Yolov8和Yolov10的差异以及后处理实现
Yolo模型可分为4个维度的概念
Yolo各模型版本进展历史
Yolov(2015年华盛顿大学的 Joseph Redmon 和 Ali Farhadi 发布)
Yolov2(2016年Joseph Redmon发布)
Yolov3(2018年Joseph Redmon发布)
Yolov4(2020年Alexey Bochkovskiy发布)
Yolov5(2018年Glen Jocher发布)
Yolov6(2022年美团团队发布)
Yolov7(2022年WongKinYiu发布)
Yolov8(2023年Ultralytics发布)
Yolov9(2023年发布)
Yolov10(2024年清华大学团队发布)
其中Yolov10是刚刚2024年5月底才刚发布的,其中v10实现了一个无NMS的架构,具有一致的双重分配,显著减少了后处理时间,并改善了整体延迟,让后处理变得更简单很多。
数据集(用于训练)
COCO(Common Objects in Context)
COCO旨在鼓励对各种对象类别的研究,通常用于对计算机视觉模型进行基准测试。
COCO 包含 330K 张图像,其中 200K 张图像带有对象检测、分割和字幕任务的注释。
该数据集仅包含 80 个对象类别,包括汽车、自行车和动物、雨伞、手提包和运动器材等常见对象。
用途主要是拿来比较各种AI模型的优劣的,不适合实际商业用途。
COCO数据集下载地址:https://cocodataset.org/#download
OIV7(Open Image V7 )
Open Image V7 是 Google 倡导的多功能、广泛的数据集。它旨在推动计算机视觉领域的研究,拥有大量标注有大量数据的图像900万张,在边界框标注的 190 万张图像中,支持涵盖 600 个对象类别,包含的 1600 万个边界框。这些边界框主要由专家手工绘制,确保高精度。数据集总体积有561GB。
数据集下载地址:https://storage.googleapis.com/openimages/web/download_v7.html
注:目前Yolov8有Open Image V7和COCO两种数据集已经有别人训练好了的权重文件。
而Yolov10因为是刚出来只找到COCO一种数据集训练好的权重文件,也就是说Yolov10只能识别80种物体,除非我们自己去训练。
模型变体(Variants)
下面只列出来我有尝试过导出了的:
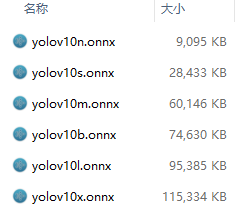
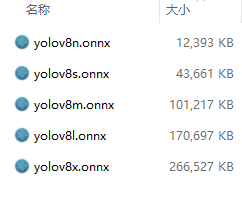
YOLOv8-N / YOLOv10-N:适用于资源极其受限的环境的纳米版本。
YOLOv8-S / YOLOv10-S:平衡速度和准确度的小型版本。
YOLOv8-M / YOLOv10-M:适用于通用用途的中型版本。
YOLOv10-B:平衡版本,宽度增加,准确度更高。
YOLOv8-L / YOLOv10-L:大型版本,以增加计算资源为代价,实现更高的准确度。
YOLOv8-X / YOLOv10-X:超大型版本,可实现最大准确度和性能。
注:v10有6种,v8只有5种。
动态/静态模型
模型支持导出成静态模型和动态模型,静态模型是[1,3,640,640],要求宽高符合32对齐。
动态模型则没有要求,其中v8的动态模型会随着输入尺寸不同,输出的尺寸会跟着变化。
而v10输入尺寸无论怎样,输出的尺寸都是固定的[1,300,6]。
我已将动态静态两种处理方式都融合在一份代码上,根据加载后的模型推理后的输出长度是否等于1800来判断是否是v10,均可在其内部进行处理。
Demo截图
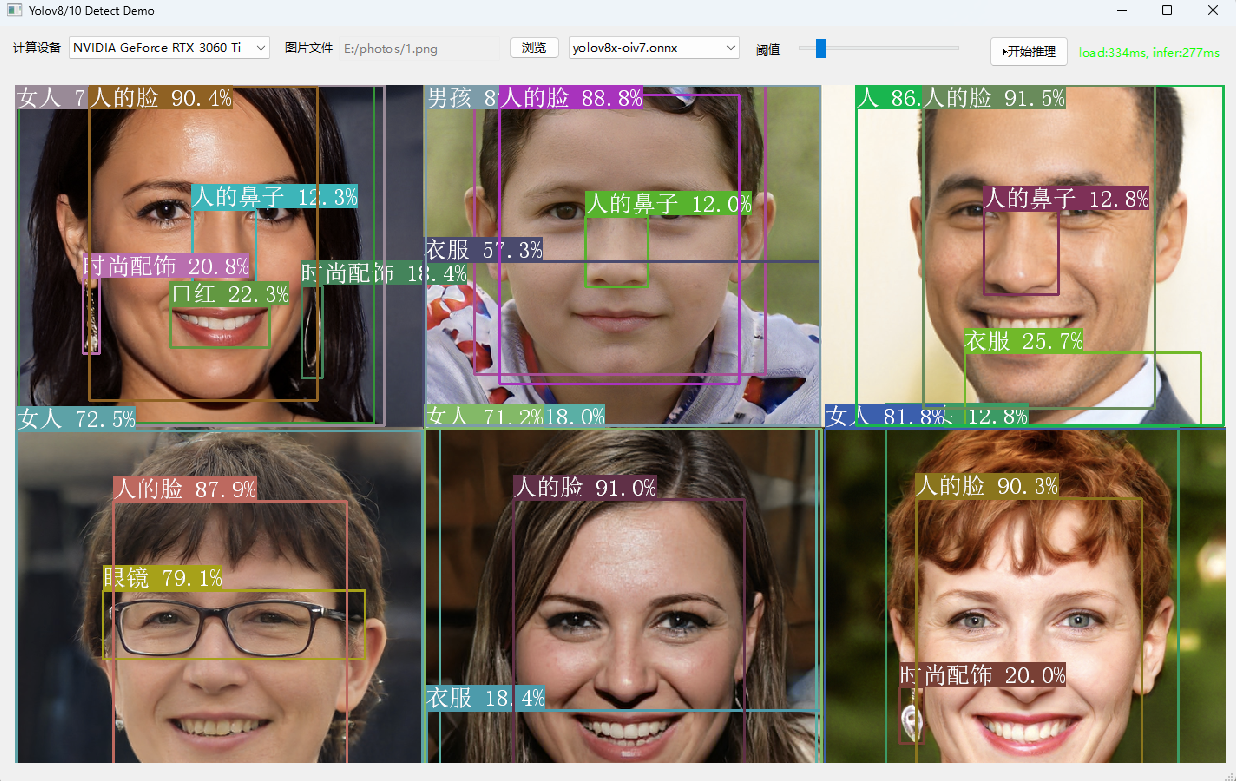
Yolov8的后处理代码:
std::vector<YoloResult> filterYolov8Detections(
float* inputs, float confidence_threshold,
int num_channels, int num_anchors, int num_labels,
int infer_img_width, int infer_img_height
)
{
std::vector<YoloResult> detections;
cv::Mat output =
cv::Mat((int)num_channels, (int)num_anchors,
CV_32F, inputs).t(); for (int i = 0; i < num_anchors; i++) {
auto row_ptr = output.row(i).ptr<float>();
auto bboxes_ptr = row_ptr;
auto scores_ptr = row_ptr + 4;
auto max_s_ptr = std::max_element(scores_ptr, scores_ptr + num_labels);
float score = *max_s_ptr;
if (score > confidence_threshold) {
float x = *bboxes_ptr++;
float y = *bboxes_ptr++;
float w = *bboxes_ptr++;
float h = *bboxes_ptr; float x0 = std::clamp((x - 0.5f * w), 0.f, (float)infer_img_width);
float y0 = std::clamp((y - 0.5f * h), 0.f, (float)infer_img_height);
float x1 = std::clamp((x + 0.5f * w), 0.f, (float)infer_img_width);
float y1 = std::clamp((y + 0.5f * h), 0.f, (float)infer_img_height); cv::Rect_<float> bbox;
bbox.x = x0;
bbox.y = y0;
bbox.width = x1 - x0;
bbox.height = y1 - y0;
YoloResult object;
object.object_id = max_s_ptr - scores_ptr;
object.score = score;
object.box = bbox;
detections.emplace_back(object);
}
}
return detections;
}
Yolov10的后处理代码:
std::vector<YoloResult> filterYolov10Detections(
const std::vector<float> &inputs, float confidence_threshold)
{
std::vector<YoloResult> detections;
const int num_detections = inputs.size() / 6;
for (int i = 0; i < num_detections; ++i)
{
float left = inputs[i * 6 + 0];
float top = inputs[i * 6 + 1];
float right = inputs[i * 6 + 2];
float bottom = inputs[i * 6 + 3];
float confidence = inputs[i * 6 + 4];
int class_id = inputs[i * 6 + 5]; if (confidence >= confidence_threshold)
{
cv::Rect_<float> bbox;
bbox.x = left;
bbox.y = top;
bbox.width = right - left;
bbox.height = bottom - top;
detections.push_back({class_id, confidence, bbox});
}
}
return detections;
}
Yolov8和Yolov10的差异以及后处理实现的更多相关文章
- 相同数据源情况下,使用Kafka实时消费数据 vs 离线环境下全部落表后处理数据,结果存在差异
原因分析: 当某个consumer宕机时,消费位点(例如2s提交一次)尚未提交到zookeeper,此时Kafka集群自动rebalance后另一consumer来接替该宕机consumer继续消费, ...
- 转:[译]Autoprefixer:一个以最好的方式处理浏览器前缀的后处理程序
原文来自于:http://www.cnblogs.com/aNd1coder/archive/2013/08/12/3252690.html Autoprefixer解析CSS文件并且添加浏览器前缀到 ...
- [译]Autoprefixer:一个以最好的方式处理浏览器前缀的后处理程序
Autoprefixer解析CSS文件并且添加浏览器前缀到CSS规则里,使用Can I Use的数据来决定哪些前缀是需要的. 所有你需要做的就是把它添加到你的资源构建工具(例如 Grunt)并且可 ...
- 浏览器前缀-----[译]Autoprefixer:一个以最好的方式处理浏览器前缀的后处理程序
Autoprefixer解析CSS文件并且添加浏览器前缀到CSS规则里,使用Can I Use的数据来决定哪些前缀是需要的. 所有你需要做的就是把它添加到你的资源构建工具(例如 Grunt)并且可 ...
- Autoprefixer:一个以最好的方式处理浏览器前缀的后处理程序
Autoprefixer解析CSS文件并且添加浏览器前缀到CSS规则里,使用Can I Use的数据来决定哪些前缀是需要的. 所有你需要做的就是把它添加到你的资源构建工具(例如 Grunt)并且可以完 ...
- Autoprefixer:一个以最好的方式处理浏览器前缀的后处理程序
Autoprefixer解析CSS文件并且添加浏览器前缀到CSS规则里,使用Can I Use的数据来决定哪些前缀是需要的. 所有你需要做的就是把它添加到你的资源构建工具(例如 Grunt)并且可 ...
- Git小技巧 - 指令别名及使用Beyond Compare作为差异比较工具
前言 本文主要写给使用命令行来操作Git的用户,用于提高Git使用的效率.至于使用命令还是GUI(Tortoise Git或VS的Git插件)就不在此讨论了,大家根据自己的的喜好选择就好.我个人是比较 ...
- BZOJ 3238: [Ahoi2013]差异 [后缀数组 单调栈]
3238: [Ahoi2013]差异 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 2326 Solved: 1054[Submit][Status ...
- Atitit 硬件 软件 的开源工作 差异对比
Atitit 硬件 软件 的开源工作 差异对比 1.1. 模块化,标准化,以及修改的便捷性1 1.2. 生产和发布成本 1 1.3. 3. 入行门槛搞2 1.4. 在软件业极度发达的今天,任何具 ...
- Javascript不同浏览器差异及兼容方法
原文链接:http://caibaojian.com/js-ie-different-from-firefox.html javascript的各种兼容就是为了解决不同浏览器的差异性,了解其中的差异能 ...
随机推荐
- 嘉楠k210 多线程 点亮流水灯
from Maix import GPIO from fpioa_manager import fm import _thread import time fm.register(24, fm.fpi ...
- 双11特刊|一站式在线数据管理平台DMS技术再升级,高效护航双11
简介: 10万+企业共同选择的数据库服务平台 阿里云数据库已连续多年稳定支撑天猫双11,历经极端流量场景淬炼.除了保障稳定顺滑的基本盘,今年大促期间数据库通过全面云原生化,大幅提升用户体验,让技术帮 ...
- [Nova] belongsTo, belongsToMany 当前页动态 dependsOn 其它 fields, nova-belongs-to-dependency, belongs-to-many-field-nova
nova-belongs-to-dependency 例子: use Manmohanjit\BelongsToDependency\BelongsToDependency; ... return [ ...
- 扎克伯格说,Llama3-8B还是太大了,量化、剪枝、蒸馏准备上!
扎克伯格说,Llama3-8B还是太大了,不适合放到手机中,有什么办法? 量化.剪枝.蒸馏,如果你经常关注大语言模型,一定会看到这几个词,单看这几个字,我们很难理解它们都干了些什么,但是这几个词对于现 ...
- dotnet 在 WPF 里显示数学 π 的颜色
有逗比小伙伴问我,数学的 π 视觉效果是啥.于是我就来写一个逗比的应用将 π 的颜色在 WPF 应用画出来.原理就是读取 π 的小数点后的数值,然后使用逗比算法转换为 RGB 颜色像素,接着将这些像素 ...
- vue-cli快速搭建项目的几个文件(一)
===========app.vue文件============= <template> <div id="app"> <router ...
- 01、Windows 排查
Windows 分析排查 分析排查是指对 Windows 系统中的文件.进程.系统信息.日志记录等进行检测,挖掘 Windows 系统中是否具有异常情况 1.开机启动项检查 一般情况下,各种木马.病毒 ...
- gin返回json假数据
package main import ( "github.com/gin-gonic/gin" "encoding/json" "fmt" ...
- ubuntu系统下安装最新版的MySQL
目录 下载mysql源 视频地址 原文章地址 下载mysql源 打开mysql官网 mysql官网文档 进入下载地址页面 下载mysql源 apt-get install -y wget #如果没有w ...
- iOS LLVM 中的宏定义
在阅读 Objc 库源码时常常会遇到很多宏定义,比如宏 SUPPORT_INDEXED_ISA.SUPPORT_PACKED_ISA,代码如下所示: // Define SUPPORT_INDEXED ...