情况
本文转载于新风作浪的博客专栏,博客地址:http://blog.csdn.net/duxinfeng2010/article/details/8757211 以下博客原文: 最近遇到这样一个问题,以前 ...