java核心数据结构总结
JDK提供了一组主要的数据结构的实现,如List、Set、Map等常用结构,这些结构都继承自java.util.collection接口。
- List接口
List有三种不同的实现,ArrayList和Vector使用数组实现,其封装了对内部数组的操作。LinkedList使用了循环双向链表的数据结构,LinkedList链表是由一系列的链表项连接而成,一个链表项包括三部分:链表内容、前驱表项和后驱表项。
LinkedList的表项结构如图:
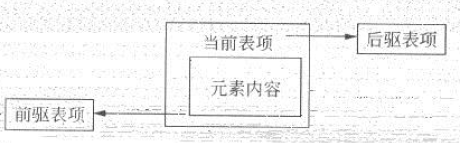
LinkedList表项间的连接关系如图:

可以看出,无论LinkedList是否为空,链表都有一个header表项,它即表示链表的开头也表示链表的结尾。表项header的后驱表项便是链表的第一个元素,其前驱表项就是链表的最后一个元素。
对基于链表和基于数组的两种List的不同实现做一些比较:
1、增加元素到列表的末尾:
在ArrayList中源代码如下:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
add()方法性能的好坏取决于grow()方法的性能:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
可以看出,当ArrayList对容量的需求超过当前数组的大小是,会进行数组扩容,扩容的过程中需要大量的数组复制,数组复制调用System.arraycopy()方法,操作效率是非常快的。
在LinkedList源码中add()方法:
public boolean add(E e) {
linkLast(e);
return true;
}
linkLast()方法如下:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
LinkedList是基于链表实现,因此不需要维护容量大小,但是每次都新增元素都要新建一个Node对象,并进行一系列赋值,在频繁系统调用中,对系统性能有一定影响。性能测试得出,在列表末尾增加元素,ArrayList比LinkedList性能要好,因为数组是连续的,在末尾增加元素,只有在空间不足时才会进行数组扩容,大部分情况下追加操作效率还是比较高的。
2、增加元素到列表的任意位置:
List接口还提供了在任意位置插入元素的方法:void add(int index,E element)方法,由于实现方式不同,ArrayList和LinkedList在这个方法上存在一定的差异。由于ArrayList是基于数组实现的,而数组是一块连续的内存,如果在数组的任意位置插入元素,必然会导致该位置之后的所有元素重新排序,其效率相对较低。
ArrayList源码实现:
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
可以看出每次插入都会进行数组复制,大量的数组复制操作导致系统性能效率低下。并且数组插入的位置越靠前,数组复制的开销就越大。因此,尽可能插入元素在其尾端附近,有助于提高该方法的性能。
LinkedList的源码实现:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
对于LinkedList的在尾端插入和对任意位置插入数据是一样的,并不会因为插入位置靠前而导致效率低下。因此,在应用中,如果经常往任意位置插入元素,可以考虑使用LinkedList提到ArrayList。
3、删除任意位置的元素:
List接口还提供了在任意位置删除元素的方法:remove(int index)方法。在ArrayList中,对于remove()方法和add()方法一样,在任意位置移除元素,都需要数组复制。
ArrayList的remove()方法的源码如下:
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
可以看出,在ArrayList的每一次删除操作,都需要进行数组重组,并且删除元素的位置越靠前,数组重组的开销就越大。
LinkedList的remove()方法的源码:
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
在LinkedList中首先通过循环找到要删除的元素,如果元素位于前半段则,从前往后找;若位置位于后半段,则从后往前找,但是要移除中间的元素,却几乎要遍历半个List。所有,无论元素位于较前还是较后,效率都比较高,但是位于中间效率就非常低。
4、容量参数:
容量参数是ArrayList和Vector等基于数组的List特有的性能参数,它表示初始化数组的大小。当数组所存储的元素的数量超过其原有的大小时,它就会进行扩容,即进行一次数组复制,因此,合理设置数组大小有助于减少扩容次数,从而提升系统性能。
5、遍历列表:
在JDK1.5之后,至少有三种遍历列表的方式:forEach操作,迭代器,for循环。通过测试发现,forEach综合性能不如迭代器,而for循环遍历列表时,ArrayList的性能表现最好,而LinkedList的性能差的无法忍受,因为LinkedList进行随机访问,总会进行一次列表的遍历操作。
对于ArrayList是基于数组来实现的,随机访问效率快,因此有限选择随机访问。而LinkedList是基于链表实现的,随机访问的性能差,应该避免使用。
- Map接口
围绕着Map接口,最主要的实现类有:HashMap、hashTable、LinkedHashMap和TreeMap。在HashMap的子类中还有Properties类的实现。
1、HashMap和Hashtable
首先说一下,HashMap和Hashtable的区别:Hashtable的大部分方法都实现了同步,而HashMap没有。因此,HashMap不是线程安全的。其次,Hashtable不允许key或value使用null值,而HashMap可以。第三是内部的算法不同,它们对key的hash算法和hash值到内存索引的映射算法不同。
HashMap就是将key做hash算法,然后将hash值映射到内存地址,直接取得key所对应的数据。在HashMap的底层使用的是数组,所谓的内存地址即数组的下标索引。
HashMap中不得不提的就是hash冲突,需要存放到HashMap中的元素1和元素2经过hash计算,发现对应的内存地址一样。如下图:
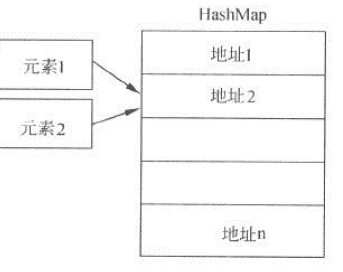
HashMap底层使用的是数组,但是数组内的元素不是简单的值,而是一个Entry对象。如下图所示:

可以看出,HashMap的内部维护了一个Entry数组,每个entry表项包括:key、value、next、hash。next部分表示指向另一个Entry。在HashMap的put()方法中,可以看到当put()方法有冲突时,新的entry依然会安放在对应的索引下标内,并替换掉原来的值,同时为了保证旧值不丢失,会将新的entry的next指向旧值。这样便实现了在一个数组索引空间内存放多个值。
HashMap的put()操作的源码:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;//取得旧值
e.value = value;
e.recordAccess(this);
return oldValue;//返回旧值
}
}
modCount++;
addEntry(hash, key, value, i);//添加当前表项到i位置
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);//将新增元素放到i位置,并把它的next指向旧值
size++;
}
基于HashMap的这种实现,只要对hashCode()和hash()的方法实现的够好,就能尽可能的减少冲突,那么对HashMap的操作就等价于对数组随机访问的操作,具有很好的性能。但是,如果处理不好,在产生大量冲突的情况下,HashMap就退化为几个链表,性能极差。
2、容量参数:
因为HashMap和Hashtable底层是基于数组实现的,当数组空间不足时,就会进行数组扩容,数组扩容就会进行数组复制,是十分影响性能的。
HashMap的构造函数:
public HashMap(int initialCapacity)
public HashMap(int initialCapacity, float loadFactor)
initialCapacity指定HashMap的初始容量,loadFactor是指负载因子(元素个数/元素总量),HashMap中还定义了一个阈值,它是当前数组容量和负载因子的乘积,当数组的实际容量超过阈值时,就会进行数组扩容。
另外,HashMap的性能一定程度上取决于hashCode()的实现,一个好的hashCode()的实现,可以尽可能减少冲突,提升hashMap的访问速度。
3、LinkedHashMap
HashMap的一大缺点就是无序性,放入的数据,在遍历取出时候是无序的。如果需要保证元素输入时的顺序,可以使用LinkedHashMap。
LinkedHashMap继承自HashMap,因此,其性能是比较好。在HashMap的基础上,LinkedHashMap内部又增加了一个链表,用于存放元素的顺序。LinkedHashMap提供了两种类型的顺序,一种是元素插入时的顺序,一种是最近访问的顺序。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder)
其中,accessOrder为true是,是按元素最后访问时间排序,当accessOrder为false时,按插入顺序排序。
4、TreeMap
TreeMap可以对元素进行排序,TreeMap是基于元素的固有顺序而排序的(有Comparable或Comparator确定)。
TreeMap是根据key进行排序的,为了确定key的排序算法,可以使用两种方法指定:
1:在TreeMap的构造函数中注入Comparator
TreeMap(Comparator<? super K> comparator);
2:使用一个实现了Comparable接口的key。
TreeMap是内部是基于红黑树实现,红黑树是一种平衡查找树,其统计性能优于平衡二叉树。
- Set接口
set集合中的元素是不能重复的,其中最主要的实现就是HashSet、LinkedHashSrt和TreeSet。查看Set接口实现类,可以发现所有的Set的一些实现都是相应Map的一种封装。
set特性如图所示:

- 集合操作的一些优化建议
1、分离循环中被重复调用的代码。如:for(int i=0;i<list.size();i++),可以将list.size()分离出来。
2、省略相同的操作
3、减少方法的调用,方法调用时消耗系统堆栈的,会牺牲系统的性能。
- RandomAccess接口
RandomAccess接口是一个标识接口,本身没有提供任何方法。主要的目的是为了标识出那些可以支持快速随机访问的List的实现。例如,根据是否实现RandomAccess接口在变量的时候选择不同的遍历实现,以提升性能。
java核心数据结构总结的更多相关文章
- 【转】Java学习---Java核心数据结构(List,Map,Set)使用技巧与优化
[原文]https://www.toutiao.com/i6594587397101453827/ Java核心数据结构(List,Map,Set)使用技巧与优化 JDK提供了一组主要的数据结构实现, ...
- Java核心数据结构(List,Map,Set)原理与使用技巧
JDK提供了一组主要的数据结构实现,如List.Map.Set等常用数据结构.这些数据都继承自 java.util.Collection 接口,并位于 java.util 包内. 1.List接口 最 ...
- Java核心数据结构(List、Map、Set)原理与使用技巧
JDK提供了一组主要的数据结构实现,如List.Set等常用数据结构.这些数据都继承自java.util.Collection接口,并位于java.util包内. 一.List接口 最重要的三种Lis ...
- java核心问题总结
Java 核心概念 equals 与 hashCode 的异同点在哪里?Java 的集合中又是如何使用它们的. Math.Integer.Double等这些封装类在使用equals()方法时,已经覆盖 ...
- 金三银四面试季节之Java 核心面试技术点 - JVM 小结
原文:https://github.com/linsheng9731/notebook/blob/master/java/JVM.md 描述一下 JVM 的内存区域 程序计数器(PC,Program ...
- 2018.6.19 Java核心API与高级编程实践复习总结
Java 核心编程API与高级编程实践 第一章 异常 1.1 异常概述 在程序运行中,经常会出现一些意外情况,这些意外会导致程序出错或者崩溃而影响程序的正常执行,在java语言中,将这些程序意外称为异 ...
- 阿里架构师花近十年时间整理出来的Java核心知识pdf(Java岗)
由于细节内容实在太多啦,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容! 整理了一份Java核心知识点.覆盖了JVM.锁.并发.Java反射.Spring原理.微服务.Zooke ...
- 【惊喜】Github爆火的java面试神技+java核心面试技术已开发下载,大厂内都传疯了!
前言 今年,由于疫情的影响,很多互联网企业都在缩减招聘成本.作为程序员,原本这两年就面临竞争激烈.年龄危机的问题,而现在的求职局面又完全是企业在挑人的状态. 所以最好能在空闲的时候看看大厂相匹配的技术 ...
- 深入Java核心 Java中多态的实现机制(1)
在疯狂java中,多态是这样解释的: 多态:相同类型的变量,调用同一个方法时,呈现出多中不同的行为特征, 这就是多态. 加上下面的解释:(多态四小类:强制的,重载的,参数的和包含的) 同时, 还用人这 ...
随机推荐
- [转载]在iTOP-4412开发板上调试helloworld应用
本文转自迅为论坛:http://www.topeetboard.com 1.安装ADB驱动 在开发板上调试 Android 应用,首先要安装 ADB 驱动. 通过“SDK Manager.exe”来安 ...
- 如何解决inline-block元素的空白间距
早上在博客中有人提了这样一个问题:“li元素inline-block横向排列,出现了未知间隙”,我相信大家在写页面的时候都遇到过这样的情况吧. 我一般遇到这情况都会把li浮动起来,这样就没有间隙.但是 ...
- POJ 1984 Navigation Nightmare
并查集,给n个点和m条边,每条边有方向和长度,再给q个询问,第i个询问查询两个点之间在Ti时刻时的曼哈顿距离(能连通则输出曼哈顿距离,否则输出-1) 这题跟Corporative Network 有点 ...
- HDU 1576 A/B【扩展欧几里德】
设A/B=x,则A=Bx n=A%9973=A-9973*y=Bx-9973*y 用扩展欧几里德求解 #include<stdio.h> #include<string.h> ...
- AC日记——潜伏者 洛谷 P1071 (模拟)
题目描述 R 国和 S 国正陷入战火之中,双方都互派间谍,潜入对方内部,伺机行动.历尽艰险后,潜伏于 S 国的 R 国间谍小 C 终于摸清了 S 国军用密码的编码规则: 1. S 国军方内部欲发送的原 ...
- [3D跑酷] MissionManager
前言 许久没有更新日志了,之前写了GUIManager,GUIClickEventReceiver还有AudioManager,这次写MissionManager 引用关系 首先看下MissionMa ...
- MongoDB学习(四)客户端工具备份数据库
在上一篇MongoDB学习(三)中讲解了如何在服务器端进行数据的导入导出与备份恢复,本篇介绍下如何利用客户端工具来进行远程服务器的数据备份到本地. 以客户端工具MongoVUE为例来进行讲解: 1.首 ...
- 狮子和计算Java题
package cn.bdqn.com; import java.util.Scanner; public class Jisaunqi { int num1; int num2; int jiegu ...
- 转: EclipseIDE开发 for C++
Eclipse 开发C++ 程序 http://tangmingjie2009.iteye.com/blog/2088363 Eclipse 开发C++ 程序 (二) 静态库 http://tangm ...
- Redis集群环境的部署记录
Redis Cluster终于出了Stable,这让人很是激动,等Stable很久了,所以还是先玩玩. 一. 集群简单概念. Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施( ...