顶会VLDB‘22论文解读:CAE-ENSEMBLE算法
摘要:针对时间序列离群点检测问题,提出了基于CNN-AutoEncoder和集成学习的CAE-ENSEMBLE深度神经网络算法,并通过大量的实验证明CAE-ENSEMBLE算法能有效提高时间序列离群点检测的准确度与效率。
本文分享自华为云社区《VLDB'22 CAE-ENSEMBLE论文解读》,作者:云数据库创新Lab。
导读
本文(Unsupervised Time Series Outlier Detection with Diversity-Driven Convolutional Ensembles)是由华为云数据库创新Lab联合丹麦Aalborg University与电子科技大学发表在顶会VLDB’22的文章。该文章针对时间序列离群点检测问题,提出了基于CNN-AutoEncoder和集成学习的CAE-ENSEMBLE深度神经网络算法,并通过大量的实验证明CAE-ENSEMBLE算法能有效提高时间序列离群点检测的准确度与效率。VLDB是CCF推荐的A类国际学术会议,是数据库和数据挖掘领域顶级学术会议之一。
1. 摘要
随着交通、医疗和金融等方面的全面数字化,大量的传感器被布置在我们生活的环境中,产生了各种各样的时间序列数据,随即催生出大量新的应用。本文研究时间序列的离群点检测问题,尽管过去有很多相关的研究,现有的离群点检测方法在算法的准确性与效率方面还是存在不足。本文针对这些问题提出了相应的解决方法,主要贡献如下:
- 提出了CAE-ENSEMBLE算法,本算法包括基于CNN的自编码器和多样性驱动的集成学习方法,其中基于CNN的自编码器用于对时间序列的时间依赖进行高效建模,多样性驱动的集成学习方法进一步提升了算法的准确性。
- 本文提出了一种无监督的超参数选择方法,减少了对昂贵标签数据的依赖。
- CAE-ENSEMBLE算法的表现在真实的时间序列数据集上击败了现有的方法。
2. 背景
时间序列离群点检测 给定一个长度为CC的时间序列\mathcal{T}=<s_1, s_2, ..., s_C>T=<s1,s2,...,sC>,即在第tt时刻的观测值为s_tst。 离群点检测的目标在于给每个观测值s_tst计算一个离群点分数\mathcal{OS}(s_t)OS(st),这个离群点分数越大,这个观测值越可能是离群点。比如可以根据领域知识预先设定一个阈值\epsilonϵ,那么如果\mathcal{OS}(s_t)>\epsilonOS(st)>ϵ, s_tst就被认为是离群点。
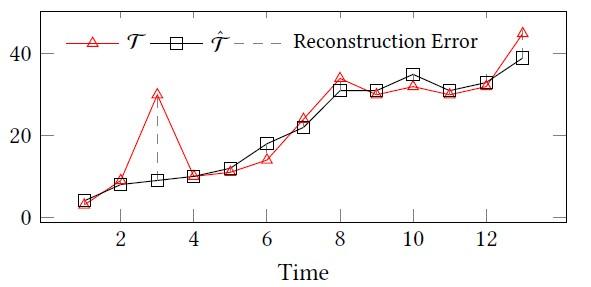
由于自动编码器属于无监督模型,且对时间序列数据具有强大的学习能力,本文采用自动编码器作为基本模型,用于时间序列离群点检测。具体来说,我们首先将原始时间序列\mathcal{T}T输入到编码器中进行表示学习,然后将学习到的表示输入到解码器中进行复原,得到重建的时间序列\hat{\mathcal{T}}T^,最后计算重建差异(reconstruction error),即\mathcal{T}T与\hat{\mathcal{T}}T^之间的差异,作为离群点分数。
如下图中时刻3的观测值的重建差异很大,它就很有可能是一个离群点。
自动编码器 自动编码器由一个编码器(Encoder)和解码器(Decoder)组成,给定输入X = [x_1, x_2, ..., x_C]X=[x1,x2,...,xC],则相对应的自动编码器输出为\hat{X} = [\hat{x}_1, \hat{x}_2, ..., \hat{x}_C]X^=[x^1,x^2,...,x^C],用于离群点检测的自动编码器目标函数为:
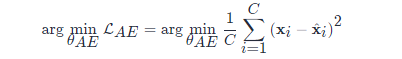
其中\theta_{AE}θAE代表自动编码器的参数。我们将重建损失RE定义为||x_i - \hat{x}_i||^2∣∣xi−x^i∣∣2,若重建损失RE超过设定好的阈值\epsilonϵ,则代表这个点为离群点。
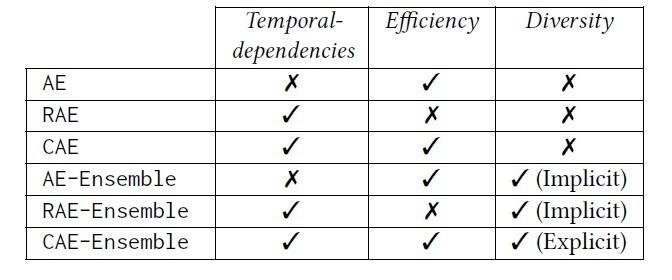
本文提及了6种编码器:普通自动编码器AE(由全连接层组成)、基于RNN的自动编码器RAE、基于CNN的自动编码器、集成的普通自动编码器AE-Ensemble、集成的基于RNN的自动编码器RAE-Ensemble、集成的基于CNN的自动编码器CAE-Ensemble。这六种编码器在建模时间依赖、效率和多样性方面的区别如下图所示。
3. CAE-ENSEMBLE算法设计
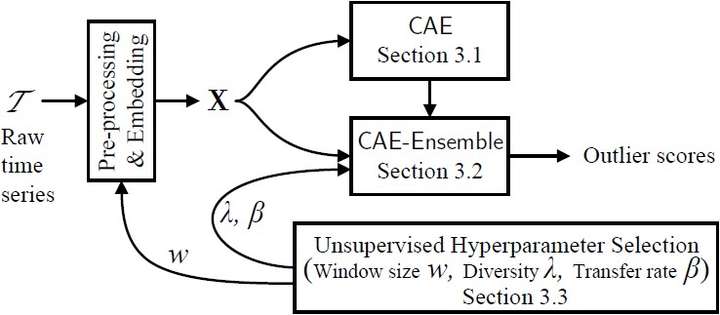
CAE-ENSEMBLE算法设计如下图所示,包含数据预处理、集成的CAE模型和无监督超参选择三部分,我们将从这三部分分别介绍本模型。
A. 数据预处理
数据预处理的目的在于将原始的时间序列数据处理为时间序列窗口数据,并用于模型训练和测试。防止减少不同特征对最后重构损失RE的影响,我们首先将原始数据进行标准化,公式如下:
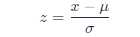
其中\muμ与\sigmaσ分别是训练集中观测值xx的均值和标准差。
将数据标准化后,设定滑动窗口大小为ww,然后对当前的时间序列观测数据进行滑动窗口,若原始时间序列为\mathcal{T}=<s_1, s_2, ..., s_C>T=<s1,s2,...,sC>,则第一个窗口为<s_1, s_2, ..., s_w><s1,s2,...,sw>,第二个窗口为<s_2, s_3, ..., s_{w+1}><s2,s3,...,sw+1>。
B. 集成的CAE模型CAE-ENSEMBLE
在本节中,首先,我们将介绍如何用基于CNN的自动编码器对时间序列数据进行建模,然后介绍多样性驱动的集成方法构建CAE-ENSEMBLE模型。
(1). 基于CNN的自动编码器(Convolutional Sequence-to-Sequence Autoencoder CAE)
本文采用基于CNN的自动编码器CAE作为集成学习的基础模型,并对时间序列进行建模,CAE结合了卷积神经网络CNN与Seq2Seq模型,结构如下图所示。首先,我们将一个滑动窗口的时间序列数据输入到由一维卷积组成的编码器中学习数据的时间依赖,然后将同样的数据和编码器学到的隐藏表示一起输入到由一维卷积组成的解码器中进行特征学习,最后利用注意力机制组合编码器和解码器学习到的特征,并用于重构时间序列。

在数据输入阶段,我们首先对原始滑动窗口数据进行特征嵌入,包含位置与观测嵌入两种方法,具体实现如下图所示。
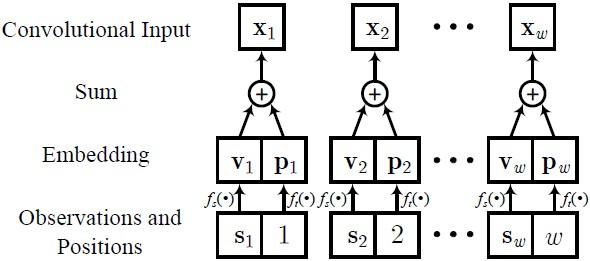
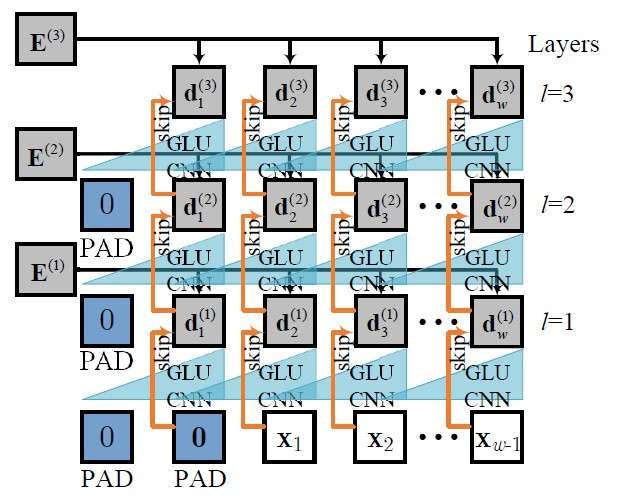
在编码阶段,编码器采用堆叠的卷积层学习时间序列的时序特征,下图给出了一个由三层卷积网络组成的编码器示例。

解码器与编码器类似,但存在轻微的不同,我们利用padding的方式确保在tt时刻的输入不晚于tt,下图给出了一个由三层卷积网络组成的解码器示例。
然后,利用注意力机制学习局部的时间依赖,注意力机制公式如下。

最终,对解码器最后一层网络生成的隐藏特征,利用全连接层进行重构,公式如下:
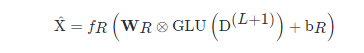
其中,D^{(L+1)}D(L+1)代表解码器最后一层学习到的隐藏特征。
(2). 多样性驱动的集成方法(Diversity-driven Ensembles)
为了解决现有方法准确度低和训练成本高的问题,我们将CAE作为基础模型,提出了一个新颖的多样性驱动的集成方法CAE-ENSEMBLE,如下图所示。与传统方法不同的是,我们一个一个的生成基础模型,而不是采取分别生成的方式。同时,我们还设计了一个用于保证模型多样性的目标函数,防止模型过于相似,以提高准确度。同时,我们在训练模型时,将一部分前一个模型的参数迁移到当前训练的基本模型中,这个操作可以显著地减少训练时间,提升效率。

目标函数 CAE-ENSEMBLE目标函数包含两部分:重构损失\mathcal{J}_{f_m}Jfm和模型的多样度损失\mathcal{K}_{f_m}Kfm,公式如下。

离群点分数计算 为了防止过拟合,我们采用多个模型计算出来的离群点分数\mathcal{OS}(x_t)OS(xt)的中位数作为最终的离群点分数。

其中MM代表基础模型的个数。
C. 无监督超参选择
本文有三个重要的超参:滑动窗口大小ww,参数转移比例\betaβ,平衡参数\lambdaλ,由于我们的方法是无监督的,首先,我们将划分无标签的训练集和验证集,然后我们为这三个参数设定一个范围,然后利用随机搜索,通过最小化重构损失确定一个最优的超参组合,,其中利用重构损失可以使得我们的算法不需要标签,达到无监督的作用。同时,在寻找某个参数的最优值的过程中,我们会将另外两个参数固定在默认值。具体算法如下图所示。

4. 实验
本文选择了五个常见的公开数据集ECG、SMD、MSL、SMAP、WADI,并选取了10个baseline与本文提出的CAE-ENSEMBEL算法比较。根据上述的无监督超参选择方法,对不同数据集设定的超参设置如下。

实验结果 我们在五个数据集上分别做了对比实验,用Precision、Recall、F1、PR和ROC作为评价手段,总体的精度结果如下图,可以发现CAE-Ensemble的结果在大部分情况下优于baselines。

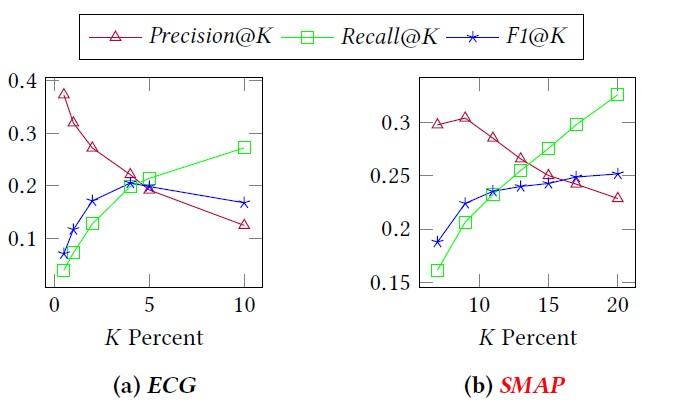
我们还在ECG与SMAP两个数据集上对对离群点的比例KK做了敏感度分析,发现在ECG数据上,K选5效果最好,而在SMAP数据上,K选12效果最优。
我们对模型的四个部分分别进行了消融实验,从实验结果中可以看出每个模块对于我们的任务都有一定的贡献。

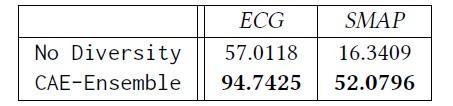
同时,我们去除了模型的多样性部分,并与完整的模型进行对比,发现CAE-Ensemble模型在多样性方面远远超过去除多样性的模型。
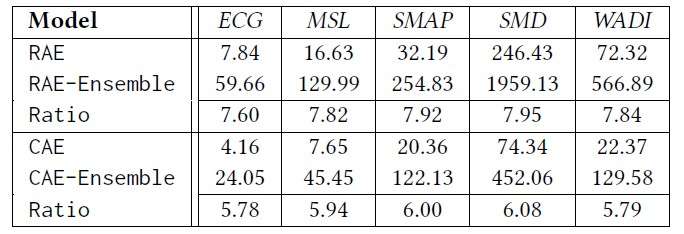
最后我们还对比了不同模型的训练时间,结果如下图,可以看出我们的模型在提升精度的同时,也提升了算法的效率。
5. 总结
本文针对时间序列的离群点检测问题,提出了基于CNN-AutoEncoder和集成学习的CAE-ENSEMBLE算法,通过大量的实验测试,证明了CAE-ENSEMBLE算法表现比现有的无监督方法优异,并能提高离群点检测的精度和效率。
华为云数据库创新lab官网:https://www.huaweicloud.com/lab/clouddb/home.html
顶会VLDB‘22论文解读:CAE-ENSEMBLE算法的更多相关文章
- VLDB'22 HiEngine极致RTO论文解读
摘要:<Index Checkpoints for Instant Recovery in In-Memory Database Systems>是由华为云数据库创新Lab一作发表在数据库 ...
- 解读ICDE'22论文:基于鲁棒和可解释自编码器的无监督时间序列离群点检测算法
摘要:本文提出了两个用于无监督的具备可解释性和鲁棒性时间序列离群点检测的自动编码器框架. 本文分享自华为云社区<解读ICDE'22论文:基于鲁棒和可解释自编码器的无监督时间序列离群点检测算法&g ...
- Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads 论文解读(VLDB 2021)
Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads 论文解读(VLDB 2021) ...
- Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021)
Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021) 本 ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
- CVPR2020行人重识别算法论文解读
CVPR2020行人重识别算法论文解读 Cross-modalityPersonre-identificationwithShared-SpecificFeatureTransfer 具有特定共享特征变换 ...
- CVPR2020论文解读:手绘草图卷积网络语义分割
CVPR2020论文解读:手绘草图卷积网络语义分割 Sketch GCN: Semantic Sketch Segmentation with Graph Convolutional Networks ...
- CVPR2020论文解读:3D Object Detection三维目标检测
CVPR2020论文解读:3D Object Detection三维目标检测 PV-RCNN:Point-Voxel Feature Se tAbstraction for 3D Object Det ...
- 可视化反投射:坍塌尺寸的概率恢复:ICCV9论文解读
可视化反投射:坍塌尺寸的概率恢复:ICCV9论文解读 Visual Deprojection: Probabilistic Recovery of Collapsed Dimensions 论文链接: ...
随机推荐
- nginx、rabbitmq、redis、zookeeper、zkui安装脚本
nginx安装脚本 #!/bin/bash yum install -y wget pcre-devel openssl openssl-devel gcc ###安装perl### cd /usr/ ...
- MVVM前后端分离:web接口规范
大前端前提下,开发采用前后端分离的方式,前端和后端主要通过接口进行分离, 后端开发接口,前端使用接口,前后端接口开发告一段落以后,接口联调差不多就进入开发尾声,准备送测了. 那么,对接口的约束和规范就 ...
- 将.View.dll文件反编译出来的*Views*.cs文件转换成.cshtml
先使用反编译工具将.View.dll文件反编译放入文件夹,然后将文件夹整体复制进\src\viewcs2cshtml\viewcs2cshtml\bin\Debug\net6.0\viewcs 复制完 ...
- 快速教程|如何在 AWS EC2上使用 Walrus 部署 GitLab
Walrus 是一款基于平台工程理念的开源应用管理平台,致力于解决应用交付领域的深切痛点.借助 Walrus 将云原生的能力和最佳实践扩展到非容器化环境,并支持任意应用形态统一编排部署,降低使用基础设 ...
- reverse_re3
main函数 点击重要函数 对if里面的数字按r键,使其从ASCII码转为字符 发现wasd四个关键的移动方向键,判断为迷宫问题 判断应该是要次数为2,即次数++3(从0开始计数)次才会有flag 点 ...
- JS判断点是否在线段上
本文利用向量的点积和叉积来判断点是否在线段上. 基础知识补充 从零开始的高中数学--向量.向量的点积.带你一次搞懂点积(内积).叉积(外积).Unity游戏开发--向量运算(点乘和叉乘 说明 点积可以 ...
- 每天5分钟复习OpenStack(十)Ceph 架构
在很多关于Ceph的文章中,通常会介绍一堆概念.虽然这些概念很重要,但是对于一个新手来说,同时接受太多的概念实际上很难消化.因此,在阅读本章节时要保持轻松的心情,只需要对所有的概念有个了解就可以了,因 ...
- ABAP 泰国凭证批导 报错 F51 192 输入一个业务场景
泰国凭证批导报错 F51 192 输入一个业务场景 方案一: 方案二: ID_BUPLA 用户参数
- 0x00.常用名词、文件下载、反弹shell
下载文章 方法一:下载谷歌插件fireshot,捕捉整个页面 方法二:使用js代码 f12进入控制台,粘贴如下代码 (function(){ $("#side").remove() ...
- 33. 干货系列从零用Rust编写正反向代理,关于HTTP客户端代理的源码实现
wmproxy wmproxy已用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,四层TCP/UDP转发,七层负载均衡,内网穿透,后续将实现websocket代 ...